pandas on Snowflake¶
pandas on Snowflake를 사용하면 pandas 코드를 Snowflake의 데이터에서 직접 실행할 수 있습니다. 가져오기 문과 몇 줄의 코드를 변경하기만 하면 익숙한 pandas 경험을 통해 강력한 파이프라인을 개발하면서 파이프라인이 확장됨에 따라 Snowflake의 성능과 확장성을 원활하게 활용할 수 있습니다.
pandas on Snowflake는 :ref:`하이브리드 실행<label-pandas-hybrid-execution>`을 사용하여 pandas 코드를 로컬에서 실행할지 또는 Snowflake 엔진을 사용하여 규모를 확장하고 성능을 개선할지를 지능적으로 결정합니다. Snowflake에서 대규모 데이터 세트로 작업하는 경우 SQL로의 변환을 통해 Snowflake에서 기본적으로 워크로드를 실행하여 병렬화와 Snowflake의 데이터 거버넌스 및 보안 이점을 활용할 수 있습니다.
pandas on Snowflake는 Snowpark pandas API를 통해 제공되며, 이는 Snowflake 플랫폼 내에서 Python 코드의 확장 가능한 데이터 처리를 활성화하는 :doc:`Snowpark Python 라이브러리</developer-guide/snowpark/python/index>`의 일부로 제공됩니다.
pandas on Snowflake 사용의 이점¶
Python 개발자에게 익숙한 인터페이스 제공: pandas on Snowflake는 Snowflake에서 기본적으로 실행할 수 있는 pandas 호환 계층을 공급하여 Python 개발자에게 익숙한 인터페이스를 제공합니다.
확장 가능한 분산형 pandas: pandas on Snowflake는 Snowflake에서 기존의 쿼리 최적화 기법을 활용하여 pandas의 편의성과 Snowflake의 확장성을 연결합니다. 최소한의 코드 재작성만 필요하므로 마이그레이션 과정이 간소화되어 프로토타입에서 프로덕션으로 원활하게 변환할 수 있습니다.
관리 및 조정할 추가 컴퓨팅 인프라가 필요 없음: pandas on Snowflake는 Snowflake의 강력한 컴퓨팅 엔진을 활용하므로 추가 컴퓨팅 인프라를 설정하거나 관리할 필요가 없습니다.
pandas on Snowflake 시작하기¶
참고
pandas on Snowflake를 사용하는 방법에 대한 실습 예제는 이 `Notebook<https://github.com/Snowflake-Labs/snowflake-python-recipes/blob/main/pandas%20on%20Snowflake%20101/pandas%20on%20Snowflake%20101.ipynb>`_을 확인하고 이 `동영상<https://www.youtube.com/watch?v=p9eX0QQGiZE>`_을 시청하세요.
pandas on Snowflake를 설치하려면 conda 또는 pip를 사용하여 패키지를 설치할 수 있습니다. 자세한 지침은 설치 섹션을 참조하십시오.
pandas on Snowflake가 설치되면 pandas를 import pandas as pd 로 가져오는 대신 다음 두 줄을 사용합니다.
다음은 Modin을 사용하여 pandas on Snowpark Python 라이브러리를 통해 pandas on Snowflake를 사용하는 방법의 예제입니다.
:code:`read_snowflake`는 Snowflake 뷰, 동적 테이블, Iceberg 테이블 등에서 읽기를 지원합니다. SQL 쿼리를 직접 전달하고 pandas on Snowflake DataFrame를 다시 가져와 SQL과 pandas on Snowflake 간을 쉽고 원활하게 이동할 수도 있습니다.
하이브리드 실행의 작동 방식¶
참고
Snowpark Python 버전 1.40.0부터는 pandas on Snowflake를 사용할 때 하이브리드 실행이 기본적으로 활성화됩니다.
pandas on Snowflake는 하이브리드 실행을 사용하여 pandas 코드를 로컬에서 실행할지 Snowflake 엔진을 사용하여 규모를 확장하고 성능을 개선할지를 결정합니다. 이를 통해 코드를 실행하는 가장 최적의 효율적인 방법을 생각할 필요 없이 친숙한 pandas 코드를 계속 작성하여 강력한 파이프라인을 개발하면서, 파이프라인이 확장됨에 따라 Snowflake의 성능과 확장성을 원활하게 활용할 수 있습니다.
