Pythonコネクタの使用¶
このトピックでは、Snowflakeコネクタを使用して、ユーザーログイン、データベースとテーブルの作成、ウェアハウスの作成、データの挿入/読み込み、クエリなどの標準のSnowflake操作を実行する方法を示す一連の例を提供します。
このトピックの最後にあるサンプルコードは、例を組み合わせて単一の動作するPythonプログラムにします。
注釈
Snowflakeは、データベース、スキーマ、テーブル、タスク、ウェアハウスなど、Snowflakeのコアリソースを SQL を使用することなく管理するためのファーストクラスのPython APIs を提供します。詳細については、 Snowflake Python APIs:PythonによるSnowflakeオブジェクトの管理 をご参照ください。
データベース、スキーマ、ウェアハウスの作成¶
ログイン後、 CREATE DATABASE、 CREATE SCHEMA、および CREATE WAREHOUSE コマンドを使用して、データベース、スキーマ、およびウェアハウスを作成します(まだ存在しない場合)。
以下の例は、 tiny_warehouse という名前のウェアハウス、 testdb という名前のデータベース、および testschema という名前のスキーマを作成する方法を示しています。スキーマを作成するときは、スキーマを作成するデータベースの名前を指定するか、スキーマを作成するデータベースに既に接続している必要があります。次の例では、 CREATE SCHEMA コマンドの前に USE DATABASE コマンドを実行して、スキーマが正しいデータベースに作成されるようにします。
データベース、スキーマ、ウェアハウスの使用¶
テーブルを作成するデータベースとスキーマを指定します。また、 DML ステートメントおよびクエリを実行するためのリソースを提供するウェアハウスを指定します。
たとえば、データベース testdb、スキーマ testschema およびウェアハウス tiny_warehouse (以前に作成した)を使用するには、
テーブルの作成およびデータの挿入¶
CREATE TABLE コマンドを使用してテーブルを作成し、 INSERT コマンドを使用してテーブルにデータを入力します。
たとえば、 testtable という名前のテーブルを作成し、テーブルに2つの行を挿入します。
データのロード¶
個々の INSERT コマンドを使用してテーブルにデータを挿入する代わりに、内部または外部の場所にステージングされたファイルからデータを一括ロードできます。
内部の場所からのデータのコピー¶
ホストマシン上のファイルからテーブルにデータを読み込むには、最初に PUT コマンドを使用してファイルを内部の場所にステージングし、次に COPY INTO <テーブル> コマンドを使用してファイル内のデータをテーブルにコピーします。
例:
Linuxまたは macOS 環境の
/tmp/dataという名前のローカルディレクトリに CSV データが保存され、ディレクトリにはfile0、file1、...file100という名前のファイルが含まれます。
外部の場所からのデータのコピー¶
外部の場所(つまり、S3バケット)に既にステージングされているファイルからテーブルにデータをロードするには、 COPY INTO <テーブル> コマンドを使用します。
例:
条件:
s3://<s3バケット>/data/はS3バケットの名前を指定しますバケット内のファイルの先頭には
dataが付きます。バケットには、アカウント管理者(つまり、ACCOUNTADMIN のロールを持つユーザー)またはグローバル CREATE INTEGRATION 権限を持つロールによって CREATE STORAGE INTEGRATION を使用して作成されたストレージ統合を使用してアクセスされます。ストレージ統合により、ユーザーはプライベートストレージの場所にアクセスするための認証情報を提供する必要がなくなります。
注釈
この例では、format()関数を使用してステートメントを作成します。ご使用の環境に SQL インジェクション攻撃のリスクがある場合、format()を使用するよりも値をバインドすることをお勧めします。
データのクエリ¶
Python用Snowflakeコネクタを使用すると、次の情報を送信できます。
