Kafkaコネクタの概要¶
このトピックでは、Apache KafkaおよびKafka用Snowflakeコネクタの概要を説明します。
注釈
Kafkaコネクタは、 コネクタ規約 に従います。
Apache Kafkaの概要¶
Apache Kafkaソフトウェアは、メッセージキューやエンタープライズメッセージシステムと同様に、パブリッシュおよびサブスクライブモデルを使用してレコードのストリームを読み書きします。Kafkaを使用すると、プロセスはメッセージを非同期で読み書きできます。サブスクライバーはパブリッシャーに直接接続する必要はありません。パブリッシャーはKafkaでメッセージをキューに入れて、サブスクライバーが後で受信できるようにします。
アプリケーションはメッセージを トピック に発行し、アプリケーションはトピックをサブスクライブしてそれらのメッセージを受信します。Kafkaはメッセージを処理および送信できますが、このドキュメントの取り扱い範囲外です。トピックを「パーティション」に分割して、スケーラビリティを向上させることができます。
Kafka Connectは、Kafkaをデータベースなどの外部システムと接続するためのフレームワークです。Kafka Connectクラスタは、Kafkaクラスタとは別のクラスタです。Kafka Connectクラスタは、コネクタ(外部システム間の読み取りおよび書き込みをサポートするコンポーネント)の実行とスケールアウトをサポートします。
Kafkaコネクタは、Kafka Connectクラスターで実行され、Kafkaトピックからデータを読み取り、Snowflakeテーブルにデータを書き込むように設計されています。
Snowflakeは、次の2つのバージョンのコネクタを提供します。
A version for the Confluent package version of Kafka.
Kafka Connectの詳細については、https://docs.confluent.io/current/connect/をご参照ください。
注釈
Kafkaコネクタのホストバージョンは、Confluent Cloudで入手できます。詳細については、https://docs.confluent.io/current/cloud/connectors/cc-snowflake-sink.htmlをご参照ください。
オープンソースソフトウェア(OSS)用のApache Kafkaパッケージ のバージョン。
Apache Kafkaの詳細については、https://kafka.apache.org/をご参照ください。
Snowflakeの観点から見ると、KafkaトピックはSnowflakeテーブルに挿入される行のストリームを生成します。一般に、各Kafkaメッセージには1つの行が含まれます。
Kafkaは、多くのメッセージパブリッシュ/サブスクライブプラットフォームと同様に、パブリッシャーとサブスクライバーの間の多対多の関係を可能にします。1つのアプリケーションで多数のトピックを発行でき、1つのアプリケーションで複数のトピックをサブスクライブできます。Snowflakeの典型的なパターンは、1つのトピックが1つのSnowflakeテーブルのメッセージ(行)を提供することです。
Kafkaコネクタの現在のバージョンは、Snowflakeへのデータのロードに制限されています。Kafkaコネクタは、データのロードメソッド2つのサポートしています。
詳細については、 Snowflakeにデータをロードする および Snowpipe Streamingを使用したKafka用Snowflakeコネクタの使用 をご参照ください。
Kafkaトピックのターゲットテーブル¶
Kafkaトピックは、Kafka構成内の既存のSnowflakeテーブルにマップできます。トピックがマップされていない場合、Kafkaコネクターはトピック名を使用して各トピックの新しいテーブルを作成します。
コネクタは、次のルールを使用してトピック名を有効なSnowflakeテーブル名に変換します。
小文字のトピック名は大文字のテーブル名に変換されます。
トピック名の最初の文字が文字(
a-zまたはA-Z)またはアンダースコア文字(_)でない場合、コネクタはテーブル名の先頭にアンダースコアを追加します。トピック名内の文字がSnowflakeテーブル名に有効な文字でない場合、その文字はアンダースコア文字に置き換えられます。テーブル名で有効な文字の詳細については、 識別子の要件 をご参照ください。
