Leitfaden zur Migration von Teradata zu Snowflake¶
Snowflake-Migrationsframework¶
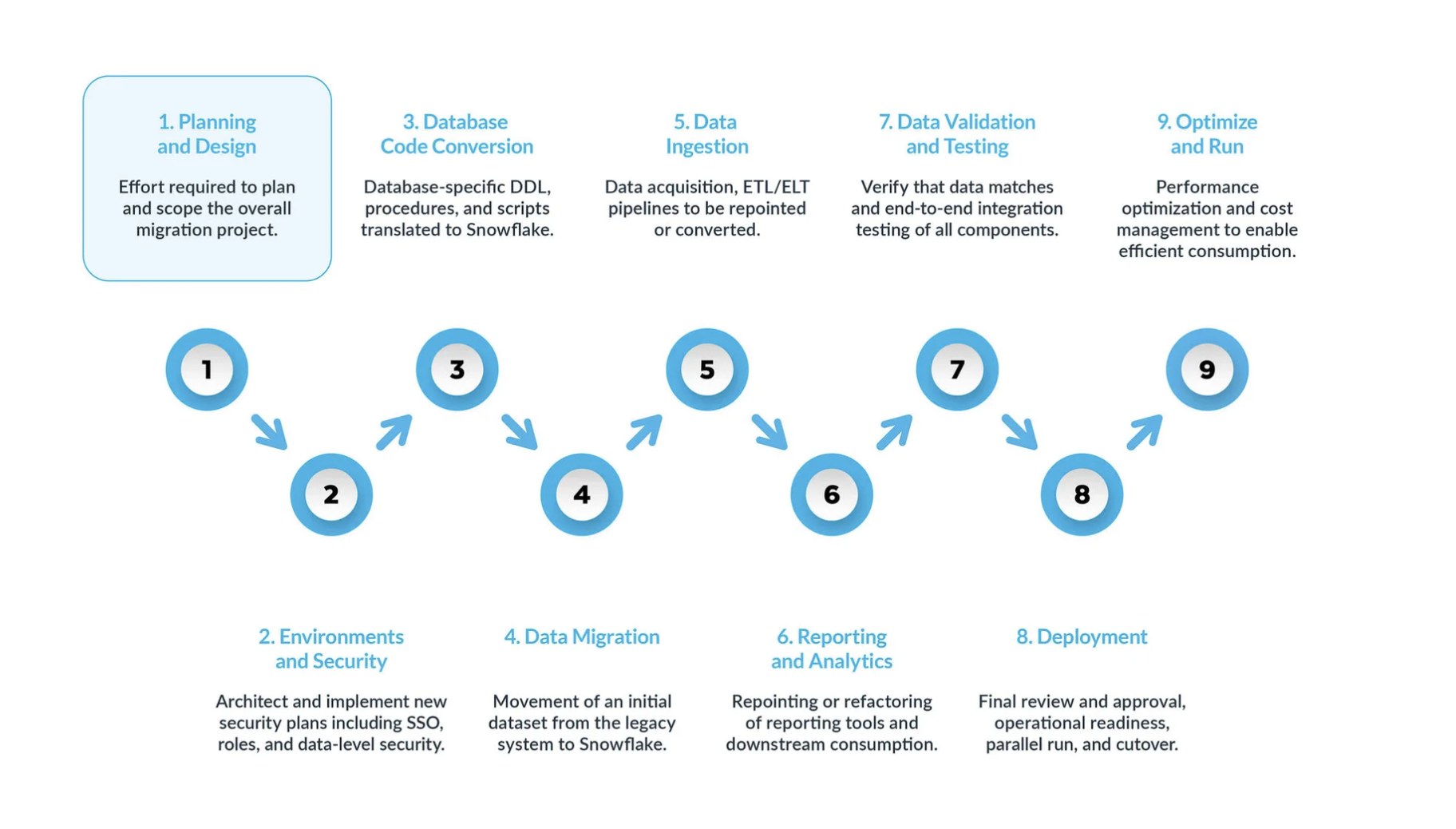
Eine typische Teradata-zu-Snowflake-Migration kann in fünf Hauptschritte unterteilt werden:
Planung und Entwurf sind oft übersehene Schritte im Migrationsprozess. Der Hauptgrund ist, dass Unternehmen in der Regel schnell Fortschritte zeigen möchten, auch wenn sie den Umfang des Projekts nicht vollständig verstanden haben. Daher ist diese Phase entscheidend, um das Migrationsprojekt zu verstehen und zu priorisieren.