クエリが完了したら、 Cursor オブジェクトを使用して 結果の値をフェッチ します。デフォルトでは、Python用Snowflakeコネクタは、 値を Snowflakeデータ型 からPythonのネイティブデータ型に変換します。(値を文字列として返し、アプリケーションで型変換を実行するように選択することもできます。データ変換をバイパスすることによるクエリパフォーマンスの改善 をご参照ください。)
注釈
デフォルトでは、 NUMBER 列の値は倍精度浮動小数点値(float64)として返されます。fetch_pandas_all() メソッドと fetch_pandas_batches() メソッドでこれらを10進値(decimal.Decimal)として返すには、 connect() メソッドの arrow_number_to_decimal パラメーターを True に設定します。
同期クエリの実行¶
同期クエリを実行するには、 Cursor オブジェクトで execute() メソッドを呼び出します。例:
cursor を使用した値のフェッチ で説明されているように、 Cursor オブジェクトを使用して結果の値をフェッチします。
非同期クエリの実行¶
Python用Snowflakeコネクタは、非同期クエリ(つまり、クエリが完了する前にユーザーに制御を返すクエリ)をサポートしています。非同期クエリを送信し、ポーリングを使用して、クエリがいつ完了したかを判断できます。クエリが完了すると、結果を取得できます。
注釈
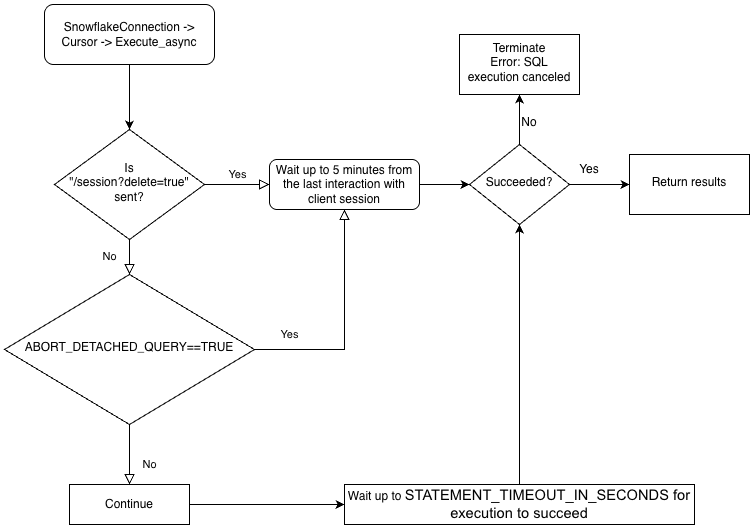
非同期クエリを実行するには、 ABORT_DETACHED_QUERY 構成パラメーターが FALSE (デフォルト値)であることを確認する必要があります。
クライアントとの接続が切れた場合:
進行中のすべての同期クエリは、パラメーター値に関係なくすぐに中止されます。
非同期クエリの場合:
ABORT_DETACHED_QUERY が
FALSEに設定されている場合、進行中の非同期クエリは、正常に終了するまで実行され続けます。ABORT_DETACHED_QUERY が
TRUEに設定されている場合、5 分経過してもクライアント接続が再確立されないと、Snowflake は進行中のすべての非同期クエリーを自動的に中止します。cursor.query_result(queryId)を呼び出すことで、非同期クエリを5分経過時に中止されることを防ぐことができます。クエリはまだ実行中なので、この呼び出しは実際のクエリ結果を取得しませんが、クエリがキャンセルされるのを防ぎます。query_resultの呼び出しは同期操作であり、特定のユースケースに適している場合とそうでない場合があります。
この機能を使用すると、各クエリが完了するのを待たずに、複数のクエリを並行して送信できます。同じセッション中に、同期クエリと非同期クエリを組み合わせて実行することもできます。
注釈
1つのクエリで複数のステートメントを実行するには、有効なウェアハウスがセッションで利用可能である必要があります。
最後に、ある接続から非同期クエリを送信し、別の接続からの結果を確認できます。たとえば、ユーザーはアプリケーションから長時間実行されるクエリを開始し、アプリケーションを終了し、後ほどアプリケーションを再起動して結果を確認することができます。
ドライバーのビジネスロジックの階層とABORT_DETACHED_QUERYパラメーターの相互作用については、次のフローチャートをご参照ください。
非同期クエリの送信¶
注釈
非同期クエリはPUT/GETステートメントをサポートしていません。
cursor.execute_async(query) が使用されると、Snowflake Pythonドライバーは非同期で送信されたクエリを自動的に追跡します。connection.close() で接続が明示的に閉じられた場合、またはコンテキストマネージャーが connect()... と使用されている場合、非同期クエリのリストが検査され、まだ実行中のものがある場合、Snowflake側のセッションは削除されません。
同じ接続内で非同期クエリが実行されていない場合、その接続に属するSnowflakeセッションは connection.close() が呼び出されたときにログアウトします。これは、同じセッションで実行されている他のすべてのクエリが暗黙的にキャンセルされます。
This behavior also depends on the SQL ABORT_DETACHED_QUERY parameter.
