クラスタリングキーとクラスタ化されたテーブル¶
一般に、Snowflakeはテーブル内に適切にクラスタ化されたデータを生成します。ただし、時間の経過とともに、特に DML が非常に大きなテーブル(行数ではなくテーブル内のデータ量で定義される)で発生するため、一部のテーブル行のデータが必要なディメンションに適切ににクラスタ化されなくなる場合があります。
基礎となるテーブルマイクロパーティションのクラスタリングを改善するために、キーテーブル列の行をいつでも手動でソートし、テーブルに再挿入できます。ただし、これらのタスクの実行は面倒で費用がかかる可能性があります。
代わりに、Snowflakeは、1つ以上のテーブル列/式をテーブルの クラスタリングキー として指定することにより、これらのタスクの自動化をサポートしています。定義されたクラスタリングキーを持つテーブルは、 クラスタ化済み と見なされます。
マテリアライズドビュー だけでなく、テーブルもクラスタ化できます。テーブルとマテリアライズドビューをクラスタリングするためのルールは、一般的に同じです。マテリアライズドビューに特有ないくつかの追加のヒントについては、 マテリアライズドビューとクラスタリング と マテリアライズドビューのベストプラクティス をご参照ください。
注意
クラスタリングキーでは、最初にデータをクラスタリングし、クラスタリングを維持するコストがかかるため、すべてのテーブルを対象するものでは ありません。クラスタリングは、次のいずれかの場合に最適です。
コストに関係なく、可能な限り最速の応答時間が必要。
クエリパフォーマンスの向上により、テーブルのクラスター化と維持に必要なクレジットが相殺される。
クラスター化するテーブルの選択の詳細については、 テーブルのクラスタリングを選択する際の考慮事項 をご参照ください。
クラスタリングキーとは何ですか?¶
クラスタリングキーは、同じ マイクロパーティション 内のテーブル内のデータを共存させるために明示的に指定されたテーブル(またはテーブル上の式)の列のサブセットです。これは、順序が理想的ではなかった(データが挿入/ロードされた時点で)非常に大きなテーブルや、 DML によってテーブルの自然なクラスタリングが低下した場合に便利です。
テーブルのクラスタリングキーを定義するかどうかを判断するのに役立ついくつかの一般的なインジケータには次が含まれます。
テーブルのクエリの実行速度が予想よりも遅いか、時間が経つにつれて著しく低下します。
テーブルの クラスタリングの深さ は大きいです。
クラスタリングキーは、テーブルの作成時( CREATE TABLE コマンドを使用)またはその後( ALTER TABLE コマンドを使用)に定義できます。テーブルのクラスタリングキーは、いつでも変更または削除できます。
注意
ハイブリッドテーブル ではクラスタリングキーを定義できません。ハイブリッドテーブルでは、データは常に主キーによって順序付けられます。
クラスタリングキーを定義する利点(非常に大きなテーブルの場合)¶
クラスタリングキーを使用して、同じマイクロパーティション内の同様の行を同じ場所に配置すると、次のような非常に大きなテーブルでいくつかの利点が得られます。
フィルタリング述語と一致しないデータをスキップすることにより、クエリのスキャン効率が向上しました。
クラスタリングのないテーブルよりも列圧縮が向上します。これは、他の列がクラスタリングキーを構成する列と強く相関している場合に特に当てはまります。
テーブルでキーが定義された後、キーをドロップまたは変更することを選択しない限り、追加の管理は必要ありません。(最適なクラスタリングを保証するための)テーブル内の行に対する今後のすべてのメンテナンスは、Snowflakeによって自動的に実行されます。
クラスタリングによりパフォーマンスは大幅に改善され、一部のクエリのコストを削減できますが、クラスタリングの実行に使用される計算リソースはクレジットを消費します。そのため、クエリがクラスタリングの実質的なメリットを享受する場合にのみクラスタリングする必要があります。
