分類(SnowflakeML関数)
分類は、機械学習アルゴリズムを使用して、トレーニングデータから検出されたパターンを使用してデータを異なるクラスに分類します。バイナリ分類(2つのクラス)とマルチクラス分類(2つ以上のクラス)がサポートされています。分類の一般的なユースケースとしては、顧客のチャーン予測、クレジットカード詐欺の検出、スパムの検出などがあります。
注釈
分類は、機械学習を活用したSnowflakeのビジネス分析ツールスイートの一部です。
分類には、トレーニングデータへの参照を渡して分類モデルオブジェクトを作成することが含まれます。モデルは提供されたトレーニングデータに適合されます。次に、スキーマレベルの分類モデルオブジェクトを使用して、新しいデータポイントを分類し、評価 APIs を通してモデルの精度を理解します。
分類モデルについて
Snowflake Cortexの分類関数は、 勾配ブースティングマシン を使用します。二項分類の場合、モデルは 曲線下面積 損失関数を用いてトレーニングされます。マルチクラス分類の場合、モデルは ロジスティック損失 関数を用いてトレーニングされます。
分類に使用するのに適したトレーニングデータセットには、各データポイントのラベル付けされたクラスを表すターゲット列と、少なくとも1つの特徴列が含まれます。
分類モデルは、特徴量とラベルについて、数値、ブール、文字列のデータ型をサポートしています。
数値機能は連続として扱われます。数値特徴量をカテゴリとして扱うには、文字列にキャストします。
文字列機能はカテゴリとして扱われます。分類機能は、高カーディナリティ機能(例えば、職種や果物)をサポートします。文章や段落のような完全なフリーテキストには対応していません。
ブール機能はカテゴリとして扱われます。
タイムスタンプは TIMESTAMP_NTZ SHOW_FEATURE_IMPORTANCE derived_features
ラベル列のカーディナリティは1より大きく、データセットの行数より小さいものである必要があります。
推論データはトレーニングデータと同じ特徴名とタイプでなければなりません。カテゴリ特徴量にトレーニングデータセットに存在しない値があってもエラーではありません。トレーニングデータセットに存在しない推論データの列は無視されます。
分類モデルは予測の質を評価できます。評価プロセスでは、元のデータに対して追加のモデルを学習しますが、その際いくつかのデータポイントは除外されます。保留されたデータポイントは推論に使用され、予測されたクラスが実際のクラスと比較されます。
現在の制限
トレーニングデータと推論データは、数値、TIMESTAMP_NTZ、ブール値、または文字列である必要があります。その他の型は、これらの型のいずれかにキャストする必要があります。
分類アルゴリズムの選択や変更はできません。
モデルのパラメーターを手動で指定または調整することはできません。
テストでは、Medium Snowparkに最適化されたウェアハウスでのトレーニングが、最大1,000列、6億行で成功しました。この制限を下回ってメモリ不足になる可能性はありますが、その可能性は低いといえます。
対象となる列に含めるクラスは、255個以下である必要があります。
SNOWFLAKE.ML.CLASSIFICATION インスタンスはクローンできません。分類モデルを含むデータベースをクローンまたは複製すると、そのモデルは現在スキップされます。
分類の準備
分類を使用する前に、次を行う必要があります。
また、 SNOWFLAKE.ML スキーマを含めるために、 検索パスを変更
仮想ウェアハウスの選択
Snowflake 仮想ウェアハウス
トレーニングデータのサイズに基づいてウェアハウスタイプを選択する必要があります。標準ウェアハウスは、Snowpark のメモリ制限が低く、行数や機能が少ないプロトタイピングに適しています。標準ウェアハウスのメモリ制限は、ウェアハウスの大きさによって増えることはありません。
行数や機能数が増えるにつれて、トレーニングが成功するようにSnowparkに最適化されたウェアハウスの使用を検討してください。Snowparkに最適化されたウェアハウスのメモリ制限は、Medium以上には増加しません。
最高のパフォーマンスを得るために、モデルのトレーニングには他のワークロードが同時に発生しない専用ウェアハウスを使用することをSnowflakeは推奨します。
コストを最小限に抑えるため、プロトタイピングにはX-Small標準ウェアハウスの使用をお勧めします。もっと大きなデータセットや本番ワークロードには、Medium Snowparkに最適化されたウェアハウスを使用してください。
分類モデル作成権限の付与
予測モデルをトレーニングすると、スキーマレベルのオブジェクトが得られます。したがって、モデルの作成に使用するロールには、モデルが作成されるスキーマ上で CREATE SNOWFLAKE.ML.CLASSIFICATION 権限があり、そこにモデルを格納できるようにする必要があります。この権限は CREATE TABLE や CREATE VIEW のような他のスキーマ権限と類似しています。
Snowflakeは、 analyst
以下の例では、 admin admin_db.admin_schema analyst
USE ROLE admin ;
GRANT USAGE ON DATABASE admin_db TO ROLE analyst ;
GRANT USAGE ON SCHEMA admin_schema TO ROLE analyst ;
GRANT CREATE SNOWFLAKE.ML.CLASSIFICATION ON SCHEMA admin_db . admin_schema TO ROLE analyst ;
このスキーマを使用するには、ユーザーは analyst
USE ROLE analyst ;
USE SCHEMA admin_db . admin_schema ;