ベストプラクティスとして、実行時間の長いすべての非同期タスク(特に接続の終了後も継続することを意図したもの)を別の接続に分離します。
server_session_keep_alive (デフォルト: False )接続パラメーターを使用して、この自動動作をオーバーライドできます。デフォルトでは、非同期クエリが実行されていない場合に のみ connection.close() が呼び出されたときにSnowflakeセッションはログアウトされます。デフォルトの動作では、同期クエリを考慮したり追跡したりしません。
server_session_keep_alive=True の場合、 connection.close() はクエリのステータスに関係なくSnowflakeセッションをログアウトしません。長時間の非同期クエリを発行するように設計された接続の場合、この設定を有効にするとCPUオーバーヘッドを削減し、接続終了プロセスを高速化します。
重要
このパラメーターを有効にすると、予期しない請求といった影響が生じる可能性があります(たとえば、 STATEMENT_TIMEOUT_IN_SECONDS の構成値までクエリが実行される可能性があります)。Snowflakeでは server_session_keep_alive の値をデフォルトから変更する必要があるかどうかを慎重に決定することを強く推奨します。また、可能な場合、実稼働環境に実装する前に、非実稼働環境で変更を十分にテストすることを強く推奨します。
非同期クエリを送信するには、 Cursor オブジェクトで execute_async() メソッドを呼び出します。例:
クエリを送信した後、
クエリがまだ実行されているかどうかを確認するには、 クエリのステータスの確認 をご参照ください。
クエリの結果を取得するには、 クエリ ID を使用したクエリの結果の取得 をご参照ください。
非同期クエリの実行例については、 非同期クエリの例 をご参照ください。
非同期クエリのベストプラクティス¶
非同期クエリを送信するときは、次のベストプラクティスに従ってください。
クエリを並行して実行する前に、どのクエリが他のクエリに依存しているかを確認してください。たとえば、 INSERT ステートメントは、対応する CREATE TABLE ステートメントが終了するまで開始するべきではありません。
使用可能なメモリに対して、実行するクエリが多すぎないことを確認してください。特に複数の結果が同時にメモリに格納されている場合に複数のクエリを並行して実行すると、通常はより多くのメモリを使用します。
ポーリング時に、クエリが成功しないまれなケースを処理します。
トランザクション制御ステートメント(BEGIN、 COMMIT、および ROLLBACK)が他のステートメントと並行して実行されないようにします。
非同期クエリは、 SQL 自体に ORDER BY 句があっても、順序付けられた結果を返すことは保証されないことに注意してください。したがって、
result_scan関数は、順序付けられた結果を保証しません。
Snowflakeクエリ ID の取得¶
クエリ ID は、Snowflakeによって実行される各クエリを識別します。Python用Snowflakeコネクタを使用してクエリを実行すると、 Cursor オブジェクトの sfqid 属性を介してクエリ ID にアクセスできます。
クエリ ID を使用して次を実行できます。
ウェブインターフェイスでクエリのステータスを確認。
Snowsight では、クエリIDsは Query History ページに表示されます。クエリ履歴でクエリのアクティビティをモニターする をご参照ください。
プログラムでクエリのステータスを確認(例:非同期クエリが完了したかどうかを判断するため)。
クエリのステータスの確認 をご参照ください。
非同期クエリまたは以前に送信された同期クエリの結果を取得。
クエリ ID を使用したクエリの結果の取得 をご参照ください。
実行中のクエリをキャンセル。
クエリ ID ごとのクエリのキャンセル をご参照ください。
クエリのステータスの確認¶
クエリのステータスを確認するには、
Cursorオブジェクトのsfqidフィールドから、クエリ ID を取得します。クエリ ID を
Connectionオブジェクトのget_query_status()メソッドに渡して、クエリのステータスを表すQueryStatus列挙型定数を返します。デフォルトでは、クエリの結果がエラーになった場合、
get_query_status()はエラーを発生しません。エラーを発生したい場合は、代わりにget_query_status_throw_if_error()を呼び出してください。QueryStatus列挙型定数を使用して、クエリのステータスを確認します。クエリがまだ実行されているかどうかを判断するには(たとえば、これが非同期クエリの場合)、定数を