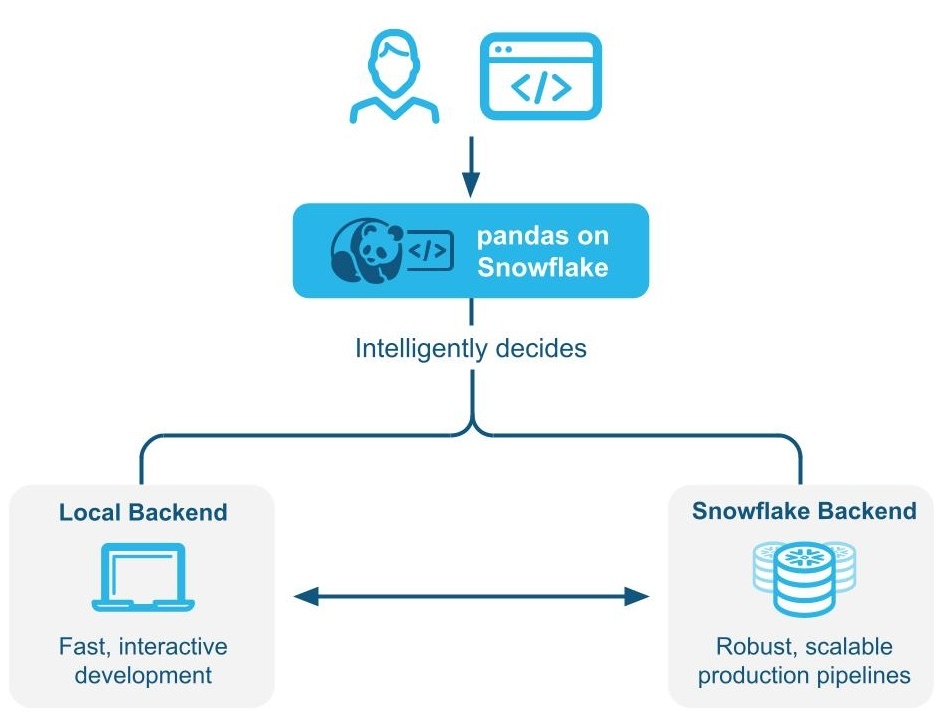
예 1: 작은 11행 DataFrame를 인라인으로 만듭니다. 하이브리드 실행을 사용하면 Snowflake는 작업을 실행하기 위해 로컬 메모리 내 pandas 백엔드를 선택합니다.
예 2: 1,000만 개의 트랜잭션 행이 있는 테이블 시드
Snowflake에 있는 대규모 테이블이므로 테이블이 Snowflake를 백엔드로 활용하는 것을 볼 수 있습니다.
예 3: 데이터를 필터링하고 groupby 집계를 수행하여 7개 행의 데이터를 생성합니다.
데이터가 필터링되면 출력이 7행의 데이터에 불과하므로 Snowflake는 백엔드 엔진 변경 사항의 백엔드 선택 항목을 Snowflake에서 pandas로 암시적으로 인식합니다.
참고 및 제한 사항¶
DataFrame 유형은 백엔드가 변경되는 경우에도 항상 :code:`modin.pandas.DataFrame/Series/etc`이므로 다운스트림 코드와의 상호 운용성 및 호환성이 보장됩니다.
사용할 백엔드를 결정하기 위해 Snowflake는 각 단계에서 DataFrame의 정확한 길이를 계산하는 대신, 행 크기 추정치를 사용하는 경우가 있습니다. 즉, Snowflake는 데이터 세트가 더 커지거나 작아질 때(예: 필터, 집계) 작업 직후에 항상 최적의 백엔드로 전환하지는 못할 수 있습니다.
여러 백엔드 간에 둘 이상의 DataFrames를 결합하는 작업이 있는 경우 Snowflake는 가장 낮은 데이터 전송 비용을 기준으로 데이터를 이동할 위치를 결정합니다.
Snowflake가 필터링된 기본 데이터의 크기를 추정하지 못할 수 있으므로 필터 작업을 수행해도 데이터가 이동되지 않을 수 있습니다.
메모리 내 Python 데이터로 구성된 DataFrames는 다음과 같이 pandas 백엔드를 사용합니다.
DataFrames는 제한된 작업 세트에서 Snowflake 엔진으로부터 pandas 엔진으로 자동 이동합니다. 이러한 작업에는
df.apply,df.plot,df.iterrows,df.itertuples, :code:`series.items`가 포함되고, 축소 작업을 통해 더 작은 데이터 크기가 보장될 수 있습니다. 데이터 마이그레이션이 발생할 수 있는 지점에서 모든 작업이 지원되는 것은 아닙니다.:code:`pd.concat`와 같은 작업이 여러 DataFrames에서 수행되는 경우를 제외하고 하이브리드 실행은 pandas 엔진에서 Snowflake로 DataFrame을 자동으로 이동하지 않습니다.
:code:`pd.concat`과 같은 작업이 여러 DataFrames에 작동하지 않는 한, Snowflake는 DataFrame을 pandas 엔진에서 Snowflake로 자동으로 다시 이동하지 않습니다.
pandas on Snowflake를 사용해야 하는 경우¶
다음 중 하나라도 해당하는 경우 pandas on Snowflake를 사용해야 합니다.
사용자가 pandas API와 더 광범위한 PyData 생태계에 대해 익숙합니다.
사용자가 pandas에 익숙하고 동일한 코드베이스에서 협업하고자 하는 다른 사람들과 함께 팀에서 일하고 있습니다.
pandas로 작성된 기존 코드가 있습니다.
보다 정확한 코드 완성을 위해 AI 기반 Copilot 도구를 선호합니다.
자세한 내용은 Snowpark DataFrames vs Snowpark pandas DataFrame: 어떤 것을 선택해야 할까요? 섹션을 참조하십시오.
Snowpark DataFrames과 함께 pandas on Snowflake 사용하기¶
pandas on Snowflake와 DataFrame API는 상호 운용성이 뛰어나기 때문에 두 가지 APIs를 모두 활용하는 파이프라인을 구축할 수 있습니다. 자세한 내용은 Snowpark DataFrames vs Snowpark pandas DataFrame: 어떤 것을 선택해야 할까요? 섹션을 참조하십시오.
