Snowflake Connector for Kafka with Snowpipe Streaming classic¶
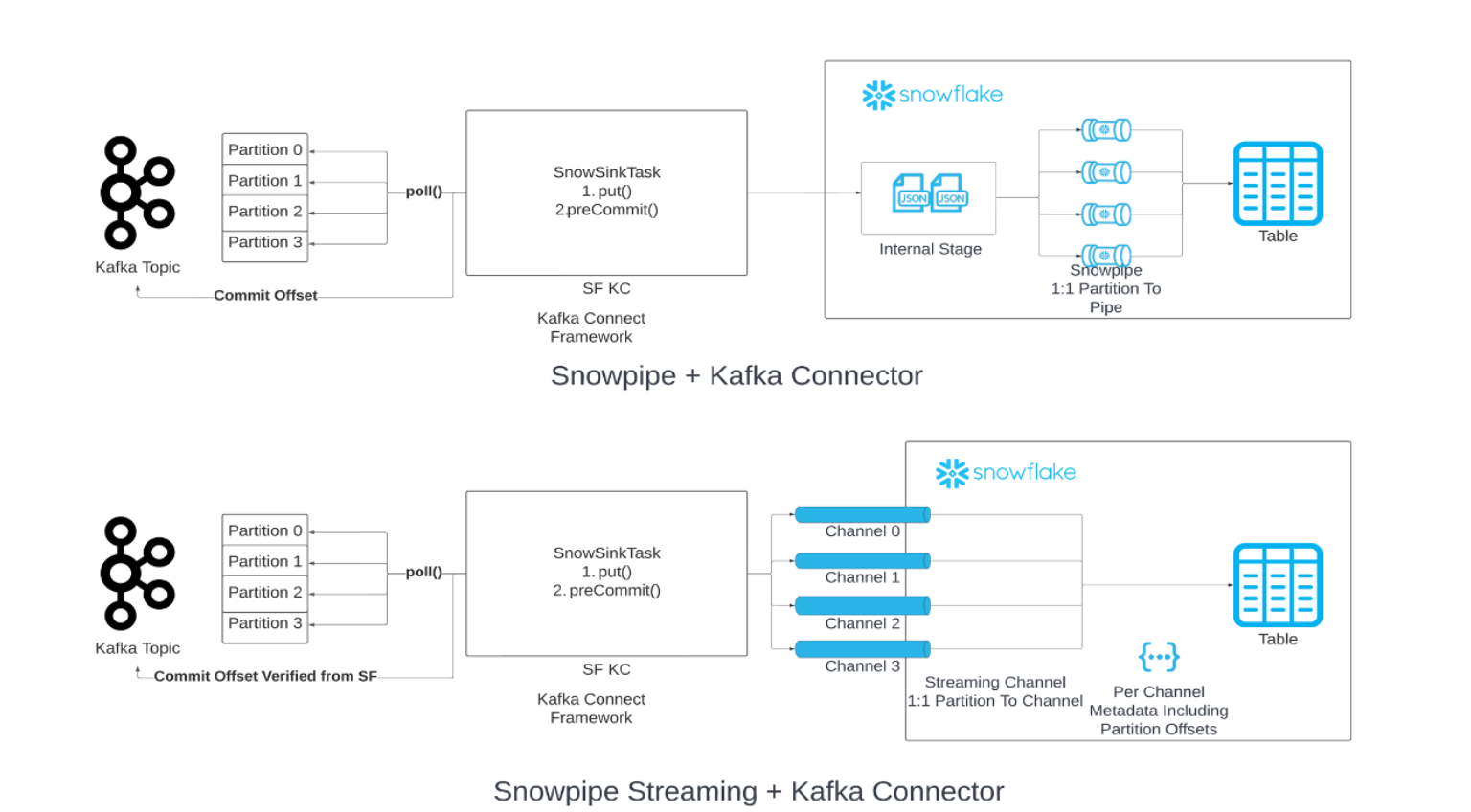
KafkaからのデータのロードチェーンでSnowpipeを Snowpipe Streaming に置き換えることができます。指定されたフラッシュバッファーのしきい値(時間、メモリ、またはメッセージ数)に達すると、コネクタはSnowpipe Streaming API(「API」)を呼び出して、データの行をSnowflakeテーブルに書き込みます。このアーキテクチャにより、ロード遅延が短縮され、同様の量のデータをロードするためのコストが削減されます。
Snowpipe Streaming Classicで使用するには、Kafkaコネクタのバージョン2.0.0(またはそれ以降)が必要です。Snowpipe Streaming ClassicのKafkaコネクタには、Snowflake Ingest SDK が含まれ、Apache Kafkaトピックからターゲットテーブルへの直接ストリーミング行をサポートします。
必要最小バージョン¶
Snowpipe StreamingをサポートするKafkaコネクタの最小必要バージョンは2.0.0です。
Kafka構成プロパティ¶
接続設定をKafkaコネクタのプロパティファイルに保存します。詳細については、 Kafkaコネクタの構成 をご参照ください。
必須のプロパティ¶
Kafkaコネクタのプロパティファイルで接続設定を追加または編集します。詳細については、 Kafkaコネクタの構成 をご参照ください。
snowflake.ingestion.methodストリーミングインジェストクライアントとしてKafkaコネクタを使用する場合にのみ必要です。 Kafkaトピックデータをロードするために、Snowpipe Streamingまたは標準Snowpipeのいずれを使用するかを指定します。サポートされている値は次のとおりです。
SNOWPIPE_STREAMINGSNOWPIPE(デフォルト)
トピックデータをキューに入れてロードするために、バックエンドサービスを選択する追加の設定は必要ありません。通常どおり、Kafkaコネクタのプロパティファイルで追加のプロパティを構成します。
snowflake.role.nameテーブルに行を挿入するときに使用するアクセス制御ロール。
クライアント最適化プロパティ¶
enable.streaming.client.optimizationワンクライアント最適化を有効にするかどうかを指定します。このプロパティは、Kafkaコネクタのリリースバージョン2.1.2以降でサポートされています。デフォルトで有効になっています。
ワンクライアント最適化では、Kafkaコネクタごとに複数のトピックパーティションに対して1つのクライアントのみが作成されます。 この機能により、より大きなファイルを作成することによって、クライアントの実行時間を短縮し、移行コストを削減することができます。
- 値:
truefalse
- デフォルト:
true
高スループットのシナリオ (例: コネクタあたり50 MB/s) でこのプロパティを有効にすると、遅延やコストの上昇につながる可能性があることに注意してください。スループットの高いシナリオでは、このプロパティを無効にすることをお勧めします。
バッファーおよびポーリングのプロパティ¶
buffer.flush.timeバッファーフラッシュ間の秒数。フラッシュごとに、バッファーされた記録の挿入操作が実行されます。Kafkaコネクタは、各フラッシュの後にSnowpipe Streaming API を1回呼び出します。
buffer.flush.timeプロパティでサポートされる最小値は1(秒単位)です。データの平均フローレートを高くするには、遅延を低減するためにデフォルト値を下げることをお勧めします。遅延よりもコストが重要な場合は、バッファーのフラッシュ時間を増やすことができます。メモリ不足の例外を回避するため、バッファーがいっぱいになる前にKafkaメモリバッファーをフラッシュするように注意してください。- 値:
最小:
1最大: 上限なし
- デフォルト:
10
Snowpipe Streamingは自動的に1秒ごとにデータをフラッシュしますが、これはKafkaコネクタのバッファフラッシュ時間とは異なることに注意してください。Kafkaバッファのフラッシュ時間に達した後、データはSnowpipe Streamingを通じてSnowflakeに1秒の遅延で送信されます。詳細については、 Snowpipe Streamingの遅延 をご参照ください。
buffer.count.recordsSnowflakeにインジェストされる前に、Kafkaパーティションごとにメモリにバッファされる記録の数。
- 値:
最小:
1最大: 上限なし
- デフォルト:
10000
buffer.size.bytesデータファイルとしてSnowflakeに取り込まれる前に、Kafkaパーティションごとにメモリーにバッファーされたレコードの累積サイズ(バイト単位)。
レコードは、データファイルに書き込まれるときに圧縮されます。その結果、バッファー内のレコードのサイズは、レコードから作成されたデータファイルのサイズよりも大きくなる可能性があります。
- 値:
最小:
1最大: 上限なし
- デフォルト:
20000000(20 MB)
snowflake.streaming.max.client.lagSnowflake Ingest Java がSnowflakeにデータをフラッシュする頻度を秒単位で指定します。
値を低くするとレイテンシーは低く保たれますが、特に
snowflake.streaming.enable.single.bufferが有効な場合、クエリのパフォーマンスが悪化する可能性があります。詳細情報については、 Snowpipe Streamingの推奨レイテンシー構成 を参照してください。- 値:
最小:
1秒最大:
600秒
- デフォルト:
バージョン 3.1.1 以降は
30秒、バージョン 3.0.0 および 3.1.0 は120秒、それ以外は1秒
snowflake.streaming.enable.single.bufferSnowpipe Streamingのシングルバッファを有効にして、コネクタの内部バッファでのデータのバッファリングをスキップするかどうかを指定します。
このプロパティは、Kafkaコネクタのバージョン2.3.1以降でサポートされています。
ストリーミングコネクターは、 Snowflake Ingest Java によって提供されるものと一緒に内部バッファを使用します。このプロパティを
trueに設定すると、Kafkaコネクタは低レイテンシを実現するために内部バッファをスキップします。このプロパティを
trueに設定すると、buffer.flush.timeとbuffer.count.recordsは無関係になることに注意してください。- 値:
truefalse
- デフォルト:
バージョン3.0.0以降の場合は
true、それ以外の場合はfalse
Kafkaコネクタのプロパティに加えて、Kafkaコンシューマー max.poll.records のプロパティに注意してください。これは、1回のポーリングでKafkaからKafka Connectに返される記録の最大数を制御します。500 のデフォルト値は増やすことができますが、メモリの制約に注意してください。このプロパティの詳細については、Kafkaパッケージのドキュメントをご参照ください。
エラー処理および DLQ プロパティ¶
errors.toleranceKafkaコネクタで発生したエラーの処理方法を指定します。
このプロパティは、次の値をサポートします。
- 値:
NONE: 最初のエラーが発生したときにデータのロードを停止します。ALL: すべてのエラーを無視して、データのロードを続行します。
- デフォルト:
NONE
errors.log.enableKafka Connectログファイルにエラーメッセージを書き込むかどうかを指定します。
このプロパティは、次の値をサポートします。
- 値:
TRUE: エラーメッセージを書き込みます。FALSE: エラーメッセージを書き込みません。
- デフォルト:
FALSE
errors.deadletterqueue.topic.nameSnowflakeテーブルにインジェストできなかったメッセージをKafkaに配信するために、Kafkaの DLQ (配信不能キュー) トピック名を指定します。詳細については、 配信不能キュー (このトピック内)をご参照ください。
- 値:
カスタムテキスト文字列
- デフォルト:
なし
必ず1回のセマンティクス¶
必ず1回のセマンティクスにより、重複やデータ損失なしでKafkaメッセージの配信が保証されます。この配信保証は、Snowpipe Streamingを使用するKafkaコネクタに対してデフォルトで設定されています。
Kafkaコネクタは、パーティションとチャネル間の1対1マッピングを採用し、2つの異なるオフセットを使用します。
コンシューマーオフセット: これは、コンシューマーによって消費された最新のオフセットを追跡し、Kafkaによって管理されます。
オフセットトークン: これは、Snowflakeでコミットされた最新のオフセットを追跡し、Snowflakeによって管理されます。
Kafka コネクタは、オフセットの欠落を常に処理するわけではないことに注意してください。Snowflakeは、すべての記録が順次増加するオフセットを持つことを期待しています。オフセットの欠落は、特定のユースケースにおいてKafkaコネクタを破壊します。NULL の記録ではなく、tombstoneの記録を使用することをお勧めします。
Kafkaコネクタは、次のベストプラクティスを実装することで、1回限りの配信を実現します。
チャネルの開始/再開:
特定のパーティションのチャネルを開始したり、再開したりする場合、Kafkaコネクタは、
getLatestCommittedOffsetTokenAPI を通じてSnowflakeから取得した、最新のコミットされたオフセットトークンを信頼できる情報源として使用し、それに応じてKafkaのコンシューマーオフセットをリセットします。コンシューマーオフセットがデータ保持期間内にない場合は、例外がスローされ、実行する適切なアクションを決定できます。
KafkaコネクタがKafkaのコンシューマーオフセットをリセットせず、それを信頼できる情報源として使用する唯一のシナリオは、Snowflakeからのオフセットトークンが NULL である場合です。この場合、コネクタはKafkaによって送信されたオフセットを受け入れ、その後オフセットトークンが更新されます。
記録の処理:
Kafkaの潜在的なバグによって発生する可能性のある非連続オフセットに対する追加の安全層を確保するために、Snowflakeは最新の処理されたオフセットを追跡するメモリ内変数を維持します。Snowflakeは、現在の行のオフセットが、最後に処理されたオフセットに1を加えた値に等しい場合にのみ行を受け入れます。これにより、インジェスチョンプロセスが継続的かつ正確であることを保証するための追加の保護層が得られます。
例外、障害、クラッシュ復旧への対処:
復旧プロセスの一環として、Snowflakeは、チャネルを再開し、最新のコミットされたオフセットトークンを使用してコンシューマーオフセットをリセットすることにより、前に概説したチャネルの開始/再開ロジックを一貫して遵守します。これにより、Snowflakeは、コミットされた最新のオフセットトークンより1つ大きいオフセット値からデータを送信するようKafkaに通知し、データ損失をまったく発生させずに、障害発生時点からインジェスチョンを再開できるようになります。
再試行メカニズムの実装:
潜在的な一時的問題に対処するために、Snowflakeには API 呼び出しに再試行メカニズムが組み込まれています。Snowflakeは、成功の可能性を高め、インジェスチョンプロセスに影響を与える断続的な障害のリスクを軽減するために、これらの API 呼び出しを複数回再試行します。
コンシューマーオフセットの提出:
Snowflakeは、一定の間隔で、最新のコミットされたオフセットトークンを使用してコンシューマーオフセットを提出し、インジェスチョンプロセスが確実にSnowflake内のデータの最新状態と継続的に一致するようにします。
