Cortex Search¶
Get started with Cortex Search
概要¶
Cortex Searchは、Snowflakeデータに対して低遅延で高品質な「ファジー」検索を可能にします。検索拡張世代(RAG) 大規模言語モデル(LLMs)を活用したアプリケーションなど、Snowflakeユーザーのための幅広い検索体験を提供します。
Cortex Searchは、埋め込み、インフラストラクチャのメンテナンス、検索品質パラメーターのチューニング、継続的なインデックスの更新を心配することなく、数分でテキストデータのハイブリッド(ベクトルとキーワード)検索エンジンを立ち上げ、実行することができます。つまり、インフラや検索品質のチューニングに費やす時間を減らし、データを活用した高品質なチャットや検索体験の開発に多くの時間を費やすことができます。Cortex Searchチュートリアル で、Cortex Searchを使用して AI チャットおよび検索アプリケーションをパワーアップするためのステップバイステップの手順をご覧ください。
Cortex Searchの使用時期¶
Cortex Searchの2つの主なユースケースは、検索拡張世代(RAG)とエンタープライズ検索です。
LLM チャットボット用 RAG エンジン:Cortex Searchは、セマンティック検索を活用することで、カスタマイズされた文脈に応じた応答を実現し、テキストデータを使用したチャットアプリケーションの RAG エンジンとして使用できます。
エンタープライズ検索:Cortex Searchを、アプリケーションに埋め込まれた高品質の検索バーのバックエンドとして使用します。
RAG 向けのCortex Search¶
検索拡張生成(RAG)は、大規模言語モデルの生成応答を拡張するために、知識ベースからデータを検索する技術です。次のアーキテクチャ図は、Cortex Searchと Cortex LLM 関数 を組み合わせて、Snowflakeデータをナレッジベースとして使用する RAG エンタープライズチャットボットを作成する方法を示しています。
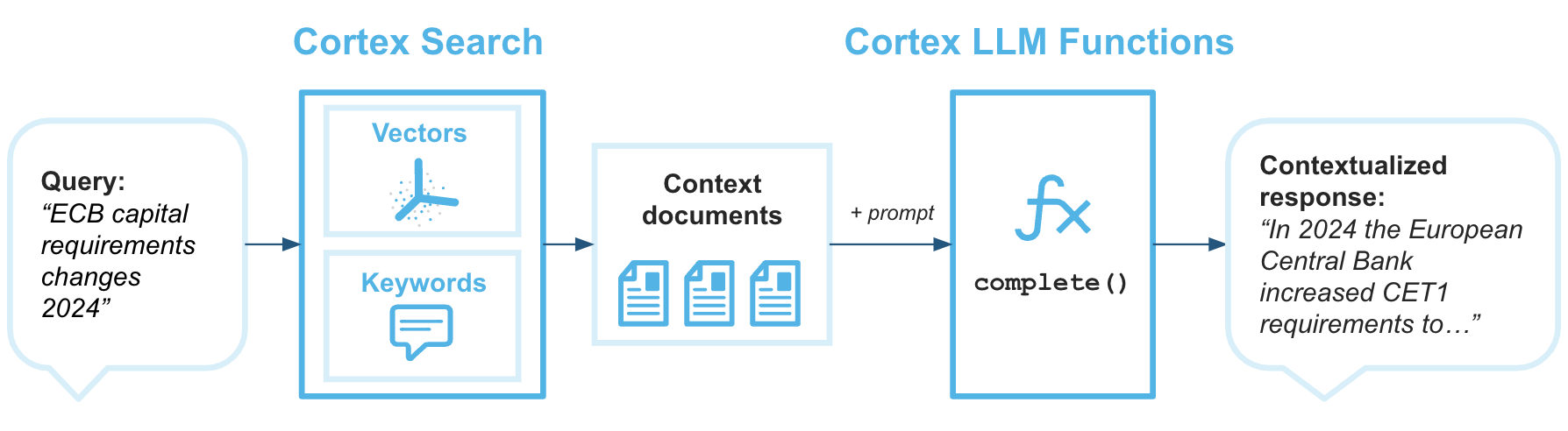
Cortex Searchは、L大規模言語モデルに必要なコンテキストを提供し、最新の独自データに基づいた回答を返す検索エンジンです。
例: Cortex Search Serviceの作成とクエリ¶
この例では、Cortex Search Serviceを作成し、 REST API を使ってクエリする手順を説明します。サービスのクエリの詳細については、 「Cortex Search Serviceのクエリ」 をご参照ください。
この例では、カスタマーサポートのトランスクリプトデータセットのサンプルを使用します。
以下のコマンドを実行して、サンプルのデータベースとスキーマを設定します。
以下の SQL コマンドを実行してデータセットを作成します。
サービスの作成¶
Cortex Search Serviceは、単一の SQL クエリ、またはSnowflake AI & ML Studioから作成できます。Cortex Search Serviceを作成すると、Snowflakeはソースデータに対して変換を実行し、低レイテンシでサービングできるようにします。以下のセクションでは、 SQL と、 Snowsight のSnowflake AI & ML Studioの両方を使用してサービスを作成する方法を示します。
注釈
検索サービスを作成すると、作成プロセスの一部として検索インデックスが構築されます。これは、 CREATE CORTEX SEARCH SERVICE ステートメントが大きなデータセットの場合、完了までに時間がかかる可能性があることを意味します。
SQL を使用する¶
次の例は、前のセクションで作成したサンプルカスタマーサポートのトランスクリプトデータセットに CREATE CORTEX SEARCH SERVICE、Cortex Search Serviceを作成する方法を示しています。
このコマンドは、データの検索サービスを構築するトリガーとなります。この例では:
同サービスへの問い合わせは、
transcript_text列で一致するものを検索します。
TARGET_LAGパラメーターは、Cortex Search Serviceがベーステーブルsupport_transcriptsの更新を1日に1回程度チェックすることを指示します。列
regionとagent_idは、transcript_text列に対するクエリの結果とともに返されるようにインデックスが付けられます。列