Connectionオブジェクトのis_still_running()メソッドに渡します。エラーが発生したかどうかを判断するには、定数を
is_an_error()メソッドに渡します。
列挙型定数の包括的なリストについては、
QueryStatusをご参照ください。
次の例では、非同期クエリを実行し、クエリのステータスを確認します。
次の例では、クエリの結果でエラーある場合にエラーが発生します。
クエリ ID を使用したクエリの結果の取得¶
注釈
Cursor オブジェクトで execute() メソッドを呼び出して 同期クエリを実行 した場合は、結果を取得するためにクエリ ID を使用する必要はありません。cursor を使用した値のフェッチ で説明されているように、結果から値をフェッチするだけです。
非同期クエリまたは以前に送信された同期クエリの結果を取得する場合は、次の手順に従います。
該当クエリのクエリ ID を取得します。Snowflakeクエリ ID の取得 をご参照ください。
Cursorオブジェクトでget_results_from_sfqid()メソッドを呼び出して、結果を取得します。cursor を使用した値のフェッチ で説明されているように、
Cursorオブジェクトを使用して結果の値をフェッチします。
クエリがまだ実行中の場合、フェッチメソッド( fetchone()、 fetchmany()、 fetchall() など)はクエリの完了を待機することに注意してください。
例:
cursor を使用した値のフェッチ¶
カーソルオブジェクトの反復子メソッドを使用して、テーブルから値をフェッチします。
たとえば、以前に( テーブルの作成およびデータの挿入 で)作成された testtable という名前のテーブルから「col1」および「col2」という名前の列をフェッチするには、次のようなコードを使用します。
または、Python用Snowflakeコネクタが便利なショートカットを提供します。
単一の結果(つまり単一の行)を取得する必要がある場合は、 fetchone メソッドを使用します。
一度に指定された行数を取得する必要がある場合は、行数で fetchmany メソッドを使用します。
注釈
結果セットが大きすぎてメモリに収まらない場合は、
fetchoneまたはfetchmanyを使用します。
すべての結果を一度に取得する必要がある場合、
クエリのタイムアウトを設定するには、「開始」コマンドを実行し、クエリにタイムアウトパラメーターを含めます。クエリがパラメーター値の長さを超える場合、エラーが生成され、ロールバックが発生します。
次のコードでは、エラー604はクエリがキャンセルされたことを意味します。タイムアウトパラメーターは Timer() を開始し、指定された時間内にクエリが終了しない場合はキャンセルします。
DictCursor を使用した列名の値のフェッチ¶
列名で値をフェッチする場合は、タイプ DictCursor の cursor オブジェクトを作成します。
例:
非同期クエリの例¶
以下は、非同期クエリの簡単な例です。
次の例では、ある接続から非同期クエリを送信し、別の接続から結果を取得します。
クエリ ID ごとのクエリのキャンセル¶
クエリ ID によるクエリのキャンセル:
文字列「queryID」を実際のクエリ ID に置き換えます。クエリ ID を取得するには、 Snowflakeクエリ ID の取得 をご参照ください。
データ変換をバイパスすることによるクエリパフォーマンスの改善¶
クエリのパフォーマンスを向上させるには、 snowflake.connector.converter_null モジュールの SnowflakeNoConverterToPython クラスを使用して、Snowflake内部データ型からネイティブPythonデータ型へのデータ変換をバイパスします。例:
その結果、すべてのデータは文字列形式で表されるため、アプリケーションはそれをネイティブPythonデータ型に変換する必要があります。たとえば、 TIMESTAMP_NTZ および TIMESTAMP_LTZ データは文字列形式で表されるエポック時間であり、 TIMESTAMP_TZ データは文字列形式で表されるエポック時間の後に、空白と分単位の UTC へのオフセットが続きます。
バインドデータに影響はありません。Pythonネイティブデータは引き続き更新用にバインドできます。
データのダウンロード¶
Snowflake Connector for Pythonバージョン3.14.0では、 GET コマンドでSnowflakeステージのファイルをダウンロードするときにコネクターがファイルアクセス権をどのように設定するかを指定する unsafe_file_write 接続パラメーターが導入されました。これらのファイルは常に Python プロセスを実行しているユーザーによって所有されます。
