Snowpipe Streaming¶
Snowpipe Streamingは、ハイパフォーマンスアーキテクチャ上に構築されたSnowflakeのリアルタイムインジェスションサービスです。これにより、アプリケーションは行が到着すると、ファイルをステージングしたり、中間ストレージを管理したりすることなく、ストリーミングデータをSnowflakeテーブルに直接ロードできます。データは取り込まれて数秒以内にクエリで利用できるようになり、IoTテレメトリーおよび変更データキャプチャ(CDC)パイプラインから、不正使用検出とライブ分析に至るまでのユースケースをサポートします。
Snowpipe Streamingは以下を提供します。
テーブルごとに最大 10GB/s のスループット
エンドツーエンドの取り込みからクエリまでのレイテンシが 最短5秒
組み込みのオフセットトークン追跡による 1回限りの配信
各チャネル内の 順序付きインジェスチョン
Snowflakeマネージド Apache Iceberg テーブルへのストリーミング
Snowpipe Streamingを使用する理由¶
1回限りの配信 :組み込みのオフセットトークン追跡は、1回限りのセマンティクスを可能にします。アプリケーションはコミットされたオフセットを追跡し、復旧時に最後にコミットされた位置からリプレイすることで、データの重複やデータの損失を防ぎます。詳細については、 オフセットトークンと1回限りの配信 をご参照ください。
順序付きインジェスチョン :行は各 チャネル 内で順番にインジェストされます。チャネルはソースパーティション(例えば、Kafkaトピックパーティション)に自然にマップされ、決定論的再生とゼロ損失回復を可能にします。
高スループット、低レイテンシ :テーブルごとに最大10GB/sの取り込み速度をサポートするように設計されており、最短5秒でデータをクエリに使用できます。
同時進行の変換:PIPEオブジェクト内のCOPYコマンド構文を使用して、インジェスチョン中にデータをクリーンアップ、再作成、および変換します。データがターゲットテーブルにコミットされる前に、行をフィルターし、列を並べ替え、型をキャストし、式を適用します。別にETLステップは必要ありません。
インジェスト時の事前クラスタリング :クラスタリングキーを使用してテーブルのクエリパフォーマンスを最適化するために、インジェスチョン中にデータを並べ替えます。
Apache Icebergテーブルのサポート :Iceberg v2および:doc:
Iceberg v3 </user-guide/tables-iceberg-v3-specification-support>`両方のテーブルを含む、Snowflake管理のIcebergテーブルにデータをストリーミングします。詳細については、 :doc:`snowpipe-streaming-high-performance-icebergをご参照ください。スキーマの進化 :データ構造の変化にテーブルスキーマを自動的に適応させます。Snowflakeは、手動DDL変更を必要とせず受信ストリームで検出された新しい列を追加できます。
簡素化されたパイプライン :SDKsが行をテーブルに直接書き込み、ステージングファイルや中間のクラウドストレージの必要性を回避します。
サーバーレスでスケーラブル :コンピューティングリソースは、取り込みの負荷に基づいて自動的にスケールします。管理するインフラストラクチャはありません。
透明性のある価格設定 :インジェストされたデータの非圧縮GBあたりのクレジットで計算されるスループットベースの請求。詳細については、 Snowpipe Streaming high-performance architecture: Understand your costs をご参照ください。
接続する方法¶
Snowpipe Streamingは、異なるワークロードに合わせて複数のインジェスチョンパスをサポートしています。
統合 |
最適な用途 |
|---|---|
高スループットのカスタムアプリケーション。Java 11以降が必要です。 |
|
データエンジニアリングおよびPythonネイティブのワークフロー。Python 3.9以降が必要です。 |
|
軽量なワークロード、IoTデバイス、およびエッジのデプロイ。 |
|
Apache Kafkaトピックインジェスチョン。 |