regionは、transcript_text列をクエリする際にフィルター列として利用できるようになります。ウェアハウス
cortex_search_whは、指定されたクエリの結果を最初にマテリアライズするために使用され、ベーステーブルが変更されるたびに使用されます。
注釈
クエリで指定されたウェアハウスのサイズとテーブルの行数によっては、この CREATE コマンドの完了に数時間かかる場合があります。
Snowflakeでは、 MEDIUM 以下のサイズの専用ウェアハウスを各サービスに使用することを推奨しています。
ATTRIBUTES フィールドの列は、明示的な列挙またはワイルドカード(
*)によって、ソースクエリに含まれている必要があります。
Snowsight を使用する¶
Snowsight でCortex Search Serviceを作成するには、以下の手順に従います。
Snowsight にサインインします。
SNOWFLAKE.CORTEX_USER データベースロールが付与されているロールを選択します。
ナビゲーションメニューで AI & ML » Cortex Search を選択します。
Create を選択します。
ロールとウェアハウスを選択します。
このロールには、 SNOWFLAKE.CORTEX_USER データベースロールが付与されていなければならなりません。ウェアハウスは、サービスが作成され更新されるときに、ソースクエリの結果を実体化するために使用されます。
サービスを定義するデータベースとスキーマを選択します。
サービス名を入力し、 Next を選択します。
インデックスを作成するデータを選択します。
テーブルまたはビューを選択するには、Table or view を選択します。
検索用にインデックスを作成するテキストデータを含むテーブルまたはビューを選択し、 Next を選択します。たとえば、
support_transcriptsテーブルを選択します。ステージからファイルを選択するには、Stage を選択します。(プレビュー)
検索用にインデックスを作成するファイルを含むステージを選択し、Next を選択します。
注釈
サービス定義時に複数のデータソースを指定したり、変換を実行したりしたい場合は、 SQL を使用してください。
Table or view を選択した場合:
検索結果に含める列(たとえば
transcript_text、region、agent_id)を選択し、Next を選択します。検索する列(たとえば
transcript_text)を選択し、Next を選択します。特定の列に基づいて検索結果をフィルタリングできるようにする場合は、それらの列を選択し、Next を選択します。フィルターが不要な場合は、 Skip this option を選択してください。
:ui:`Stage`を選択した場合(プレビュー):
処理されたデータの宛先を選択し、Next を選択します。
サービスの構成パラメーターを選択します。
ターゲットラグ(サービスコンテンツがベースデータの更新から遅れる時間)を設定し、 Create を選択します。
最後のステップでは、サービスが作成されたことを確認し、サービス名とそのデータソースを表示します。
注釈
Snowsight からサービスを作成する場合、サービス名は二重引用符で囲まれます。SQL でサービスを参照する際の意味については、 二重引用符で囲まれた識別子 をご参照ください。
使用許可の付与¶
サービスとインデックスを作成した後、customer_supportのような他のロールにサービス、そのデータベース、スキーマの使用を許可することができます。
サービスのプレビュー¶
サービスにデータが正しく入力されていることを確認するには、 SQL 環境から SEARCH_PREVIEW 関数 を使用してサービスをプレビューできます。
成功したクエリ応答のサンプル:
この応答は、サービスにデータが入力され、指定されたクエリに対して妥当な結果が提供されていることを確認します。
CORTEX_SEARCH_DATA_SCAN テーブル関数を使用して、サービスのコンテンツを検査することもできます。
アプリケーションからサービスをクエリする¶
検索サービスを作成し、自分のロールに使用許可を付与し、プレビューしたら、 Python API を使ってアプリケーションからクエリすることができます。
次のコードは、 internet issues に関するクエリに最も関連するサポートチケットを取得するためにPython API を使用し、 North America リージョン内の結果を返すようにフィルタリングしています。
成功したクエリ応答のサンプル:
Cortex Search Serviceは、クエリの columns フィールドで指定されたすべての列を返します。
必要な権限¶
Cortex Search Serviceを作成するには、ロールがCortex組み込み関数を使用するために必要な権限を持っている必要があります。そのためには、サービス作成者のロールに SNOWFLAKE.CORTEX_USER データベースロールまたは SNOWFLAKE.CORTEX_EMBED_USER データベースロールを付与する必要があります。また、以下の権限も必要です。
サービスを作成するスキーマに対する CREATE CORTEX SEARCH SERVICE または OWNERSHIP 権限。
サービスがクエリする基になるテーブルまたはビューに対する SELECT 権限。
サービスを更新するウェアハウスに対する USAGE 権限。
変更追跡は、Cortex Search Serviceで使用される基になるオブジェクトすべてで有効にする必要があります。変更追跡の要件の詳細については、 変更追跡の要件 をご参照ください。
Cortex Search Serviceにクエリを実行するには、クエリを実行するユーザーのロールが、サービス自体、およびサービスが存在するデータベースとスキーマに対して、 USAGE 権限を持っている必要があります。Cortex Searchアクセス制御の要件 をご参照ください。
ALTER コマンドを使用してCortex Search Serviceを一時停止または再開するには、クエリするユーザーのロールがサービス上で OPERATE 権限を持っている必要があります。ALTER CORTEX SEARCH SERVICE をご参照ください。
重要
Cortex Search Serviceは、 所有者権限 で検索を実行し、所有者権限で実行される他のSnowflakeオブジェクトと同じセキュリティモデルに従います。詳細情報については、 Cortex Search アクセス制御要件 を参照してください。
Cortex Searchの品質を理解する¶
Cortex Searchは、検索とランキングモデルのアンサンブルを活用し、ほとんどチューニングの必要なく、高レベルの検索品質を提供します。Cortex Searchは、文書の検索とランキングに「ハイブリッド」なアプローチをとっています。各検索クエリは、以下のものを利用します。
意味的に類似した文書を検索するための ベクトル検索
語彙的に類似した文書を検索するための キーワード検索
結果セットの中で最も関連性の高い文書を再ランク付けするための セマンティック再ランク付け
このハイブリッド検索アプローチは、セマンティックリランキングステップと相まって、幅広いデータセットとクエリにおいて高い検索品質を達成しています。
検索結果のスコアリングは、数値ブーストや時間減衰の適用、コンポーネントの重みの調整、再ランク付けの無効化などによってカスタマイズできます。詳細については、 Cortex Searchスコアリングのカスタマイズ をご参照ください。
Cortex Search埋め込みモデル¶
Cortex Searchでは、検索のベクトル検索ステージで利用する埋め込みモデルをユーザーが選択できます。Cortex Searchでは、以下の埋め込みモデルが可用性です。
重要
モデル価格設定は変わることがあります。正規モデルの価格設定は Snowflakeサービス利用表 で確認できます。以下に表示されている価格が、Snowflakeサービス利用表のモデルに対して表示されている価格と異なる場合は、Snowflakeサービス利用表が優先されます。
モデル名 |
出力次元 |
コンテキストウィンドウサイズ(トークン) |
言語サポート |
説明 |
|---|---|---|---|---|
|
768 |
512 |
英語のみ |
Snowflakeの最も実用的な、英語のみのエンベッディングモデルです。このオープンソースの110Mパラメータ・モデルは、Cortex Searchの可用性モデルの中で最速のインデックス作成時間を実現します。詳細情報については、 Arctic Embed 1.5 ブログ記事 および Arctic Embed 1.5 モデルカード を参照してください。 |
|
1024 |
512 |
多言語 |
512トークンのコンテキストウィンドウを持つ、Snowflakeのコストパフォーマンスに優れた多言語埋め込みモデル。このオープンソースの568Mパラメーターモデルは、英語と英語以外のデータセットの両方で高い品質をもたらします。詳細については、 Arctic Embed 2ブログ投稿 および Arctic Embed 2モデルカード をご参照ください。 |
|
1024 |
8192 |
