Teradata-Snowflake 마이그레이션 가이드¶
Snowflake 마이그레이션 프레임워크¶
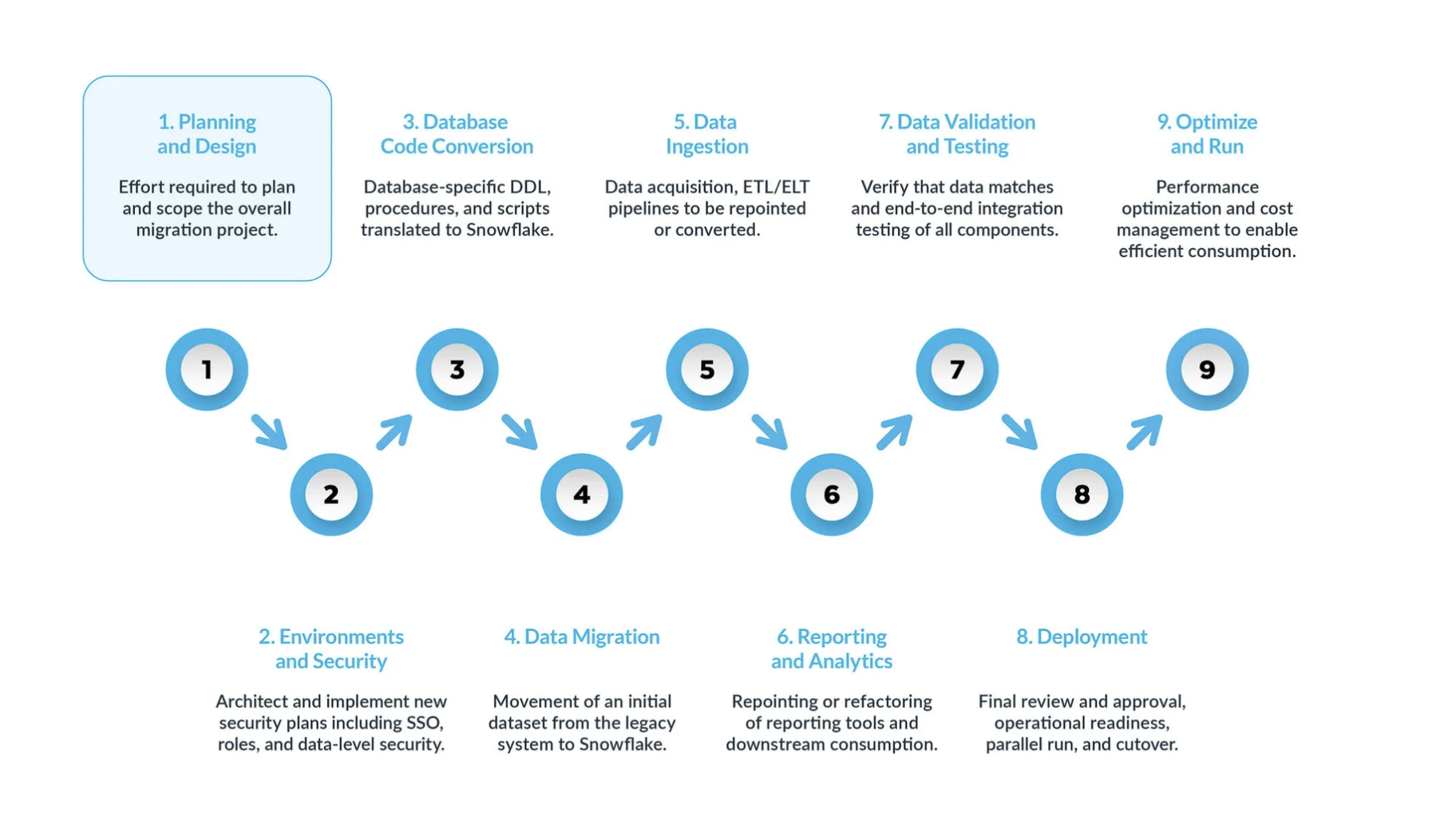
일반적인 Teradata-Snowflake 마이그레이션은 9가지 주요 단계로 구성됩니다.
계획 및 설계: 마이그레이션 프로세스에서 종종 간과되는 단계입니다. 주된 이유는 기업이 일반적으로 프로젝트의 범위를 완전히 이해하지 못한 경우에도 진행 상태를 신속하게 보여주고 싶어 하기 때문입니다. 따라서 마이그레이션 프로젝트를 이해하고 우선 순위를 지정하는 데 매우 중요한 단계입니다.
환경 및 보안: 계획, 명확한 타임라인, RACI 행렬을 만들고 모든 이해 관계자의 동의를 얻은 후 실행 모드로 전환하는 단계입니다. 마이그레이션을 시작하기 전에 마이그레이션 시작에 필요한 환경과 보안 조치를 설정하는 작업은 매우 중요합니다. 많은 변수가 존재하므로, 마이그레이션을 진행하기 전에 모든 설정이 준비되면 마이그레이션 프로젝트에 큰 효과가 있습니다.
