ベクトル埋め込み¶
埋め込み は構造化されていないテキストのような高次元のデータを、ベクトルのような次元数の少ない表現に縮小することを指します。最新のディープラーニング技術は、テキストや画像などの非構造化データから、構造化された数値表現であるベクトル埋め込みを生成することができ、ベクトルの幾何学における類似性と非類似性のセマンティック概念を保持することができます。
以下の図は、自然言語テキストのベクトル埋め込みと幾何学的類似性の簡略化された例です。実際には、ニューラルネットワークは、ここで示したような2次元ではなく、何百、何千という次元の埋め込みベクトルを生成しますが、コンセプトは同じです。意味的に類似したテキストは、同じ一般的な方向を「ポイントする」ベクトルを生成します。
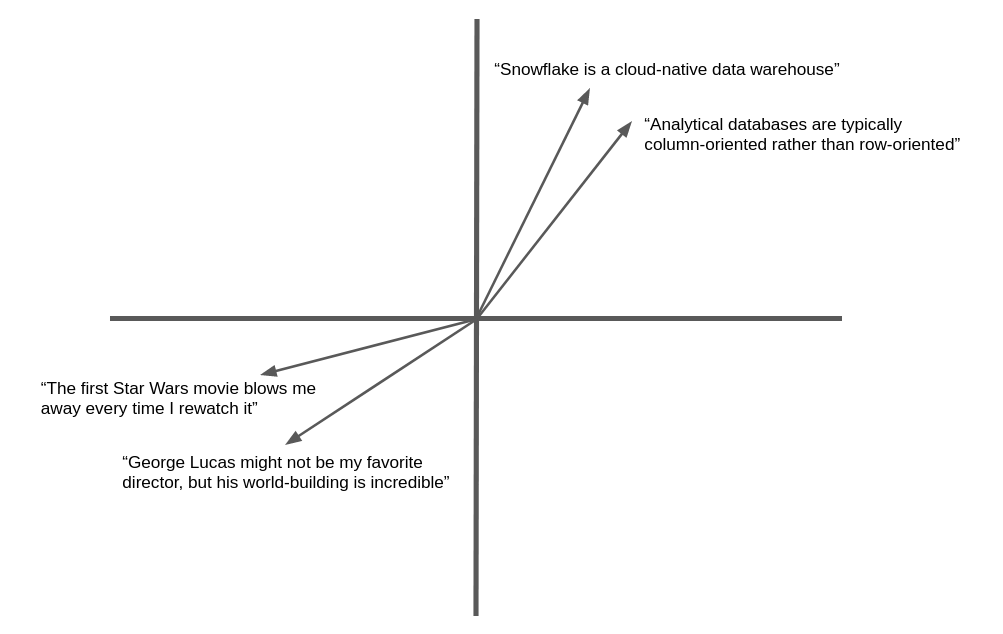
多くのアプリケーションは、ターゲットに類似したテキストや画像を検索する機能から恩恵を受けることができます。例えば、新しいサポートケースがヘルプデスクにログされると、サポートチームはすでに解決された類似のケースを見つけることができます。このアプリケーションで埋め込みベクトルを使用する利点は、キーワードのマッチングを超えて意味的な類似性を実現することで、まったく同じ単語が含まれていなくても関連する記録を見つけることができることです。
Snowflake Cortexには、 EMBED_TEXT_768 および EMBED_TEXT_1024 関数と、さまざまなアプリケーション向けにそれらを比較するためのいくつかの ベクトル関数 が用意されています。
テキスト埋め込みモデル¶
Snowflakeでは、以下のテキスト埋め込みモデルを提供しています。詳細については、 以下 をご参照ください。
モデル名 |
出力次元 |
コンテキストウィンドウ |
言語サポート |
|---|---|---|---|
snowflake-arctic-embed-m-v1.5 |
768 |
512 |
英語のみ |
snowflake-arctic-embed-m |
768 |
512 |
英語のみ |
e5-base-v2 |
768 |
512 |
英語のみ |
snowflake-arctic-embed-l-v2.0 |
1024 |
512 |
多言語 |
voyage-multilingual-2 |
1024 |
32000 |
多言語(サポートされている言語) |
nv-embed-qa-4 |
1024 |
512 |
英語のみ |
サポートされるモデルでは、 コスト が異なる可能性があります。
ベクトル類似関数について¶
ベクトル間の類似度の測定は、意味比較における基本的な操作です。Snowflake Cortexは、 VECTOR_INNER_PRODUCT、 VECTOR_L1_distance、 VECTOR_L2_DISTANCE、および VECTOR_COSINE_SIMILARITY の4つのベクトル類似性関数を提供します。これらの関数の詳細については、 ベクトル関数 をご参照ください。
構文や使い方の詳細については、各関数のリファレンスページをご参照ください。
例¶
以下の例では、ベクトルの類似性関数を使用しています。
この SQL の例では、VECTOR_INNER_PRODUCT 関数を使用して、 a 列と b の間で、テーブル内のどのベクトルが互いに最も近いかを判定しています。
この SQL の例では、 VECTOR_COSINE_SIMILARITY 関数を呼び出して、 [1,2,3] に近いベクトルを求めています。
Snowflake Pythonコネクタ¶
これらの例は、VECTORデータ型とベクトル類似性関数をPython Connectorで使用する方法を示しています。
注釈
VECTOR型のサポートはSnowflake Python Connectorのバージョン3.6で導入されました。
Snowpark Python¶
これらの例は、Snowpark Python ライブラリでVECTORデータ型とベクトル類似性関数を使用する方法を示しています。
注釈
VECTOR型のサポートはSnowpark Pythonのバージョン1.11で導入されました。
Snowpark Pythonライブラリは VECTOR_COSINE_SIMILARITY 関数をサポートしていません。
テキストからベクトル埋め込みを作成する¶
テキストからベクトル埋め込みを作成するには、モデルの出力次元に応じて、 EMBED_TEXT_768 (SNOWFLAKE.CORTEX) または EMBED_TEXT_1024 (SNOWFLAKE.CORTEX) 関数を使用できます。この関数は、与えられた英語テキストに対するベクトル埋め込みを返します。このベクトルは、 ベクトル比較関数 と共に使用することで、2つのドキュメントの意味的類似度を決定することができます。
Tip
Snowpark Container Services を通して他の埋め込みモデルを使用することができます。詳細については、 テキスト埋め込みコンテナーサービス をご参照ください。
重要
EMBED_TEXT_768とEMBED_TEXT_1024はCortex LLM関数であるため、その使用には他のCortex LLM関数と同じアクセス制御が適用されます。これらの関数へのアクセス方法については、 Cortex LLM 関数の必須権限 をご参照ください。
使用例¶
このセクションでは、埋め込み、ベクトル類似度関数、VECTORデータ型を使用して、ベクトル類似度検索や検索拡張生成(RAG)などの一般的なユースケースを実装する方法を示します。
ベクトル類似性検索¶
意味的に類似したドキュメントの検索を行うには、まず検索対象のドキュメントの埋め込みを保存します。ドキュメントが追加または編集された場合、埋め込みは常に最新の状態に保たれます。
この例では、ドキュメントはサポート担当者がログに記録したコールセンターの問題です。この問題は、テーブル issues の issue_text という列に格納されています。次のSQLは、問題の埋め込みを保持する新しいベクトル列を作成します。
検索を実行するには、検索語またはターゲットドキュメントの埋め込みを作成し、類似の埋め込みを持つドキュメントを見つけるためにベクトルの類似性関数を使用します。ORDER BY と LIMIT 句を使用して、 k にマッチする上位のドキュメントを選択し、オプションで WHERE 条件を使用して最小類似度を指定します。
通常、ベクトル類似性関数の呼び出しは、WHERE句ではなく、SELECT句に記述します。この方法では、WHERE句で指定された行に対してのみ関数が呼び出されます。この関数は、テーブル内のすべての行を操作するのではなく、他の条件に基づいてクエリを制限することができます。WHERE句で類似値をテストするには、SELECT句でVECTOR_COSINE_SIMILARITY呼び出し用の列エイリアスを定義し、WHERE句の条件でそのエイリアスを使用します。
この例では、検索語との余弦類似度が少なくとも0.7であると仮定して、過去90日間の検索語に一致する最大5つの項目を検索します。
検索拡張世代(RAG)¶
検索支援型生成(RAG)では、ユーザーのクエリを用いて、 ベクトル類似度 を用いて類似ドキュメントを検索します。最上位ドキュメントはユーザーのクエリとともに大規模言語モデル(LLM)に渡され、生成応答(完了)のためのコンテキストを提供します。そうすることで、応答の適切さを大幅に改善することができます。
以下の例では、 wiki はテキスト列 content を持つテーブルで、 query はテキスト列 text を持つ1行のテーブルです。
コストの考慮事項¶
EMBED_TEXT_768とEMBED_TEXT_1024を含むSnowflake Cortex LLM関数は、処理されたトークンの数に基づいてコンピューティングコストが発生します。
注釈
トークンは、Snowflake Cortex LLM関数で処理されるテキストの最小単位で、テキストの4文字にほぼ同じです。トークンに相当する生の入力または出力テキストは、モデルによって異なる場合があります。
EMBED_TEXT_768およびEMBED_TEXT_1024関数では、入力トークンのみが請求可能合計にカウントされます。
ベクトル類似性関数はトークンベースのコストを発生させません。
Cortex LLM 関数の請求に関する情報については、 Cortex LLM 関数 コストに関する考察 をご参照ください。計算コストに関する一般的な情報については、 コンピューティングコストについて をご参照ください。