多言語 |
Snowflakeのコストパフォーマンスに優れた多言語埋め込みモデルで、8000トークンのコンテキストウィンドウを持ちます。このオープンソースの568Mパラメーターモデルは、英語と英語以外のデータセットの両方で高い品質をもたらします。 |
|
1024 |
32,000 |
多言語 |
Voyageの多言語埋め込みモデル。このモデルは、英語データセットと非英語データセットの両方で高い品質をもたらします。詳細情報については、 Voyage Multilingual 2 のブログ記事をご覧ください。 |
一部の埋め込みモデルは、Cortex Searchの特定のクラウドリージョンでのみ利用可能です。リージョン/モデル別の可用性リストについては、 Cortex Searchリージョン別可用性 をご参照ください。
モデルごとにパフォーマンス、コスト、コンテキストウィンドウのサイズ、品質の特徴が異なります。モデルの仕様を注意深く確認し、特定のワークロードに最適なモデルを決定してください。100万トークンあたりのクレジット単位での各モデルコストに関する最も正確な情報については、Snowflakeサービス利用表 をご参照ください。
トークン、モデルコンテキストウィンドウ、テキスト分割¶
トークンは文字のシーケンスであり、大規模な言語モデルで処理できるテキストの最小単位です。近似値として、1トークンは英単語の約3/4、つまり約4文字に相当します。文字列のトークン数を計算するには、 COUNT_TOKENSCortex 関数 を使用します。例えば、 snowflake-arctic-embed-m-v1.5 モデルで埋め込む文字列のトークンを計算するとします。
各ベクトル埋め込みモデルは、前述の埋め込みモデルのテーブルに示されているように、テキスト入力のための固定サイズのコンテキストウィンドウをサポートしています。インデックス作成中と使用中の両方で、検索列の値に含まれるトークンの数がコンテキストウィンドウのサイズを超えると、Cortex Searchは文字列をコンテキストウィンドウのサイズに切り捨ててから、セマンティック検索のためにベクトル空間に埋め込みます。しかし、 Cortex Searchは、キーワードベースの検索にテキストの全文を使用します。
Snowflakeには、テキストを小さなチャンクに分割するための組み込み関数が用意されています。詳細については、 :doc:`SPLIT_TEXT_RECURSIVE_CHARACTER </sql-reference/functions/split_text_recursive_character-snowflake-cortex> ` をご参照ください。
Cortex Searchで最適な検索結果を得るために、Snowflakeは検索列のテキストを512トークン(約385英単語)以下のチャンクに分割することを推奨します。現在、``snowflake-arctic-embed-l-v2.0-8k``などのより長いコンテキスト埋め込みモデルがありますが、`調査<https://www.snowflake.com/en/engineering-blog/impact-retrieval-chunking-finance-rag/>`__では、*チャンクサイズが小さいほど、一般的に検索やダウンストリームのLLMの応答品質が良くなる*ことが示されています。チャンクが小さいと、特定のクエリや検索拡張生成(RAG)シナリオでより正確な検索が行われ、ダウンストリームの LLM は、クエリにより関連度の高いテキストチャンクを受け取ります。
リフレッシュ¶
Cortex Search Serviceで提供されるコンテンツは、特定のクエリの結果に基づいています。Cortex Search Serviceの基礎となるデータが変更されると、サービスはその変更を反映して更新されます。これらの更新は リフレッシュ と呼ばれます。このプロセスは自動化されており、テーブルの基礎となるクエリを分析します。
Cortex Search Serviceは動的テーブルと同じ更新プロパティを持っています。Cortex Search Serviceのリフレッシュの特徴については、 動的なテーブルの初期化とリフレッシュの理解 のトピックをご参照ください。
Cortex Search Serviceのソースクエリは、動的テーブルの増分リフレッシュの候補でなければなりません。これらの要件の詳細については、 増分リフレッシュのサポート をご参照ください。この制限は、ベクトル埋め込み計算に伴う不要なコストの暴走を防ぐためのものです。動的テーブルの増分リフレッシュでサポートされないコンストラクトの詳細については、 動的テーブルでサポートされるクエリ をご参照ください。
主キー¶
Cortex Search Serviceの主キーは、ソースクエリの各行を一意に識別するオプションの列セットです(つまり、指定された列の値の正確な組み合わせを持つのは1行だけ)。Cortex Search Serviceで使用するには、主キー列は TEXT データタイプである必要があります。
主キーは、次のようにサービスを作成するときに指定できます。
既存のサービスの主キー列は ALTER CORTEX SEARCH SERVICE ... SET PRIMARY KEY (...) で変更できます。詳細な構文については、 ALTER CORTEX SEARCH SERVICE をご参照ください。
主キーを持つサービスは、サービスの基礎となるデータが変更されたときに、最適化されたリフレッシュパスを利用できます。この最適化されたパスにより、リフレッシュのコストとレイテンシを大幅に削減することができます。この最適化を有効にすると、検索サービスは、リフレッシュ中に生成されたインデックス情報を定期的に圧縮します。サービスの``FULL_INDEX_BUILD_INTERVAL_DAYS``プロパティを設定することで、インデックスの更新のターゲット頻度を指定できます。構文について詳しくは、/sql-reference/sql/create-cortex-search`および:doc:/sql-reference/sql/alter-cortex-search`を参照してください。
注釈
``FULL_INDEX_BUILD_INTERVAL_DAYS``は、ソフトターゲットです。サービスのターゲットラグ、サービスソースデータの変更率、サービス全体のサイズなどの要因に基づいて提供パフォーマンスを最適化するため、フル再構築は指定された間隔よりも頻繁に発生する可能性があります。
主キーを持つサービスに対するクエリは、@primarykeyフィルター演算子 も使用できます。
重要
主キー列値のセットは、ソースクエリの各行に対して一意である必要があります。結果の検索インデックスでは、重複は無視されます。
マルチインデックスCortex Search¶
Cortex Searchは、複数の列にインデックスを付けたり、クエリにカスタムベクトル埋め込みを使用したりでき、Cortex Search Serviceがデータを解釈し、ユーザーリクエストに応答する方法に柔軟性を持たせることができます。以下のいずれかを特徴とするユースケースがある場合は、マルチインデックスCortex Searchを使用する必要があります。
複数の検索フィールド:ユーザーは、記録のさまざまなフィールドで検索する必要があります。
ユーザー提供のベクトル埋め込み:Cortex Search Serviceに取り込む前に、1つまたは複数の列に対して事前に計算されたベクトル埋め込みがあります。
検索タイプの混合:検索の種類を優先して、さまざまなフィールドの検索をサポートしたいとします。
正確またはファジーキーワードの一致が重要なフィールドには、テキストインデックス を使用します。例は、製品コード、名前、カテゴリです。
セマンティックの理解が価値のある、より長いテキストコンテンツのフィールドには、ベクトルインデックス を使用します。例には、製品の説明、ユーザーレビュー、サポートケースなどがあります。
フィールド固有の関連性:データの異なるフィールドは、検索結果の関連性とは異なるかたちで貢献する必要があります。
たとえば、製品カタログ検索のユースケースでは、次の場合にマルチインデックスサービスを作成できます。
製品名と SKUs は、正確なレキシカル一致のための テキストインデックス です。
製品説明は、セマンティックマッチングのための ベクトルインデックス です。
カテゴリ名とブランド名は両方ともテキストインデックス と ベクトルインデックスであり、レキシカル一致とセマンティック一致の両方をサポートします。
マルチインデックスCortex Search Serviceの作成例については、 CREATE CORTEX SEARCH SERVICE ... TEXT INDEXES .. VECTOR INDEXES をご参照ください。マルチインデックスサービスのクエリの例については、 Cortex Search serviceをクエリする - マルチインデックスクエリ をご参照ください。
ユーザー提供のベクトル埋め込み¶
マルチインデックスCortex Searchでは、あらゆる埋め込みモデル(オープンソース、商用、カスタム学習済みモデルを含む)から生成された、事前計算済みのベクトル埋め込みを使用できます。次の場合にユーザー提供のベクトル埋め込みを使用します。
Cortex Searchでネイティブに利用できない埋め込みモデルを使用したい場合、またはコストを削減し、パフォーマンスを向上させるために、すでに生成している埋め込みを再利用したい場合。
ハイブリッド検索のために、ベクトル埋め込みとCortex Searchテキストインデックスを組み合わせたい場合。
VECTOR INDEXES句でモデルを指定せずに列名のみを指定した場合、Cortex Searchは列のコンテンツをユーザー提供のベクトル埋め込みとして扱います。ユーザーが提供したベクトルはそのままインデックス付けされ、埋め込みコストはかかりません。
注釈
ベクトルをSnowflakeテーブルに直接ロードすることはできません。代わりに、Cortex Search Serviceのソーステーブルにデータを挿入または更新する際に、数値の配列をVECTORデータ型にキャストします。これを行う方法の詳細と例については、:ref:`label-data_type_vector_conversion`を参照してください。
Cortex Searchは、検索リクエストにクエリベクトルを提供するか、クエリテキストを提供するかに応じて、検索時に以下のモードのいずれかを選択します。
モード |
インデックス作成時 |
クエリ実行時 |
|---|---|---|
完全にユーザー管理 |
VECTOR列でベクトルを提供 |
multi_index_query経由でクエリベクトルを提供 |
管理されたクエリ埋め込みによるユーザー管理 |
VECTOR列でベクトルを提供 |
Cortex Searchは、指定されたモデルを使用してクエリテキストを埋め込みます。 |
インデックス作成とサービングの停止¶
動的テーブルと同様に、Cortex Search Serviceは、ソースクエリに関連するリフレッシュが5回連続して失敗した場合、インデックス作成状態を自動的に一時停止します。お客様のサービスでこのエラーが発生した場合、 SQL または DESCRIBE CORTEX SEARCH SERVICE のいずれかを使用して、特定の CORTEX_SEARCH_SERVICES ビュー エラーを表示できます。両者の出力には以下の列が含まれます。
一時停止されたサービスの場合はSUSPENDEDとなるINDEXING_STATE列。
ソースクエリで発生した特定のSQLエラーが格納されるINDEXING_ERROR列。
ルート問題が解決すれば、 ALTER CORTEX SEARCH SERVICE <名前> RESUME INDEXING でサービスを再開できます。詳細な構文については、 ALTER CORTEX SEARCH SERVICE をご参照ください。
コストの考慮事項¶
Cortex Search Serviceでは、以下のようなコストが発生します。
カテゴリ |
説明 |
|---|---|
バーチャルウェアハウスコンピューティング |
Cortex Search Serviceは、サービスをリフレッシュするために 仮想ウェアハウス を必要とします。これは、テキスト埋め込みジョブのオーケストレーションや検索インデックスの構築など、初期化およびリフレッシュ時にベースオブジェクトに対してクエリを実行するためです。これらのオペレーションはコンピューティングリソースを使用しますが、これが クレジット を消費します。リフレッシュ中に変更が識別されなかった場合、リフレッシュする新しいデータがないため、仮想ウェアハウスクレジットは消費されません。 |
EMBED_TEXT トークン計算 |
Cortex Search Serviceは、 |
マルチインデックスCortex Search |
マルチインデックスCortex Search Serviceには、トークンの埋め込み方法とインデックスの列数に応じてコストがかかります。埋め込みベクトルが大きい場合やインデックス列の数が多い場合は、コストが高くなります。埋め込みは、行が挿入または更新されるたびに計算されます。埋め込みはソースクエリの評価の中で段階的に処理されるため、埋め込みコストは追加または変更された文書に対してのみ発生します。 |
使用中コンピュート |
Cortex Search Serviceは、ユーザーが提供する仮想ウェアハウスとは別に、マルチテナントのサービングコンピュータを使用し、低レイテンシーで高スループットのサービスを確立します。このコンポーネントの計算コストは、 GB/月 (GB/月) の非圧縮インデックスデータあたりで発生します。インデックスデータとは、Cortex Searchソースクエリ内のユーザー提供データと、ユーザーに代わって計算されたベクトル埋め込みです。クエリに応答するためにサービスが利用可能である間、一定の期間にクエリが提供されなかった場合でも、これらのコストが発生します。インデックスされたデータ GB/月あたりのCortex Search Servingクレジットレートについては、 Snowflake Service Consumption Table をご参照ください。 |