다음 작업을 사용하여 Snowpark DataFrames와 Snowpark pandas DataFrames 간의 변환을 수행할 수 있습니다.
작업 |
입력 |
출력 |
|---|---|---|
Snowpark DataFrame |
Snowpark pandas DataFrame |
|
Snowpark pandas DataFrame 또는 Snowpark pandas 시리즈 |
Snowpark DataFrame |
pandas on Snowflake와 네이티브 pandas 비교 방법¶
pandas on Snowflake와 네이티브 pandas는 일치하는 시그니처와 유사한 DataFrame APIs와 유사한 의미 체계를 가지고 있습니다. pandas on Snowflake는 네이티브 pandas와 동일한 API 시그니처를 제공하며 확장 가능한 계산을 Snowflake로 제공합니다. pandas on Snowflake는 네이티브 pandas 문서에서 설명하는 의미 체계를 최대한 존중하지만 Snowflake 계산 및 유형 시스템을 사용합니다. 그러나 네이티브 pandas가 클라이언트 머신에서 실행되면 Python 계산 및 유형 시스템을 사용합니다. pandas on Snowflake와 Snowflake 간의 유형 매핑에 대한 정보는 :ref:`데이터 타입<label-snowpark_pandas_data_types>`을 참조하세요.
Snowpark Python 1.40.0부터, pandas on Snowflake는 이미 Snowflake에 존재하는 데이터와 함께 사용할 때 가장 효과적입니다. 네이티브 pandas와 pandas on Snowflake 간을 전환하려면 다음 작업을 사용하세요.
작업 |
입력 |
출력 |
|---|---|---|
Snowpark pandas DataFrame |
네이티브 pandas DataFrame - 모든 데이터를 로컬 환경에 구체화합니다. 데이터 세트가 큰 경우 메모리 부족 오류가 발생할 수 있습니다. |
|
네이티브 pandas DataFrame, 원시 데이터, Snowpark pandas 오브젝트 |
Snowpark pandas DataFrame |
실행 환경¶
pandas: 단일 머신에서 작동하며 메모리 내 데이터를 처리합니다.pandas on Snowflake: Snowflake와 통합되어 대규모 데이터 세트의 경우 머신 클러스터 전체에 분산 컴퓨팅을 허용하는 동시에 메모리 내 pandas를 활용하여 작은 데이터 세트를 처리할 수 있습니다. Snowpark pandas API를 사용하려면 Snowflake에 연결해야 합니다.
지연 평가 및 즉시 평가¶
pandas: 각 작업 후에 즉시 작업을 실행하고 결과를 메모리에 완전히 구체화합니다. 이 즉시 작업 평가는 머신 내에서 데이터를 광범위하게 이동해야 하기 때문에 메모리 부담을 가중시킬 수 있습니다.pandas on Snowflake: pandas와 동일한 API 경험을 제공합니다. pandas의 즉시 평가 모델을 모방하지만, 내부적으로는 지연 평가 쿼리 그래프를 구축하여 작업 전반에 걸쳐 최적화를 가능하게 합니다.쿼리 그래프를 통해 작업을 융합하고 트랜스파일링하면 기본 분산형 Snowflake 컴퓨팅 엔진에 대한 추가적인 최적화 기회를 얻을 수 있어, pandas를 Snowflake 내에서 직접 실행할 때보다 비용과 엔드투엔드 파이프라인 런타임이 모두 감소합니다.
데이터 소스 및 저장소¶
pandas: IO 도구(텍스트, CSV, HDF5, …) 에서 pandas 설명서에 나열된 다양한 독자 및 작성자를 지원합니다.pandas on Snowflake: Snowflake 테이블에서 읽고 쓸 수 있으며 로컬 또는 스테이징된 CSV, JSON, Parquet 파일을 읽을 수 있습니다. 자세한 내용은 IO(읽기 및 쓰기) 섹션을 참조하세요.
데이터 타입¶
pandas: 정수, 부동 소수점, 문자열,datetime타입, 범주형 타입 등 다양한 데이터 타입을 지원합니다. 또한 사용자 정의 데이터 타입도 지원합니다. pandas의 데이터 타입은 일반적으로 기본 데이터에서 파생되며 엄격하게 적용됩니다.pandas on Snowflake: pandas 데이터 타입을 Snowflake의 SQL 타입으로 변환하여 pandas 오브젝트를 SQL에 매핑하는 Snowflake 타입 시스템에 의해 제약됩니다. 대부분의 pandas 유형은 Snowflake에서 자연스럽게 대응되지만 매핑이 항상 1:1로 이루어지는 것은 아닙니다. 경우에 따라 여러 개의 pandas 타입이 동일한 SQL 타입에 매핑되는 경우도 있습니다.
다음 테이블에는 pandas와 Snowflake SQL 간 유형 매핑이 나와 있습니다.
pandas 타입 |
Snowflake 유형 |
|---|---|
모든 부호화/부호화되지 않은 정수 유형, pandas 확장 정수 유형 포함 |
NUMBER(38, 0) |
모든 부동소수점 타입, pandas 확장 부동소수점 데이터 타입 포함 |
FLOAT |
|
BOOLEAN |
|
STRING |
|
TIME |
|
DATE |
모든 시간대 무관 |
TIMESTAMP_NTZ |
모든 시간대 인식 |
TIMESTAMP_TZ |
|
ARRAY |
|
MAP |
혼합 데이터 타입을 갖는 오브젝트 열 |
VARIANT |
Timedelta64[ns] |
NUMBER(38, 0) |
참고
범주형, 기간형, 간격형, 희소형 및 사용자 정의 데이터 타입은 지원되지 않습니다. Timedelta는 현재 Snowpark 클라이언트의 panda에서만 지원됩니다. Timedelta를 다시 Snowflake에 쓰면 Number 유형으로 저장됩니다.