analyst analyst_db analyst_db.analyst_schema
USE ROLE analyst ;
CREATE SCHEMA analyst_db . analyst_schema ;
USE SCHEMA analyst_db . analyst_schema ;
スキーマに対するロールのモデル作成権限を取り消すには、 REVOKE <権限> ... FROM ROLE
REVOKE CREATE SNOWFLAKE.ML.CLASSIFICATION ON SCHEMA admin_db . admin_schema FROM ROLE analyst ;
モデルのトレーニング、使用、表示、削除、更新
注釈
SNOWFLAKE.ML.CLASSIFICATION は制限された権限で実行されるため、デフォルトではご使用のデータにアクセスできません。そのため、テーブルとビューを 参照 クエリ参照
トレーニング、推論、評価 APIs については、 CLASSIFICATION リファレンス
CREATE SNOWFLAKE.ML.CLASSIFICATION を使用してモデルを作成し、トレーニングします。
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION < model_name >(...);
データセットに対して推論(予測)を実行するには、モデルの PREDICT メソッドを使用します。
SELECT < model_name >! PREDICT (...);
モデルを評価するには、提供されている評価メソッドを呼び出します。
CALL < model_name >! SHOW_EVALUATION_METRICS ();
CALL < model_name >! SHOW_GLOBAL_EVALUATION_METRICS ();
CALL < model_name >! SHOW_THRESHOLD_METRICS ();
CALL < model_name >! SHOW_CONFUSION_MATRIX ();
モデルの特徴重要度ランキングを表示するには、その SHOW_FEATURE_IMPORTANCE メソッドを呼び出します。
CALL < model_name >! SHOW_FEATURE_IMPORTANCE ();
トレーニング中に生成されたログを調査するには、 SHOW_TRAINING_LOGS メソッドを使用します。トレーニングログがない場合、この呼び出しはNULLを返します。
CALL < model_name >! SHOW_TRAINING_LOGS ();
Tip
これらのメソッドの使用例については、 例
すべての分類モデルを表示するには、 SHOW コマンドを使用します。
SHOW SNOWFLAKE.ML.CLASSIFICATION ;
分類モデルを削除するには、 DROP コマンドを使用します。
DROP SNOWFLAKE.ML.CLASSIFICATION < model_name >;
モデルは不変であり、導入状態で更新することはできません。モデルを更新するには、既存のモデルをドロップし、新しいモデルをトレーニングします。CREATE コマンドの CREATE OR REPLACE バリアントはこの目的に便利です。
例
例に対するデータの設定
このトピックの例では、2つのテーブルを使用します。最初のテーブル training_purchase_data prediction_purchase_data
CREATE OR REPLACE TABLE training_purchase_data AS (
SELECT
CAST ( UNIFORM ( 0 , 4 , RANDOM ()) AS VARCHAR ) AS user_interest_score ,
UNIFORM ( 0 , 3 , RANDOM ()) AS user_rating ,
FALSE AS label ,
'not_interested' AS class
FROM TABLE ( GENERATOR ( rowCount => 100 ))
UNION ALL
SELECT
CAST ( UNIFORM ( 4 , 7 , RANDOM ()) AS VARCHAR ) AS user_interest_score ,
UNIFORM ( 3 , 7 , RANDOM ()) AS user_rating ,
FALSE AS label ,
'add_to_wishlist' AS class
FROM TABLE ( GENERATOR ( rowCount => 100 ))
UNION ALL
SELECT
CAST ( UNIFORM ( 7 , 10 , RANDOM ()) AS VARCHAR ) AS user_interest_score ,
UNIFORM ( 7 , 10 , RANDOM ()) AS user_rating ,
TRUE AS label ,
'purchase' AS class
FROM TABLE ( GENERATOR ( rowCount => 100 ))
);
CREATE OR REPLACE table prediction_purchase_data AS (
SELECT
CAST ( UNIFORM ( 0 , 4 , RANDOM ()) AS VARCHAR ) AS user_interest_score ,
UNIFORM ( 0 , 3 , RANDOM ()) AS user_rating
FROM TABLE ( GENERATOR ( rowCount => 100 ))
UNION ALL
SELECT
CAST ( UNIFORM ( 4 , 7 , RANDOM ()) AS VARCHAR ) AS user_interest_score ,
UNIFORM ( 3 , 7 , RANDOM ()) AS user_rating