Umgebung und Sicherheit – mit einem Plan, einem klaren Zeitplan, einer RACI-Matrix und der Zustimmung aller Beteiligten ist es nun an der Zeit, in die Umsetzungsphase überzugehen. Die Einrichtung der erforderlichen Umgebungen und Sicherheitsmaßnahmen vor Beginn der Migrationsphase ist äußerst wichtig, da viele Komponenten ineinandergreifen. Das Migrationsprojekt wird deutlich erfolgreicher verlaufen, wenn alle Vorbereitungen abgeschlossen sind, bevor es weitergeht.
Der Prozess der Datenbankcode-Konvertierung umfasst das Extrahieren von Code direkt aus dem Datenbankkatalog der Quellsysteme, wie z. B. Tabellendefinitionen, Ansichten, gespeicherten Prozeduren und Funktionen. Sobald Sie diesen Code extrahiert haben, migrieren Sie diesen Code in entsprechende Datendefinitionssprachen (DDLs) in Snowflake. Dieser Schritt umfasst auch die Migration von Data Manipulation Language (DML)-Skripten, die von Business-Analysten zur Erstellung von Berichten oder Dashboards verwendet werden können. Der gesamte Code muss migriert und angepasst werden, damit er in Snowflake funktioniert. Die Anpassungen können von einfachen Änderungen, wie Namenskonventionen und Zuordnungen von Datentypen, bis hin zu komplexeren Unterschieden in der Syntax, der Semantik der Plattformen und anderen Faktoren reichen. Um dies zu unterstützen, bietet Snowflake eine leistungsstarke Lösung namens SnowConvert AI, die einen großen Teil des Konvertierungsprozesses von Datenbankcode automatisiert.
Datenmigration Bei der Datenmigration werden Daten zwischen verschiedenen Speichersystemen, Formaten oder Computersystemen übertragen. Im Zusammenhang mit einer Migration von Teradata nach Snowflake bezieht sich der Begriff speziell auf das Verschieben von Daten aus Ihrer Teradata-Umgebung in Ihre neue Snowflake-Umgebung. Es gibt zwei Haupttypen, die in diesem Leitfaden behandelt werden:
Migration historischer Daten: Erstellen eines Snapshots von Teradata-Daten zu einem bestimmten Zeitpunkt und Übertragen dieser Daten auf Snowflake. Dies erfolgt oft als erste Massenübertragung.
Inkrementelle Datenmigration: Laufende Übertragung neuer oder geänderter Daten von Teradata nach Snowflake nach der anfänglichen historischen Migration. Dadurch wird sichergestellt, dass Ihre Snowflake-Umgebung mit Ihren Quellsystemen auf dem neuesten Stand bleibt.
Datenaufnahme: Nach der Migration der historischen Daten besteht der nächste Schritt in der Migration des Datenaufnahmeprozesses, bei dem Live-Daten aus verschiedenen Quellen eingelesen werden. Typischerweise folgt dieser Prozess einem Extract, Transform, Load (ETL)- oder Extract, Load, Transform (ELT)-Modell – je nachdem, wann und wo die Datenumwandlung erfolgt, bevor die Daten den Business-Usern zur Verfügung stehen.
Berichterstellung und Analysen: Da die Datenbank nun sowohl historische Daten als auch laufende Pipelines enthält, die kontinuierlich neue Daten importieren, besteht der nächste Schritt darin, aus diesen Daten durch BI Wert zu schöpfen. Die Berichterstellung kann mit Standard-BI-Tools oder benutzerdefinierten Abfragen erfolgen. In beiden Fällen muss das an die Datenbank gesendete SQL möglicherweise angepasst werden, um den Anforderungen von Snowflake zu entsprechen. Diese Anpassung kann von einfachen Namensänderungen (häufig während der Migration) bis hin zur Syntax und komplexeren semantischen Unterschieden reichen. Sie alle müssen identifiziert und erledigt werden.
Datenvalidierung und -tests: Das Ziel besteht darin, die Daten so sauber wie möglich zu haben, bevor diese Phase beginnt. Jedes Unternehmen hat seine eigenen Testmethoden und Anforderungen, um Daten in die Produktion zu verschieben. Diese müssen von Beginn des Projekts an vollständig verstanden werden.
Bereitstellung. In dieser Phase werden die Daten validiert, ein entsprechendes System eingerichtet, alle ETLs wurden migriert und die Berichte wurden verifiziert. Sind Sie bereit, live zu gehen? Nicht so schnell – es gibt noch einige kritische Überlegungen, bevor es endgültig in die Produktion gehen kann. Erstens kann Ihre Legacy-Anwendung aus mehreren Komponenten oder Services bestehen. Idealerweise sollten Sie diese Anwendungen eine nach der anderen migrieren (obwohl eine parallele Migration möglich ist) und sie in der gleichen Reihenfolge in die Produktion überführen. Stellen Sie während dieses Prozesses sicher, dass Ihre Bridging-Strategie implementiert ist, damit Business-User nicht sowohl Snowflake als auch das Altsystem abfragen müssen. Die Datensynchronisierung für Anwendungen, die noch nicht migriert wurden, sollte im Hintergrund durch den Bridging-Mechanismus erfolgen. Wenn dies nicht geschieht, müssen die Benutzer in einer hybriden Umgebung arbeiten und die Auswirkungen dieses Setups verstehen.
Optimieren und ausführen – sobald ein System auf Snowflake migriert wurde, wechselt es in den normalen Wartungsmodus. Alle Softwaresysteme sind lebende Organismen, die eine laufende Wartung erfordern. Diese Phase nach der Migration wird als „Optimieren und Ausführen“ bezeichnet und ist nicht Teil der Migration selbst.
Migrationsphasen¶
Phase 1: Planung und Design¶
Diese Phase ist der entscheidende erste Schritt für eine erfolgreiche Snowflake-Migration. Sie bildet die Grundlage für den gesamten Migrationsprozess, indem sie den Umfang, die Ziele und die Anforderungen definiert. Diese Phase beinhaltet ein großes Verständnis der aktuellen Umgebung und eine klare Vorstellung von dem zukünftigen Zustand von Snowflake.
Während dieser Phase identifizieren Organisationen die wichtigsten geschäftlichen Faktoren und technischen Ziele für die Migration zu Snowflake, indem sie die folgenden Aufgaben ausführen:
Ausführen einer gründlichen Bewertung der Teradata-Umgebung¶
Um eine gründliche Bewertung der aktuellen Umgebung vorzunehmen, ist es wichtig, mit der Inventarisierung der bestehenden Datenbestände zu beginnen. Dabei werden nicht nur Datenbanken und Dateien, sondern auch alle externen Systeme dokumentiert, wobei Datentypen, Schemas und bestehende Probleme mit der Datenqualität sorgfältig geprüft werden. Gleichzeitig ist die Analyse von Abfrage-Workloads unerlässlich, um häufig ausgeführte und ressourcenintensive Abfragen zu identifizieren, die Aufschluss über Datenzugriffsmuster und Benutzerverhalten geben. Schließlich ist die Bewerteung von Sicherheits- und Compliance-Anforderungen nicht vernachlässigbar und erfordert die Identifizierung sensibler Daten, gesetzlicher Bestimmungen und potenzieller Schwachstellen innerhalb des bestehenden Systems.
Phase 2: Umgebung und Sicherheit¶
Einer der ersten Schritte, die wir empfehlen, ist die Einrichtung der notwendigen Umgebungen und Sicherheitsmaßnahmen, um mit der Migration zu beginnen. Vieles spielt zusammen – beginnen wir also mit der Sicherheit. Wie bei jeder Cloudplattform arbeitet Snowflake nach einem gemeinsamen Sicherheitsmodell zwischen der Plattform und Administratoren.
¶
Einrichten von Umgebungen¶
Zunächst müssen Sie entscheiden, wie viele Konten Sie benötigen. Auf älteren Plattformen hatten Sie normalerweise Datenbankinstanzen, aber in Snowflake konzentriert sich die Einrichtung auf Konten. Sie sollten mindestens eine Produktionsumgebung und eine Entwicklungsumgebung einrichten. Abhängig von Ihrer Teststrategie benötigen Sie möglicherweise zusätzliche Umgebungen für verschiedene Testphasen.
Sicherheitsmaßnahmen¶
Sobald die Umgebungen eingerichtet sind, ist es wichtig, die richtigen Sicherheitsmaßnahmen zu implementieren. Beginnen Sie mit der Netzwerkrichtlinie, um sicherzustellen, dass nur autorisierte Benutzer innerhalb Ihrer VPN auf das Snowflake-System Zugriff erhalten.
Die Benutzerzugriffssteuerung von Snowflake ist rollenbasiert, sodass Administratoren Rollen entsprechend den Geschäftsanforderungen definieren müssen. Sobald die Rollen definiert sind, erstellen Sie die Benutzerkonten und erzwingen die mehrstufige Authentifizierung (MFA) und/oder Single Sign-On (SSO) für alle Benutzer. Außerdem müssen Sie Dienstkonten einrichten und sicherstellen, dass Sie sich bei diesen Konten nicht auf die herkömmliche Authentifizierung mit Benutzername und Kennwort verlassen.
Rollen während der Migration¶
Während der Migration müssen Sie auch bestimmte Rollen für die Benutzer definieren, die die Migration selbst ausführen. Auch wenn sich die Rollen für Nicht-Produktionsumgebungen unterscheiden können, denken Sie daran, dass Sie es während der Migration mit echten Daten zu tun haben. An der Sicherheit sollten Sie nie sparen – auch nicht in Test- oder Entwicklungsumgebungen.
In der Entwicklung hat das Migrationsteam im Allgemeinen mehr Freiheit, wenn es Änderungen an der Struktur oder dem Code vornimmt. Dies sind aktive Entwicklungsumgebungen, und Sie möchten das Migrationsteam nicht mit übermäßigen Sicherheitseinschränkungen blockieren. Es ist jedoch weiterhin wichtig, ein robustes Sicherheitsmodell aufrechtzuerhalten, auch in nicht produktiven Umgebungen.
Überarbeiten des Access Models¶
Da sich das Sicherheitsmodell in Snowflake von dem vieler Legacy-Plattformen unterscheidet, ist diese Migration eine gute Gelegenheit, Ihr Zugriffsmodell zu überarbeiten. Bereinigen Sie die Hierarchie der Benutzer, die Zugriff auf Ihr System benötigen, und stellen Sie sicher, dass nur die erforderlichen Benutzer Zugriff auf bestimmte Ressourcen haben.
Koordination mit der Finanzabteilung¶
Snowflake verwendet ein verbrauchsabhängiges Preismodell, d. h. die Kosten sind an die Nutzung gebunden. Wenn Sie Rollen definieren, ist es eine gute Idee, sich mit Ihrem Finanzteam abzustimmen, um zu verfolgen, welche Abteilungen Snowflake wie nutzen. Snowflake ermöglicht es Ihnen auch, Datenbankobjekte zu taggen, um die Eigentümerschaft auf Geschäftsebene zu verfolgen und so die Nutzung mit der Kostenzuweisung der Abteilungen in Einklang zu bringen.
Der Sicherheits- und Umgebungsaufbau sind komplexe Aufgaben, die im Voraus geplant werden müssen. Möglicherweise müssen Sie sogar eine Neugestaltung Ihres Zugriffsmodells in Betracht ziehen, um sicherzustellen, dass die neue Plattform auf Weiteres verwaltet werden kann. Nehmen Sie sich die Zeit für eine korrekte Einrichtung. So legen Sie eine starke Grundlage für eine sichere und effiziente Migration zu Snowflake.
Phase 3: Konvertieren von Datenbankcode¶
SnowConvert AI versteht den Teradata-Quellcode und konvertiert die Data Definition Language (DDL), Data Manipulation Language (DML) und Funktionen im Quellcode auf das entsprechende SQL im Ziel: Snowflake SnowConvert AI kann den Quellcode in jedem dieser drei Formate migrieren: .sql, .dml oder .ddl.
In dieser Phase wird Code direkt aus dem Datenbankkatalog der Quellsysteme extrahiert, z. B. Tabellendefinitionen, Ansichten, gespeicherte Prozeduren und Funktionen. Sobald Sie diesen Code extrahiert haben, migrieren Sie den gesamten Code in die entsprechende DDLs (Data Definition Language) in Snowflake. Dieser Schritt umfasst auch die Migration von DML (Data Manipulation Language)-Skripten, die von Geschäftsanalysten zum Erstellen von Berichten oder Dashboards verwendet werden.
Lesen Sie unsere empfohlenen Extraktionsskripte hier
Teradaten DDL enthält typischerweise Verweise auf Primärindizes, Fallback oder Partitionierung. In Snowflake existieren diese Strukturen nicht auf dieselbe Weise:
[Verwenden Sie SnowConvert AI für Teradata] (https://www.snowflake.com/en/migrate-to-the-cloud/snowconvert/), das den Konvertierungsprozess der Data Definition Language (DDL) erheblich vereinfacht, insbesondere bei einer großen Anzahl von Tabellen. Es automatisiert die Übersetzung der spezifischen Teradata-DDL-Konstrukte, wie Primärindexdefinitionen und Fallback-Optionen, in die entsprechenden Strukturen von Snowflake. Diese Automatisierung reduziert den manuellen Aufwand und minimiert das Fehlerrisiko, sodass sich die Teams auf die übergeordnete Migrationsstrategie und die Validierung konzentrieren können. Über die grundlegende DDL-Konvertierung hinaus behandelt SnowConvert AI auch Feinheiten wie die Zuordnung von Datentypen und die Umstrukturierung von Schemas. Es kann Datentypen automatisch an die in Snowflake verfügbaren Typen anpassen und dabei helfen zu entscheiden, ob Schemas für optimale Performance und eine bessere Verwaltung zusammengeführt oder aufgeteilt werden sollten. Dieser umfassende Ansatz stellt sicher, dass die migrierte Datenbankstruktur nicht nur funktionsfähig, sondern auch für die -Architektur von Snowflake optimiert ist.
Passen Sie die Datentypen bei Bedarf an oder verwenden Sie den Migrations AI-Assistenten, um etwaige Fehler oder Warnungen (EWI, Errors oder Warnings) zu beheben.
Entscheiden Sie, ob Schemas reorganisiert werden sollen (z. B. Aufteilen großer, monolithischer Schemas in mehrere Snowflake-Datenbanken).
Hinweise zur Teradaten-Migration¶
Bei der Migration von Daten von Teradata zu Snowflake ist es wichtig, die Funktionsunterschiede zwischen den Datenbanken zu berücksichtigen.
Sitzungsmodi in Teradata¶
Die Teradata-Datenbank verfügt über verschiedene Modi für die Ausführung von Abfragen: ANSI Modus (Regeln basierend auf den ANSI SQL: 2011 Spezifikationen) und TERA Modus (von Teradata definierte Regeln). Bitte lesen Sie die folgende Teradata-Dokumentation für weitere Informationen.
Teradata-Modus für informative String-Tabellen
Bei Zeichenfolgen funktioniert der Teradata-Modus anders. Wie in der folgenden Tabelle, die auf der Teradata-Dokumentation basiert, erläutert wird:
Feature |
ANSI-Modus |
Teradata-Modus |
|---|---|---|
Standardattribut für Zeichenvergleiche |
CASESPECIFIC |
NOT-CASESPECIFIC |
Standard-TRIM-Verhalten |
TRIM(BOTH FROM) |
TRIM(BOTH FROM) |
Zusammenfassung der Übersetzungsspezifikation
Modus |
Werte der Spalteneinschränkungen |
Teradata-Verhaltensweise |
Erwartetes SC-Verhalten |
|---|---|---|---|
ANSI-Modus |
CASESPECIFIC |
CASESPECIFIC |
Keine Einschränkung hinzugefügt. |
NOT-CASESPECIFIC |
CASESPECIFIC |
COLLATE „en-cs“ in der Spaltendefinition hinzufügen |
|
Teradata-Modus |
CASESPECIFIC |
CASESPECIFIC |
In den meisten Fällen sollten Sie COLLATE nicht hinzufügen und die entsprechenden Zeichenfolgenvergleiche in RTRIM (Ausdruck) umwandeln. |
NOT-CASESPECIFIC |
NOT-CASESPECIFIC |
In den meisten Fällen sollten Sie COLLATE nicht hinzufügen und die entsprechenden Zeichenfolgenvergleiche in RTRIM (UPPER (Ausdruck)) umwandeln. |
Verfügbare Optionen für die Übersetzungsspezifikation
SQL-Übersetzungsreferenz¶
Verwenden Sie dies als Leitfaden, um zu verstehen, wie der transformierte Code bei der Migration von Teradata zu Snowflake aussehen könnte. SQL hat eine ähnliche Syntax zwischen Dialekten, aber jeder Dialekt kann Funktionen erweitern oder neue hinzufügen.
Aus diesem Grund gibt es beim Ausführen von SQL in einer Umgebung (z. B. Teradata) im Vergleich zu einer anderen (z. B. Snowflake) viele Anweisungen, die angepasst oder sogar entfernt werden müssen. Diese Transformationen werden von SnowConvert AI ausgeführt.
Weitere Informationen zu bestimmten Themen finden Sie auf den folgenden Seiten.
Datentypen vergleichen Teradata-Datentypen und ihre Äquivalente in Snowflake.
DDL untersucht die Übersetzung der Datendefinitionssprache (Data Definition Language).
DML untersucht die Übersetzung der Datenbearbeitungssprache (Data Manipulation Language).
Integrierte Funktionen vergleichen die im Laufzeitsystem beider Sprachen enthaltenen Funktionen.
SQL zu JavaScript (Prozeduren)¶
Skripte zu Snowflake SQL-Übersetzungsreferenz¶
Übersetzungsreferenz zum Konvertieren von Teradata-Skriptdateien in Snowflake SQL
Übersetzungsreferenz für Skripte in Python¶
In diesem Abschnitt wird beschrieben, wie SnowConvert AI die Teradata-Skripte (BTEQ, FastLoad, MultiLoad, TPUMP usw.) in eine mit Snowflake kompatible Skriptsprache übersetzt.
Weitere Informationen zu bestimmten Themen finden Sie auf den folgenden Seiten.
Phase 4: Datenmigration¶
Zunächst ist es wichtig, zwischen der Migration historischer Daten und dem Hinzufügen neuer Daten zu unterscheiden. Die historische Datenmigration bezieht sich darauf, eine Momentaufnahme der Daten zu einem bestimmten Zeitpunkt zu erstellen und diese nach Snowflake zu übertragen. Wir empfehlen, zunächst eine exakte Kopie der Daten zu erstellen, ohne eine Transformation in Snowflake vorzunehmen. Durch diese erste Kopie wird die alte Plattform etwas ausgelastet, sodass Sie sie nur einmal ausführen und in Snowflake speichern sollten.
Ihre umführbaren Schritte:
Migration historischer Daten durchführen: Erstellen Sie eine Momentaufnahme Ihrer Teradata-Daten zu einem bestimmten Zeitpunkt und übertragen Sie sie nach Snowflake – häufig als anfängliche Massenübertragung. Es wird empfohlen, zunächst eine exakte Kopie ohne Transformation zu erstellen.
Inkrementelle Datenmigration planen: Richten Sie nach der ersten historischen Migration Prozesse ein, um neue oder geänderte Daten von Teradata kontinuierlich in Snowflake zu verschieben und Ihre Snowflake-Umgebung auf dem neuesten Stand zu halten.