다음 테이블은 df.dtypes 를 사용하여 Snowflake SQL 유형을 pandas on Snowflake 유형에 다시 매핑한 것입니다.
Snowflake 유형 |
pandas on Snowflake 유형( |
|---|---|
NUMBER( |
|
NUMBER ( |
|
BOOLEAN |
|
STRING, TEXT |
|
VARIANT, BINARY, GEOMETRY, GEOGRAPHY |
|
ARRAY |
|
OBJECT |
|
TIME |
|
TIMESTAMP, TIMESTAMP_NTZ, TIMESTAMP_LTZ, TIMESTAMP_TZ |
|
DATE |
|
Snowpark pandas DataFrame에서 :code:`to_pandas()`를 사용하는 네이티브 pandas DataFrame으로 변환할 때, 네이티브 pandas DataFrame은 함수 및 프로시저에 대해 :ref:`label-sql_python_data_type_mappings`와 호환되는 pandas on Snowflake 타입에 비해 정제된 데이터 타입을 갖게 됩니다.
형변환 및 타입 추론¶
pandas: NumPy 를 준수하며 기본적으로 암시적 형변환과 추론을 위해 NumPy 및 Python 타입 시스템을 따릅니다. 예를 들어, 부울을 정수형으로 취급하므로1 + True는2를 반환합니다.pandas on Snowflake: 앞의 테이블에 따라 NumPy 및 Python 유형을 Snowflake 유형에 매핑하고, 암시적 타입 형변환 및 추론 에 기본 Snowflake 타입 시스템을 사용합니다. 예를 들어, 논리 데이터 타입 에 따라 부울을 정수 유형으로 암시적으로 변환하지 않으므로1 + True는 형변환 오류가 발생합니다.
Null 값 처리¶
pandas: pandas 1.x 버전에서는 누락된 데이터를 처리 할 때 유연성이 우수하므로 모든 PythonNone,np.nan,pd.NaN,pd.NA및pd.NaT를 누락된 값으로 처리했습니다. 이후 버전의 pandas(2.2.x)에서는 이러한 값이 다른 값으로 처리됩니다.pandas on Snowflake: 나열된 모든 앞의 값을 누락된 값으로 처리하는 이전 pandas 버전과 유사한 접근법을 채택합니다. Snowpark는 pandas의NaN,NA및NaT를 재사용합니다. 그러나 이러한 모든 누락된 값은 서로 교환 가능하도록 취급되며 Snowflake 테이블에 SQL NULL로 저장됩니다.
오프셋/빈도 별칭¶
pandas: 버전 2.2.1에서는 pandas의 날짜 오프셋이 변경되었습니다. 한 글자 별칭'M','Q','Y'등은 더 이상 두 글자 오프셋용으로 사용되지 않습니다.pandas on Snowflake: pandas 시계열 설명서 에 설명되는 새로운 오프셋을 독점적으로 사용합니다.
pandas on Snowflake 라이브러리 설치하기¶
전제 조건
다음 패키지 버전이 필요합니다.
Python 3.9(사용 중단됨), 3.10, 3.11, 3.12 또는 3.13
Modin 버전 0.32.0
pandas 버전 2.2.*
팁
Snowflake Notebooks 에서 pandas on Snowflake를 사용하려면 노트북의 pandas on Snowflake 의 설정 지침을 참조하십시오.
개발 환경에 pandas on Snowflake를 설치하려면 다음 단계를 따릅니다.
프로젝트 디렉터리로 변경하고 Python 가상 환경을 활성화합니다.
참고
API는 현재 개발 중이므로 시스템 전체에 설치하기보다는 Python 가상 환경에 설치하는 것을 권장합니다. 그러면 생성하는 각 프로젝트에서 특정 버전을 사용할 수 있으므로 향후 버전이 변경되는 것을 방지할 수 있습니다.
`Anaconda<https://www.anaconda.com/>`_, `Miniconda<https://docs.conda.io/en/latest/miniconda.html>`_ 또는 `virtualenv<https://docs.python.org/3/tutorial/venv.html>`_와 같은 도구를 사용하여 특정 Python 버전에 대한 Python 가상 환경을 만들 수 있습니다.
예를 들어, conda를 사용하여 Python 3.12 가상 환경을 구축하려면 해당 명령을 실행합니다.
참고
이전에 Python 3.9 및 pandas 1.5.3을 사용하여 이전 버전의 pandas on Snowflake를 설치한 경우 위에 설명된 대로 Python 및 pandas 버전을 업그레이드해야 합니다. Python 3.10 또는 3.13으로 새 환경을 구축하는 단계를 따르세요.
Modin으로 Snowpark Python 라이브러리를 설치합니다.
또는
참고
snowflake-snowpark-python버전 1.17.0 이상이 설치되어 있는지 확인합니다.
