マイクロパーティションとデータクラスタリング¶
従来のデータウェアハウスは、許容可能なパフォーマンスを実現し、より優れたスケーリングを可能にするために、大きなテーブルの静的パーティションに依存しています。これらのシステムでは、 パーティション は、特殊な DDL と構文を使用して個別に操作される管理単位です。ただし、静的パーティションには、メンテナンスオーバーヘッドやデータスキューなど、既知の制限がいくつかあり、パーティションのサイズが不均衡になる可能性があります。
データウェアハウスとは対照的に、Snowflake Data Platformは、 マイクロパーティショニング と呼ばれる強力で独自のパーティショニング形式を実装しています。これにより、既知の制限なしに、静的パーティショニングのメリットすべてと、有意義なメリットを追加で提供します。
注意
ハイブリッドテーブル は、標準的なSnowflakeテーブルで利用可能なクラスタリングキーなど、一部の機能をサポートしていないアーキテクチャに基づいています。
マイクロパーティションとは何ですか?¶
Snowflakeテーブル内のすべてのデータは、連続したストレージ単位であるマイクロパーティションに自動的に分割されます。各マイクロパーティションには、50 MB 〜500 MB の非圧縮データが含まれます(データは常に圧縮されて保存されるため、Snowflakeの実際のサイズは小さいことに注意してください)。テーブル内の行のグループは個々のマイクロパーティションにマップされ、列指向の状態に編成されます。このサイズと構造により、非常に大きなテーブルの非常にきめ細かなプルーニングが可能になります。これは数百万、または数億のマイクロパーティションで構成することができます。
Snowflakeは、以下を含む、マイクロパーティションに保存されているすべての行に関するメタデータを保存します:
マイクロパーティションの各列の値の範囲。
個別の値の数。
最適化と効率的なクエリ処理の両方に使用される追加のプロパティ。
注釈
すべてのSnowflakeテーブルでマイクロパーティションが自動的に実行されます。テーブルは、挿入/ロードされるデータの順序を使用して透過的にパーティション分割されます。
マイクロパーティション分割の利点¶
テーブルデータのパーティション分割に対するSnowflakeのアプローチの利点は次のとおりです:
従来の静的パーティション化とは対照的に、Snowflakeマイクロパーティションは自動的に派生します。事前に明示的に定義したり、ユーザーが保守したりする必要はありません。
名前が示すように、マイクロパーティションのサイズは小さく(50から500 MB、圧縮前)、非常に効率的な DML およびきめ細かいプルーニングにより、クエリを高速化できます。