데이터베이스 코드 변환: 테이블 정의, 뷰, 저장 프로시저 및 함수와 같은 소스 시스템의 데이터베이스 카탈로그에서 직접 코드를 추출합니다. 추출이 완료되면 이 모든 코드를 Snowflake의 상응하는 데이터 정의 언어(DDLs)로 마이그레이션합니다. 이 단계에는 비즈니스 분석가가 보고서 또는 대시보드 작성에 사용할 수 있는 데이터 조작 언어(DML) 스크립트 마이그레이션도 포함됩니다. 이 모든 코드가 Snowflake에서 작동하려면 마이그레이션 및 조정되어야 합니다. 명명 규칙 및 데이터 타입 매핑과 같은 간단한 변경부터, 구문, 플랫폼 의미 체계 및 기타 요소와 같은 더 복잡한 변경에 이르기까지 다양한 조정이 이루어질 수 있습니다. Snowflake는 이를 지원하기 위해 데이터베이스 코드 변환 프로세스의 대부분을 자동화해 주는 SnowConvert AI라는 강력한 솔루션을 제공합니다.
데이터 마이그레이션: 다양한 저장소 시스템, 형식 또는 컴퓨터 시스템 간에 데이터를 전송합니다. Teradata-Snowflake 마이그레이션 맥락에서 데이터 마이그레이션은 구체적으로 데이터를 Teradata 환경에서 새 Snowflake 환경으로 이동하는 것을 의미합니다. 이 가이드에서 설명하는 두 가지 주요 유형은 다음과 같습니다.
과거 데이터 마이그레이션: 특정 시점의 Teradata 데이터 스냅샷을 만들어 Snowflake로 전송합니다. 대개 처음에 대량 전송을 통해 이루어집니다.
증분 데이터 마이그레이션: 처음에 과거 데이터 마이그레이션이 수행된 후 신규 데이터 또는 변경된 데이터를 Teradata에서 Snowflake로 지속적으로 이동합니다. 그러면 Snowflake 환경과 소스 시스템이 함께 최신 상태를 유지하게 됩니다.
데이터 수집:: 과거 데이터를 마이그레이션한 후 다음 단계는 데이터 수집 프로세스를 마이그레이션하여 다양한 소스에서 라이브 데이터를 가져오는 것입니다. 일반적으로 이 프로세스는 데이터가 비즈니스 사용자에게 제공되기 전에 변환이 발생하는 시점과 위치에 따라 추출, 변환, 로드(ETL) 또는 추출, 로드, 변환(ELT) 모델을 따릅니다.
보고 및 분석: 이제 데이터베이스에 과거 데이터와 신규 데이터를 지속적으로 가져오는 라이브 파이프라인이 모두 있으므로, 다음 단계는 BI를 통해 이 데이터에서 가치를 추출하는 것입니다. 보고는 표준 BI 도구 또는 사용자 지정 쿼리를 사용하여 이루어집니다. 두 방법 모두, Snowflake의 요구 사항을 충족하기 위해 데이터베이스로 전송되는 SQL을 조정해야 할 수 있습니다. 간단한 이름 변경(마이그레이션 중에 흔히 발생)부터 구문, 더 복잡한 의미 체계 변경에 이르기까지 다양한 조정이 이루어질 수 있습니다. 모든 조정을 식별하고 해결해야 합니다.
데이터 유효성 검사 및 테스트: 목표는 이 단계에 들어가기 전에 데이터를 최대한 정리하는 것입니다. 조직마다 데이터를 프로덕션 환경으로 이동하기 위한 고유한 테스트 방법론과 요구 사항이 있습니다. 프로젝트 시작부터 이러한 사항을 완전히 이해해야 합니다.
배포: 이 단계에서는 데이터의 유효성이 검사되고, 상응하는 시스템이 설정되고, 모든 ETLs이 마이그레이션되고, 보고서가 검증된 상태입니다. 그렇다면 배포할 준비가 된 것일까요? 아직은 아닙니다. 프로덕션 환경으로 최종 배포하기 전에 고려해야 할 몇 가지 중요한 사항이 있습니다. 첫째, 레거시 애플리케이션은 여러 구성 요소 또는 서비스로 구성되어 있을 수 있습니다. 이상적으로는 이러한 애플리케이션을 하나씩 마이그레이션하고(병렬 마이그레이션이 가능하더라도) 동일한 순서로 프로덕션 환경에 배포해야 합니다. 이 과정에서 비즈니스 사용자가 Snowflake와 레거시 시스템을 모두 쿼리할 필요가 없도록 브리징 전략이 마련되어 있는지 확인합니다. 아직 마이그레이션되지 않은 애플리케이션에 대한 데이터 동기화는 브리징 메커니즘을 통해 백그라운드에서 이루어져야 합니다. 그렇지 않은 경우 비즈니스 사용자는 하이브리드 환경에서 작업해야 하며 이러한 설정의 의미를 이해해야 합니다.
최적화 및 실행: 시스템이 Snowflake로 마이그레이션되면 이 단계가 일반 유지 관리 모드로 전환됩니다. 모든 소프트웨어 시스템은 지속적인 유지 관리가 필요한 살아있는 유기체와 같습니다. 마이그레이션 후 이 단계를 최적화 및 실행 단계라고 하며, 이 단계는 마이그레이션 자체에 포함되지 않습니다.
