Guide de migration de Teradata vers Snowflake¶
Framework de migration Snowflake¶
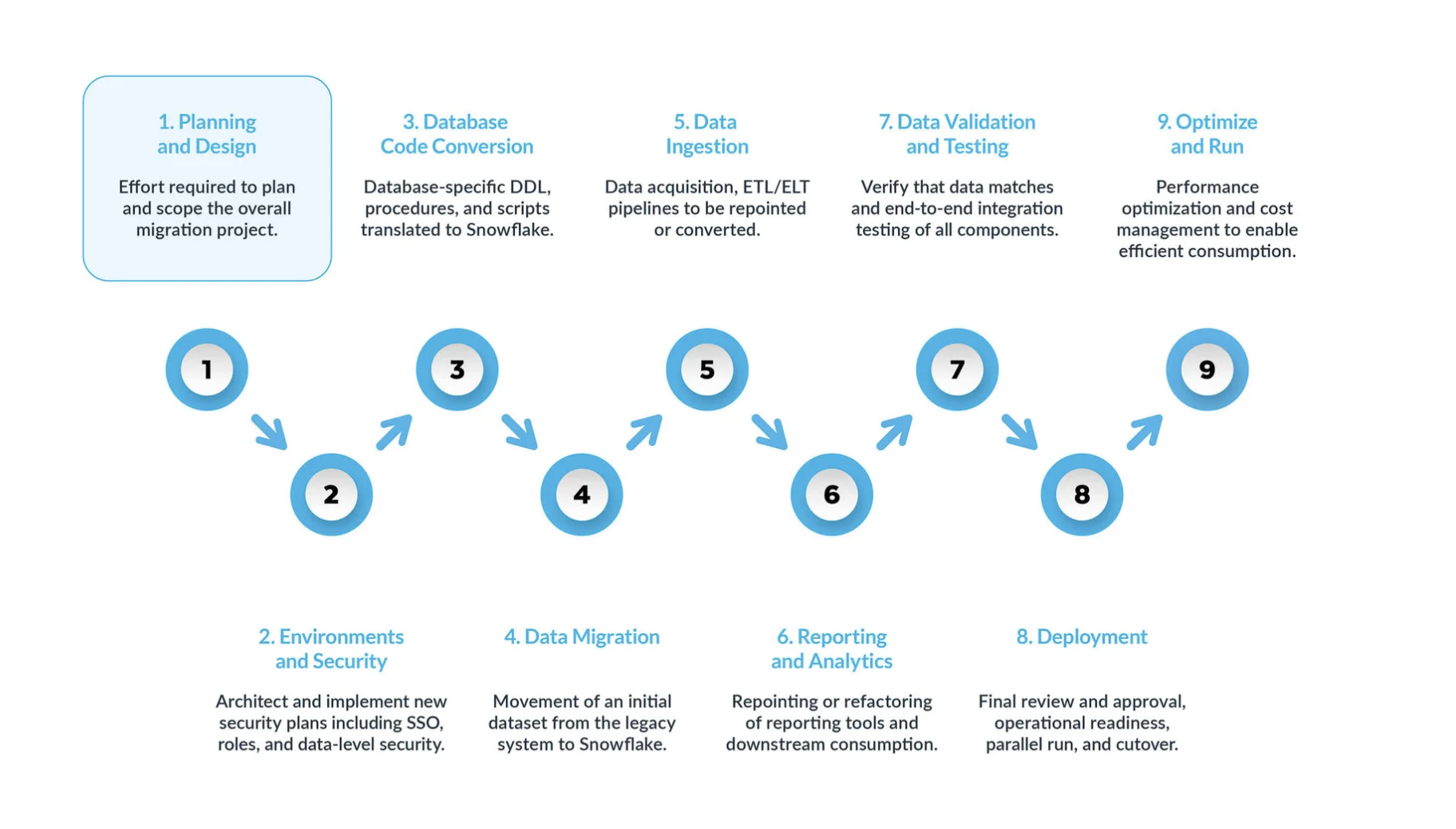
Une migration Teradata vers Snowflake typique peut être divisée en cinq étapes clés :
La planification et la conception sont souvent négligées dans le processus de migration. La principale raison est que les entreprises souhaitent généralement afficher rapidement la progression, même si elles n’ont pas bien compris la portée du projet. C’est pourquoi cette phase est essentielle pour comprendre et hiérarchiser le projet de migration.
Environnement et sécurité avec un plan, un calendrier clair, une matrice RACI, et l’adhésion de toutes les parties prenantes. Il est temps de passer en mode exécution. La mise en place des environnements et des mesures de sécurité nécessaires pour commencer la migration est très importante avant de démarrer la phase de migration, étant donné qu’il y a de nombreuses parties mobiles, et cela aura plus d’impact pour le projet de migration si toutes vos configurations sont prêtes avant d’aller plus loin.