通常、クエリは、テーブルのクラスタリングキーでフィルター処理または並べ替えを行う場合、クラスタリングの恩恵を受けます。ソートは通常、 ORDER BY 操作、 GROUP BY 操作、および一部の結合に対して行われます。例えば、次の結合により、Snowflakeがソート操作を実行する可能性があります。
この擬似例では、Snowflakeは my_materialized_view.col1 または my_table.col1 のいずれかの値をソートする可能性があります。たとえば、 my_table.col1 の値が並べ替えられている場合、マテリアライズドビューがスキャンされているときに、Snowflakeは my_table の対応する行をすばやく見つけることができます。
テーブルが頻繁にクエリされるほど、クラスタリングが提供する利益が増えます。ただし、テーブルが頻繁に変更されるほど、クラスタ化を維持するのに費用がかかります。したがって、一般的にクラスタリングは、頻繁にクエリされ、頻繁に変更されないテーブルに対して最も費用効果が高くなります。
テーブルのクラスタリングを選択する際の考慮事項¶
応答時間を短縮する場合でも、全体的なコストを削減する場合でも、クラスタリングは、次の基準の すべて を満たすテーブルに最適です。
テーブルには、多数の マイクロパーティション が含まれている。通常、これは、テーブルに複数テラバイト(TB)のデータが含まれていることを意味します。
クエリはクラスタリングを活用できる。通常、これは次のいずれかまたは両方が当てはまることを意味します。
クエリは選択的。つまり、クエリは、テーブル内の行のごく一部(したがって、通常はマイクロパーティションのごく一部)のみを読み取る必要があります。
クエリはデータを並べ替える。(たとえば、クエリにはテーブルで ORDER BY 句が含まれています。)
クエリの大部分は、同じクラスタリングキーの恩恵を受けられる。言い換えると、多くの/ほとんどのクエリは、同じ少数の列を選択するか、並べ替えます。
主に全体的なコストを削減することが目標である場合、各クラスター化テーブルは、 DML 操作(INSERT/UPDATE/DELETE)に対する高いクエリ比率が必要です。これは通常、テーブルが頻繁に照会され、頻繁に更新されないことを意味します。多くの DML が発生するテーブルをクラスター化する場合は、 DML ステートメントを大規模で頻度の低いバッチにグループ化することを検討してください。
また、テーブルのクラスター化を明示的に選択する前に、テーブルでクエリの代表セットをテストして、パフォーマンスベースラインを確立することを、Snowflakeは 強く お勧めします。
クラスタリングキーを選択するための戦略¶
単一のクラスタリングキーには、1つ以上の列または式を含めることができます。ほとんどのテーブルでは、Snowflakeはキーごとに最大3または4列(または式)を推奨しています。3〜4を超える列を追加すると、利益よりもコストが増加する傾向があります。
クラスタリングキーに適切な列/式を選択すると、クエリのパフォーマンスに劇的な影響を与える可能性があります。ワークロードの分析により、通常、適切なクラスタリングキー候補が得られます。
Snowflakeは、以下の順序でキーに優先順位を付けることをお勧めします。
選択フィルターで最もアクティブに使用されるクラスタ列。日付ベースのクエリに関係する多くのファクトテーブル(例:WHERE invoice_date > x AND 請求日 <= y」)の場合、日付列を選択することをお勧めします。イベントテーブルでは、多数の異なるイベントタイプがある場合にイベントタイプが適切な選択になる場合があります。(テーブルに含まれるイベントタイプが少数の場合は、クラスタリングキーとしてイベント列を選択する前に、以下のカーディナリティに関するコメントを参照してください。)