마이그레이션 단계¶
1단계: 계획 및 설계¶
이 단계는 성공적인 Snowflake 마이그레이션을 위한 중요한 첫 번째 단계입니다. 범위, 목표 및 요구 사항을 정의하여 전체 마이그레이션 프로세스의 토대를 마련합니다. 이 단계에는 현재 환경을 심층적으로 이해하고 Snowflake에서 향후 달성하고자 하는 명확한 비전을 수립해야 합니다.
이 단계에서 조직은 다음 작업을 실행하여 Snowflake로 마이그레이션하는 주요 비즈니스 동인 및 기술적 목표를 식별합니다.
Teradata 환경에 대한 철저한 평가 수행¶
현재 환경에 대한 철저한 평가를 수행하려면 먼저 기존 데이터 자산의 인벤토리를 작성 하는 것이 중요합니다. 이를 위해서는 데이터베이스와 파일뿐만 아니라 외부 시스템도 문서화하면서 데이터 타입, 스키마, 널리 발생하는 데이터 품질 문제를 주의 깊게 기록해야 합니다. 동시에, 자주 실행되고 리소스 집약적인 쿼리를 정확히 찾아내기 위해 쿼리 워크로드 분석이 필수적입니다. 이를 통해 데이터 액세스 패턴과 사용자 동작을 파악할 수 있습니다. 마지막으로, 기존 시스템 내의 민감한 데이터, 규제 의무, 잠재적인 취약점을 식별하기 위해 보안 및 규정 준수 요구 사항 평가를 꼭 수행해야 합니다.
2단계: 환경 및 보안¶
권장하는 첫 번째 단계 중 하나는 마이그레이션을 시작하는 데 필요한 환경과 보안 조치를 설정하는 것입니다. 많은 변수가 존재하므로 보안부터 시작해 보겠습니다. 다른 클라우드 플랫폼과 마찬가지로, Snowflake는 플랫폼과 관리자 간의 공유 보안 모델에 따라 운영됩니다.
¶
환경 설정¶
먼저, 필요한 계정 수를 결정해야 합니다. 레거시 플랫폼에서는 일반적으로 데이터베이스 인스턴스가 있었지만, Snowflake에서는 계정을 중심으로 설정이 이루어집니다. 최소한 프로덕션 환경과 개발 환경을 설정해야 합니다. 테스트 전략에 따라 다양한 테스트 스테이지를 위한 추가 환경이 필요할 수도 있습니다.
보안 조치¶
환경이 설정되면 적합한 보안 조치를 구현하는 것이 중요합니다. VPN 내에서 승인된 사용자만 Snowflake 시스템에 액세스할 수 있도록 하는 네트워크 정책부터 시작합니다.
Snowflake의 사용자 액세스 제어는 역할을 기반으로 하므로, 관리자는 비즈니스 요구 사항에 따라 역할을 정의해야 합니다. 역할이 정의되면 사용자 계정을 생성하고 모든 사용자에게 다단계 인증(MFA) 또는 Single Sign-On(SSO)을 적용합니다. 또한 서비스 계정을 설정하고 이러한 계정이 기존 사용자 이름 및 비밀번호 인증을 사용하지 않도록 해야 합니다.
마이그레이션 중 역할¶
마이그레이션 중에 마이그레이션 자체를 실행하는 사용자에 대한 특정 역할도 정의해야 합니다. 비프로덕션 환경의 역할은 다를 수 있지만, 마이그레이션 중에는 실제 데이터를 처리해야 한다는 점을 기억해야 합니다. 비프로덕션 환경의 경우에도 보안을 게을리하면 안 됩니다.
개발 단계에서 마이그레이션 팀은 일반적으로 구조나 코드에 대한 변경 사항을 배포할 때 더 많은 자유를 가집니다. 이는 활성 개발 환경이므로 과도한 보안 제한으로 마이그레이션 팀을 방해하면 안 됩니다. 그러나 비프로덕션 환경에서도 강력한 보안 모델을 유지하는 것은 여전히 중요합니다.
액세스 모델 재고¶
Snowflake의 보안 모델은 많은 레거시 플랫폼의 보안 모델과 다르기 때문에 Snowflake으로의 마이그레이션은 액세스 모델을 재고할 좋은 기회입니다. 시스템에 액세스해야 하는 사용자의 계층 구조를 정리하고 필요한 사용자만 특정 리소스에 액세스할 수 있도록 합니다.
재무 부서와 협력¶
Snowflake는 사용량 기반 가격 모델을 사용하므로, 비용은 사용량에 따라 달라집니다. 역할을 정의할 때 재무 부서와 협력하여 Snowflake를 사용하는 부서 및 사용 방법을 추적하는 것이 좋습니다. 또한, Snowflake를 사용하면 비즈니스 수준에서 소유권을 추적하는 데 사용할 수 있는 데이터베이스 오브젝트에 태그를 지정할 수 있으므로 사용량을 부서별 비용 할당에 맞춰 조정할 수 있습니다.