FROM TABLE ( GENERATOR ( rowCount => 100 ))
UNION ALL
SELECT
CAST ( UNIFORM ( 7 , 10 , RANDOM ()) AS VARCHAR ) AS user_interest_score ,
UNIFORM ( 7 , 10 , RANDOM ()) AS user_rating
FROM TABLE ( GENERATOR ( rowCount => 100 ))
);
二値分類子のトレーニングと使用
まず、トレーニング用のバイナリデータを含むビューを作成します。
CREATE OR REPLACE view binary_classification_view AS
SELECT user_interest_score , user_rating , label
FROM training_purchase_data ;
SELECT * FROM binary_classification_view ORDER BY RANDOM ( 42 ) LIMIT 5 ;
SELECT ステートメントは、次のような形式で結果を返します。
+---------------------+-------------+-------+
| USER_INTEREST_SCORE | USER_RATING | LABEL |
|---------------------+-------------+-------|
| 5 | 4 | False |
| 8 | 8 | True |
| 6 | 5 | False |
| 7 | 7 | True |
| 7 | 4 | False |
+---------------------+-------------+-------+
このビューを使用して、二項分類モデルを作成し、トレーニングします。
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model_binary (
INPUT_DATA => SYSTEM$REFERENCE ( 'view' , 'binary_classification_view' ),
TARGET_COLNAME => 'label'
);
モデルを作成したら、その PREDICT メソッドを使用して、ラベルのない購買データのラベルを推測します。 オブジェクトリテラルでワイルドカード拡張
SELECT model_binary ! PREDICT ( INPUT_DATA => {*})
AS prediction FROM prediction_purchase_data ;
このモデルは次のような形式で出力を返します。予測オブジェクトには、各クラスの予測確率と、最大予測確率に基づく予測クラスが含まれます。予測値は、元の特徴量が提供されたのと同じ順序で返されます。
+-------------------------------------+
| PREDICTION |
|-------------------------------------|
| { |
| "class": "True", |
| "logs": null, |
| "probability": { |
| "False": 1.828038600000000e-03, |
| "True": 9.981719614000000e-01 |
| } |
| } |
| { |
| "class": "False", |
| "logs": null, |
| "probability": { |
| "False": 9.992944771000000e-01, |
| "True": 7.055229000000000e-04 |
| } |
| } |
| { |
| "class": "True", |
| "logs": null, |
| "probability": { |
| "False": 3.429796010000000e-02, |
| "True": 9.657020399000000e-01 |
| } |
| } |
| { |
| "class": "False", |
| "logs": null, |
| "probability": { |
| "False": 9.992687686000000e-01, |
| "True": 7.312314000000000e-04 |
| } |
| } |
| { |
| "class": "False", |
| "logs": null, |
| "probability": { |
| "False": 9.992951615000000e-01, |
| "True": 7.048385000000000e-04 |
| } |
| } |
+-------------------------------------+
特徴量と予測値をまとめるには、以下のようなクエリーを使用します。
SELECT *, model_binary ! PREDICT ( INPUT_DATA => {*})
AS predictions FROM prediction_purchase_data ;
+---------------------+-------------+-------------------------------------+
| USER_INTEREST_SCORE | USER_RATING | PREDICTIONS |
|---------------------+-------------+-------------------------------------|
| 9 | 8 | { |
| | | "class": "True", |
| | | "logs": null, |
| | | "probability": { |
| | | "False": 1.828038600000000e-03, |
| | | "True": 9.981719614000000e-01 |