KafkaコネクタがKafkaトピック用に作成されたテーブルの名前を調整する必要がある場合、同じスキーマ内の2つのテーブルの名前が同一になる可能性があることに注意してください。例えば、トピック numbers+x および numbers-x からデータを読み取る場合、これらのトピック用に作成されるテーブルは両方とも NUMBERS_X になります。誤ってテーブル名が重複しないように、コネクタはテーブル名にサフィックスを追加します。サフィックスは、アンダースコアとそれに続く生成されたハッシュコードです。
Tip
可能であれば、Snowflake識別子名のルールに従うトピック名を選択することをSnowflakeはお勧めします。
Kafkaトピックのテーブルのスキーマ¶
Kafka コネクタが読み込むテーブルのスキーマは、テーブルのタイプとコネクタの構成によって異なります:
ほとんどのテーブルは、このセクションで説明するデフォルトのスキーマを使用します。
スキーマ検出と進化 を使用すると、スキーマにはユーザー定義スキーマに一致する列が含まれます。
Iceberg テーブルにインジェストすると、スキーマには同じデフォルト列(
record_contentとrecord_metadata)が含まれます。ただし、これらは VARIANT ではなく、 構造型タイプ の列です。
Snowpipe または Snowpipe Streaming では、デフォルトで、KafkaコネクタによってロードされるすべてのSnowflakeテーブルには、2つの VARIANT 列で構成されるスキーマがあります。
RECORD_CONTENTこれには、Kafkaメッセージが含まれます。
RECORD_METADATAこれには、メッセージに関するメタデータ(例えば、メッセージが読み取られたトピック)が含まれます。
Snowflakeがテーブルを作成する場合、テーブルにはこれらの2つの列のみが含まれます。Kafkaコネクタのために行を追加するためのテーブルをユーザーが作成する場合、テーブルにはこれらの2列以上を含めることができます(コネクタのデータにはこれらの列の値が含まれないため、追加の列には NULL 値を許可する必要があります)。
RECORD_CONTENT 列には、Kafkaメッセージが含まれています。
Kafkaメッセージには、送信される情報に依存する内部構造があります。たとえば、 IoT (モノのインターネット)気象センサーからのメッセージには、データが記録された時のタイムスタンプ、センサーの場所、温度、湿度などが含まれる場合があります。在庫システムからのメッセージには、製品 ID と販売されたアイテムの数、および販売または出荷された日時を示すタイムスタンプが含まれる場合があります。
通常、特定のトピックの各メッセージは同じ基本構造を持っています。通常、トピックごとに構造が異なります。
各Kafkaメッセージは、 JSON 形式またはAvro形式でSnowflakeに渡されます。Kafkaコネクタは、そのフォーマットされた情報をタイプ VARIANT の単一の列に保存します。データは解析されず、Snowflakeテーブルのデータは複数の列に分割されません。
RECORD_METADATA 列には、デフォルトで次の情報が含まれています。
フィールド |
Java . データ型 |
SQL . データ型 |
必須 |
説明 |
|---|---|---|---|---|
topic |
文字列 |
VARCHAR |
有り |
レコードが由来するKafkaトピックの名前です。 |
partition |
文字列 |
VARCHAR |
有り |
トピック内のパーティションの番号です。(これはSnowflakeマイクロパーティションではなく、Kafkaパーティションであることに注意してください。) |
offset |
long |
INTEGER |
有り |
そのパーティションのオフセットです。 |
CreateTime / . LogAppendTime |
long |
BIGINT |
無し |
これは、Kafkaトピックのメッセージに関連付けられたタイムスタンプです。値は、1970年1月1日午前0時 UTCからのミリ秒です。詳細については、https://kafka.apache.org/0100/javadoc/org/apache/kafka/clients/producer/ProducerRecord.htmlをご参照ください。 |
SnowflakeConnectorPushTime |
long |
BIGINT |
無し |
Snowpipe Streaming使用時のみ利用可能。記録がインジェスト SDK バッファにプッシュされたときのタイムスタンプ。値は、1970年1月1日午前0時 UTC からのミリ秒数です。詳細については、 インジェスチョンレイテンシの推定 を参照してください。 |
key |
文字列 |
VARCHAR |
無し |