보안 및 환경 설정은 복잡한 작업이므로 사전에 계획해야 합니다. 장기적으로 새 플랫폼을 관리할 수 있도록 액세스 모델을 재설계해야 할 수도 있습니다. 시간을 투자하여 올바르게 설정하면 Snowflake로 안전하고 효율적으로 마이그레이션할 수 있는 강력한 기반을 마련할 수 있습니다.
3단계: 데이터베이스 코드 변환¶
SnowConvert AI는 Teradata 소스 코드를 이해하고 소스 코드의 데이터 정의 언어(DDL), 데이터 조작 언어(DML), 함수를 대상인 Snowflake의 해당 SQL로 변환합니다. SnowConvert AI는 3가지 확장명 .sql, .dml, ddl 중 하나로 소스 코드를 마이그레이션할 수 있습니다.
이 단계에는 테이블 정의, 뷰, 저장 프로시저 및 함수와 같은 소스 시스템의 데이터베이스 카탈로그에서 직접 코드를 추출합니다. 추출이 완료되면 이 모든 코드를 Snowflake에서 상응하는 데이터 정의 언어(DDLs)로 마이그레이션합니다. 이 단계에는 비즈니스 분석가가 보고서 또는 대시보드를 작성하는 데 사용할 수 있는 데이터 조작 언어(DML) 스크립트 마이그레이션도 포함됩니다.
여기에서 권장되는 추출 스크립트를 검토하세요.
Teradata DDL에는 일반적으로 기본 인덱스, 대체 또는 파티셔닝에 대한 참조가 포함됩니다. Snowflake에서는 이러한 구조가 동일한 방식으로 존재하지 않습니다.
Teradata용 SnowConvert AI를 사용하면 특히 여러 테이블을 처리할 때 데이터 정의 언어(DDL) 변환 프로세스를 크게 간소화할 수 있습니다. 또한 기본 인덱스 정의 및 대체 옵션과 같은 Teradata의 특정 DDL 구문을 Snowflake의 동일한 구조로 자동 변환할 수 있습니다. 이 자동화를 통해 수작업을 줄이고 오류 위험을 최소화하여 팀은 상위 수준의 마이그레이션 전략과 유효성 검사에 집중할 수 있습니다. 기본적인 DDL 변환 외에도 SnowConvert AI는 데이터 타입 매핑 및 스키마 재구성과 같은 미묘한 차이도 해결합니다. Snowflake의 제품에 맞게 데이터 타입을 자동으로 조정하고 최적의 성능과 관리 용이성을 위해 스키마를 통합할지, 아니면 세분화할지 쉽게 결정할 수 있습니다. 이 포괄적인 접근 방식은 마이그레이션된 데이터베이스 구조가 작동할 뿐만 아니라 Snowflake의 아키텍처에 최적화되도록 합니다.
필요한 경우 데이터 타입을 조정하거나 마이그레이션 AI 어시스턴트를 사용하여 오류 또는 경고(EWI)를 수정합니다.
스키마를 재구성할지 여부(예: 대규모 모놀리식 스키마를 여러 Snowflake 데이터베이스로 분할)를 결정합니다.
Teradata 마이그레이션 고려 사항¶
Teradata에서 Snowflake로 데이터를 마이그레이션할 때 데이터베이스 간의 기능적 차이를 고려하는 것이 중요합니다.
Teradata의 세션 모드¶
Teradata 데이터베이스에는 쿼리 실행을 위한 ANSI 모드(ANSI SQL: 2011 사양에 기반한 규칙) 및 TERA 모드(Teradata에서 정의한 규칙)의 여러 모드가 있습니다. 자세한 내용은 다음 Teradata 설명서 를 검토하십시오.
문자열 정보 테이블을 위한 Teradata 모드
문자열의 경우, Teradata 모드는 다르게 작동합니다. Teradata 설명서 를 기반으로한 다음 테이블의 설명을 따릅니다.
특징 |
ANSI 모드 |
Teradata 모드 |
|---|---|---|
문자 비교를 위한 기본 특성 |
CASESPECIFIC |
NOT CASESPECIFIC |
기본 TRIM 동작 |
TRIM(BOTH FROM) |
TRIM(BOTH FROM) |
변환 사양 요약
모드 |
열 제약 조건 값 |
Teradata 동작 |
SC 예상 동작 |
|---|---|---|---|
ANSI 모드 |
CASESPECIFIC |
CASESPECIFIC |
제약 조건이 추가되지 않습니다. |
NOT CASESPECIFIC |
CASESPECIFIC |
열 정의에 COLLATE ‘en-cs’를 추가합니다. |
|
Teradata 모드 |
CASESPECIFIC |
CASESPECIFIC |
대부분의 경우 COLLATE를 추가하지 말고 문자열 비교의 사용법을 RTRIM(식)으로 변환합니다. |
NOT CASESPECIFIC |
NOT CASESPECIFIC |
대부분의 경우 COLLATE를 추가하지 말고 문자열 비교의 사용법을 RTRIM(UPPER(식))으로 변환합니다. |
사용 가능한 변환 사양 옵션
SQL 변환 참조¶
이 가이드를 참조하면 Teradata에서 Snowflake로 마이그레이션할 때 변환된 코드가 어떻게 보이는지 파악할 수 있습니다. SQL는 언어 간에 구문이 유사하지만, 언어마다 새로운 기능을 확장하거나 추가할 수 있습니다.