| | | } |
| | | } |
| 3 | 0 | { |
| | | "class": "False", |
| | | "logs": null, |
| | | "probability": { |
| | | "False": 9.992944771000000e-01, |
| | | "True": 7.055229000000000e-04 |
| | | } |
| | | } |
| 10 | 7 | { |
| | | "class": "True", |
| | | "logs": null, |
| | | "probability": { |
| | | "False": 3.429796010000000e-02, |
| | | "True": 9.657020399000000e-01 |
| | | } |
| | | } |
| 6 | 6 | { |
| | | "class": "False", |
| | | "logs": null, |
| | | "probability": { |
| | | "False": 9.992687686000000e-01, |
| | | "True": 7.312314000000000e-04 |
| | | } |
| | | } |
| 1 | 3 | { |
| | | "class": "False", |
| | | "logs": null, |
| | | "probability": { |
| | | "False": 9.992951615000000e-01, |
| | | "True": 7.048385000000000e-04 |
| | | } |
| | | } |
+---------------------+-------------+-------------------------------------+
マルチクラス分類器のトレーニングと使用
トレーニング用のバイナリデータを含むビューを作成します。
CREATE OR REPLACE VIEW multiclass_classification_view AS
SELECT user_interest_score , user_rating , class
FROM training_purchase_data ;
SELECT * FROM multiclass_classification_view ORDER BY RANDOM ( 42 ) LIMIT 10 ;
この SELECT ステートメントは、次のような形式で結果を返します。
+---------------------+-------------+-----------------+
| USER_INTEREST_SCORE | USER_RATING | CLASS |
|---------------------+-------------+-----------------|
| 5 | 4 | add_to_wishlist |
| 8 | 8 | purchase |
| 6 | 5 | add_to_wishlist |
| 7 | 7 | purchase |
| 7 | 4 | add_to_wishlist |
| 1 | 1 | not_interested |
| 2 | 1 | not_interested |
| 7 | 3 | add_to_wishlist |
| 2 | 0 | not_interested |
| 0 | 1 | not_interested |
+---------------------+-------------+-----------------+
このビューからマルチクラス分類モデルを作成します。
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model_multiclass (
INPUT_DATA => SYSTEM$REFERENCE ( 'view' , 'multiclass_classification_view' ),
TARGET_COLNAME => 'class'
);
モデルを作成したら、その PREDICT メソッドを使用して、ラベルのない購買データのラベルを推測します。INPUT_DATA 引数のキーと値のペアを自動的に作成するには、 オブジェクトリテラルでワイルドカード拡張
SELECT *, model_multiclass ! PREDICT ( INPUT_DATA => {*})
AS predictions FROM prediction_purchase_data ;
このモデルは次のような形式で出力を返します。予測オブジェクトには、各クラスの予測確率と、最大予測確率に基づく予測クラスが含まれます。予測は、提供された元の特徴量と同じ順序で返され、同じクエリで結合することができます。
+---------------------+-------------+-----------------------------------------------+
| USER_INTEREST_SCORE | USER_RATING | PREDICTIONS |
|---------------------+-------------+-----------------------------------------------|
| 9 | 8 | { |
| | | "class": "purchase", |
| | | "logs": null, |
| | | "probability": { |
| | | "add_to_wishlist": 3.529288000000000e-04, |
| | | "not_interested": 2.259768000000000e-04, |
| | | "purchase": 9.994210944000000e-01 |
| | | } |
| | | } |
| 3 | 0 | { |