Snowflake에 인증하기¶
pandas on Snowflake를 사용하기 전에 Snowflake 데이터베이스와 세션을 설정해야 합니다. 세션에 대한 연결 매개 변수를 선택하려면 구성 파일을 사용하거나 코드에서 열거하면 됩니다. 자세한 내용은 Snowpark Python용 세션 만들기 섹션을 참조하세요. 활성 상태의 고유 Snowpark Python 세션이 존재하면 pandas on Snowflake가 자동으로 해당 세션을 사용합니다. 예를 들면 다음과 같습니다.
:code:`pd.session`은 Snowpark 세션이므로 다른 Snowpark 세션에서 수행할 수 있는 모든 기능을 수행할 수 있습니다. 예를 들어, 이를 사용하여 임의의 SQL 쿼리를 실행할 수 있으며, 이 쿼리는 `세션 API<https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/snowpark/api/snowflake.snowpark.Session.sql>`_에 따라 Snowpark DataFrame을 생성하지만, 그 결과는 Snowpark pandas DataFrame이 아닌 Snowpark DataFrame이 됩니다.
또는 :ref:`구성 파일<label-python_connection_toml>`에서 Snowpark 연결 매개 변수를 구성할 수 있습니다. 그러면 코드에서 연결 매개 변수를 열거할 필요가 없으므로, 일반적으로 pandas 코드를 작성하는 것처럼 pandas on Snowflake 코드를 작성할 수 있습니다.
:file:`~/.snowflake/connections.toml`에 다음과 같은 구성 파일을 생성합니다.
이러한 자격 증명을 사용하여 세션을 만들려면 :code:`snowflake.snowpark.Session.builder.create()`를 사용합니다.
여러 개의 Snowpark 세션을 생성한 후 그중 하나를 pandas on Snowflake에 할당할 수도 있습니다. pandas on Snowflake는 하나의 세션만 사용하므로 :code:`pd.session = pandas_session`을 사용하여 pandas on Snowflake에 세션 중 하나를 명시적으로 할당해야 합니다.
다음 예제에서는 활성 Snowpark 세션이 없는 상태에서 pandas on Snowflake를 사용하는 경우 “pandas on Snowflake requires an active snowpark session, but there is none.”과 같은 오류와 함께 :code:`SnowparkSessionException`이 발생하는 모습을 보여 줍니다. 세션을 생성한 후에는 pandas on Snowflake를 사용할 수 있습니다. 예를 들면 다음과 같습니다.
다음 예제에서는 활성 Snowpark 세션이 여러 개 있을 때 pandas on Snowflake를 사용하려고 하면 “There are multiple active snowpark sessions, but you need to choose one for pandas on Snowflake.”라는 메시지와 함께 SnowparkSessionException 이 발생한다는 것을 보여 줍니다.
참고
새로운 pandas on Snowflake DataFrame 또는 계열에 사용되는 세션을 :code:`modin.pandas.session`을 통해 설정해야 합니다. 단, 다른 세션에서 생성된 DataFrames을 합치거나 병합하는 것은 지원되지 않으므로 워크플로에서 다른 세션을 설정하고 다른 세션으로 DataFrames을 반복해서 생성하는 것은 피해야 합니다.
API 참조¶
현재 구현된 APIs와 사용 가능한 메서드의 전체 목록은 pandas on Snowflake API 참조 섹션을 참조하십시오.
지원되는 작업의 전체 목록은 pandas on Snowflake 참조의 다음 테이블을 참조하십시오.
하이브리드 실행을 위한 APIs 및 구성 매개 변수¶
하이브리드 실행은 데이터 세트 크기 추정과 DataFrame에 적용되는 작업의 조합을 사용하여 백엔드 선택을 결정합니다. 일반적으로 100,000개 행 미만의 데이터 세트는 로컬 pandas를 사용하는 경향이 있습니다. 데이터 세트가 로컬 파일에서 로드되지 않는 한, 100,000개 행을 초과하는 행은 Snowflake를 사용하는 경향이 있습니다.
전송 비용 구성¶
기본 전환 임계값을 다른 행 제한 값으로 변경하려면 DataFrame를 초기화하기 전에 환경 변수를 수정하면 됩니다.
이 값을 설정하면 Snowflake 외부로 행을 전송하는 데 패널티가 적용됩니다.
로컬 실행 제한 구성¶
DataFrame이 로컬이고, 병합을 위해 Snowflake로 다시 이동할 필요가 없는 한 일반적으로 로컬로 유지되지만, 로컬에서 처리할 수 있는 데이터의 최대 크기에 대해 고려되는 상한이 있습니다. 현재 이 경계는 1,000만 개 행입니다.
백엔드 확인 및 설정¶
선택한 현재 백엔드를 확인하려면 `df.getbackend()<https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/modin/pandas_api/modin.pandas.DataFrame.get_backend#modin.pandas.DataFrame.get_backend>`_ 명령을 사용할 수 있습니다. 이 명령은 로컬 실행의 경우 ``Pandas``를 반환하고, 푸시다운 실행의 경우 ``Snowflake``를 반환합니다.
set_backend 또는 해당 별칭 :code:`move_to`를 사용하여 선택한 현재 백엔드를 설정하려면:
백엔드를 고정할 수도 있습니다.