マイクロパーティションは、値の範囲内で重複する可能性があり、均一に小さいサイズと組み合わせて、スキューを防ぐのに役立ちます。
列は、マイクロパーティション内に独立して保存され、多くの場合、 列指向ストレージ と呼ばれます。これにより、個々の列を効率的にスキャンできます。クエリによって参照される列のみがスキャンされます。
列は、マイクロパーティション内で個別に圧縮されます。Snowflakeは、各マイクロパーティションの列に対して最も効率的な圧縮アルゴリズムを自動的に決定します。
これらの各テーブルにクラスタリングキーを指定することで、特定のテーブルでクラスタリングを有効にすることができます。クラスタリングキーの指定については、以下をご参照ください。
クラスター化するテーブルを選択するための戦略など、クラスタリングに関する追加情報については、以下をご参照ください。
マイクロパーティションの影響¶
DML¶
すべての DML 操作(例: DELETE、 UPDATE、 MERGE)は基礎となるマイクロパーティションメタデータを利用して、テーブルのメンテナンスを容易にし、簡素化します。例えば、テーブルからすべての行を削除するなどの一部の操作は、メタデータのみの操作です。
テーブル列の削除¶
テーブルの列がドロップされると、ドロップされた列のデータが含まれるマイクロパーティションは、ドロップステートメントの実行時に再書き込みされません。ドロップされた列のデータはストレージにそのまま残ります。詳細については、 ALTER TABLE の 使用上の注意 をご参照ください。
クエリプルーニング¶
Snowflakeが保持するマイクロパーティションメタデータを使用すると、クエリの実行時にマイクロパーティション内の列(半構造化データを含む列を含む)を正確にプルーニングできます。言い換えると、範囲内の値の10%にアクセスする値の範囲でフィルター述語を指定するクエリは、理想的にはマイクロパーティションの10%のみをスキャンする必要があります。
例えば、大きなテーブルに日付と時間の列を持つ、1年間の履歴データが含まれているとします。データが均一に分布していると仮定すると、特定の時間を対象とするクエリは、理想的にはテーブル内の1/8760番目のマイクロパーティションをスキャンし、時間列のデータを含むマイクロパーティションの部分のみをスキャンします。Snowflakeはパーティションの列状スキャンを使用するため、クエリが1列でのみフィルターする場合、パーティション全体はスキャンされません。