追加のクラスタキーの余地がある場合は、結合述語で頻繁に使用される列、例:「FROM table1 JOIN table2 ON table2.column_A = table1.column_B」を検討してください。
通常、クエリを2つのディメンション(例: application_id 列と user_status 列)でフィルター処理する場合、両方の列でクラスタリングするとパフォーマンスが向上します。
列/式内の個別の値の数(つまり、カーディナリティ)は、クラスタリングキーとして選択する重要な側面です。以下を含むクラスタリングキーを選択することが重要です:
テーブルで効果的なプルーニングを可能にするために十分な数の個別の値。
Snowflakeが同じマイクロパーティション内の行を効果的にグループ化できるようにするための十分に少数の個別の値。
ブール値のみを含む IS_NEW_CUSTOMER という名前の列のように、カーディナリティが非常に低い列は、最小限のプルーニングのみを生成する可能性があります。その一方で、カーディナリティが非常に高い列も、通常、クラスタリングキーとして直接使用する候補には 適していません 。たとえば、ナノ秒のタイムスタンプ値を含む列はクラスタリングキーとしては不適切です。
Tip
一般に、列(または式)のカーディナリティが高い場合、その列でのクラスタリングの維持はより高価になります。
一意のキーでのクラスタリングのコストは、特にそのテーブルの主な使用例ではないポイントルックアップの場合、そのキーでのクラスタリングの利点を上回る場合があります。
カーディナリティが非常に高い列をクラスタリングキーとして使用する場合は、個別の値の数を減らすために、キーを列ではなく列の式として定義することをSnowflakeはお勧めします。式は、各パーティションの最小値と最大値でプルーニングが有効になるように、列の元の順序を保持する必要があります。
例えば、ファクトテーブルに、多くの離散値(テーブル内のマイクロパーティションの数よりも多く)を含む TIMESTAMP 列 c_timestamp がある場合、タイムスタンプではなく日付に値をキャストすることで、列にクラスタリングキーを定義できます(例: to_date(c_timestamp))。これにより、カーディナリティが合計日数に削減され、より優れたプルーニング結果が通常生成されます。
別の例として、 TRUNC 関数とスケールの負の値(例: TRUNC(123456789, -5))を使用して、数値をより少ない有効桁数に切り捨てることができます。
Tip
テーブルに複数列のクラスタリングキーを定義する場合は、 CLUSTER BY 句で指定される列の順序が重要です。原則として、Snowflakeは列を 最低 カーディナリティから 最高 カーディナリティに並べることを推奨しています。一般に、低いカーディナリティ列の前に高いカーディナリティ列を配置すると、後者の列でのクラスタリングの有効性が低下します。
Tip
テキストフィールドでクラスタリングする場合、クラスターキーメタデータは最初の数バイト(通常は5または6バイト)のみを追跡します。マルチバイト文字セットの場合、これは5 文字 より少なくなる可能性があることに注意してください。
場合によっては、 GROUP BY または ORDER BY 句で使用される列のクラスタリングが役立つ場合があります。ただし、通常、これらの列のクラスタリングは、フィルター操作または JOIN 操作で頻繁に使用される列のクラスタリングよりも有用性が低くなります。フィルター/結合操作で頻繁に使用される列と、 ORDER BY または GROUP BY 操作で使用される異なる列がある場合、フィルターおよび結合操作で使用される列を優先します。
再クラスタリング¶
クラスタ化されたテーブルで DML 操作(INSERT、UPDATE、DELETE、MERGE、COPY)が実行されると、テーブル内のデータのクラスタ化が低下する場合があります。最適なクラスタリングを維持するには、テーブルの定期的な再クラスタリングが必要です。