데이터가 이동된 *이유*에 대한 정보를 검사하고 표시하려면:
백엔드를 고정하여 백엔드 선택 수동 재정의¶
기본적으로, Snowflake는 주어진 DataFrame 및 작업에 가장 적합한 백엔드를 자동으로 선택합니다. 자동 엔진 선택을 재정의하려면 `pin_backend()<https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/modin/pandas_api/modin.pandas.DataFrame.pin_backend#modin.pandas.DataFrame.pin_backend>`_ 메서드를 사용하여 오브젝트와 그로부터 생성된 모든 결과 데이터의 자동 전환을 비활성화할 수 있습니다.
자동 백엔드 전환을 다시 활성화하려면 `unpin_backend()<https://docs.snowflake.com/en/developer-guide/snowpark/reference/python/latest/modin/pandas_api/modin.pandas.DataFrame.unpin_backend#modin.pandas.DataFrame.unpin_backend>`_를 호출하세요.
Snowpark pandas를 Snowflake Notebook에 사용하기¶
Snowflake 노트북에서 pandas on Snowflake를 사용하려면 Snowflake 노트북의 pandas on Snowflake 를 참고하십시오.
Python 워크시트에서 Snowpark pandas 사용하기¶
Snowpark pandas를 사용하려면 Python 워크시트 환경의 Packages 에서 modin 을 선택하여 Modin을 설치해야 합니다.
Python 함수의 반환 유형은 Settings > Return type 에서 선택할 수 있습니다. 기본적으로 Snowpark 테이블로 설정되어 있습니다. 결과적으로 Snowpark pandas DataFrame 을 표시하려면 to_snowpark() 를 호출하여 Snowpark pandas DataFrame 을 Snowpark DataFrame 으로 변환할 수 있습니다. 이 변환에는 I/O 비용이 발생하지 않습니다.
다음은 Python 워크시트와 함께 Snowpark pandas를 사용하는 예입니다.
저장 프로시저에서 pandas on Snowflake 사용하기¶
저장 프로시저 에서 pandas on Snowflake를 사용하여 데이터 파이프라인을 구축하고 작업 으로 저장 프로시저의 실행을 예약할 수 있습니다.
SQL 을 사용하여 저장 프로시저를 만드는 방법은 다음과 같습니다.
다음은 Snowflake Python API 를 사용하여 저장 프로시저를 생성하는 방법입니다.
저장 프로시저를 호출하려면 Python에서 CALL run_data_transformation_pipeline_sp() 를 실행하거나 SQL에서 dt_pipeline_sproc() 를 실행하면 됩니다.
서드 파티 라이브러리와 함께 pandas on Snowflake 사용하기¶
pandas는 흔히 시각화 및 머신 러닝 애플리케이션을 위해 서드 파티 라이브러리 API와 함께 사용됩니다. pandas on Snowflake는 이러한 라이브러리 대부분과 상호 운용이 가능하므로 pandas DataFrames 로 명시적으로 변환하지 않고도 사용할 수 있습니다. 그러나 대부분의 서드 파티 라이브러리에서는 제한된 사용 사례를 제외하고는 분산 실행이 지원되지 않는 경우가 많다는 점에 유의하십시오. 따라서 대규모 데이터 세트에서는 성능이 느려질 수 있습니다.
지원되는 서드 파티 라이브러리¶
아래 목록에 있는 라이브러리는 pandas on Snowflake DataFrames 를 입력으로 허용하지만 모든 메서드가 테스트된 것은 아닙니다. API 수준에서 심층적인 상호 운용성 상태는 서드 파티 라이브러리와의 상호 운용성 섹션을 참조하십시오.
Plotly
Altair
Seaborn
Matplotlib
Numpy
scikit-learn
XGBoost
NLTK
Streamlit
pandas on Snowflake는 현재 np.where 에 대한 분산 구현 및 df.plot 과의 상호 운용성 등 특정 NumPy 및 Matplotlib APIs 에 대한 호환성이 제한되어 있습니다. 이러한 서드 파티 라이브러리로 작업할 때 to_pandas() 를 통해 Snowpark pandas DataFrames을 변환하면 여러 번의 I/O 호출을 피할 수 있습니다.
다음은 시각화용 Altair 와 머신 러닝용 scikit-learn 을 사용한 예제입니다.
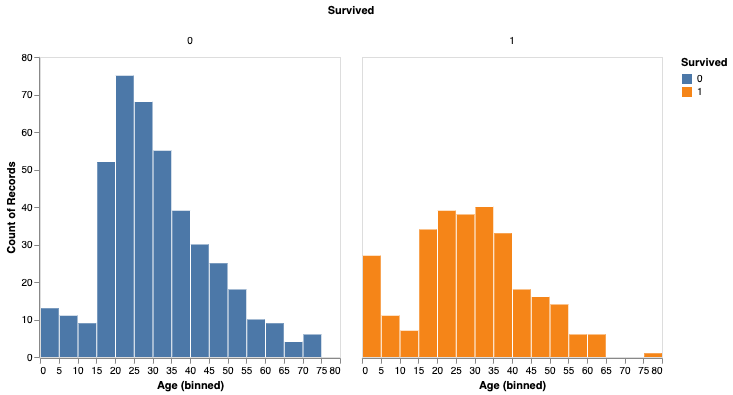
성별에 따라 생존율을 분석할 수도 있습니다.
이제 scikit-learn을 사용하여 간단한 모델을 학습시킬 수 있습니다.