言い換えれば、スキャンされたマイクロパーティションと列指向データの比率が選択された実際のデータの比率に近いほど、テーブルで実行されるプルーニングはより効率的です。
時系列データの場合、このレベルのプルーニングにより、範囲内(つまり、「スライス」)のクエリに対して1時間以下の細粒度の潜在的な応答時間が可能になります。
すべての述語式をプルーニングに使用できるわけではありません。たとえば、Snowflakeは、サブクエリの結果が定数になる場合でも、サブクエリの述語に基づいてマイクロパーティションをプルーニングしません。
データクラスタリングとは¶
通常、テーブルに格納されているデータは、自然の次元(例えば、日付や地理的地域など)に沿って並べ替えられます。この「クラスタリング」は、特に非常に大きなテーブルで、ソートされていないか、部分的にしかソートされていないテーブルデータがクエリのパフォーマンスに影響を及ぼす可能性があるため、クエリの重要な要素です。
Snowflakeでは、データがテーブルに挿入/ロードされると、プロセス中に作成された各マイクロパーティションのクラスタリングメタデータが収集および記録されます。Snowflakeは、このクラスタリング情報を活用して、クエリ中のマイクロパーティションの不要なスキャンを回避し、これらの列を参照するクエリのパフォーマンスを大幅に向上させます。
次の図は、日付でソートされた4つの列を持つSnowflakeテーブル t1 を示しています:
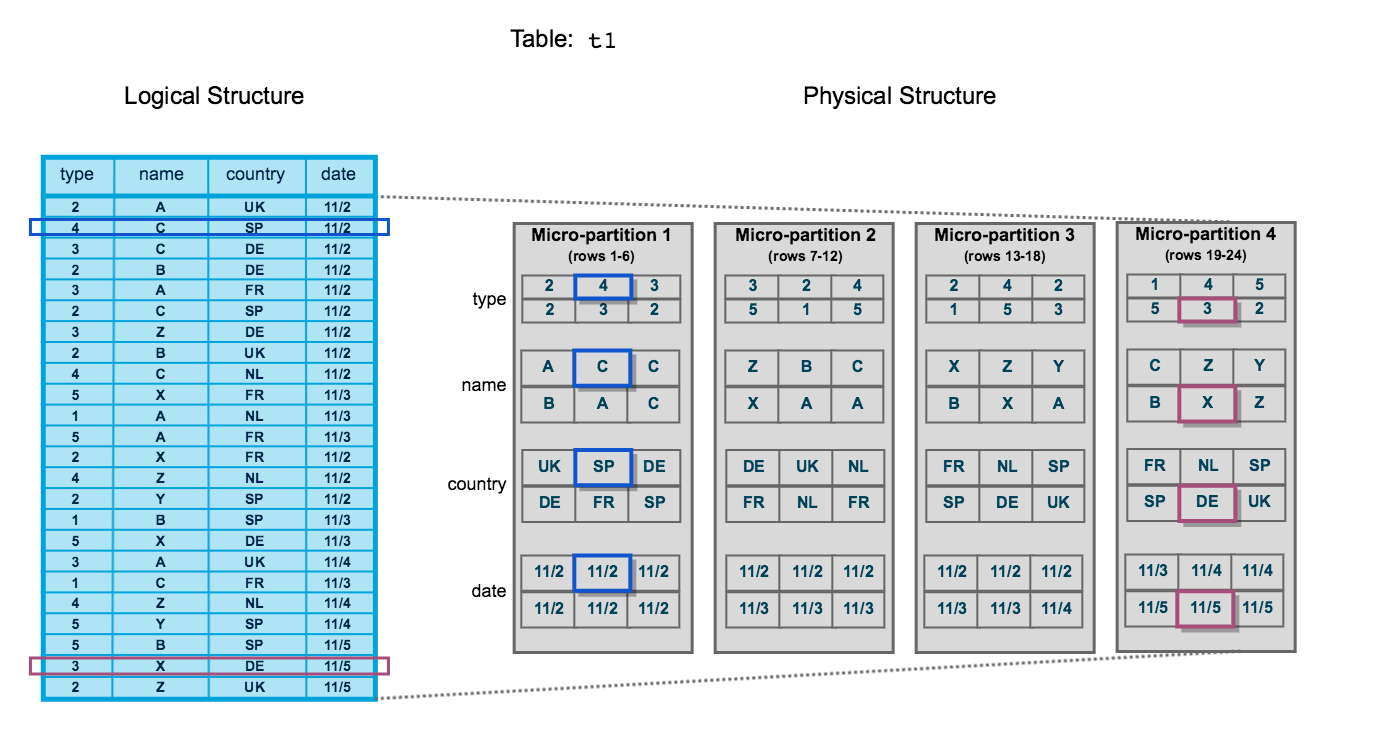
テーブルは、4個のマイクロパーティションに保存された24行で構成され、各マイクロパーティション間で行が均等に分割されます。各マイクロパーティション内で、データは列ごとに並べ替えられて保存されます。これにより、Snowflakeはテーブルのクエリに対して次のアクションを実行できます:
まず、クエリに不要なマイクロパーティションをプルーニングします。
次に、残りのマイクロパーティション内の列ごとにプルーニングします。
この図は、Snowflakeがマイクロパーティションで使用するデータクラスタリングの小規模な概念的表現としてのみ意図されていることに注意してください。典型的なSnowflakeテーブルは、数千、さらには数百万ものマイクロパーティションで構成されます。
マイクロパーティション用に維持されるクラスタリング情報¶
Snowflakeは、以下のような、マイクロパーティションのクラスタリングメタデータをテーブルに保持します:
テーブルを構成するマイクロパーティションの総数。
(テーブル列の指定されたサブセット内で)互いに重複する値を含むマイクロパーティションの数。
重なり合うマイクロパーティションの深さ。
クラスタリングの深さ¶