ストレージ |
Cortex Search Serviceは、ソースクエリをお客様のアカウントに保存されているテーブルに実体化します。このテーブルは、低レイテンシ配信に最適化されたデータ構造に変換され、お客様のアカウントにも保存されます。テーブルと中間データ構造のストレージは、1テラバイトあたりの定額制(TB)基づいています。 |
クラウドサービス コンピュート |
Cortex Search Servicesは、 Cloud Servicesのコンピュート を使用して、基になるオブジェクトの変更と、仮想ウェアハウスを呼び出す必要があるかどうかを識別します。クラウドサービスのコンピューティングコストには、日次クラウドサービスコストがアカウントの日次ウェアハウスコストの10%より大きい場合にのみ、Snowflakeによって請求されるという制約が適用されます。 |
Cortex Search Serviceのコスト管理のベストプラクティスについては、 Cortex Search Serviceのコストについて を参照してください。
アカウントの各Cortex Search Serviceの AI サービス 関連の消費コストを日次で集計して表示するには、 CORTEX_SEARCH_DAILY_USAGE_HISTORY ビュー をご覧ください。
既知の制限¶
Cortex Searchの使用には以下の制限があります。
ベース・テーブル・サイズ: 検索サービスのマテリアライズド・クエリの結果は、最適なパフォーマンスを維持するために、100M行未満のサイズである必要があります。クエリのマテリアライズド結果が 100M 行を超える場合、作成クエリはエラーで失敗します。
注釈
連絡先Cortex Search Serviceの行スケーリング制限を100M以上に増やすには、Snowflakeアカウントチームまでご連絡ください。
スループットとレートの制限:クライアントのリクエスト送信が早すぎる場合、またはサービスが過負荷になった場合にCortex Searchは429 HTTP ステータスコードを返します。検索サービスを呼び出すクライアントロジックは、これらの429応答を正常に処理するために、バックオフと再試行ロジックを実装する必要があります。
注釈
単一の検索サービスで20 QPS を超えてスループットを増やす、またはアカウントのすべてのサービスで 140 QPS スループットに増やすには、Snowflakeアカウントチームにお問い合わせください。
クエリ構造:Cortex Search Serviceのソースクエリは、動的テーブルと同じクエリ制限に従わなければなりません。詳細については 動的テーブルの制限 をご覧ください。
データ保持:Cortex Search Serviceには、データ保持に関して動的テーブルと同じ要件があります。具体的には、ベーステーブルの DATA_RETENTION_TIME_IN_DAYS オブジェクトパラメーターをゼロに設定すること、または検索サービスを含むスキーマまたはデータベースでこのパラメーターを設定することができません。さらに、検索サービスは、MAX_DATA_EXTENSION_TIME_IN_DAYS 内にリフレッシュされないと、古くなる可能性があります。一度古くなった場合は、リフレッシュを再開するために再作成する必要があります。詳細は 動的テーブルの制限 をご参照ください。
クローニング:Cortex Search Serviceは、現在 :doc:` クローニング </user-guide/object-clone>` をサポートしていません。Snowflakeは、将来のリリースでこの機能を提供する予定ですが、具体的な時期についての保証はできません。
テーブルの不変性:実行中、Cortex Search Serviceでは、変更またはドロップされていないテーブルが必要です。Cortex Search Serviceで使用されるテーブルを安全に更新するには、変更を行う前にサービスを停止します。
リージョンの可用性¶
この機能のサポートは、以下のSnowflakeリージョンのアカウントで利用可能です。リージョン内の特定の埋め込みモデルの可用性は、チェックマークで示されます。
クラウドプロバイダー
|
リージョン
|
snowflake-arctic-embed-m-v1.5 |
snowflake-arctic-embed-l-v2.0 |
snowflake-arctic-embed-l-v2.0-8k |
voyage-multilingual-2 |
|---|---|---|---|---|---|
AWS
|
US 西部2(オレゴン州)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
US 東部2(オハイオ)
|
✔ |
✔ |
✔ |
|
AWS
|
US 東部1(北部バージニア)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
US 東部(商業組織、バージニア政府北部)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
カナダ(中部)
|
✔ |
✔ |
✔ |
|
AWS
|
南米(サンパウロ)
|
✔ |
✔ |
✔ |
|
AWS
|
ヨーロッパ(アイルランド)
|
✔ |
✔ |
✔ |
|
AWS
|
ヨーロッパ(ロンドン)
|
✔ |
✔ |
✔ |
|
AWS
|
ヨーロッパ中部1(フランクフルト)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
ヨーロッパ(ストックホルム)
|
✔ |
✔ |
✔ |
|
AWS
|
アジア太平洋(東京)
|
✔ |
✔ |
✔ |
✔ |
AWS
|
アジア太平洋(ムンバイ)
|
✔ |
✔ |
✔ |
|
AWS
|
アジア太平洋(シドニー)
|
✔ |
✔ |
✔ |
|
AWS
|
アジア太平洋(ジャカルタ)
|
✔ |
✔ |
✔ |
|
AWS
|
アジア太平洋(ソウル)
|
✔ |
✔ |
✔ |
|
Azure
|
東 US 2(バージニア)
|
✔ |
✔ |
✔ |
|
Azure
|
西 US 2(ワシントン)
|
✔ |
✔ |
✔ |
|
Azure
|
南中央 US (テキサス)
|
✔ |
✔ |
✔ |
|
Azure
|
UK 南部(ロンドン)
|
✔ |
✔ |
✔ |
|
Azure
|
北ヨーロッパ(アイルランド)
|
✔ |
✔ |
✔ |
|
Azure
|
西ヨーロッパ(オランダ)
|
✔ |
✔ |
✔ |
✔ |
Azure
|
スイス北部(チューリッヒ)
|
✔ |
✔ |
✔ |
|
Azure
|
インド中部(プネー)
|
✔ |
✔ |
✔ |
|
Azure
|
日本東部(東京)
|
✔ |
✔ |
✔ |
|
Azure
|
東南アジア(シンガポール)
|
✔ |
✔ |
✔ |
|
Azure
|
オーストラリア東部(ニューサウスウェールズ)
|
✔ |
✔ |
✔ |
|
GCP
|
ヨーロッパ西部2(ロンドン)
|
✔ |
✔ |
✔ |
|
GCP
|
ヨーロッパ西部3(フランクフルト)
|
✔ |
✔ |
✔ |
|
GCP
|
ヨーロッパ西部4(オランダ)
|
✔ |
✔ |
✔ |
|
GCP
|
中東セントラル2(ダンマーム)
|
✔ |
✔ |
✔ |
|
GCP
|
US 中央部1(アイオワ)
|
✔ |
✔ |
✔ |
|
GCP
|
US 東部4(北部バージニア)
|
✔ |
✔ |
✔ |
注釈
上記のリージョンのいずれかで、 クロスリージョン推論パラメーター を指定することで、デフォルトリージョンでは直接サポートされていないモデルにアクセスすることができます。
Cortex Searchはクロスリージョン推論を使用する場合 のみ、以下のリージョンで利用可能です。クロスリージョン推論でCortex Searchを使用するには、 クロスリージョン推論パラメーター を使います。
AWS ヨーロッパ(パリ)
AWS ヨーロッパ(チューリッヒ)
AWS アジア太平洋(シンガポール)
AWS アジア太平洋(大阪)
Azureカナダ中部(トロント)
Azure中部US(アイオワ)
Azure UAE 北部(ドバイ)
注釈
クロスリージョン推論を使用する場合、リージョン間のクエリ遅延はクラウドプロバイダーのインフラストラクチャとネットワークステータスに依存します。Snowflakeでは、クロスリージョン推論を有効にして特定のユースケースをテストすることを推奨しています。
法的通知¶
インプットとアウトプットのデータ分類は以下の表の通りです。
入力データの分類 |
出力データの分類 |
指定 |
|---|---|---|
Usage Data |
Customer Data |
一般的に利用可能な関数は、カバーされている AI 機能です。プレビュー関数は、 AI 機能をプレビューします。[1] |
詳細については、 Snowflake AI と ML をご参照ください。