참고
성능을 높이려면 to_pandas() 를 통해 pandas DataFrames 로 변환하는 것이 좋습니다. 특히 scikit-learn과 같은 머신 러닝 라이브러리를 사용하는 경우 더욱 그렇습니다. 그러나 to_pandas() 함수는 모든 행을 수집하므로 sample(frac=0.1) 또는 head(10) 을 사용하여 데이터 프레임 크기를 먼저 줄이는 것이 좋습니다.
지원되지 않는 라이브러리¶
지원되지 않는 서드 파티 라이브러리를 pandas on Snowflake DataFrame 과 함께 사용하는 경우, DataFrame 을 서드 파티 라이브러리 메서드에 전달하기 전에 to_pandas() 를 호출하여 pandas on Snowflake DataFrame 을 pandas DataFrame 으로 변환하는 것이 좋습니다.
참고
to_pandas() 를 호출하면 데이터를 Snowflake에서 메모리로 가져오므로 대규모 데이터 세트와 민감한 사용 사례의 경우 이를 고려하십시오.
Snowpark pandas와 함께 Snowflake Cortex LLM 함수 사용하기¶
Snowpark pandas apply 함수 를 통해 Snowflake Cortex LLM 함수 를 사용할 수 있습니다.
특수 키워드 인자를 사용하여 함수를 적용합니다. 현재 지원되는 Cortex 함수는 다음과 같습니다.
다음은 Snowpark pandas DataFrame 의 여러 레코드에 걸쳐 TRANSLATE 함수를 사용하는 예입니다.
출력:
다음 예제는 ``reviews``라는 Snowflake 테이블에서 SENTIMENT (SNOWFLAKE.CORTEX) 함수를 사용합니다.
다음은 EXTRACT_ANSWER (SNOWFLAKE.CORTEX) 를 사용하여 질문에 답변하는 예입니다.
출력:
참고
snowflake-ml-python 패키지를 설치해야 Cortex LLM 함수를 사용할 수 있습니다.
제한 사항¶
pandas on Snowflake에는 다음과 같은 제한 사항이 있습니다.
pandas on Snowflake는 OSS 서드 파티 라이브러리와의 호환성을 보장하지 않습니다. 그러나 1.14.0a1 버전부터 Snowpark pandas에는 NumPy, 특히
np.where사용에 대한 제한적 호환성이 적용됩니다. 자세한 내용은 NumPy 상호 운용성 섹션을 참조하십시오.서드 파티 라이브러리 APIs를 Snowpark pandas DataFrame으로 호출하는 경우, Snowflake는 서드 파티 라이브러리 호출에 DataFrame을 전달하기 전에
to_pandas()`를 호출하여 Snowpark pandas DataFrame을 pandas DataFrame으로 변환할 것을 권장합니다. 자세한 내용은 :ref:`label-snowpark_pandas_third-party-libraries섹션을 참조하세요.pandas on Snowflake는 Snowpark ML 과 통합되지 않습니다. Snowpark ML을 사용하는 경우, Snowpark ML을 호출하기 전에 `to_snowpark()<https://docs.snowflake.com/developer-guide/snowpark/reference/python/latest/modin/pandas_api/modin.pandas.to_snowpark>`_를 사용하여 Snowpark pandas DataFrame을 Snowpark DataFrame으로 변환하는 것이 좋습니다.
지연
MultiIndex오브젝트는 지원되지 않습니다.MultiIndex를 사용하면 모든 데이터를 클라이언트 측으로 가져와야 하는 네이티브 pandasMultiIndex오브젝트를 반환합니다.모든 pandas APIs가 pandas on Snowflake에서 분산 구현된 것은 아니지만 일부는 추가 중입니다. 지원되지 않는 APIs의 경우, :code:`NotImplementedError`가 throw됩니다. 지원되는 APIs에 대한 자세한 내용은 API 참조 설명서를 참조하세요.
pandas on Snowflake는 pandas 2.2의 모든 패치 버전과 호환성을 제공합니다.
Snowpark pandas는 Snowpark pandas
apply함수 내에서 참조할 수 없습니다.apply내부에서는 네이티브 pandas만 사용할 수 있습니다.다음은 그 예입니다.
문제 해결하기¶
이 섹션에서는 pandas on Snowflake를 사용할 때 발생하는 문제 해결 팁을 설명합니다.
문제를 해결할 때 네이티브 pandas DataFrame(또는 샘플)에서 동일한 작업을 실행하여 동일한 오류가 지속되는지 확인합니다. 이러한 접근 방식은 사용자의 쿼리를 수정하는 방법에 대한 힌트를 제공할 수 있습니다. 예를 들면 다음과 같습니다.
장기 실행 중인 노트북이 열려 있는 경우, 기본적으로 세션이 240분(4시간) 동안 유휴 상태가 되면 Snowflake 세션 시간 제한이 설정됩니다. 세션이 만료되면 추가 pandas on Snowflake 쿼리를 실행하는 경우 “Authentication token has expired. The user must authenticate again.” 오류가 발생합니다. 이 시점에 Snowflake에 대한 연결을 다시 설정해야 합니다. 이로 인해 보존되지 않은 세션 변수가 손실될 수 있습니다. 세션 유휴 시간 제한 매개 변수를 구성하는 방법에 대한 자세한 내용은 세션 정책 섹션을 참조하세요.
