ハイブリッドテーブルを作成する¶
このトピックでは、Snowflakeで ハイブリッドテーブル を作成する概要について説明します。
注釈
ハイブリッドテーブルを作成するには、セッションの現在のウェアハウスとして指定された実行中のウェアハウスが必要です。ハイブリッドテーブルの作成時に実行中のウェアハウスが指定されていないと、エラーが発生する場合があります。詳細については、 ウェアハウスでの作業 をご参照ください。
CREATE HYBRID TABLE オプション¶
ハイブリッド・テーブルは次のいずれかの方法で作成できます。
CREATE HYBRID TABLE。以下の例では、必須 PRIMARY KEY 制約を持つハイブリッドテーブルを作成し、行を挿入し、行を削除し、テーブルに問い合わせます。
CREATE HYBRID TABLE ... AS SELECT (CTAS) または CREATE HYBRID TABLE ... LIKE。例:
データのロード¶
注釈
ハイブリッドテーブルのプライマリストレージは行ストアであるため、ハイブリッドテーブルのストレージフットプリントは通常、標準テーブルよりも大きくなります。この違いの主な理由は、標準テーブルの列データは、しばしば高い圧縮率を達成するからです。ストレージコストの詳細については、 ハイブリッドテーブルのコスト評価 をご参照ください。
最適化された一括ロード¶
ハイブリッドテーブルへのデータの一括ロードは、データステージまたは他のテーブルからのコピー(CTAS、 COPY INTO <テーブル>、または INSERT INTO ... SELECT を使用)によって行うことができます。
一括ロードの最適化は、テーブルが一度も記録がロードされることなく新しく作成されるか、 CTAS クエリを使用して作成されるかに依存関係します。
ハイブリッド・テーブルが空の場合、3つのロード・メソッド (CTAS, COPY, INSERT INTO ... SELECT) はすべて、最適化されたバルク・ロードを使用してロード処理を高速化します。テーブルがロードされた後は、通常のパフォーマンス (INSERT) が適用されます。COPY、 INSERT INTO ... SELECT、インクリメンタルバッチロードを実行することはできますが、一般的に効率が悪くなります。バルクロードの速度は1分間に約100万記録が一般的ですが、テーブルの構造によって大きく異なる場合があります(たとえば、記録が大きいほどロードは遅くなります)。最適化された一括ロードは、将来のリリースで増分一括ロードをサポートするように拡張される予定です。
Snowsight クエリプロファイルで Statistics の情報を確認することで、バルクロード高速パスが使用されたかどうかを確認できます。高速パスが使用されている場合、 Number of rows inserted は Number of rows bulk loaded と呼ばれます。例えば、この CTAS 演算子は200000行を新しいテーブルに一括ロードします。
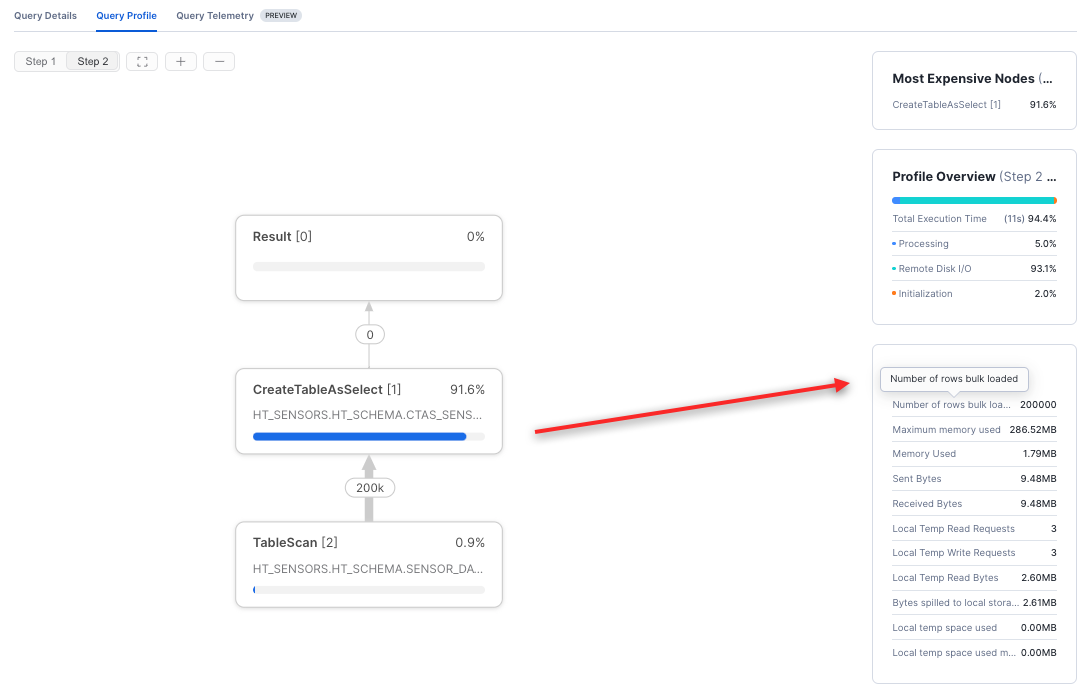
同じテーブルへの後続の増分一括ロードでは、最適化された一括ロードは使用されません。
クエリプロファイルの詳細については、 ハイブリッドテーブルのクエリプロファイルの分析 および クエリ履歴でクエリのアクティビティをモニターする をご参照ください。
注意
CTAS コマンドは FOREIGN KEY 制約をサポートしていません。ハイブリッドテーブルに FOREIGN KEY 制約が必要な場合は、 COPY または INSERT INTO ... SELECT を使用してテーブルをロードします。
注釈
Snowflakeテーブルにデータをロードする他の方法(Snowpipeなど)は、現在サポートされていません。
ロード中のインデックス構築エラー¶
インデックスのサイズは幅に制限があります。ハイブリッド・テーブルの列にインデックスを構築する場合、特に大容量の列にインデックスを構築する場合、テーブルをロードするコマンド (CTAS、 COPY、または INSERT INTO ... SELECT を含む)が以下のエラーを返すことがあります。この場合、テーブルには IDX_HT100_COLS というインデックスが含まれています:
このエラーが発生するのは、行ベースのストレージでは記録ごとに保存できるデータ(およびメタデータ)のサイズに制限があるためです。記録サイズを小さくするには、幅広の VARCHAR 列などの大きな列をインデックス列として指定せずにテーブルを作成してみてください。より少ない列でインデックスを作成してみることもできます。
ハイブリッドテーブルを作成するとき、またはハイブリッドテーブルにインデックスを作成するときに、セカンダリインデックスで INCLUDE 列を使用してみることもできます。詳細については、 INCLUDE列 をご参照ください。