따라서 하나의 환경(예: Teradata)과 다른 환경(예: Snowflake)에서 SQL을 실행할 때 변환이나 심지어 제거가 필요한 문이 많이 있습니다. 이러한 변환을 SnowConvert AI에서 수행합니다.
다음 페이지에서 특정 항목에 대한 자세한 정보를 찾아보십시오.
SQL에서 JavaScript로(프로시저)¶
Snowflake SQL 변환 참조에 대한 스크립트¶
Teradata 스크립트 파일을 Snowflake SQL로 변환하기 위한 변환 참조
Python 변환 참조에 대한 스크립트¶
이 섹션에서는 SnowConvert AI가 Teradata 스크립트(BTEQ, FastLoad, MultiLoad, TPUMP 등)를 Snowflake와 호환되는 스크립팅 언어로 변환하는 방법에 대해 자세히 설명합니다.
다음 페이지에서 특정 항목에 대한 자세한 정보를 찾아보십시오.
4단계: 데이터 마이그레이션¶
먼저, 과거 데이터 마이그레이션과 새로운 데이터 추가를 구분하는 것이 중요합니다. 과거 데이터 마이그레이션이란 특정 시점의 데이터 스냅샷을 만들어 Snowflake로 전송하는 것을 말합니다. Snowflake로 변환하지 않고 먼저 데이터의 정확한 복사본을 생성하는 것이 좋습니다. 이 초기 복사본은 레거시 플랫폼에 어느 정도 부하를 발생시키므로, 한 번만 수행하여 Snowflake에 저장하는 것이 좋습니다.
실행 가능한 단계:
과거 데이터 마이그레이션 수행: 특정 시점의 Teradata 데이터 스냅샷을 만들어 Snowflake로 전송하며, 대개 처음에 대량 전송을 통해 이루어집니다. 처음에는 변환하지 않고 정확한 복사본을 생성하는 것이 좋습니다.
증분 데이터 마이그레이션 계획: 처음에 과거 데이터를 마이그레이션한 후, Snowflake 환경을 최신 상태로 유지하기 위해 신규 데이터 또는 변경된 데이터를 Teradata에서 Snowflake로 지속적으로 이동하는 프로세스를 설정합니다.
5단계: 데이터 수집¶
Snowflake로의 파이프라인을 마이그레이션할 때는 BTEQ 스크립트, 저장 프로시저, 매크로 또는 특수 ETL 흐름과 같은 Teradata 기반 논리를 이동하거나 다시 작성해야 합니다. 여기에는 증분 변환을 위해 BTEQ 또는 예약된 Teradata 작업을 Snowflake 내부의 Streams 및 Tasks로 대체하는 오케스트레이션 전환이 포함됩니다. 또한 Teradata에 도착하는 여러 인바운드 데이터 소스를 Snowflake 수집 패턴(COPY, Snowpipe)으로 리디렉션하는 소스 및 싱크 재정렬이 필요합니다.
쿼리 변환 및 최적화 스테이지 중에 Teradata SQL은 Snowflake SQL로 변환됩니다. 여기에는 매크로를 저장 프로시저 또는 뷰로 바꾸고, QUALIFY 논리를 재작성하며, 저장 프로시저 및 조인 인덱스를 조정하는 작업이 포함됩니다. Teradata용 SnowConvert AI는 이러한 변환의 대부분을 자동화할 수 있습니다.
Snowflake에 데이터 자체를 마이그레이션할 때는 이제 BTEQ 스크립트, 저장 프로시저, 매크로 또는 특수 ETL 흐름과 같은 Teradata 기반 논리를 마이그레이션하거나 다시 작성해야 합니다.
오케스트레이션 전환¶
네이티브 Snowflake: 증분 변환을 위해 BTEQ 또는 예약된 Teradata 작업을 Snowflake 내부의 Streams 및 Tasks로 대체합니다.
외부 오케스트레이터: 서드 파티 스케줄러(Airflow, Control-M 등)를 사용한 경우 해당 스케줄러를 Snowflake로 지정하고 임베드된 Teradata SQL을 다시 작성합니다.
소스 및 싱크 재정렬¶
Teradata에 여러 개의 인바운드 데이터 소스가 도착한 경우 Snowflake 수집 패턴(COPY, Snowpipe)으로 리디렉션합니다.
다운스트림 시스템이 Teradata에서 데이터를 읽어오는 경우 파이프라인이 안정화되면 Snowflake로 다시 지정합니다.
Teradata용 SnowConvert AI는 자동 변환에 권장됩니다. 매크로, 저장 프로시저, BTEQ 스크립트를 처리하고 Snowflake 호환 코드를 출력할 수 있습니다.
6단계: 보고 및 분석¶
이제 데이터베이스에 과거 데이터와 신규 데이터를 지속적으로 가져오는 라이브 파이프라인이 모두 있으므로, 다음 단계는 비즈니스 인텔리전스(BI)를 통해 이 데이터에서 가치를 추출하는 것입니다. 보고는 표준 BI 도구 또는 사용자 지정 쿼리를 사용하여 이루어집니다. 두 방법 모두, Snowflake의 요구 사항을 충족하기 위해 데이터베이스로 전송되는 SQL을 조정해야 할 수 있습니다. 간단한 이름 변경(마이그레이션 중에 흔히 발생)부터 구문 변경 및 더 복잡한 의미 체계의 변경에 이르기까지 다양한 조정이 이루어질 수 있습니다. 모든 조정을 식별하고 해결해야 합니다.