| | | "class": "not_interested", |
| | | "logs": null, |
| | | "probability": { |
| | | "add_to_wishlist": 3.201690000000000e-04, |
| | | "not_interested": 9.994749885000000e-01, |
| | | "purchase": 2.048425000000000e-04 |
| | | } |
| | | } |
| 10 | 7 | { |
| | | "class": "purchase", |
| | | "logs": null, |
| | | "probability": { |
| | | "add_to_wishlist": 1.271809310000000e-02, |
| | | "not_interested": 3.992673600000000e-03, |
| | | "purchase": 9.832892333000000e-01 |
| | | } |
| | | } |
| 6 | 6 | { |
| | | "class": "add_to_wishlist", |
| | | "logs": null, |
| | | "probability": { |
| | | "add_to_wishlist": 9.999112027000000e-01, |
| | | "not_interested": 4.612520000000000e-05, |
| | | "purchase": 4.267210000000000e-05 |
| | | } |
| | | } |
| 1 | 3 | { |
| | | "class": "not_interested", |
| | | "logs": null, |
| | | "probability": { |
| | | "add_to_wishlist": 2.049559150000000e-02, |
| | | "not_interested": 9.759854413000000e-01, |
| | | "purchase": 3.518967300000000e-03 |
| | | } |
| | | } |
+---------------------+-------------+-----------------------------------------------+
結果をテーブルに保存して、予測を詳しく調べる
モデルの PREDICT メソッドの呼び出しの結果は、クエリに直接読み込むことができますが、結果をテーブルに保存することで予測を都合に合わせて調べることができます。
CREATE OR REPLACE TABLE my_predictions AS
SELECT *, model_multiclass ! PREDICT ( INPUT_DATA => {*}) AS predictions FROM prediction_purchase_data ;
SELECT * FROM my_predictions ;
キー列と予測列は、さらにクエリして探索することができます。以下のクエリは、予測を詳しく調べます。
SELECT
predictions :class AS predicted_class ,
ROUND ( predictions :probability:not_interested , 4 ) AS not_interested_class_probability ,
ROUND ( predictions [ 'probability' ][ 'purchase' ], 4 ) AS purchase_class_probability ,
ROUND ( predictions [ 'probability' ][ 'add_to_wishlist' ], 4 ) AS add_to_wishlist_class_probability
FROM my_predictions
LIMIT 5 ;
上記のクエリは、次のような形式で結果を返します。
+-------------------+----------------------------------+----------------------------+-----------------------------------+
| PREDICTED_CLASS | NOT_INTERESTED_CLASS_PROBABILITY | PURCHASE_CLASS_PROBABILITY | ADD_TO_WISHLIST_CLASS_PROBABILITY |
|-------------------+----------------------------------+----------------------------+-----------------------------------|
| "purchase" | 0.0002 | 0.9994 | 0.0004 |
| "not_interested" | 0.9995 | 0.0002 | 0.0003 |
| "purchase" | 0.0002 | 0.9994 | 0.0004 |
| "purchase" | 0.0002 | 0.9994 | 0.0004 |
| "not_interested" | 0.9994 | 0.0002 | 0.0004 |
| "purchase" | 0.0002 | 0.9994 | 0.0004 |
| "add_to_wishlist" | 0 | 0 | 0.9999 |
| "add_to_wishlist" | 0.4561 | 0.0029 | 0.5409 |
| "purchase" | 0.0002 | 0.9994 | 0.0004 |
| "not_interested" | 0.9994 | 0.0002 | 0.0003 |
+-------------------+----------------------------------+----------------------------+-----------------------------------+
評価関数の使用
デフォルトでは、評価はすべてのインスタンスで有効になっています。ただし、構成オブジェクトの引数を使えば、評価を手動で有効または無効にできます。キー「evaluate」に値 FALSE が指定されている場合、評価は使用できません。
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model (
INPUT_DATA => SYSTEM$REFERENCE ( 'view' , 'binary_classification_view' ),
TARGET_COLNAME => 'label' ,
CONFIG_OBJECT => { 'evaluate' : TRUE }
);
評価を有効にすると、ここに表示される評価 APIs を使用して評価指標を取得できます。
CALL model ! SHOW_EVALUATION_METRICS ();
CALL model ! SHOW_GLOBAL_EVALUATION_METRICS ();
CALL model ! SHOW_THRESHOLD_METRICS ();
CALL model ! SHOW_CONFUSION_MATRIX ();
返される指標の説明については 評価指標の理解
マルチクラスモデルの評価メトリクスは以下の通りです。
CALL model_multiclass ! SHOW_EVALUATION_METRICS ();
+--------------+-----------------+--------------+---------------+------+
| DATASET_TYPE | CLASS | ERROR_METRIC | METRIC_VALUE | LOGS |
|--------------+-----------------+--------------+---------------+------|
| EVAL | add_to_wishlist | precision | 0.8888888889 | NULL |
| EVAL | add_to_wishlist | recall | 1 | NULL |
| EVAL | add_to_wishlist | f1 | 0.9411764706 | NULL |
| EVAL | add_to_wishlist | support | 16 | NULL |
| EVAL | not_interested | precision | 1 | NULL |
| EVAL | not_interested | recall | 0.9090909091 | NULL |
| EVAL | not_interested | f1 | 0.9523809524 | NULL |
| EVAL | not_interested | support | 22 | NULL |
| EVAL | purchase | precision | 1 | NULL |
| EVAL | purchase | recall | 1 | NULL |
| EVAL | purchase | f1 | 1 | NULL |
| EVAL | purchase | support | 22 | NULL |
+--------------+-----------------+--------------+---------------+------+
CALL model_multiclass ! SHOW_GLOBAL_EVALUATION_METRICS ();
+--------------+--------------+--------------+---------------+------+
| DATASET_TYPE | AVERAGE_TYPE | ERROR_METRIC | METRIC_VALUE | LOGS |
|--------------+--------------+--------------+---------------+------|
| EVAL | macro | precision | 0.962962963 | NULL |
| EVAL | macro | recall | 0.9696969697 | NULL |
| EVAL | macro | f1 | 0.964519141 | NULL |
| EVAL | macro | auc | 0.9991277911 | NULL |
| EVAL | weighted | precision | 0.9703703704 | NULL |
| EVAL | weighted | recall | 0.9666666667 | NULL |
| EVAL | weighted | f1 | 0.966853408 | NULL |
| EVAL | weighted | auc | 0.9991826156 | NULL |
| EVAL | NULL | log_loss | 0.06365200147 | NULL |
+--------------+--------------+--------------+---------------+------+
CALL model_multiclass ! SHOW_CONFUSION_MATRIX ();
+--------------+-----------------+-----------------+-------+------+
| DATASET_TYPE | ACTUAL_CLASS | PREDICTED_CLASS | COUNT | LOGS |
|--------------+-----------------+-----------------+-------+------|