データが取り込まれたテーブルのクラスタリングの深さは、テーブル内の指定された列の重複するマイクロパーティションの平均深度(1 以上)を測定します。平均深度が小さいほど、指定された列に関するテーブルがよりクラスタ化されます。
クラスタリングの深さは、次のようなさまざまな目的に使用できます:
特に DML がテーブルで実行されるため、大きなテーブルのクラスタリングの「健全性」を監視します。
クラスタリングキー を明示的に定義することで大きなテーブルにメリットがあるかどうかを判断します。
マイクロパーティションのないテーブル(つまり、取り込まれていない/空のテーブル)のクラスタリングの深さは 0 です。
注釈
テーブルのクラスタリングの深さは、テーブルが適切にクラスタ化されているかどうかの絶対的または正確な尺度では ありません 。最終的に、クエリパフォーマンスは、テーブルがどれだけ適切にクラスタ化されているかを示す最適な指標です:
テーブルのクエリが必要または期待どおりに実行されている場合、テーブルは適切にクラスタ化されている可能性があります。
クエリのパフォーマンスが時間の経過とともに低下する場合、テーブルはおそらく十分にクラスタ化されておらず、クラスタリングの恩恵を受ける可能性があります。
クラスタリングの深さの図解¶
次の図は、AからZの範囲の値を持つ5つのマイクロパーティションで構成されるテーブルの概念例を示し、重複がクラスタリングの深さにどのように影響するかを示しています:
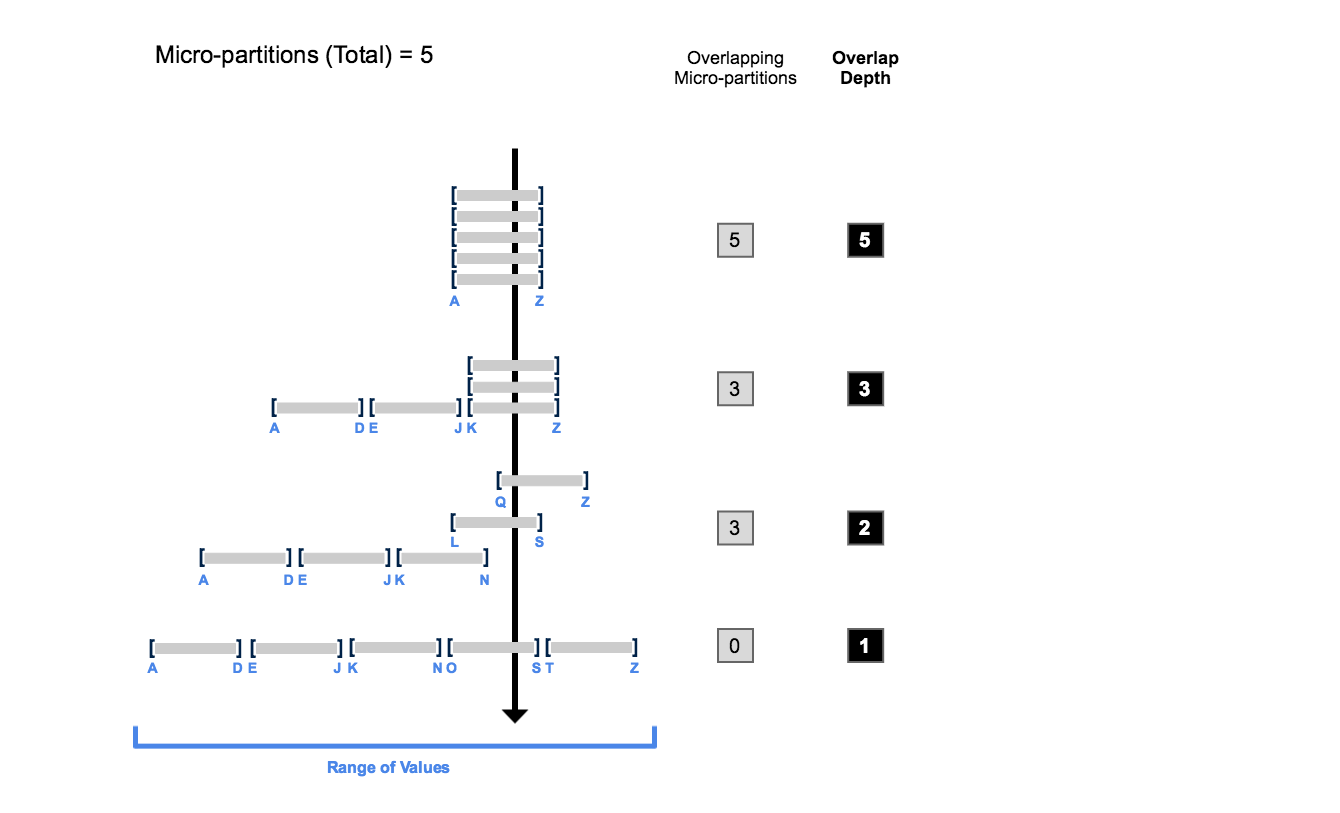
この図が示すように:
最初は、すべてのマイクロパーティションの値の範囲が重複しています。
重なり合うマイクロパーティションの数が減少すると、重なりの深さが減少します。
すべてのマイクロパーティションにわたって値の範囲に重複がない場合、マイクロパーティションは 一定の状態 であると見なされます(つまり、クラスタリングによって改善することはできません)。
この図は、実際のテーブルを表すものではありません。多数のマイクロパーティションにデータが含まれている実際のテーブルでは、クエリのパフォーマンスを向上させるために、すべてのマイクロパーティションで一定の状態に達することはほとんどなく、またその必要もありません。
テーブルのクラスタリング情報の監視¶
テーブルのクラスタリングメタデータを表示/監視するために、Snowflakeは次のシステム機能を提供します:
SYSTEM$CLUSTERING_INFORMATION (クラスタリングの深さを含む)
これらの関数がクラスタリングメタデータを使用する方法の詳細については、 クラスタリングの深さの図解 (このトピック)をご参照ください。