Le processus de conversion du code de la base de données implique l’extraction du code directement depuis le catalogue de la base de données des systèmes sources, tels que les définitions de table, les vues, les procédures stockées et les fonctions. Une fois extrait, vous migrez l’ensemble de ce code vers des langages de définition de données équivalents (DDLs) dans Snowflake. Cette étape comprend également la migration des scripts du langage de manipulation des données (DML), qui peuvent être utilisés par les analystes commerciaux pour créer des rapports ou des tableaux de bord. Tout ce code doit être migré et ajusté pour fonctionner dans Snowflake. Les ajustements peuvent aller de changements simples, tels que les conventions de dénomination et les mappages de types de données, à des différences plus complexes dans la syntaxe, la sémantique de plateforme et d’autres facteurs. Pour y remédier, Snowflake propose une solution puissante appelée SnowConvert AI, qui automatise une grande partie du processus de conversion du code de la base de données.
Migration de données La migration de données implique le transfert de données entre différents systèmes de stockage, formats ou systèmes informatiques. Dans le contexte d’une migration de Teradata vers Snowflake, il s’agit spécifiquement du déplacement de données de votre environnement Teradata vers votre nouvel environnement Snowflake. Ce guide présente deux principaux types de :
Migration des données historiques : instantané de vos données Teradata à un moment précis et transfert vers Snowflake. Il s’agit souvent d’un transfert initial en masse.
Migration des données incrémentielles : déplacement continu de données nouvelles ou modifiées de Teradata vers Snowflake après la migration historique initiale. Cela garantit que votre environnement Snowflake reste à jour avec vos systèmes sources.
Ingestion des données : après la migration des données historiques, l’étape suivante consiste à migrer le processus d’ingestion de données, en intégrant des données dynamiques provenant de diverses sources. En règle générale, ce processus suit un modèle d’extraction, transformation, chargement (ETL) ou d’extraction, changement, transformation (ELT), en fonction du moment et de l’endroit où la transformation des données se produit avant qu’elle ne soit disponible pour les utilisateurs professionnels.
Rapports et analyses : maintenant que la base de données contient à la fois des données historiques et des pipelines dynamiques qui importent continuellement de nouvelles données, l’étape suivante consiste à extraire de la valeur de ces données via BI. Les rapports peuvent être effectués à l’aide des outils BI standard ou de requêtes personnalisées. Dans les deux cas, le SQL envoyé à la base de données peut devoir être ajusté pour répondre aux exigences de Snowflake. Ces ajustements peuvent aller de simples modifications de nom (communes lors de la migration) à des différences de syntaxe et sémantiques plus complexes. Tous ces problèmes doivent être identifiés et traités.
Validation et test des données : l’objectif consiste à ce que les données soient aussi propres que possible avant d’entamer cette phase. Chaque organisation possède ses propres méthodologies de test et ses propres exigences pour passer des données en production. Celles-ci doivent être bien comprises dès le début du projet.
Déploiement : à ce stade, les données sont validées, un système équivalent est mis en place, tous les ETLs ont été migrés et les rapports ont été vérifiés. Prêt pour la mise en production ? Encore un peu de patience - il y a encore quelques considérations critiques avant la mise en production finale. Tout d’abord, votre application existante peut consister en plusieurs composants ou services. Idéalement, vous devriez migrer ces applications une par une (bien que la migration parallèle soit possible) et les passer en production dans le même ordre. Au cours de ce processus, assurez-vous que votre stratégie de « pont » est en place afin que les utilisateurs professionnels n’aient pas à interroger à la fois Snowflake et le système existant. La synchronisation des données pour les applications qui n’ont pas encore été migrées doit se faire en arrière-plan via le mécanisme de pont. Si cela n’est pas fait, les utilisateurs professionnels devront travailler dans un environnement hybride, et ils doivent comprendre les implications de cette configuration.
Optimisation et exécution une fois qu’un système a été migré vers Snowflake, il passe en mode de maintenance normale. Tous les systèmes logiciels sont des organismes vivants qui nécessitent une maintenance continue. Cette phase, après la migration, est appelée optimisation et exécution, et elle ne fait pas partie de la migration elle-même.
Phases de migration¶
Phase 1 : Planification et conception¶
Cette phase est la première étape cruciale d’une migration Snowflake réussie. Elle pose les bases de l’ensemble du processus de migration en définissant la portée, les objectifs et les exigences. Cette phase implique une compréhension profonde de l’environnement actuel et une vision claire de l’état futur de Snowflake.