수집 프로세스와 마찬가지로, 모든 레거시 플랫폼 사용량을 검토하고 그 결과를 마이그레이션 계획에 통합하는 것이 중요합니다. 일반적으로 고려해야 할 두 가지 유형의 보고서가 있습니다. 바로 (IT 소유 보고서와 비즈니스 소유 보고서입니다. 일반적으로 IT 소유 보고서를 추적하는 것이 더 쉽지만, 비즈니스 소유 보고서 및 비즈니스 사용자가 작성한 복잡한 쿼리에는 다른 접근 방식이 필요합니다.
비즈니스 사용자는 마이그레이션 프로세스의 주요 이해관계자이므로, 계획 단계에서 RACI 매트릭스에 포함되어야 합니다. Snowflake의 운영 방식에 대한 교육을 받고 플랫폼의 차이점을 명확하게 이해해야 합니다. 이를 통해 필요에 따라 사용자 지정 쿼리와 보고서를 수정할 수 있습니다. 일반적으로 비즈니스 사용자를 위한 병행 교육 과정을 제공한 후 플랫폼 간의 차이를 해결하고 필요한 조정을 안내할 수 있는 마이그레이션 전문가와의 상담 시간을 마련하는 것이 좋습니다.
비즈니스 사용자는 궁극적으로 마이그레이션을 “수용”하는 대상입니다. IT 관점에서 기술 마이그레이션을 완료했더라도 비즈니스 사용자가 참여하지 않은 경우 비즈니스 사용자는 여전히 비즈니스 운영에 중요한 수천 개의 보고서에 의존할 수 있습니다. 이러한 보고서가 Snowflake와 호환하도록 업데이트되지 않으면 해당 비즈니스가 레거시 플랫폼에서 완전히 전환할 수 없습니다.
Teradata SQL에는 Snowflake에 없는 일부 구성이 있으며, Snowflake에도 마찬가지입니다. 주요 차이는 다음과 같습니다.
매크로: Snowflake에서는 지원되지 않으며, 일반적으로 저장 프로시저나 뷰로 대체됩니다.
QUALIFY: Snowflake에서는
QUALIFY를 직접 지원하지 않으며, 하위 쿼리 또는 외부 SELECT를 사용하여 논리를 재작성합니다.저장 프로시저: Teradata SP 및 Snowflake SP(SQL 또는 JavaScript기반)가 있습니다. 프로시저 언어가 다릅니다.
조인 인덱스: 직접적으로 상응하는 것이 없으며, 마이크로 파티션 삭제 및 클러스터링 키에 의존합니다.
COLLECT STATISTICS: Teradata는 명시적 통계를 사용하는 반면, Snowflake는 이를 자동으로 수행합니다.
Teradata용 SnowConvert AI는 자동 변환에 권장됩니다. 매크로, 저장 프로시저, BTEQ 스크립트를 처리하고 Snowflake 호환 코드를 출력할 수 있습니다.
7단계: 데이터 유효성 검사 및 테스트¶
이 단계에서는 마이그레이션 계획 프로세스에서 간과되기도 하는 두 가지 단계인 데이터 유효성 검사 및 테스트를 수행해야 합니다. 물론, 목표는 이 단계에 들어가기 전에 데이터를 최대한 정리하는 것입니다.
조직마다 데이터를 프로덕션 환경으로 이동하기 위한 고유한 테스트 방법론과 요구 사항이 있습니다. 프로젝트 시작부터 이러한 사항을 완전히 이해해야 합니다. 그렇다면 유용한 데이터 유효성 검사 전략은 무엇일까요?
Snowflake 마이그레이션 중에 포괄적인 테스트 수행: Snowflake 마이그레이션 프로세스 중에 다음을 포함한 포괄적인 테스트를 수행해야 합니다.
기능 테스트: 마이그레이션된 모든 애플리케이션과 기능이 새 환경 내에서 예상대로 작동하는지 확인하여 데이터 무결성과 정확성을 보장합니다.
성능 테스트: 쿼리 성능, 데이터 로딩 속도, 전반적인 시스템 응답성을 평가하여 성능 병목 상태를 식별하고 해결합니다.
사용자 수용 테스트(UAT): 마이그레이션된 시스템이 비즈니스 요구 사항을 충족하는지 확인하고 잠재적 개선을 위한 피드백을 수집하기 위해 테스트 프로세스에 최종 사용자를 참여시킵니다.
Snowflake 마이그레이션을 위한 교육 및 설명서 제공:
데이터 액세스, 쿼리 최적화, 보안과 같은 항목을 다루는 Snowflake의 특징, 기능, 모범 사례에 대한 포괄적인 교육을 최종 사용자에게 제공합니다.