再クラスタリング中、Snowflakeはクラスタ化されたテーブルのクラスタリングキーを使用して列データを再編成し、関連するレコードが同じマイクロパーティションに再配置されるようにします。この DML 操作は、影響を受けるレコードを削除し、クラスタリングキーに従ってグループ化されたレコードを再挿入します。
注釈
Snowflakeの再クラスタリングは自動です。メンテナンスは必要ありません。詳細については、 自動クラスタリング をご参照ください。
ただし、特定のアカウントでは、手動の再クラスタリングは廃止されましたが、引き続き許可されています。詳細については、 手動再クラスタリング をご参照ください。
再クラスタリングのクレジットおよびストレージへの影響¶
Snowflakeのすべての DML 操作と同様に、再クラスタリングはクレジットを消費します。消費されるクレジットの数は、テーブルのサイズと再クラスタ化する必要があるデータの量によって異なります。
再クラスタリングは、ストレージコストももたらします。データが再クラスタ化されるたびに、テーブルのクラスタリングキーに基づいて行が物理的にグループ化されるため、Snowflakeはテーブルの 新しい マイクロパーティションを生成します。テーブルに少数の行を追加しても、それらの値を含むすべてのマイクロパーティションが再作成される可能性があります。
元のマイクロパーティションは削除済みとしてマークされていますが、Time TravelとFail-safeを有効にするためにシステムに保持されているため、このプロセスは大量のデータターンオーバーを引き起こす可能性があります。元のマイクロパーティションは、Time Travelの保持期間とそれに続くFail-safe期間の両方が経過した後にのみパージされます(つまり、Snowflake Enterprise以上を使用している場合、延長Time Travelの最小8日から最大97日)。これにより、通常、ストレージコストが増加します。詳細については、 Snowflake Time TravelおよびFail-safe をご参照ください。
重要
テーブルのクラスタリングキーを定義する前に、関連するクレジットとストレージのコストを考慮する必要があります。
再クラスタリングの例¶
前のトピックの クラスタリング図 に基づいて構築されたこの図は、テーブルの再クラスタリングがクエリのパフォーマンスを向上させるためにマイクロパーティションのスキャンを削減する方法を示しています:
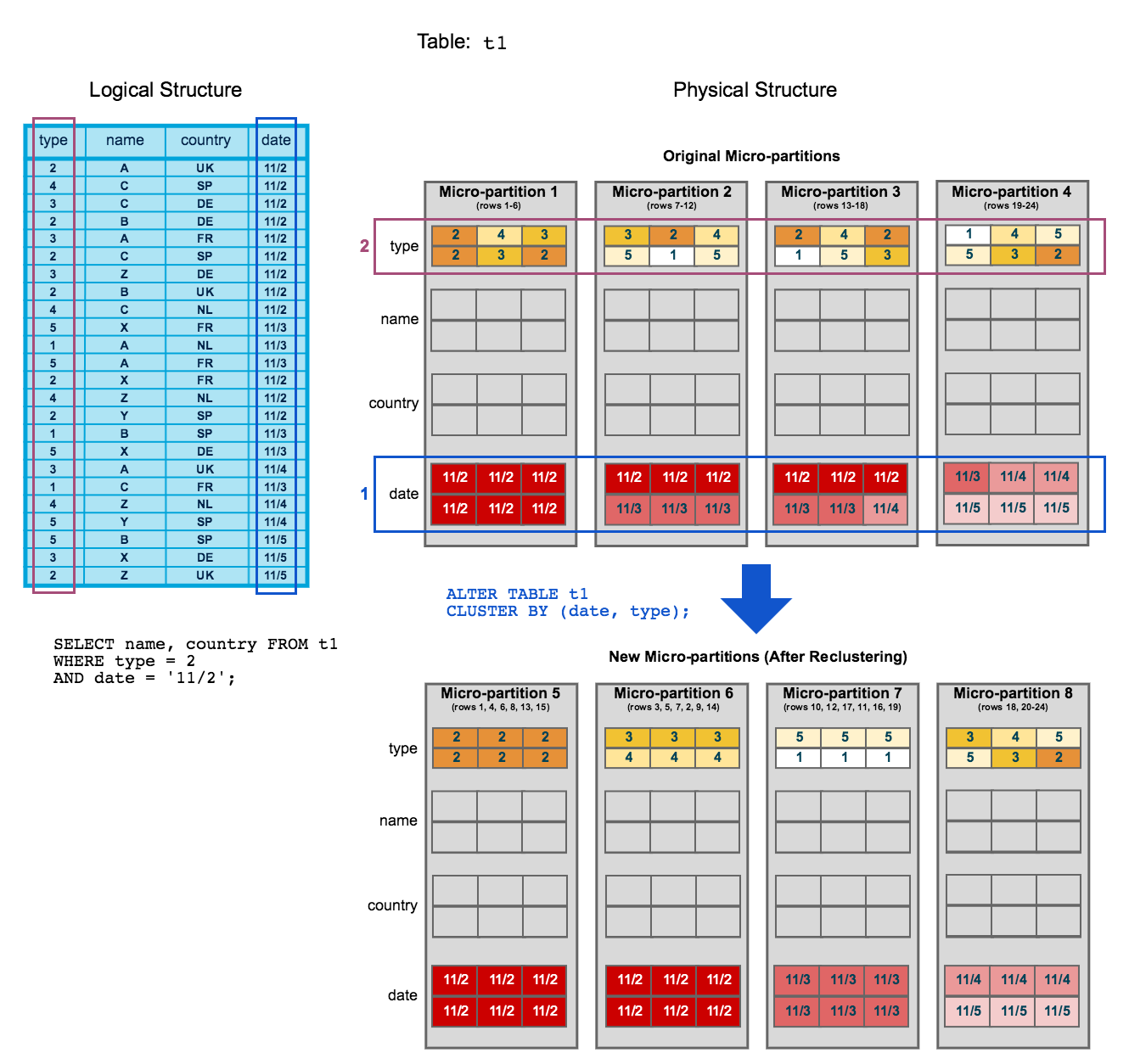
開始するには、テーブル
t1は、当然、マイクロパーティション1-4のdateによってクラスタ化されます。クエリ(図内)には、マイクロパーティション1、2、および3のスキャンが必要です。
dateおよびtypeはクラスタリングキーとして定義されます。テーブルが再クラスター化されると、新しいマイクロパーティション(5-8)が作成されます。再クラスタリング後、同じクエリはマイクロパーティション5のみをスキャンします。
さらに、再クラスタリング後、
マイクロパーティション5は 一定の状態 (つまり、再クラスタリングでは改善できない)に達しているため、将来のメンテナンスのために深さとオーバーラップを計算するときに除外されます。適切にクラスタ化された大きなテーブルでは、ほとんどのマイクロパーティションがこのカテゴリに分類されます。
元のマイクロパーティション(1-4)は削除済みとしてマークされますが、システムからは 削除されません 。 Time TravelおよびFail-safe 用に保持されます。
注釈
この例は、非常に小規模な再クラスタリングの影響を示しています。非常に大きなテーブル(つまり、数百万以上のマイクロパーティションで構成される)に外挿すると、再クラスタリングはスキャンに大きな影響を与える可能性があるため、クエリのパフォーマンスに影響を与える可能性があります。