Au cours de cette phase, les organisations identifient les indicateurs clés et les objectifs techniques pour migrer vers Snowflake en exécutant les tâches suivantes :
Réaliser une évaluation complète de votre environnement Teradata¶
Pour réaliser une évaluation approfondie de l’environnement actuel, il est crucial de commencer par effectuer un inventaire des données existantes. Cela implique de documenter non seulement les bases de données et les fichiers, mais aussi tous les systèmes externes, tout en notant soigneusement les types de données, les schémas et tous les problèmes courants de qualité des données. De même, l”analyse des charges de travail des requêtes est essentielle pour identifier les requêtes fréquemment exécutées et gourmandes en ressources, ce qui permettra de mettre en évidence les modèles d’accès aux données et le comportement des utilisateurs. Enfin, l”évaluation des exigences de sécurité et de conformité n’est pas négociable, ce qui nécessite l’identification des données sensibles, des obligations réglementaires et des vulnérabilités potentielles au sein du système existant.
Phase 2 : Environnement et sécurité¶
L’une des premières étapes que nous recommandons est de configurer les environnements et les mesures de sécurité nécessaires pour commencer la migration. Il y a beaucoup d’éléments à prendre en compte, alors commençons par la sécurité. Comme pour toute plateforme cloud, Snowflake fonctionne selon un modèle de sécurité partagé entre la plateforme et les administrateurs.
¶
Configuration d’environnements¶
Tout d’abord, vous devez décider du nombre de comptes dont vous aurez besoin. Dans les plateformes existantes, vous aviez généralement des instances de base de données, mais dans Snowflake, la configuration s’articule autour des comptes. Au minimum, vous devez configurer un environnement de production et un environnement de développement. Selon votre stratégie de test, vous pouvez également avoir besoin d’environnements supplémentaires pour différentes zones de préparation des tests.
Mesures de sécurité¶
Une fois les environnements mis en place, il est crucial de mettre en œuvre les mesures de sécurité appropriées. Commencez par la politique réseau pour garantir que seuls les utilisateurs autorisés de votre VPN peuvent accéder au système Snowflake.
Le contrôle d’accès utilisateur de Snowflake est basé sur les rôles, les administrateurs doivent donc définir les rôles en fonction des besoins de l’entreprise. Une fois les rôles définis, créez les comptes utilisateurs et appliquez l’authentification multifactorielle (MFA) et/ou la connexion unique (SSO) pour tous les utilisateurs. De plus, vous devrez configurer des comptes de service et vous assurer que vous ne dépendez pas de l’authentification traditionnelle par nom d’utilisateur/mot de passe pour ces comptes.
Rôles pendant la migration¶
Pendant la migration, vous devrez également définir des rôles spécifiques pour les utilisateurs qui exécutent la migration elle-même. Bien que les rôles des environnements hors production puissent varier, n’oubliez pas que lors de la migration, vous traiterez avec des données réelles. Ne faites pas l’impasse sur la sécurité, même pour les environnements hors production.
En développement, l’équipe de migration aura généralement plus de liberté lors du déploiement de modifications de la structure ou du code. Ce sont des environnements de développement actifs, et il ne faut pas bloquer l’équipe de migration avec des restrictions de sécurité excessives. Cependant, il est toujours important de maintenir un modèle de sécurité robuste, même dans les environnements hors production.
Repenser le modèle d’accès¶
Le modèle de sécurité de Snowflake étant différent de celui de nombreuses plateformes héritées, cette migration est une bonne occasion de repenser votre modèle d’accès. Clarifiez la hiérarchie des utilisateurs qui ont besoin d’accéder à votre système et assurez-vous que seuls les utilisateurs nécessaires ont accès à des ressources spécifiques.
Collaboration avec le département des finances¶
Snowflake utilise un modèle de tarification basé sur la consommation, ce qui signifie que les coûts sont liés à l’utilisation. Lorsque vous définissez des rôles, nous vous conseillons de vous coordonner avec votre équipe financière pour savoir quels départements utilisent Snowflake et comment. Snowflake vous permet également de baliser les objets de la base de données, qui peuvent être utilisés pour suivre la propriété au niveau de l’entreprise, ce qui vous aide à aligner l’utilisation sur la répartition des coûts du service.
La sécurité et la configuration de l’environnement sont des tâches complexes et elles doivent être planifiées à l’avance. Vous devrez peut-être même envisager une refonte de votre modèle d’accès pour vous assurer que la nouvelle plateforme est gérable à long terme. En prenant le temps de le configurer correctement, vous disposerez de bases solides pour une migration sécurisée et efficace vers Snowflake.
Phase 3 : Conversion du code de base de données¶
SnowConvert AI comprend le code source Teradata et convertit le langage de définition des données (DDL), le langage de manipulation de données (DML), et les fonctions dans le code source en SQL correspondant dans la cible : Snowflake. SnowConvert AI peut migrer le code source vers l’une de ces trois extensions .sql, .dml, ddl
Cette phase consiste à extraire le code directement du catalogue de la base de données des systèmes sources, tels que les définitions de table, les vues, les procédures stockées et les fonctions. Une fois extrait, vous migrez l’ensemble de ce code vers desDDLs (Langages de définition des données) équivalents dans Snowflake. Cette étape comprend également la migration des scripts DML (Language de manipulation de données), qui peuvent être utilisés par les analystes commerciaux pour créer des rapports ou des tableaux de bord.
Consultez nos scripts d’extraction recommandés ici
Le DDL Teradata comprend généralement des références aux index principaux, plan de secours, ou partitionnement. Dans Snowflake, ces structures n’existent pas de la même manière :
[Utilisez SnowConvert AI pour Teradata] (https://www.snowflake.com/en/migrate-to-the-cloud/snowconvert/) qui rationalise considérablement le langage de définition des données (DDL), en particulier lorsque vous traitez de nombreuses tables. Il automatise la traduction des constructions DDL spécifiques de Teradata, telles que les définitions d’index principales et les options de secours, en structures équivalentes de Snowflake. Cette automatisation réduit l’effort manuel et réduit le risque d’erreurs, permettant aux équipes de se concentrer sur une stratégie de migration et une validation de niveau supérieur. Au-delà de la conversion DDL de base, SnowConvert AI traite également les complexités comme le mappage des types de données et la réorganisation des schémas. Elle peut ajuster automatiquement les types de données pour les aligner sur les offres de Snowflake et faciliter les décisions relatives à la consolidation ou à la décomposition des schémas pour des performances et une gestion optimales. Cette approche complète garantit que la structure de base de données migrée est non seulement fonctionnelle, mais également optimisée pour l’architecture de Snowflake.
Ajustez les types de données si nécessaire ou utilisez l’assistant AI aux migrations pour résoudre toute erreur ou tout avertissement (EWI).
Décidez s’il faut réorganiser les schémas (par exemple, en divisant de grands schémas monolithiques en plusieurs bases de données Snowflake).
Considérations relatives à Teradata¶
Lors de la migration des données de Teradata vers Snowflake, il est crucial de prendre en compte les différences fonctionnelles entre les bases de données.
Modes de session dans Teradata¶
La base de données Teradata dispose de différents modes d’exécution des requêtes : Mode ANSI (règles basées sur les spécifications ANSI SQL : 2011) et mode TERA (règles définies par Teradata). Pour plus d’informations, veuillez consulter la documentation Teradata suivante.
Mode Teradata pour la table informative des chaînes
Pour les chaînes, le mode Teradata fonctionne différemment. Comme l’explique la table suivante, basée sur la documentation Teradata :
Fonctionnalité |
Mode ANSI |
Mode Teradata |
|---|---|---|
Attribut par défaut pour les comparaisons de caractères |
CASESPECIFIC |
NOT CASESPECIFIC |
Comportement TRIM par défaut |
TRIM(BOTH FROM) |
TRIM(BOTH FROM) |
Résumé des spécifications de traduction
Mode |
Valeurs de contrainte de colonne |
Comportement de Teradata |
Comportement attendu de SC |
|---|---|---|---|
Mode ANSI |
CASESPECIFIC |
CASESPECIFIC |
Aucune contrainte ajoutée. |
NOT CASESPECIFIC |
CASESPECIFIC |
Ajouter COLLATE « en-cs » dans la définition de colonne. |
|
Mode Teradata |
CASESPECIFIC |
CASESPECIFIC |
Dans la plupart des cas, n’ajoutez pas COLLATE, et convertit ses utilisations de la comparaison de chaînes en RTRIM(expression) |
NOT CASESPECIFIC |
NOT CASESPECIFIC |
Dans la plupart des cas, n’ajoutez pas COLLATE, et convertit ses utilisations de la comparaison de chaînes en RTRIM(UPPER(expressions)) |
Options de spécification de traduction disponibles
Référence à la traduction SQL¶
Utilisez ce guide comme guide pour comprendre à quoi pourrait ressembler le code transformé lors de la migration de Teradata vers Snowflake. SQL a une syntaxe similaire entre les dialectes, mais chaque dialecte peut étendre ou ajouter de nouvelles fonctionnalités.
C’est pourquoi, lors de l’exécution de SQL dans un environnement (tel que Teradata) ou un autre (tel que Snowflake), il existe de nombreuses instructions qui nécessitent une transformation, voire une suppression. Ces transformations sont effectuées par SnowConvert AI.
Parcourez les pages suivantes pour trouver plus d’informations sur des sujets spécifiques.
Types de données, comparez les types de données Teradata et leurs équivalents dans Snowflake.
DDL, explorez la traduction du Langage de définition des données.
DML, explorez la traduction du Langage de manipulation de données.
Fonctions intégrées, comparez les fonctions incluses dans l’environnement d’exécution des deux langages.
SQL à JavaScript (Procédures)¶
Référence de traduction de scripts vers le SQL Snowflake¶
Référence de traduction pour convertir des fichiers de scripts Teradata vers le SQL Snowflake
Référence de traduction des scripts vers Python¶
Cette section explique comment SnowConvert AI traduit les scripts Teradata (BTEQ, FastLoad, MultiLoad, TPUMP, etc.) en un langage de script compatible avec Snowflake.
Parcourez les pages suivantes pour trouver plus d’informations sur des sujets spécifiques.
Phase 4 : Migration des données¶
Tout d’abord, il est important de faire la différence entre la migration des données historiques et l’ajout de nouvelles données. La migration des données historiques consiste à prendre un instantané des données à un moment précis et à les transférer vers Snowflake. Nous recommandons de réaliser d’abord une copie exacte des données sans transformation quelconque dans Snowflake. Cette copie initiale entraînera une certaine charge sur la plateforme héritée, par conséquent, ne le faites qu’une seule fois et stockez-la dans Snowflake.
Vos étapes pratiques :
Exécution d’une migration des données historiques : Prenez un instantané de vos données Teradata à un moment précis et transférez-les vers Snowflake, souvent en tant que transfert en masse initial. Nous recommandons d’effectuer une copie exacte sans transformation initiale.
Planification de la migration des données incrémentielles : Après la migration historique initiale, mettez en place des processus pour déplacer les données nouvelles ou modifiées de Teradata vers Snowflake de manière graduelle afin de maintenir votre environnement Snowflake à jour.
Phase 5 : Ingestion des données¶
La migration des pipelines vers Snowflake implique le déplacement ou la réécriture de la logique basée sur les données, comme les scripts BTEQ, les procédures stockées, les macros ou les flux ETL spécialisés. Ceci inclut une transition d’orchestration, qui remplace les scripts BTEQ ou les tâches Teradata planifiées par des flux et des tâches dans Snowflake pour des transformations incrémentielles. Cela nécessite également un réalignement entrée/sortie, qui redirige plusieurs sources de données entrantes atterrissant dans Teradata vers des modèles d’ingestion Snowflake (COPY, Snowpipe).
Au cours de la phase de conversion et d’optimisation des requêtes, le SQL Teradata est converti en SQL Snowflake, qui peut inclure le remplacement de macros par des procédures ou des vues stockées, la réécriture de la logique QUALIFY, et l’ajustement des procédures stockées et des index de jointure. SnowConvert AI pour Teradata peut automatiser une grande partie de cette traduction.
Avec les données elles-mêmes dans Snowflake, vous passez maintenant à la migration ou à la réécriture d’une logique basée sur Teradata— scripts BTEQ, procédures stockées, macros ou flux ETL spécialisés.
Transition d’orchestration¶
Snowflake natif : Remplacez les scripts BTEQ ou les tâches Teradata planifiées par des flux et des tâches à l’intérieur de Snowflake pour des transformations incrémentielles.
Orchestrations externes : Si vous avez utilisé des planificateurs tiers (Airflow, Control-M, etc.), dirigez-les vers Snowflake et réécrivez tout SQL Teradata intégré.
Réalignement entrée/sortie¶
Si vous aviez plusieurs sources de données entrantes qui aboutissent dans Teradata, redirigez-les vers des modèles d’ingestion Snowflake (COPY, Snowpipe).
Si les systèmes en aval lisent depuis Teradata, prévoyez de les rediriger vers Snowflake une fois le pipeline stable.
SnowConvert AI pour Teradata est recommandée pour la traduction automatique. Elle peut gérer les macros, les procédures stockées et les scripts BTEQ, produisant du code compatible avec Snowflake.
Phase 6 : Rapports et analyses¶
Maintenant que nous avons une base de données avec des données historiques et des pipelines dynamiques qui importent continuellement de nouvelles données, l’étape suivante consiste à extraire la valeur de ces données par le biais de la Business Intelligence (BI). Les rapports peuvent être effectués à l’aide des outils BI standard ou de requêtes personnalisées. Dans les deux cas, le SQL envoyé à la base de données peut devoir être ajusté pour répondre aux exigences de Snowflake. Ces ajustements peuvent aller de simples changements de nom (qui sont courants pendant la migration) à des différences de syntaxe et à des différences sémantiques plus complexes. Tous ces éléments doivent être identifiés et traités.
Comme pour le processus d’ingestion, il est crucial d’examiner toute utilisation de la plateforme héritée et d’intégrer ces résultats dans le plan de migration. Il existe généralement deux types de rapports à prendre en compte : rapports de l’IT et rapports appartenant à des entreprises. Il est généralement plus facile de suivre les rapports de l’IT, mais les rapports appartenant à l’entreprise et les requêtes complexes créées par des utilisateurs professionnels nécessitent une approche différente.
Les utilisateurs professionnels sont un acteur clé dans le processus de migration et doivent être inclus dans la matrice RACI pendant la phase de planification. Ils doivent être formés au fonctionnement de Snowflake et doivent comprendre clairement les différences entre les plateformes. Cela leur permettra de modifier leurs requêtes et rapports personnalisés selon leurs besoins. Nous recommandons généralement une formation parallèle pour les utilisateurs professionnels, suivie d”heures de bureau avec des experts en migration qui peuvent aider à traiter les différences entre les plateformes et guider les utilisateurs à propos des ajustements qu’ils doivent effectuer.
Les utilisateurs professionnels sont finalement ceux qui « acceptent » la migration. Vous avez peut-être terminé la migration technique du point de vue de l’IT, mais si les utilisateurs professionnels ne sont pas impliqués, ils peuvent continuer à utiliser des milliers de rapports qui sont essentiels à la gestion de l’entreprise. Si ces rapports ne sont pas mis à jour pour fonctionner avec Snowflake, l’entreprise ne peut pas complètement quitter l’ancienne plateforme.
Le SQL Teradata possède des constructions qui ne sont pas dans Snowflake, et vice versa. Les différences principales sont les suivantes :
Macros : Non prises en charge dans Snowflake ; généralement remplacées par des procédures stockées ou des vues.
QUALIFY : Snowflake ne prend pas en charge
QUALIFYdirectement ; réécrire la logique en utilisant une sous-requête ou unSELECT externe.Procédures stockées : Teradata SP vs. Snowflake SP (basé sur SQL ou JavaScript). La langue procédurale diffère.
Index de jointure : Pas d’équivalent direct ; s’appuient sur le nettoyage des micropartitions et les clés de clustering.
COLLECT STATISTICS: Teradata utilise des statistiques explicites, tandis que Snowflake le fait automatiquement.
SnowConvert AI pour Teradata est recommandée pour la traduction automatique. Elle peut gérer les macros, les procédures stockées et les scripts BTEQ, produisant du code compatible avec Snowflake.
Phase 7 : Validation et test des données¶
Cela nous amène à la validation et au test des données, deux étapes souvent sous-estimées dans le processus de planification de migration. Bien sûr, l’objectif est de disposer de données aussi propres que possible avant d’entrer dans cette phase.
Chaque organisation possède ses propres méthodologies de test et ses propres exigences pour passer des données en production. Celles-ci doivent être bien comprises dès le début du projet. Quelles sont alors les stratégies utiles pour la validation des données ?
Effectuer des tests complets dans la migration Snowflake : au cours du processus de migration Snowflake, des tests complets doivent être effectués, notamment :
Des tests fonctionnels : Pour vérifier que toutes les applications et fonctionnalités migrées fonctionnent comme prévu dans le nouvel environnement, en veillant à l’intégrité et à la précision des données.
Des tests de performances : Pour évaluer les performances des requêtes, la vitesse de chargement des données et la réactivité globale du système, ce qui permet d’identifier et de remédier aux goulots d’étranglement des performances.
Des tests d’acceptation par l’utilisateur (UAT) : Impliquez les utilisateurs finaux dans le processus de test pour vous assurer que le système migré répond à leurs exigences et recueillir des commentaires pour les améliorations potentielles.
Fournir une formation et une documentation pour la migration Snowflake :
proposez une formation complète aux utilisateurs finaux sur les fonctionnalités et les meilleures pratiques de Snowflake, en abordant des sujets tels que l’accès aux données, l’optimisation des requêtes et la sécurité.
Créez une documentation complète, y compris des schémas d’architecture système, des schémas de flux de données, des procédures opérationnelles, des guides d’utilisateur, des guides de dépannage et des FAQs pour des recherches simples.
Phase 8 : Déploiement¶
Lorsque vous serez prêt pour la migration, assurez-vous que toutes les parties prenantes sont d’accord et comprennent qu’à partir de là, Snowflake sera le système d’enregistrement, et non la plateforme héritée. Vous devrez obtenir des signatures finales et officielles de la part de toutes les parties prenantes avant de poursuivre. Tous les rapports qui n’ont pas été migrés sont désormais de la responsabilité des utilisateurs professionnels. C’est pourquoi il est crucial de ne pas impliquer les utilisateurs à la dernière minute : ils doivent faire partie du processus depuis le début et doivent être informés du calendrier de migration.
En outre, vérifiez que toutes les autorisations ont été correctement accordées. Par exemple, si vous utilisez des rôles basés sur Active Directory, assurez-vous qu’ils sont créés et configurés dans Snowflake.
Quelques scénarios supplémentaires sont généralement laissés à la fin, mais ils ne doivent pas être négligés :
Clés artificielles : Si vous utilisez des clés artificielles, sachez que leur cycle de vie peut varier entre les systèmes existants et Snowflake. Ces clés doivent être synchronisées pendant la migration.
Calendrier de la migration : Selon votre secteur d’activité, il peut y avoir des moments plus ou moins favorables au cours de l’année pour effectuer une migration. Réfléchissez bien au calendrier.
Licences de plateforme héritée : N’oubliez pas que vous pouvez être amené à respecter des délais stricts liés à l’octroi de licences pour la plateforme héritée. Veillez à planifier votre migration en fonction de ces délais.
Phase 9 : Optimisation et exécution¶
Une fois qu’un système a été migré vers Snowflake, il entre en mode de maintenance normal. Tous les systèmes logiciels sont des organismes vivants qui nécessitent une maintenance continue. Cette phase, après la migration, est appelée optimisation et exécution, et elle ne fait pas partie de la migration elle-même.
L’optimisation et l’amélioration continue sont des processus permanents qui se produisent après la migration. À ce stade, votre équipe prend la propriété entière du système dans Snowflake. Le système continuera d’évoluer et l’optimisation sera impulsée par les modèles d’utilisation.
En général, nous notons que les tâches dans Snowflake ont tendance à s’exécuter plus rapidement que sur les plateformes d’origine. Si les performances ne répondent pas aux attentes, vous devrez peut-être exécuter des optimisations pour tirer pleinement parti de l’architecture unique de Snowflake. Snowflake fournit divers outils d’analyse de requêtes qui peuvent aider à identifier les goulots d’étranglement, ce qui vous permet d’optimiser des parties spécifiques du workflow.
Au cours de la phase d’optimisation, vous devrez peut-être revoir différents aspects du système. L’avantage est que vous bénéficiez déjà des capacités de Snowflake, et les tâches d’optimisation feront partie de votre routine de maintenance régulière.
Nous vous recommandons de vous concentrer sur le traitement des problèmes de performances critiques uniquement au cours de la phase de migration. Il est préférable de traiter l’optimisation comme un effort après la migration.
Besoin d’aide pour la migration ?¶
Pour les scénarios de migration complexes, les différences fonctionnelles spécifiques ou l’assistance générale, Snowflake propose des canaux d’assistance dédiés, tels que snowconvert-support@snowflake.com. En outre, l’utilisation des ressources de migration étendues de Snowflake, y compris les Master Class, les webinaires et les guides de référence détaillés spécifiquement pour les migrations Teradata, peut améliorer considérablement la probabilité de réussite de la migration.
La migration réussie de la plateforme de données depuis Teradata ne dépend pas uniquement de l’outil de conversion lui-même. Au lieu de cela, elle s’appuie sur une stratégie holistique qui intègre l’efficacité de l’automatisation (fournie par SnowConvert AI), les capacités de calcul critique et de résolution des problèmes des experts humains (tels que les architectures de données), et le support et les ressources complets offerts par l’écosystème de la plateforme cible (y compris la documentation, les services d’assistance et les meilleures pratiques de Snowflake). Cela implique que les organisations doivent investir stratégiquement non seulement dans l’outil de migration, mais également dans le renforcement des compétences de leurs équipes en matière de capacités natives de Snowflake et dans l’établissement de processus de validation robustes. Le but final n’est pas simplement de déplacer les données, mais de * moderniser* l’ensemble du fonctionnement des données, aboutissant à une plateforme de données Cloud plus résistante, plus performante et plus prête pour l’avenir.