デフォルトでは、unsafe_file_write パラメーターは:codenowrap:False に設定され、より安全で厳密な:codenowrap:600 ファイル権限が提供されます。つまり、所有者のみがダウンロードしたファイルの読み取りおよび書き込み権限を持ちます。他のグループやユーザーには、 GET コマンドでダウンロードされたファイルに対する権限はありません。
組織でファイルアクセス権の制限を少なくする必要がある場合は、 unsafe_file_write パラメーターを True に設定することができます。このパラメーターを有効にすると、ステージからダウンロードされたファイルのファイルアクセス権が 644 に設定され、所有者はファイルの読み取りと書き込みができますが、他の人には読み取りのみが許可されます。この設定は、例えば、ダウンロードしたファイルを読み込んで処理できる必要がある別のシステムユーザーの下で実行される ETL ツールのために必要な場合があります。
どの値を使用すべきか不明な場合は、組織のセキュリティポリシー担当チームに相談してください。
データのバインド¶
SQL ステートメントで使用する値を指定するには、ステートメントにリテラルを含めるか、 変数をバインドします。変数をバインドするときは、 SQL ステートメントのテキストに1つ以上のプレースホルダーを配置し、各プレースホルダーに変数(使用する値)を指定します。
次の例は、リテラルとバインドの使用を比較しています。
リテラル:
バインド:
注釈
バインドできるデータのサイズ、またはバッチで結合できるデータのサイズには上限があります。詳細については、 クエリテキストサイズの制限 をご参照ください。
Snowflakeは、次のタイプのバインドをサポートしています。
pyformatおよびformat。これは クライアント上のデータをバインド します。qmarkおよびnumeric。これは サーバー上のデータをバインド します。
これらのそれぞれについて、以下で説明します。
pyformat または format バインド¶
pyformat バインディングと format バインディングの両方が、サーバー側ではなくクライアント側でデータをバインドします。
デフォルトでは、Python用Snowflakeコネクタは pyformat および format の両方をサポートしているため、プレースホルダーとして %(name)s または %s を使用できます。例:
%(name)sをプレースホルダーとして使用:%sをプレースホルダーとして使用。
pyformat と format により、リストオブジェクトを使用して IN 演算子のデータをバインドすることもできます。
パーセント文字(「%」)は、 SQL LIKE のワイルドカード文字であり、Pythonの形式バインディング文字でもあります。フォーマットバインディングを使用し、 SQL コマンドにパーセント文字が含まれている場合、パーセント文字をエスケープする必要がある場合があります。例えば、 SQL ステートメントが次の場合:
Pythonコードは次のようになります(元のパーセント記号をエスケープするための追加のパーセント記号に注意)。
qmark または numeric バインド¶
qmark バインディングと numeric バインディングの両方とも、クライアント側ではなくサーバー側でデータをバインドします。
qmarkバインディングの場合は、疑問符文字(?)を使用して、変数の値を文字列のどこに挿入するかを指定します。numericバインディングの場合は、コロン(:)の後に数字を使用して、その位置で置換する変数の位置を指定します。たとえば、:2は2番目の変数を指定します。数値バインディングを使用して、同じクエリで同じ値を複数回バインドします。たとえば、長い VARCHAR、 BINARY、または 半構造化 の値を複数回使用する場合は、
numericバインディングにより値をサーバーに1回送信すると、それを複数回使用できるようになります。
次のセクションでは、 qmark および numeric バインディングの使用方法について説明します。
qmark または numeric バインドの使用¶
qmark または numeric スタイルのバインディングを使用するには、以下のいずれかを実行するか、 connect() を呼び出す際に接続パラメーターの一部として paramstyle を設定します。
snowflake.connector.paramstyle='qmark'snowflake.connector.paramstyle='numeric'