| EVAL | add_to_wishlist | add_to_wishlist | 16 | NULL |
| EVAL | add_to_wishlist | not_interested | 0 | NULL |
| EVAL | add_to_wishlist | purchase | 0 | NULL |
| EVAL | not_interested | add_to_wishlist | 2 | NULL |
| EVAL | not_interested | not_interested | 20 | NULL |
| EVAL | not_interested | purchase | 0 | NULL |
| EVAL | purchase | add_to_wishlist | 0 | NULL |
| EVAL | purchase | not_interested | 0 | NULL |
| EVAL | purchase | purchase | 22 | NULL |
+--------------+-----------------+-----------------+-------+------+
また、機能の重要性をレビューすることもできます。
CALL model_multiclass ! SHOW_FEATURE_IMPORTANCE ();
+------+---------------------+---------------+---------------+
| RANK | FEATURE | SCORE | FEATURE_TYPE |
|------+---------------------+---------------+---------------|
| 1 | USER_RATING | 0.9186571982 | user_provided |
| 2 | USER_INTEREST_SCORE | 0.08134280181 | user_provided |
+------+---------------------+---------------+---------------+
モデルロールと使用権限
各分類モデルインスタンスには、 mladmin mlconsumer model!mladmin model!mlconsumer model!mladmin model!mlconsumer
mladmin mlconsumer
以下の SQL 例は、分類モデルのロールを他のロールに付与する例を示しています。 r1 r2 mlconsumer r2 r3 r1 mladmin r3
まず、ロール r1 r1 model
USE ROLE r1 ;
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION model (
INPUT_DATA => SYSTEM$REFERENCE ( 'TABLE' , 'test_classification_dataset' ),
TARGET_COLNAME => 'LABEL'
);
以下のステートメントを実行すると、ロール r2
USE ROLE r2 ;
SELECT model ! PREDICT ( 1 ); -- privilege error
次に、 r1 r2 mlconsumer r2
USE ROLE r1 ;
GRANT SNOWFLAKE.ML.CLASSIFICATION ROLE model ! mlconsumer TO ROLE r2 ;
USE ROLE r2 ;
CALL model ! PREDICT (
INPUT_DATA => system$query_reference (
'SELECT {*} FROM test_classification_dataset' )
);
同様に、 r3 mladmin
USE ROLE r3 ;
CALL model ! SHOW_EVALUATION_METRICS (); -- privilege error
ロール r1 r3 r3
USE ROLE r1 ;
GRANT SNOWFLAKE.ML.CLASSIFICATION ROLE model ! mladmin TO ROLE r3 ;
USE ROLE r3 ;
CALL model ! SHOW_EVALUATION_METRICS ();
以下のように権限を取り消すことができます。
USE ROLE r1 ;
REVOKE SNOWFLAKE.ML.CLASSIFICATION ROLE model ! mlconsumer FROM ROLE r2 ;
REVOKE SNOWFLAKE.ML.CLASSIFICATION ROLE model ! mladmin FROM ROLE r3 ;
以下のコマンドを使用して、どのアカウントロールとデータベースロールにこれらのインスタンスロールが付与されているかを確認します。
SHOW GRANTS TO SNOWFLAKE.ML.CLASSIFICATION ROLE < model_name >! mladmin ;
SHOW GRANTS TO SNOWFLAKE.ML.CLASSIFICATION ROLE < model_name >! mlconsumer ;
評価指標の理解
指標は、モデルがどれだけ正確に新しいデータを予測するかを測定します。現在、Snowflake分類はデータセット全体からランダムにサンプルを選択してモデルを評価しています。これらの行を除いた新しいモデルがトレーニングされ、その行が推論入力として使用されます。ランダムのサンプル部分は EVALUATION_CONFIG オブジェクトの test_fraction
show_evaluation_metrics show_evaluation_metrics SHOW_EVALUATION_METRICS
上記の値を使用して、各クラスについて以下の指標が報告されます。各指標では、値が大きいほど予測性の高いモデルであることを示しています。
精度 : 全予測陽性に対する真陽性の比率。これは、予測された陽性インスタンスのうち、実際に陽性であったインスタンスの数を測定します。
リコール(感度) : 実際の陽性の合計に対する真の陽性の割合。これは、実際の陽性インスタンスのいくつが正しく予測されたかを測定します。
F1スコア : 精度とリコールの調和平均値。これは、特にクラス分布が不均等な場合に、精度とリコールのバランスを提供します。
show_global_evaluation_metrics show_global_evaluation_metrics show_evaluation_metrics SHOW_GLOBAL_EVALUATION_METRICS
現在、精度、リコール、F1、AUC の指標には macro weighted
ロジスティック損失(LogLoss)は、モデル全体で計算されます。予測の目的は、損失関数を最小化することです。
show_threshold_metrics show_threshold_metrics SHOW_THRESHOLD_METRICS
そのクラスに属する予測確率が指定されたしきい値を超えた場合、サンプルはそのクラスに属するものとして分類されます。真陽性と偽陽性と陰性は、考慮されているクラスに属さないすべてのインスタンスを陰性クラスとみなして計算されます。そして、以下の指標が計算されます。
真陽性率(TPR) : モデルが正しく識別する実際の陽性インスタンスの割合(リコールに相当)。
偽陽性率(FPR) : 陽性と誤って予測された実際の陰性インスタンスの割合。
精度 : 予測の総数に対する正しい予測(真陽性と真陰性の両方)の比率で、モデルがどの程度機能しているかの全体的な尺度。この指標は、アンバランスなケースでは誤解を招く可能性があります。
サポート : 指定したデータセットに実際に出現したクラスの数。サポート値が高いほど、データセットでクラスがより多く使用されていることを示しています。サポートはモデルの指標ではなく、データセットの特徴です。
show_confusion_matrix 混同行列は、予測値と実際値を比較し、陽性インスタンスと陰性インスタンスを正しく識別する能力を評価することによって、モデルの性能を評価するために使用される表です。行列の対角線上のインスタンス数を最大化しながら、対角線外のインスタンス数を最小化することを目的としています。 SHOW_CONFUSION_MATRIX
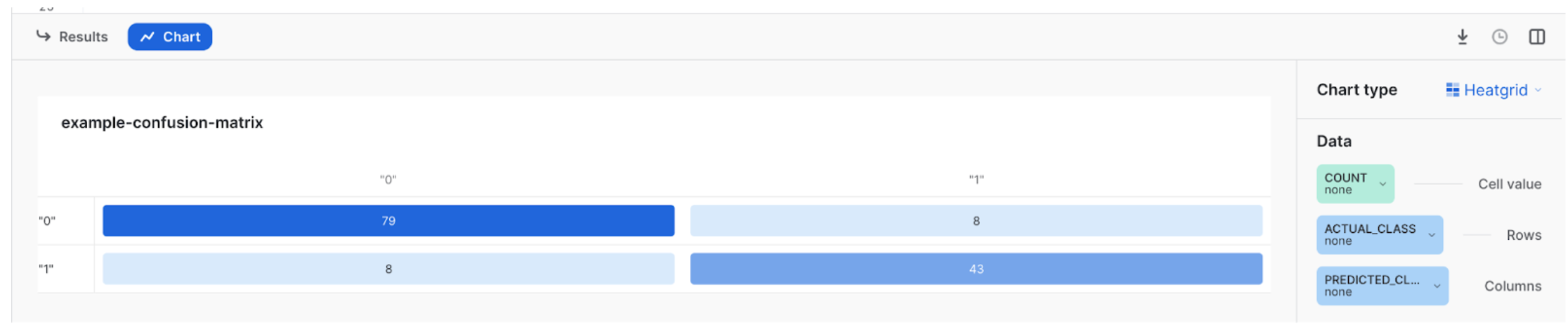
Snowsightの混同行列は次のように視覚化できます。
CALL model_binary ! SHOW_CONFUSION_MATRIX ();
結果は次のようになります。
+--------------+--------------+-----------------+-------+------+
| DATASET_TYPE | ACTUAL_CLASS | PREDICTED_CLASS | COUNT | LOGS |
|--------------+--------------+-----------------+-------+------|
| EVAL | false | false | 37 | NULL |
| EVAL | false | true | 1 | NULL |
| EVAL | true | false | 0 | NULL |
| EVAL | true | true | 22 | NULL |
+--------------+--------------+-----------------+-------+------+
混同行列を可視化するには、 Chart 、 Chart Type 、 Heatgrid の順にクリックします。データで、 Cell values には NONE を、 Rows には PREDICTED_CLASS を、 Columns には ACTUAL_CLASS を選択します。結果は以下の図のようになります。
特徴量の重要性について
分類モデルは、モデルで使用されるすべての特徴の相対的な重要性を説明することができます。この情報は、データに実際に影響を与えている要因を理解するのに役立ちます。
SHOW_FEATURE_IMPORTANCE
スコアが近い特徴量は同じような重要性を持ちます。互いによく似た複数の特徴量を使用すると、それらの特徴量の重要度スコアが低下する可能性があります。
例
CALL model_binary ! SHOW_FEATURE_IMPORTANCE ();
+------+---------------------+---------------+---------------+
| RANK | FEATURE | SCORE | FEATURE_TYPE |
|------+---------------------+---------------+---------------|
| 1 | USER_RATING | 0.9295302013 | user_provided |
| 2 | USER_INTEREST_SCORE | 0.07046979866 | user_provided |
+------+---------------------+---------------+---------------+
コストの考慮事項
分類モデルのトレーニングと使用には、コンピューティングコストとストレージコストがかかります。
分類機能から任意の APIs を使用する(モデルをトレーニングする、モデルで予測する、指標を検索する)には、アクティブなウェアハウスが必要です。分類関数を使用するためのコンピューティングコストはウェアハウスに請求されます。Snowflakeのコンピューティングコストに関する一般的な情報については、 コンピューティングコストについて
ML 関数の一般的な使用コストの詳細については、 ML 関数の概要の コストの考慮事項