Annexe¶
Annexe 1 : Bases de données Teradata à exclure lors de la migration vers Snowflake¶
La liste suivante des bases de données est nécessaire pour Teradata uniquement et ne doit pas être migrée vers Snowflake :
DBC Crashdumps Dbcmngr External_AP EXTUSER LockLogShredder QCD SQLJ Sys_Calendar |
SysAdmin SYSBAR SYSJDBC SYSLIB SYSSPATIAL SystemFE SYSUDTLIB SYSUIF TD_SERVER_DB |
TD_SYSFNLIB TD_SYSGPL TD_SYSXML TDPUSER TDQCD TDStats tdwm |
|---|
Annexe 2 : Types Teradata vers types de données Snowflake¶
Type de colonne Teradata |
Type de données Teradata |
Type de données Snowflake |
|---|---|---|
++ |
TD_ANYTYPE |
Le type de données TD_ANYTYPE n’est pas pris en charge dans Snowflake. |
A1 |
ARRAY |
ARRAY |
AN |
ARRAY |
ARRAY |
AT |
TIME |
TIME |
BF |
BYTE |
BINARY |
BO |
BLOB |
Le type de données BLOB n’est pas directement pris en charge, mais peut être remplacé par BINARY (limité à 8MB). |
BV |
VARBYTE |
BINARY |
CF |
CHAR |
VARCHAR |
CO |
CLOB |
Le type de données CLOB n’est pas directement pris en charge, mais peut être remplacé par VARCHAR (limité à 16MB). |
CV |
VARCHAR |
VARCHAR |
D |
DECIMAL |
NUMBER |
DA |
DATE |
DATE |
DH |
INTERVAL DAY TO HOUR |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD) |
DM |
INTERVAL DAY TO MINUTE |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD) |
DS |
INTERVAL DAY TO SECOND |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD). |
DT |
DATASET |
Le type de données DATASET n’est pas pris en charge dans Snowflake. |
DY |
INTERVAL DAY |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD). |
F |
FLOAT |
FLOAT |
HM |
INTERVAL HOUR TO MINUTE |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD). |
HR |
INTERVAL HOUR |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD). |
HS |
INTERVAL HOUR TO SECOND |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD). |
I1 |
BYTEINT |
NUMBER |
I2 |
SMALLINT |
NUMBER |
I8 |
BIGINT |
NUMBER |
I |
INTEGER |
NUMBER |
JN |
JSON |
VARIANT |
LF |
CHAR |
Ce type de données est dans DBC uniquement et ne peut être converti en Snowflake. |
LV |
VARCHAR |
Ce type de données est dans DBC uniquement et ne peut être converti en Snowflake. |
MI |
INTERVAL MINUTE |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD). |
MO |
INTERVAL MONTH |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD) |
MS |
INTERVAL MINUTE TO SECOND |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD). |
N |
NUMBER |
NUMBER |
PD |
PERIOD(DATE) |
Peut être converti en VARCHAR ou divisé en 2 dates distinctes. |
PM |
PERIOD(TIMESTAMP WITH TIME ZONE) |
Peut être converti en VARCHAR ou divisé en 2 horodatages distincts (TIMESTAMP_TZ). |
PS |
PERIOD(TIMESTAMP) |
Peut être converti en VARCHAR ou divisé en 2 horodatages distincts (TIMESTAMP_NTZ). |
PT |
PERIOD(TIME) |
Peut être converti en VARCHAR ou divisé en 2 heures distinctes. |
PZ |
PERIOD(TIME WITH TIME ZONE) |
Peut être converti en VARCHAR ou divisé en 2 heures distinctes mais WITH TIME ZONE n’est pas pris en charge pour TIME. |
SC |
INTERVAL SECOND I |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD). |
SZ |
TIMESTAMP WITH TIME ZONE |
TIMESTAMP_TZ |
TS |
TIMESTAMP |
TIMESTAMP_NTZ |
TZ |
TIME WITH TIME ZONE |
TIME WITH TIME ZONE n’est pas pris en charge car TIME est stocké en utilisant l’heure « horloge murale » uniquement, sans décalage de fuseau horaire. |
UF |
CHAR |
Ce type de données est dans DBC uniquement et ne peut être converti en Snowflake. |
UT |
UDT |
Le type de données UDT n’est pas pris en charge dans Snowflake. |
UV |
VARCHAR |
Ce type de données est dans DBC uniquement et ne peut être converti en Snowflake. |
XM |
XML |
VARIANT |
YM |
INTERVAL YEAR TO MONTH |
Les types de données INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD) |
YR |
INTERVAL YEAR |
Les types de données YR INTERVAL YEAR INTERVAL ne sont pas pris en charge dans Snowflake, mais les calculs de dates peuvent être effectués avec les fonctions de comparaison de dates (par exemple DATEDIFF et DATEADD). |