paramstyle を qmark または numeric に設定する場合は、プレースホルダーとしてそれぞれ ? または :N (N は数字に置換)を使用する必要があります。
例:
?をプレースホルダーとして使用。:Nをプレースホルダーとして使用。次のクエリは、
numericバインドを使用して変数を再利用する方法を示しています。
datetime での qmark または numeric バインドの使用¶
qmark または numeric バインディングを使用してデータをSnowflake TIMESTAMP データ型にバインドする場合は、Snowflakeタイムスタンプデータ型(TIMESTAMP_LTZ または TIMESTAMP_TZ)と値を指定するタプルに、バインド変数を設定します。例:
クライアント側のバインディングとは異なり、サーバー側のバインディングでは、列にSnowflakeデータ型が必要です。ほとんどの一般的なPythonデータ型には、Snowflakeデータ型への暗黙的なマッピングがすでにあります(例: int は FIXED にマッピングされます)。ただし、Python datetime データは、複数のSnowflakeデータ型(TIMESTAMP_NTZ、 TIMESTAMP_LTZ、または TIMESTAMP_TZ)のいずれかにバインドでき、デフォルトのマッピングは TIMESTAMP_NTZ であるため、使用するSnowflakeデータ型を指定する必要があります。
IN 演算子でのバインド変数の使用¶
qmark および numeric (サーバー側バインディング)は、 IN 演算子を使用したバインド変数の使用をサポートしていません。
IN 演算子でバインド変数を使用する必要がある場合は、 クライアント側バインディング (pyformat または format)を使用します。
バッチ挿入の変数に対するバインドパラメーター¶
アプリケーションコードで、単一のバッチに複数の行を挿入できます。これを実行するには、 INSERT ステートメントの値のパラメーターを使用します。たとえば、次のステートメントは、 INSERT ステートメントの qmark のバインドにプレースホルダーを使用します。
次に、挿入する必要のあるデータを指定するには、複数のシーケンス(たとえば、タプルのリスト)のシーケンス1つである変数を定義します。
上記の例に示されているように、リスト内の各項目は、挿入される行の列値を含むタプルです。
バインディングを実行するには、 executemany() メソッドを呼び出し、変数を2番目の引数として渡します。例:
サーバー上でデータをバインド している場合(つまり、 qmark または numeric バインドを使用)、コネクタはバインドを通じてバッチ挿入のパフォーマンスを最適化できます。
この手法を使用して多数の値を挿入する場合は、インジェスチョンのためにデータを(ローカルマシン上でファイルを作成することなく)仮ステージにストリーミングすると、ドライバーのパフォーマンスを向上させることができます。値の数がしきい値を超えると、ドライバーはこれを自動的に実行します。
さらに、セッションの現在のデータベースとスキーマを設定する必要があります。これらが設定されていない場合、ドライバーによって実行される CREATE TEMPORARY STAGE コマンドは、次のエラーにより失敗する可能性があります。
注釈
データをSnowflakeデータベースにロードする別の方法( COPY コマンドを使用した一括ロードを含む)については、 Snowflakeにデータをロード をご参照ください。
SQL インジェクション攻撃を回避する¶
SQL インジェクションの危険があるため、Pythonのフォーマット関数を使用してデータをバインドしないでください。例:
代わりに、値を変数に格納してから、qmarkまたは数値バインドスタイルを使用してそれらの変数をバインドします。
列のメタデータの取得¶
結果セットの各列に関するメタデータ(例: 各列の名前、タイプ、精度、スケールなど)を取得するには、次のいずれかの方法を使用します。
execute()メソッドを呼び出してクエリを実行した後にメタデータにアクセスするには、Cursorオブジェクトのdescription属性を使用します。クエリを実行 することなく メタデータにアクセスするには、
describe()メソッドを呼び出します。describeメソッドは、Python用Snowflakeコネクタ2.4.6以降のバージョンで使用できます。
description 属性は、次のいずれかの値に設定されます。
バージョン2.4.5以前: タプルのリスト。
バージョン2.4.6以降: ResultMetadata オブジェクトのリスト。(
describeメソッドもこのリストを返します。)
各タプルと ResultMetadata オブジェクトには、列のメタデータ(列名、データ型など)が含まれています。メタデータには、インデックスによりアクセス するか、2.4.6以降のバージョンでは ResultMetadata 属性によりアクセスできます。
以下の例は、返されたタプルと ResultMetadata オブジェクトからメタデータにアクセスする方法を示しています。
例: インデックスにより列名メタデータを取得(バージョン2.4.5以前):
次の例では、クエリの実行後に description 属性を使用して列名のリストを取得します。属性はタプルのリストであり、この例では、各タプルの最初の値から列名にアクセスします。
例: 属性により列名メタデータを取得(バージョン2.4.6以降):
次の例では、クエリの実行後に description 属性を使用して列名のリストを取得します。属性は ResultMetaData オブジェクトのリストであり、この例では、各 ResultMetadata オブジェクトの name 属性から列名にアクセスします。
例: クエリの実行することなく、列名のメタデータを取得(バージョン2.4.6以降):
次の例では、 describe メソッドを使用して、クエリを実行することなく列名のリストを取得します。describe() メソッドは ResultMetaData オブジェクトのリストを返し、この例では各 ResultMetadata オブジェクトの name 属性から列名にアクセスします。
エラーの処理¶
アプリケーションは、Snowflakeコネクタから発生した例外を適切に処理し、コードの実行を続行または停止する必要があります。
execute_stream を使用した SQL スクリプトの実行¶
execute_stream 関数を使用すると、ストリームで1つ以上の SQL スクリプトを実行できます。
注釈
sql_stream にコメントが含まれている場合は、追加の構成が必要になる場合があります。execute_streamを使って SQL スクリプトを実行する をご参照ください。
接続の終了¶
ベストプラクティスとしては、 close メソッドを呼び出して接続を閉じます。
これにより、収集されたクライアントメトリックがサーバーに送信され、セッションが削除されます。また、 try-finally ブロックは、途中で例外が発生した場合でも接続が確実に閉じられるようにします。
注意
閉じていない複数の接続はシステムリソースを使い果たし、最終的にはアプリケーションのクラッシュを引き起こします。
コンテキストマネージャーを使用したトランザクションの接続および制御¶
Python用Snowflakeコネクタは、必要に応じてリソースを割り当てたり解放したりするコンテキストマネージャーをサポートしています。コンテキストマネージャーは、 autocommit が無効になっている場合、ステートメントのステータスに基づいてトランザクションをコミットまたはロールバックするのに役立ちます。
上記の例では、3番目のステートメントが失敗すると、コンテキストマネージャーはトランザクションの変更をロールバックし、接続を閉じます。すべてのステートメントが成功した場合、コンテキストマネージャーは変更をコミットし、接続を閉じます。
try ブロックと except ブロックを持つ同等のコードは次のとおりです。
VECTOR データ型の使用¶
VECTOR データ型 のサポートがSnowflake Python Connectorのバージョン3.6.0で導入されました。VECTOR データタイプを ベクトル類似関数 と共に使用することで、ベクトル検索や検索拡張生成 (RAG) に基づくアプリケーションを実装することができます。
次のコード例は、Python Connectorを使用して、 VECTOR 列を持つテーブルを作成し、 VECTOR_INNER_PRODUCT 関数を呼び出す方法を示しています。
次のコード例は、 [1,2,3] に最も近いベクトルを見つけるために、Python Connectorを使用して VECTOR_COSINE_SIMILARITY を呼び出す方法を示しています。
注釈
変数バインドは VECTOR データ型ではサポートされていません。
ログ¶
Python用Snowflakeコネクタは、標準のPython logging モジュールを活用して定期的にステータスを記録するため、アプリケーションはバックグラウンドで動作しているアクティビティを追跡できます。ログを有効にする最も簡単な方法は、アプリケーションの開始時に logging.basicConfig() を呼び出すことです。