JavaおよびPythonSDKsの両方が、クライアント側のパフォーマンスを向上させ、リソースの使用量を削減するためのRustベースのクライアントコアを使用しています。
注釈
RESTAPI でSnowpipe Streaming SDK を始めて、パフォーマンスと使用開始のエクスペリエンスの向上を実感することをお勧めします。
開始するには、次をご参照ください。 チュートリアル:SDK入門 または チュートリアル:REST API入門 。
PIPEオブジェクト、チャネル、オフセットトークン、およびサポートされるデータ型の技術的な詳細については、 主な概念 をご参照ください。
以下の用途に推奨¶
最大10GB/sスループットを必要とする大量のストリーミングワークロード
データ鮮度が最短5秒程度のリアルタイム分析とダッシュボード
REST APIを使用したIoTとエッジデプロイメント
1回限りの配信保証によるCDC(変更データキャプチャ)パイプライン
Apache Kafka topic ingestion using the Snowflake Connector for Kafka
オープンテーブル形式分析用の Apache Iceberg テーブルへのストリーミング
Snowpipe Streaming 対 Snowpipe¶
SnowpipeストリームはSnowpipeを補完するものであり、Snowpipeの代わりではありません。データが行として到着するシナリオ(例:Apache Kafkaトピック、IoTデバイス、またはアプリケーションイベントから)で、ファイルの代わりにSnowpipe Streamingを使用します。Snowpipe Streamingを使用すると、Snowflakeテーブルにデータをロードするためのファイルを作成する必要がありません。
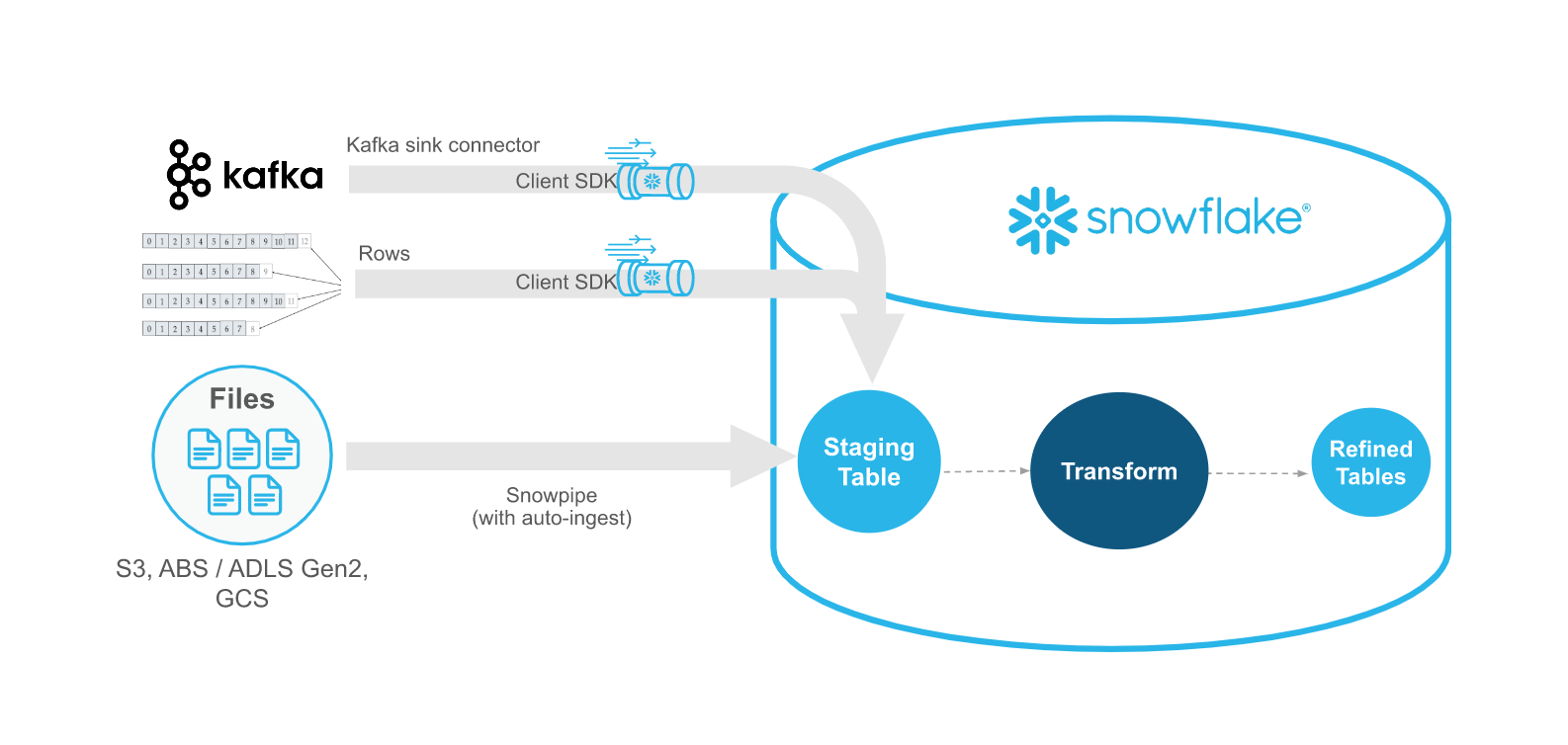
次のテーブルでは、Snowpipe StreamingとSnowpipeの違いについて説明します。
カテゴリ |
Snowpipe Streaming |
Snowpipe |
|---|---|---|
ロードするデータの形式 |
行 |
ファイル。既存のデータパイプラインがBLOBストレージにファイルを生成する場合は、代わりにSnowpipeを使用することをお勧めします。 |
データの順序 |
各チャネル内の順序付き挿入 |
サポート対象外です。Snowpipeは、クラウドストレージのファイル作成タイムスタンプとは異なる順序でファイルからデータをロードできます。 |
ロード履歴 |
SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY ビュー (Account Usage) に記録されたロード履歴。 |
COPY_HISTORY (Account Usage) および COPY_HISTORY 関数 (Information Schema) に記録されたロード履歴。 |
パイプオブジェクト |
PIPEオブジェクトは、すべてのストリーミングインジェスチョンのサーバー側処理レイヤーです。スキーマ検証、進行中の変換、事前クラスタリングを処理します。デフォルトのパイプはテーブルごとに自動的に作成されます。または、高度な処理用にカスタムパイプを作成することもできます。 |
パイプオブジェクトは、ステージングされたファイルデータをキューに入れ、ターゲットテーブルにロードします。 |
このセクションの内容¶
主な概念
**はじめる*
インジェスチョンターゲット
操作
参照情報
従来のアーキテクチャ¶
重要
` Snowflake-ingest-sdk<https://mvnrepository.com/artifact/net.snowflake/snowflake-ingest-sdk>`_ JavaSDKを使用する従来のアーキテクチャは廃止される予定です。直ちに変更する必要はありません。現在のワークロードは引き続き完全にサポートされます。
詳細については、 予定されている廃止の通知 をご参照ください。
従来のアーキテクチャで実行されている既存のワークロードがある場合は、 従来のアーキテクチャ をご参照ください。相違の詳細な比較については、 ハイパフォーマンスと従来のSDKsの比較 をご参照ください。
ハイパフォーマンスアーキテクチャにアップグレードする場合は、 移行ガイド をご参照ください。