メッセージがKafka KeyedMessageの場合、これはそのメッセージのキーです。コネクタが RECORD_METADATA にキーを保存するには、 Kafka構成プロパティ のkey.converterパラメーターを「org.apache.kafka.connect.storage.StringConverter」に設定する必要があります。そうでない場合、コネクターはキーを無視します。 |
schema_id |
int |
INTEGER |
無し |
スキーマレジストリでAvroを使用してスキーマを指定する場合、これはそのレジストリ内のスキーマの ID です。 |
headers |
Object |
OBJECT |
無し |
ヘッダーは、レコードに関連付けられたユーザー定義のキーと値のペアです。 各レコードには、0、1、または複数のヘッダーを含めることができます。 |
RECORD_METADATA 列に記録されるメタデータの量は、オプションのKafka構成プロパティを使用して構成できます。詳細については、 Kafkaコネクタのインストールと構成 をご参照ください。
フィールド名と値は大文字と小文字が区別されます。
JSON 構文で表現されたサンプルメッセージは、次のようになります。
適切な クエリの構文VARIANT 列 を使用して、Snowflakeテーブルを直接クエリできます。
以下は、 RECORD_METADATAのトピックに基づいてデータを抽出する簡単な例です。
出力は次のようになります。
または、これらのテーブルからデータを抽出し、データを個々の列にフラット化して、他のテーブルにデータを保存することができます。他のテーブルは、通常クエリが簡単です。
Kafkaコネクタのワークフロー¶
Kafkaコネクタは、KafkaトピックをサブスクライブしてSnowflakeオブジェクトを作成するために以下のプロセスを完了します。
Kafkaコネクタは、Kafka構成ファイルまたはコマンドライン(またはConfluent Control Center、Confluentのみ)を介して提供される構成情報に基づいて、1つ以上のKafkaトピックにサブスクライブします。
コネクタは、トピックごとに次のオブジェクトを作成します。
各トピックのデータファイルを一時的に保存する内部ステージ。
各トピックパーティションのデータファイルを取り込むパイプ。
トピックごとに1つのテーブル。各トピックに指定されたテーブルが存在しない場合、コネクタはテーブルを作成します。そうでない場合、コネクターは既存のテーブルに RECORD_CONTENT および RECORD_METADATA 列を作成し、他の列がNULL可能であることを検証します(それ以外の場合はエラーを生成します)。
次の図は、Kafkaコネクタを使用したKafkaの取り込みフローを示しています。
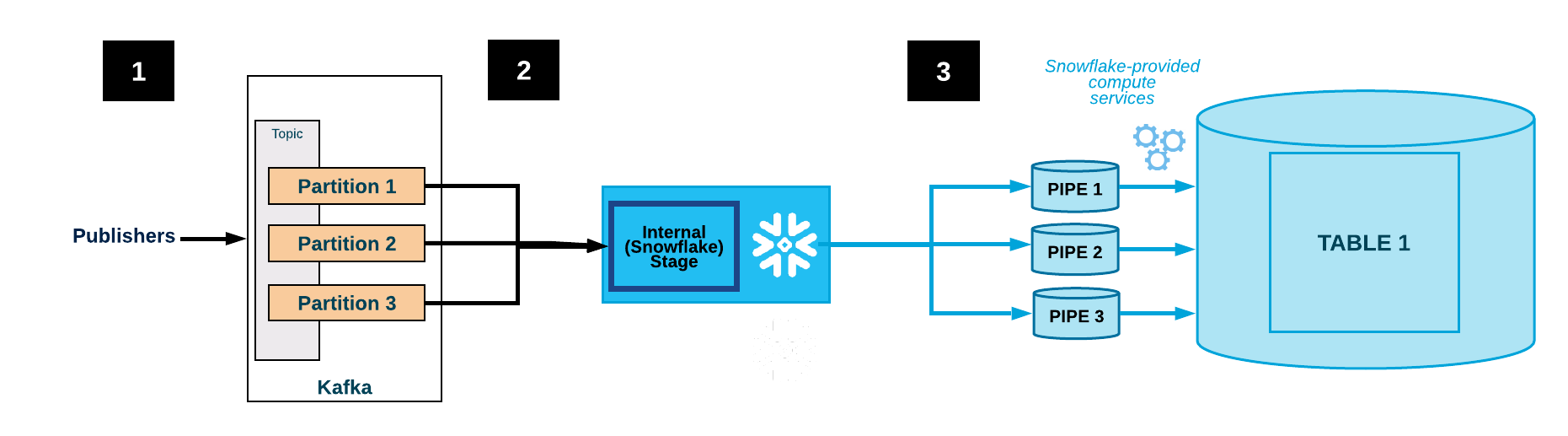
1つ以上のアプリケーションが JSON またはAvroレコードをKafkaクラスターに公開します。レコードは1つ以上のトピックパーティションに分割されます。
Kafkaコネクタは、Kafkaトピックからのメッセージをバッファします。しきい値(時間、メモリ、またはメッセージ数)に達すると、コネクタは内部ステージで一時ファイルにメッセージを書き込みます。コネクタは Snowpipe をトリガーして、一時ファイルを取り込みます。Snowpipeは、データファイルへのポインターをキューにコピーします。
Snowflakeが提供する仮想ウェアハウスは、Kafkaトピックパーティション用に作成されたパイプを介して、ステージングされたファイルからターゲットテーブル(つまり、トピックの構成ファイルで指定されたテーブル)にデータをロードします。
(表示なし)コネクタはSnowpipeをモニターし、ファイルのデータがテーブルにロードされたことを確認した後、内部ステージの各ファイルを削除します。
障害によりデータのロードが妨げられた場合、コネクタはファイルをテーブルステージに移動し、エラーメッセージを生成します。
コネクタはステップ2~4を繰り返します。
注意
Snowflakeは、 insertReport API を1時間ポーリングします。インジェストしたファイルのステータスがこの1時間以内に成功しない場合、インジェストしているファイルはテーブルステージに移動されます。
これらのファイルがテーブルステージで利用できるようになるまで、少なくとも1時間かかる場合があります。ファイルは、前の1時間以内にインジェスチョンステータスが見つからなかった場合にのみ、テーブルステージに移動されます。
フォールトトレランス¶
KafkaおよびKafkaコネクタはどちらもフォールトトレラントです。メッセージは複製されず、警告なしのドロップもされません。
データロードチェーンのSnowpipeワークフローのデータ重複排除ロジックは、まれな場合を除いて、繰り返されるデータの重複コピーを排除します。Snowpipeが記録をロードしているときにエラーが検出された場合(たとえば、記録が整形式 JSON またはAvroでなかった場合)、記録はロードされません。代わりに、記録はテーブルステージに移動されます。
Snowpipe Streamingを使用したKafkaコネクタは、エラー処理用に配信不能キュー(DLQ)をサポートしています。詳細については、 Snowpipe Streamingを使用したKafkaコネクタのエラー処理および DLQ プロパティ をご参照ください。
コネクタのフォールトトレランスの制限¶
Kafkaトピックは、ストレージスペースまたは保持時間の制限で構成できます。
デフォルトの保持時間は7日間です。保持時間を超えてシステムがオフラインしている場合、期限切れの記録はロードされません。同様に、Kafkaのストレージスペースの制限を超えると、一部のメッセージは配信されません。
Kafkaトピックのメッセージが削除または更新された場合、これらの変更はSnowflakeテーブルに反映されない可能性があります。
注意
Kafkaコネクタのインスタンスは相互に通信しません。同じトピックまたはパーティションでコネクタの複数のインスタンスを起動すると、同じ行の複数のコピーがテーブルに挿入される場合があります。これは推奨されません。各トピックは、コネクタの1つのインスタンスのみで処理する必要があります。
Snowflakeがメッセージをインジェストするよりも速くメッセージがKafkaから流れることは理論的には可能です。ただし実際には、こうした状況は通常発生しません。発生した場合、問題を解決するには、Kafka Connectクラスタのパフォーマンスチューニングが必要になります。例:
Connectクラスタ内のノード数の調整。
コネクタに割り当てられたタスクの数を調整します。
コネクタとSnowflake展開間のネットワーク帯域幅の影響に対する理解。
重要
行が最初に公開された順序で挿入されるという保証はありません。
サポートされているプラットフォーム¶
Kafkaコネクタは任意のKafka Connectクラスターで実行でき、サポートされている クラウドプラットフォーム 上のSnowflakeアカウントにデータを送信できます。
Protobufデータサポート¶
Kafkaコネクタ1.5.0(またはそれ以上)は、protobufコンバーターを介してプロトコルバッファ(protobuf)をサポートします。詳細については、 Kafka用Snowflakeコネクタを使用したprotobufデータのロード をご参照ください。
請求情報¶
Kafkaコネクタの使用には直接の料金はかかりません。ただし、次の間接的なコストがあります。
Snowpipeは、コネクタがKafkaから読みとるデータをロードするために使用され、Snowpipeの処理時間はアカウントに請求されます。
データストレージはアカウントに請求されます。
Kafkaコネクタの制限¶
単一メッセージ変換( SMTs )は、Kafka Connectを流れるメッセージに適用されます。Kafka構成プロパティ を構成するときに、 key.converter または value.converter の いずれか を次のいずれかの値に設定すると、対応するキーまたは値で SMTs はサポートされません。
com.snowflake.kafka.connector.records.SnowflakeJsonConvertercom.snowflake.kafka.connector.records.SnowflakeAvroConvertercom.snowflake.kafka.connector.records.SnowflakeAvroConverterWithoutSchemaRegistry
key.converter も value.converter も設定されていない場合、現在の regex.router を除いて、ほとんどの SMTs がサポートされます。
Snowflakeコンバーターは SMTs をサポートしていませんが、Kafkaコネクタのバージョン1.4.3(またはそれ以上)は、次のようなコミュニティベースのコンバーターを多数サポートしています。
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverter
SMTs の詳細については、https://docs.confluent.io/current/connect/transforms/index.htmlをご参照ください。