クラスタ化されたテーブルの定義¶
テーブルのクラスタリング情報の計算¶
システム関数 SYSTEM$CLUSTERING_INFORMATION を使用して、特定のテーブルのクラスタリングの深さなどのクラスタリングの詳細を計算します。この関数は、テーブルに明示的なクラスタリングキーがあるかどうかに関係なく、任意のテーブルの任意の列で実行できます。
テーブルに明示的なクラスタリングキーがある場合、関数はテーブルの名前以外の入力引数を必要としません。
テーブルに明示的なクラスタリングキーがない場合(またはテーブルにクラスタリングキーがあるが、テーブル内の他の列の比率を計算する場合)、関数は追加の入力引数として目的の列を取ります。
テーブルのクラスタリングキーの定義¶
テーブルを作成するときに、 CREATE TABLE に CLUSTER BY 句を追加すると、クラスタリングキーを定義できます。
各クラスタリングキーが1つ以上のテーブル列/式で構成されている場合は、 GEOGRAPHY、 VARIANT、 OBJECT または ARRAY を 除く 任意のデータ型を使用できます。クラスタリングキーには、次のいずれかを含めることができます。
ベース列。
ベース列の式。
VARIANT 列のパスの式。
例:
重要な使用上の注意¶
VARCHAR 列ごとに、クラスタリングの現在の実装は最初の5バイトのみを使用します。
最初のN文字がすべての行で同じである場合、または十分なカーディナリティを提供しない場合は、同一の文字の後に始まり、最適なカーディナリティを持つサブストリングでクラスタリングすることを検討します。(最適なカーディナリティの詳細については、 クラスタリングキーを選択するための戦略 をご参照ください。)例:
2つ以上の列/式をテーブルのクラスタリングキーとして定義する場合、順序はデータがマイクロパーティションでどのようにクラスタ化されるかに影響を与えます。
詳細については、 クラスタリングキーを選択するための戦略 (このトピック)をご参照ください。
CREATE TABLE ... CLONE を使用してテーブルを作成すると、既存のクラスタリングキーがコピーされます。ただし、自動クラスタリングは、 クローン化されたテーブルでは中断 されているため、再開させる必要があります。
CREATE TABLE ... AS SELECT を使用してテーブルを作成する場合、既存のクラスタリングキーは サポートされません。ただし、テーブルの作成後にクラスタリングキーを定義できます。
VARIANT 列の上に直接クラスタリングキーを定義することはサポートされていません。ただし、パスとターゲットタイプで構成される式を指定する場合、クラスタリングキーに VARIANT 列を指定できます。
テーブルのクラスタリングキーの変更¶
ALTER TABLE を使用して、いつでも既存のテーブルにクラスタリングキーを追加したり、テーブルの既存のクラスタリングキーを変更したりできます。
例:
重要な使用上の注意¶
すでにデータが入力されているテーブルにクラスタリングキーを追加する場合、すべての式をキーに指定できるわけではありません。 SHOW FUNCTIONS を使用して、特定の関数がサポートされているかどうかを確認できます。
show functions like 'function_name';出力には、出力の最後に列
valid_for_clusteringが含まれます。この列には、データを入力したテーブルのクラスタリングキーで関数を使用できるかどうかが表示されます。テーブルのクラスタリングキーを変更しても、テーブルがSnowflakeによって再クラスタ化されるまで、テーブル内の既存のレコードには影響しません。
テーブルのクラスタリングキーの削除¶
ALTER TABLE を使用して、いつでもテーブルのクラスタリングキーを削除できます。
例: