動的テーブルのベストプラクティス¶
このトピックでは、動的テーブルを作成および管理する際のベストプラクティスと重要な考慮事項について説明します。
一般的なベストプラクティス:
動的テーブル作成のベストプラクティス:
動的テーブルリフレッシュのベストプラクティス:
パフォーマンスを最適化するためのベストプラクティス:
一般的なベストプラクティス¶
メタデータの表示には、MONITOR 権限を使用します。¶
ユーザーが動的テーブルのメタデータとInformation Schemaを表示する必要があるだけのシナリオ(例えば、データサイエンティストが持つロール)では、その動的テーブルの MONITOR 権限を持つロールを使用してください。OPERATE 権限ではこのアクセス権が付与されますが、動的テーブルを変更する機能も含まれているため、ユーザーが動的テーブルを変更する必要のないシナリオでは MONITOR 権限の方が適しています。
詳細については、 動的テーブルのアクセス制御 をご参照ください。
グループ化キーでの複合式の簡略化¶
グループ化キーにベース列ではなく複合式が含まれる場合は、1つのダイナミックテーブルでその式を実体化し、別のダイナミックテーブルで実体化された列にグループ化操作を適用します。詳細については、 演算子が増分リフレッシュする方法 をご参照ください。
動的テーブルを使用して、ゆっくりと変化するディメンションを実装する¶
動的テーブルは、タイプ1および2のゆっくりと変化するディメンション(SCDs)を実装するために使用できます。変更ストリームから読み取る場合は、変更タイムスタンプで並べ替えられた記録ごとのキーに対してウィンドウ関数を使用します。このメソッドを使用すると、動的テーブルは挿入、削除、更新の順番をシームレスに処理し、SCD の作成を簡素化します。詳細については、 動的テーブルを使用して、ゆっくりと変化するディメンションを実装する をご参照ください。
動的テーブル作成のベストプラクティス¶
動的テーブルのパイプラインのチェーン¶
新しい動的テーブルを定義する場合、多くの入れ子ステートメントを持つ大きな動的テーブルを定義するのではなく、パイプラインを持つ小さな動的テーブルを使用します。
動的テーブルを設定して、他の動的テーブルをクエリできます。たとえば、データパイプラインがステージングテーブルからデータを抽出して、さまざまなディメンションテーブル(顧客、製品、日時など)を更新するシナリオを想像してください。さらに、パイプラインはこれらのディメンションテーブルの情報に基づいて、売上集計テーブルを更新します。ディメンションテーブルがステージングテーブルにクエリし、売上集計テーブルがディメンションテーブルにクエリするように構成することで、タスクグラフと同様のカスケード効果が得られます。
この設定では、売上集計テーブルのリフレッシュは、ディメンションテーブルのリフレッシュが正常に完了した後にのみ実行されます。これにより、データの一貫性が確保され、ラグターゲットが達成されます。自動化されたリフレッシュプロセスにより、ソーステーブルの変更は適切なタイミングですべての従属テーブルのリフレッシュをトリガーします。
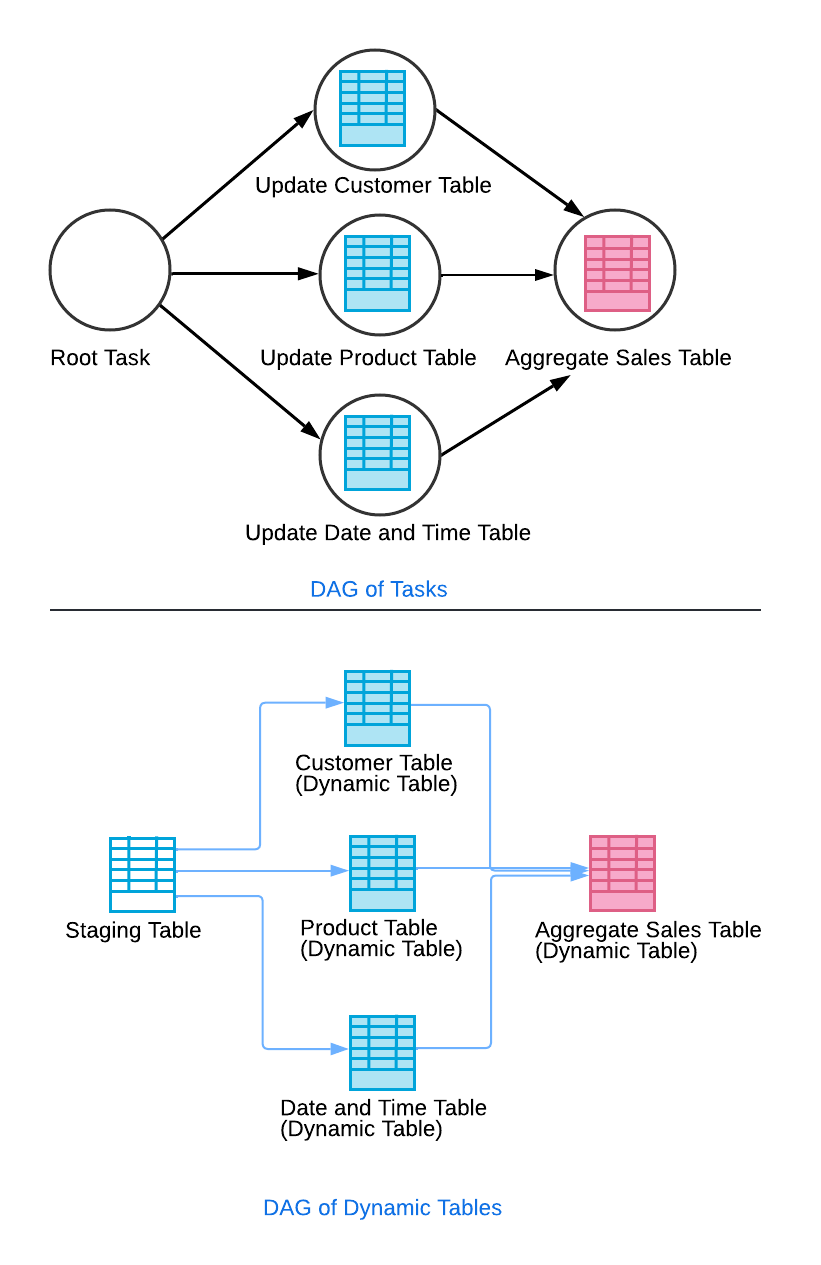
複雑なタスクグラフに「コントローラー」動的テーブルを使用する¶
多くのルートとリーフを持つ動的テーブルの複雑なグラフがあり、1つのコマンドでタスクグラフ全体に対して操作(ラグ変更、手動リフレッシュ、中断など)を実行したい場合、以下を実行します。
すべての動的テーブルの
TARGET_LAGの値をDOWNSTREAMに設定してください。タスクグラフのすべてのリーフから読み取る「コントローラー」動的テーブルを作成します。このコントローラーがリソースを消費しないようにするには、以下を実行します。
CREATE DYNAMIC TABLE controller TARGET_LAG = <target_lag> WAREHOUSE = <warehouse> AS SELECT 1 A FROM <leaf1>, …, <leafN> LIMIT 0;
コントローラーを使用してグラフ全体を制御します。例:
タスクグラフの新しいターゲットラグを設定します。
ALTER DYNAMIC TABLE controller SET TARGET_LAG = <new_target_lag>タスクグラフを手動でリフレッシュします。
ALTER DYNAMIC TABLE controller REFRESH
動的テーブルのクローンパイプラインについて¶
パイプラインの再初期化を避けるために、同じcloneコマンドで動的テーブルパイプラインのすべての要素をクローンします。パイプラインのすべての要素(基本テーブル、表示、動的テーブルなど)を同じスキーマまたはデータベースに統合することでこれを行うことができます。詳細については、 動的テーブルの既知の制限 をご参照ください。
一時動的テーブルを使用してストレージコストを削減する¶
一時 動的テーブルは、データ保持期間内はデータを確実に保持し、Time Travelをサポートしますが、フェイルセーフ期間を超えてデータを保持することはありません。デフォルトでは、動的テーブルデータは フェールセーフ ストレージに7日間保持されます。リフレッシュスループットが高い動的テーブルでは、ストレージの消費量が大幅に増加する可能性があります。したがって、動的テーブルを一時的に使用するのは、そのデータが永続テーブルと同じレベルのデータ保護とリカバリを必要としない場合に限ります。
一時動的テーブルを作成したり、既存の動的テーブルを一時的な動的テーブルにクローンするには、 CREATE DYNAMIC TABLE ステートメントを使用します。
動的テーブルリフレッシュのベストプラクティス¶
リフレッシュ専用ウェアハウスを使用する¶
動的テーブルは、リフレッシュを実行するために仮想ウェアハウスを必要とします。動的テーブルパイプラインに関連するコストを明確に把握するためには、動的テーブルに起因する仮想ウェアハウスの消費を分離できるように、専用ウェアハウスを使用して動的テーブルをテストする必要があります。詳細については、 動的テーブルのコストを理解する をご参照ください。
下流ラグを使用する¶
下流ラグは、依存する他の動的テーブルのリフレッシュが必要なときに、動的テーブルをリフレッシュする必要があることを示します。下流ラグは、その使いやすさと費用対効果の高さから、ベストプラクティスとして利用する必要があります。下流ラグがなければ、複雑な動的テーブルのチェーンを管理するには、最終テーブルのデータ鮮度を監視するだけではなく、各テーブルに個別にターゲットラグを割り当て、関連する制約を管理する必要があります。詳細については、 ターゲットラグについて をご参照ください。
すべての実稼働動的テーブルのリフレッシュモードを設定します。¶
動的テーブルの実際の リフレッシュモード は作成時に決定され、その後は不変です。明示的に指定されない場合、リフレッシュモードのデフォルトは AUTO です。これは、クエリの複雑さ、サポートされていない構成要素、演算子、関数などの様々な要因に基づいてリフレッシュモードを選択します。
リフレッシュモードと自動推奨を試して、ユースケースに最適なモードを決定してください。Snowflakeリリース間で一貫性のある動作を実現するには、すべてのプロダクションテーブルで明示的にリフレッシュモードを設定します。 AUTO の動作はSnowflakeのリリース間で変更される可能性があり、プロダクションパイプラインで使用した場合、予期しないパフォーマンスの変化を引き起こす可能性があります。
動的テーブルのリフレッシュモードを確認するには、 動的テーブルリフレッシュモードを表示する をご参照ください。
パフォーマンス最適化のベストプラクティス¶
ダイナミックテーブルのパフォーマンスを最適化するには、システムを理解し、アイデアを試し、結果に基づいて反復する必要があります。例:
コスト、データラグ、レスポンスタイムのニーズに基づき、データパイプラインを改善する方法を開発します。
以下のアクションを実施します。
クエリを素早く開発するために、小さな固定データセットから始めます。
動いているデータを使ってパフォーマンスをテストします。
データセットをスケールして、ニーズに合っていることを確認します。