たとえば、ログレベルを INFO に設定し、ログを /tmp/snowflake_python_connector.log という名前のファイルに保存するには、
次のようにログレベルを DEBUG に設定すると、より包括的なログを有効にできます。
オプションですが推奨される SecretDetector フォーマッタークラスにより、Snowflake Python Connectorログファイルに書き込まれる前に、特定の既知の機密情報セットが確実にマスクされるようにします。SecretDetector を使用するには、次のようなコードを使用します。
注釈
botocoreおよびboto3は、Python用 AWS (Amazon Web Services) SDK から入手できます。
ログ構成ファイル¶
あるいは、 config.toml 構成ファイルでログレベルとログファイルを保存するディレクトリを簡単に指定することもできます。このファイルの詳細については、 connections.toml ファイルを使用した接続 をご参照ください。
このログ構成ファイルでは、tomlを使用して、次のように save_logs、 level、および path ログパラメーターを定義します。
条件:
save_logsはログを保存するかどうかを決定します。levelはログレベルを指定します。定義されていない場合、ドライバーのデフォルトはINFOになります。pathログファイルを保存するディレクトリを識別します。定義されていない場合、ドライバーはログをデフォルトの$SNOWFLAKE_HOME/logs/ディレクトリに保存します。
注釈
config.toml ファイルに [log] セクションが含まれていない場合、ログメッセージは保存されません。
1日のログメッセージが python-connector.log ファイルに追加され、後で python-connector.log.YYYY-MM-DD に名前が変更されます。
サンプルプログラム¶
次のサンプルコードは、前のセクションで説明した例の多くを有効なpythonプログラムに結合します。この例には2つの部分が含まれています。
親クラス(「python_veritas_base」)には、サーバーへの接続など、多くの一般的な操作のコードが含まれています。
子クラス(「python_connector_example」)は、テーブルのクエリなど、特定のクライアントのカスタム部分を表します。
このサンプルコードは、テストの1つから直接インポートされ、製品の最近のビルドで実行されたことを確認するのに役立ちます。
これはテストから取得されているため、一部のテストで使用される代替ポートとプロトコルを設定するための少量のコードが含まれています。ユーザーは、プロトコルまたはポート番号を設定 しない でください。代わりに、これらを省略してデフォルトを使用します。
これには、ドキュメントに個別にインポートできるコードを識別するためのセクションマーカー(別称「スニペットタグ」)も含まれています。セクションマーカーは通常、次と類似しています。
これらのセクションマーカーは、ユーザーコードでは必要ありません。
コードサンプルの最初の部分には、次の一般的なサブルーチンが含まれています。
接続情報を含むコマンドライン引数(例:「--warehouse MyWarehouse」)を読み取ります。
サーバーに接続します。
ウェアハウス、データベース、およびスキーマを作成して使用します。
スキーマ、データベース、ウェアハウスを使い終えたらドロップします。
コードサンプルの2番目の部分では、テーブルを作成したり、それに行を挿入したりします。
このサンプルを実行するには、次を実行します。
最初のコードを「python_veritas_base.py」という名前のファイルにコピーします。
2番目のコードを「python_connector_example.py」という名前のファイルにコピーします
次のように、 SNOWSQL_PWD 環境変数をパスワードに設定します。
次のようなコマンドラインを使用してプログラムを実行します(もちろん、ユーザーとアカウントの情報を自分のユーザーとアカウントの情報に置き換えます)。
警告
これにより、プログラムの最後にウェアハウス、データベース、およびスキーマが削除されます。既存のデータベースの名前は 使用しないでください 。
出力は次のとおりです。
長い例を次に示します。
注釈
アカウントとログイン情報を設定するセクションで、Snowflakeログイン情報(名前、パスワードなど)に一致するように、必要に応じて変数を置き換えます。
この例では、format()関数を使用してステートメントを作成します。ご使用の環境に SQL インジェクション攻撃のリスクがある場合、format()を使用するよりも値をバインドすることをお勧めします。