コンバーター¶
Snowpipe Streamingは、以下のような多くのコミュニティベースのコンバーターをサポートしています。
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverterio.confluent.connect.protobuf.ProtobufConverterio.confluent.connect.json.JsonSchemaConverterorg.apache.kafka.connect.converters.ByteArrayConverterorg.apache.kafka.connect.storage.StringConverter
その他のコミュニティベースのコンバーターもサポートされるかもしれませんが、検証されていません。SnowflakeコンバーターはSnowpipe Streamingではサポートされていません。
配信不能キュー¶
Snowpipe Streamingを使用するKafkaコネクタは、壊れた記録または障害のために正常に処理できない記録の配信不能キュー(DLQ)をサポートしています。
モニタリングの詳細については、Apache Kafkaの ドキュメント をご参照ください。
スキーマ検出およびスキーマ進化¶
Snowpipe Streamingを使用したKafkaコネクタは、スキーマ検出および進化をサポートしています。Snowflakeのテーブルの構造を自動的に定義して進化させ、Kafkaコネクタによりロードされた新しいSnowpipe Streamingデータの構造をサポートすることができます。Snowpipe Streamingを使用したKafkaコネクタのスキーマ検出と進化を有効にするには、以下のKafkaプロパティを構成します。
snowflake.ingestion.methodsnowflake.enable.schematizationschema.registry.url
詳細については、 Schema detection and evolution for Kafka connector with Snowpipe Streaming classic をご参照ください。
インジェスチョンレイテンシの推定¶
インジェストレイテンシを見積もるには、 RECORD_METADATA の SnowflakeConnectorPushTime フィールドを使用します。このタイムスタンプは、記録がインジェスト SDK バッファにプッシュされた時点を表します。
RECORD_METADATA フォーマットの詳細については、 Kafkaトピックのテーブルのスキーマ をご参照ください。
注釈
このフィールドは、設定された Snowpipeストリーミングレイテンシ を考慮しないため、記録がSnowflakeテーブルに表示されるようになったタイミングを表す ものではありません。
請求および使用状況¶
Snowpipe Streamingの課金情報については、 Snowpipe Streaming Classicのコスト をご参照ください。
制限事項¶
Snowpipe Streamingの制限¶
Snowpipe Streamingの制限 をご参照ください。
フェールオーバーの制限¶
セカンダリフェールオーバーグループがプライマリに昇格すると、 Snowpipe Streamingを使用するKafkaコネクタで手動の操作が必要になります。必ず1回のセマンティクスは保持されたままになります。
enable.streaming.client.optimization プロパティが false に設定されている場合、Kafkaコネクタを再起動する必要があります。コネクタを再起動すると、新しいプライマリデプロイがターゲットになります。
enable.streaming.client.optimization プロパティが true に設定されている場合、コネクタが実行されているホスト JVM をシャットダウンして再起動する必要があります。ホスト JVM を再起動すると、新しく起動されたKafkaコネクタでは新しいプライマリデプロイがターゲットになります。