쉽게 참조할 수 있도록 시스템 아키텍처 다이어그램, 데이터 흐름 다이어그램, 운영 절차, 사용자 가이드, 문제 해결 가이드, FAQs 등이 포함된 포괄적인 문서를 작성합니다.
8단계: 배포¶
마지막으로 전환할 준비가 되면 모든 이해관계자가 정렬된 상태이며 Snowflake가 레거시 Databricks 플랫폼이 아닌 공식 시스템(System of Record, RoS)이 될 것이라는 점을 이해하는지 확인합니다. 계속 진행하기 전에 모든 이해관계자로부터 최종적이고 공식적인 승인을 받아야 합니다. 이제 마이그레이션되지 않은 모든 보고서는 비즈니스 사용자의 책임입니다. 마지막 순간에 사용자를 참여시켜서는 안 되는 이유가 바로 여기에 있습니다. 사용자는 처음부터 프로세스에 참여해야 하며 마이그레이션 타임라인을 알고 있어야 합니다.
또한 모든 권한이 올바르게 부여되었는지 확인합니다. 예를 들어, Active Directory 기반 역할을 사용하는 경우 이러한 역할이 Snowflake에서 생성 및 구성되었는지 확인합니다.
몇 가지 추가 시나리오는 일반적으로 마지막에 살펴보지만, 이를 간과해서는 안 됩니다.
대체 키: 대체 키를 사용하는 경우 대체 키의 수명 주기가 레거시 시스템과 Snowflake 시스템 간에 다를 수 있다는 점에 유의합니다. 대체 키는 전환 중에 동기화해야 합니다.
전환 타이밍: 업종에 따라 전환하기 더 좋거나 불리한 시기가 있을 수 있습니다. 전환 타이밍을 신중하게 고려합니다.
레거시 플랫폼 라이선싱: 레거시 플랫폼의 라이선싱과 관련하여 엄격한 마감 날짜가 있을 수 있다는 점을 유의해야 합니다. 이러한 마감 날짜를 고려하여 전환을 계획해야 합니다.
9단계: 최적화 및 실행¶
시스템이 Snowflake로 마이그레이션되면 이 단계가 일반 유지 관리 모드로 전환됩니다. 모든 소프트웨어 시스템은 지속적인 유지 관리가 필요한 살아있는 유기체와 같습니다. 마이그레이션 후 이 단계를 최적화 및 실행 단계라고 하며, 이 단계는 마이그레이션 자체에 포함되지 않는다는 점을 유의하세요.
최적화 및 지속적 개선은 마이그레이션 후 진행되는 지속적인 프로세스입니다. 이 시점에서 팀은 Snowflake의 시스템에 대한 모든 소유권을 갖습니다. 이 시스템은 계속 발전할 것이며, 최적화는 사용량 패턴에 따라 이루어질 것입니다.
일반적으로 Snowflake의 작업은 원래 플랫폼보다 더 빠르게 실행되는 경향이 있습니다. 성능이 기대에 미치지 못하는 경우 Snowflake의 고유한 아키텍처를 최대한 활용하기 위해 몇 가지 최적화를 실행해야 할 수도 있습니다. Snowflake는 병목 상태를 식별하는 데 도움이 되는 다양한 쿼리 분석 도구를 제공하므로, 워크플로의 특정 부분을 최적화할 수 있습니다.
최적화 단계에서 시스템의 다양한 측면을 다시 살펴봐야 할 수도 있습니다. 장점은 이미 Snowflake의 기능을 활용하고 있으며, 최적화 작업이 정기적인 유지 관리 루틴에 포함된다는 점입니다.
마이그레이션 단계에서는 중요한 성능 문제만 해결하는 데 집중하는 것이 좋습니다. 최적화는 마이그레이션 후 작업으로 처리하는 것이 가장 좋습니다.
마이그레이션 지원이 필요하신가요?¶
복잡한 마이그레이션 시나리오의 경우 특정 기능적 차이를 해결하거나 일반적인 지원을 받으려면 Snowflake에서 제공하는 snowconvert-support@snowflake.com과 같은 전용 지원 채널을 이용할 수 있습니다. 또한, 마스터 클래스, 웹 세미나, Teradata 마이그레이션을 위한 자세한 참조 가이드 등 Snowflake의 광범위한 마이그레이션 리소스를 활용하면 마이그레이션 성공 가능성을 크게 높일 수 있습니다.
Teradata에서 데이터 플랫폼 마이그레이션에 성공하려면 변환 도구 자체에만 의존해서는 안 됩니다. 자동화의 효율성(SnowConvert AI에서 제공), 인간 전문가(예: 데이터 설계자)의 비판적 판단 및 문제 해결 능력, 대상 플랫폼의 에코시스템에서 제공하는 포괄적인 지원 및 리소스(Snowflake의 설명서, 지원 서비스, 모범 사례 포함)를 아우르는 전체론적인 전략이 필요합니다. 이는 조직이 마이그레이션 도구뿐만 아니라 Snowflake 네이티브 기능에 대한 팀의 기술 향상과 강력한 유효성 검사 프로세스 구축에도 전략적으로 투자해야 함을 의미합니다. 궁극적인 목표는 단순히 데이터를 이동하는 것이 아니라 전체 데이터 작업을 현대화하여 탄력성과 성능이 뛰어나며 미래에 대비한 클라우드 데이터 플랫폼을 만드는 것입니다.