모범 사례¶
이 섹션에서는 pandas on Snowflake를 사용할 때 따라야 할 모범 사례에 대해 설명합니다.
for루프,iterrows,iteritems등 반복적 코드 패턴을 사용하지 마세요. 반복적인 코드 패턴은 생성되는 쿼리 복잡성을 빠르게 증가시킵니다. 데이터 배포 및 계산 병렬화는 클라이언트 코드가 아닌 pandas on Snowflake가 수행하도록 합니다. 반복적인 코드 패턴의 경우 전체 DataFrame에서 수행할 수 있는 연산을 찾아서 해당 작업을 대신 사용합니다.
apply,applymap및transform`을 호출하지 마세요. 그러면 :doc:`UDFs</developer-guide/udf/python/udf-python-introduction>또는 :doc:`UDTFs</developer-guide/udf/python/udf-python-tabular-functions>`가 구현되며, 이는 일반 SQL 쿼리에 비해 성능이 떨어질 수 있습니다. 적용된 함수에 동등한 DataFrame 또는 계열 작업이 있는 경우 해당 작업을 대신 사용합니다. 예를 들어, :code:`df.groupby(‘col1’).sum()`이 아닌 :code:`df.groupby(‘col1’).apply(‘sum’)`을 직접 호출합니다.서드 파티 라이브러리 호출에 DataFrame 또는 계열을 전달하기 전에
to_pandas()를 호출합니다. pandas on Snowflake는 서드 파티 라이브러리와의 호환성을 보장하지 않습니다.추가 I/O 오버헤드를 피하려면 구체화된 일반 Snowflake 테이블을 사용합니다. pandas on Snowflake는 일반 테이블에서만 작동하는 데이터 스냅샷을 기반으로 작동합니다. 외부 테이블, 뷰 및 Apache Iceberg™ 테이블을 포함한 다른 유형의 경우 스냅샷을 생성하기 전에 임시 테이블이 생성되므로 구체화 오버헤드가 추가로 발생합니다.
pandas on Snowflake는 빠른 제로 카피 복제 기능을 제공하는 동시에 DataFrames 를 사용하여 Snowflake 테이블에서 :code:`read_snowflake`을 생성합니다.
다른 작업을 진행하기 전에 결과 타입을 다시 확인하고 필요한 경우
astype을 사용하여 명시적 타입 형변환을 수행합니다.유형 추론 기능이 제한되어 있기 때문에 유형 힌트가 제공되지 않으면 결과에 모든 정수 값이 포함되어 있어도
df.apply는 오브젝트(베리언트) 유형의 결과를 반환합니다. 다른 작업에서dtype가int여야 하는 경우 계속하기 전에astype메서드를 호출하여 열 타입을 수정하여 명시적 타입 형변환을 수행할 수 있습니다.필요하지 않으면 평가 및 구체화가 필요한 APIs를 호출하지 마세요.
Series또는Dataframe을 반환하지 않는 APIs가 올바른 유형으로 결과를 도출하려면 즉시 평가와 구체화가 필요합니다. 플로팅 방법에도 마찬가지입니다. 불필요한 평가와 구체화를 최소화하기 위해 해당 APIs에 대한 호출을 줄이십시오.대규모 데이터 세트에서는
np.where(<cond>, <스칼라>, n)를 호출하지 마십시오.<스칼라>가 DataFrame에<cond>의 크기로 브로드캐스트되어 속도가 느려질 수 있습니다.반복적으로 구축된 쿼리로 작업할 때
df.cache_result를 사용하여 중간 결과를 구체화함으로써 반복되는 평가를 줄이고 전체 쿼리의 지연 시간을 개선하고 복잡성을 줄일 수 있습니다. 예:위의 예제에서
df2`를 생성하는 쿼리는 계산 비용이 많이 들며, :code:`df3및 :code:`df4`의 생성에 모두 재사용됩니다. :code:`df2`를 임시 테이블로 구체화하면(:code:`df2`와 관련된 후속 작업을 피벗이 아닌 테이블 스캔으로 만들면) 코드 블록의 전체 대기 시간을 줄일 수 있습니다.
예¶
다음은 pandas 작업이 포함된 코드 예제입니다. 세 개의 열(COL_STR, COL_FLOAT 및 COL_INT)을 포함하는 pandas_test 라는 이름의 Snowpark pandas DataFrame으로 시작합니다. 이 예제와 관련된 노트북을 보려면 Snowflake-Labs 리포지토리의 pandas on Snowflake 예제 를 참조하십시오.
DataFrame을 이름이 :code:`pandas_test`인 Snowflake 테이블로 저장하며, 이 테이블은 예제 전체에서 사용할 것입니다.
다음으로, Snowflake 테이블에서 DataFrame을 생성합니다. 열 COL_INT 를 삭제한 다음 결과를 row_position 열을 사용하여 Snowflake에 다시 저장합니다.
결과는 새 테이블 :code:`pandas_test2`이며, 이는 다음과 같습니다.
IO(읽기 및 쓰기)¶
자세한 내용은 입력/출력 섹션을 참조하십시오.
인덱싱¶
누락된 값¶
형식 변환¶
이진 연산¶
집계¶
병합¶
Groupby¶
자세한 내용은 GroupBy 섹션을 참조하십시오.