調査結果に基づいてワークロードを調整します。
パフォーマンスへの影響が最も大きいタスクに優先順位をつけて、必要に応じて繰り返します。
さらに、ダウンストリームラグを使用してテーブル間のリフレッシュ依存関係を効率的に管理し、必要なときにのみリフレッシュが行われるようにします。詳しくは、 パフォーマンスドキュメント をご覧ください。
リフレッシュモードの選択¶
あなたのユースケースに最適なモードを決定するために、自動推奨と具体的なリフレッシュモード(フルとインクリメンタル)を試してみてください。動的テーブルのパフォーマンスに最適なモードは、データ変更量とクエリの複雑さによって異なります。さらに、専用のウェアハウスでさまざまなリフレッシュモードをテストすることで、コストを分離し、実際のワークロードに基づいてパフォーマンスチューニングを改善することができます。
動的テーブルのリフレッシュモードを確認するには、 動的テーブルリフレッシュモードを表示する をご参照ください。
AUTO リフレッシュモード: システムはデフォルトでインクリメンタルリフレッシュを適用しようとします。 インクリメンタルリフレッシュがサポートされていない場合 、あるいはうまく機能しない可能性がある場合、動的テーブルは自動的にフルリフレッシュを選択します。
一貫した動作を実現するには、すべてのプロダクションテーブルで明示的にリフレッシュモードを設定してください。
AUTOの動作はSnowflakeのリリース間で変更される可能性があり、プロダクションパイプラインで使用した場合、予期しないパフォーマンスの変化を引き起こす可能性があります。
インクリメンタルリフレッシュ: 最後の更新以降の変更のみで動的テーブルを更新するため、頻繁に小さな更新が行われる大規模なデータセットに最適です。
インクリメンタルリフレッシュに対応したクエリに最適です(例えば、決定性関数、単純な結合、
SELECT、WHERE、GROUPBYの基本式など)。サポートされていない機能が存在し、更新モードがインクリメンタルに設定されている場合、Snowflakeは動的テーブルの作成に失敗します。インクリメンタルリフレッシュでパフォーマンスを最適化するための重要なプラクティスは、変更量をソースデータの5%程度に抑え、グループ化キーでデータをクラスタリングして処理のオーバーヘッドを減らすことです。
多くの結合を行う集約のような、特定の操作の組み合わせは、効率的に実行されない可能性があります。
フルリフレッシュ: データセット全体を再処理し、完全なクエリ結果で動的テーブルを更新します。複雑なクエリや、大幅なデータ変更で完全な更新が必要な場合に使用します。
複雑なクエリ、非決定性関数、データの大きな変更などにより、インクリメンタルリフレッシュがサポートされていない場合に便利です。
詳細については、 リフレッシュモードが動的テーブルのパフォーマンスに与える影響 をご参照ください。
フルリフレッシュパフォーマンス¶
フルリフレッシュ動的テーブルは、 CREATE TABLE ... AS SELECT (CTAS とも呼ばれる) と同様の動作をします。他のSnowflakeクエリと同様に最適化することができます。
増分リフレッシュパフォーマンス¶
動的テーブルの最適な増分リフレッシュパフォーマンスを実現するには:
ソースと動的テーブルの両方について、リフレッシュ間の変更を最小限、理想的にはデータセット全体の5%未満に抑えます。
行数だけでなく、変更されたマイクロパーティションの数も考慮してください。増分リフレッシュの作業量は、変更された行だけでなく、これらのマイクロパーティションのサイズに比例します。
クエリでは、結合、GROUPBYs、PARTITIONBYsなどのグループ化操作を最小限にします。大きな共通テーブル式(CTEs)を小さな部分に分割し、それぞれに動的テーブルを作成します。過剰な集約や結合を行うことで1つの動的テーブルを圧迫しないようにします。
テーブルの変更をクエリのキーに合わせることで、データの局所性を確保します(例:結合、GROUPBYs、PARTITIONBYs)。テーブルがこれらのキーで自然にクラスタリングされていない場合は、 自動クラスタリング を有効にしてください。