부록¶
부록 1: Snowflake로 마이그레이션할 때 제외할 Teradata 데이터베이스¶
다음 데이터베이스 목록은 Teradata에만 필요하며 Snowflake로 마이그레이션하면 안 됩니다.
DBC Crashdumps Dbcmngr External_AP EXTUSER LockLogShredder QCD SQLJ Sys_Calendar |
SysAdmin SYSBAR SYSJDBC SYSLIB SYSSPATIAL SystemFE SYSUDTLIB SYSUIF TD_SERVER_DB |
TD_SYSFNLIB TD_SYSGPL TD_SYSXML TDPUSER TDQCD TDStats tdwm |
|---|
부록 2: Teradata 데이터 타입에서 Snowflake 데이터 타입으로 전환¶
Teradata 열 유형 |
Teradata 데이터 타입 |
Snowflake 데이터 타입 |
|---|---|---|
++ |
TD_ANYTYPE |
TD_ANYTYPE 데이터 타입은 Snowflake에서 지원되지 않습니다. |
A1 |
ARRAY |
ARRAY |
AN |
ARRAY |
ARRAY |
AT |
TIME |
TIME |
BF |
BYTE |
BINARY |
BO |
BLOB |
BLOB 데이터 타입은 직접 지원되지 않지만 BINARY(8MB로 제한됨)로 대체할 수 있습니다. |
BV |
VARBYTE |
BINARY |
CF |
CHAR |
VARCHAR |
CO |
CLOB |
CLOB 데이터 타입은 직접 지원되지 않지만 VARCHAR(16MB로 제한됨)로 대체할 수 있습니다. |
CV |
VARCHAR |
VARCHAR |
D |
DECIMAL |
NUMBER |
DA |
DATE |
DATE |
DH |
INTERVAL DAY TO HOUR |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
DM |
INTERVAL DAY TO MINUTE |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
DS |
INTERVAL DAY TO SECOND |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
DT |
DATASET |
DATASET 데이터 타입은 Snowflake에서 지원되지 않습니다. |
DY |
INTERVAL DAY |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
F |
FLOAT |
FLOAT |
HM |
INTERVAL HOUR TO MINUTE |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
HR |
INTERVAL HOUR |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
HS |
INTERVAL HOUR TO SECOND |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
I1 |
BYTEINT |
NUMBER |
I2 |
SMALLINT |
NUMBER |
I8 |
BIGINT |
NUMBER |
I |
INTEGER |
NUMBER |
JN |
JSON |
VARIANT |
LF |
CHAR |
이 데이터 타입은 DBC에만 있으며, Snowflake로 변환할 수 없습니다. |
LV |
VARCHAR |
이 데이터 타입은 DBC에만 있으며, Snowflake로 변환할 수 없습니다. |
MI |
INTERVAL MINUTE |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
MO |
INTERVAL MONTH |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
MS |
INTERVAL MINUTE TO SECOND |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
N |
NUMBER |
NUMBER |
PD |
PERIOD(DATE) |
VARCHAR로 변환하거나 2개의 개별 날짜로 분할할 수 있습니다. |
PM |
PERIOD(TIMESTAMP WITH TIME ZONE) |
VARCHAR로 변환하거나 2개의 개별 타임스탬프(TIMESTAMP_TZ)로 분할할 수 있습니다. |
PS |
PERIOD(TIMESTAMP) |
VARCHAR로 변환하거나 2개의 개별 타임스탬프(TIMESTAMP_NTZ)로 분할할 수 있습니다. |
PT |
PERIOD(TIME) |
VARCHAR로 변환하거나 2개의 개별 시간으로 분할할 수 있습니다. |
PZ |
PERIOD(TIME WITH TIME ZONE) |
VARCHAR로 변환하거나 2개의 개별 시간으로 분할할 수 있지만 WITH TIME ZONE은 TIME에 지원되지 않습니다. |
SC |
INTERVAL SECOND I |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
SZ |
TIMESTAMP WITH TIME ZONE |
TIMESTAMP_TZ |
TS |
TIMESTAMP |
TIMESTAMP_NTZ |
TZ |
TIME WITH TIME ZONE |
TIME WITH TIME ZONE은 TIME이 타임존 오프셋 없이 “wall clock” 시간만 사용하여 저장되므로 지원되지 않습니다. |
UF |
CHAR |
이 데이터 타입은 DBC에만 있으며, Snowflake로 변환할 수 없습니다. |
UT |
UDT |
UDT 데이터 타입은 Snowflake에서 지원되지 않습니다. |
UV |
VARCHAR |
이 데이터 타입은 DBC에만 있으며, Snowflake로 변환할 수 없습니다. |
XM |
XML |
VARIANT |
YM |
INTERVAL YEAR TO MONTH |
INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |
YR |
INTERVAL YEAR |
YR INTERVAL YEAR INTERVAL 데이터 타입은 Snowflake에서 지원되지 않지만, 날짜 비교 함수(예: DATEDIFF 및 DATEADD)를 사용하여 날짜 계산을 수행할 수 있습니다. |