Phase 5: Datenaufnahme¶
Bei der Pipeline-Migration zu Snowflake wird die auf Teradaten basierende Logik verschoben oder neu geschrieben, z. B. BTEQ-Skripte, gespeicherte Prozeduren, Makros oder spezielle ETL-Flüsse. Dies umfasst eine Orchestrierungsumstellung, bei der BTEQ- oder geplante Teradata-Jobs durch Streams und Tasks in Snowflake ersetzt werden, um inkrementelle Transformationen durchzuführen. Es erfordert außerdem eine Quell-/Ziel-Neuausrichtung, bei der mehrere eingehende Datenquellen, die bisher in Teradata landeten, auf Snowflake-Einbindungsmuster (COPY, Snowpipe) umgeleitet werden.
Während der Phase der Abfragekonvertierung und -optimierung wird Teradata SQL in Snowflake SQL konvertiert, was das Ersetzen von Makros durch gespeicherte Prozeduren oder Ansichten und das Umschreiben von QUALIFY-Logik sowie das Anpassen von gespeicherten Prozeduren und Verknüpfungsindizes umfassen kann. SnowConvert AI für Teradata kann einen großen Teil dieser Übersetzung automatisieren.
Da sich die Daten nun in Snowflake befinden, folgt der nächste Schritt: die Migration oder Neuschreibung der Teradata-basierten Logik – etwa BTEQ-Skripte, gespeicherte Prozeduren, Makros oder spezialisierte ETL-Flows.
Umstellung der Orchestrierung¶
Native Snowflake: Ersetzen Sie BTEQ- oder geplante Teradata-Jobs mit Streams und Aufgaben innerhalb von Snowflake für inkrementelle Transformationen.
Externe Orchestratoren: Wenn Sie Drittanbieter-Scheduler (wie Airflow, Control-M usw.) verwendet haben, richten Sie diese auf Snowflake aus und schreiben Sie alle eingebetteten Teradata SQL-Skripte neu.
Neuausrichtung von Quelle/Ziel¶
Wenn Sie mehrere eingehende Datenquellen hatten, die in Teradata eingingen, leiten Sie diese auf Snowflake-Einbindungsmuster (COPY, Snowpipe) um.
Wenn nachgelagerte Systeme aus Teradata lesen, sollten Sie planen, sie erst wieder auf Snowflake zu verweisen, sobald sich die Pipeline stabilisiert hat.
SnowConvert AI für Teradata wird für die automatisierte Übersetzung empfohlen. Sie kann Makros, gespeicherte Prozeduren und BTEQ-Skripte verarbeiten, die Snowflake-kompatiblen Code ausgeben.
Phase 6: Berichterstattung und Analyse¶
Da wir nun eine Datenbank mit historischen Daten und Live-Pipelines haben, die kontinuierlich neue Daten importieren, besteht der nächste Schritt darin, Wert aus diesen Daten mithilfe von Business Intelligence (BI) zu extrahieren. Die Berichterstellung kann mit Standard-BI-Tools oder benutzerdefinierten Abfragen erfolgen. In beiden Fällen muss das an die Datenbank gesendete SQL möglicherweise angepasst werden, um den Anforderungen von Snowflake zu entsprechen. Diese Anpassungen können von einfachen Namensänderungen (die während der Migration häufig sind) bis hin zu Syntaxunterschieden und komplexeren semantischen Unterschieden reichen. Sie alle müssen identifiziert und behandelt werden.
Wie beim Einbindungsprozess ist es entscheidend, die Nutzung der Altsystemplattform vollständig zu überprüfen und die daraus gewonnenen Erkenntnisse in den Migrationsplan einfließen zu lassen. Im Allgemeinen gibt es zwei Arten von Berichten, die berücksichtigt werden sollten: IT-eigene Berichte und geschäftseigene Berichte. Berichte, die von der IT verwaltet werden, lassen sich in der Regel leichter nachverfolgen, aber von Fachbereichen erstellte Berichte und komplexe Abfragen von Business-Usern erfordern einen anderen Ansatz.
Business-User sind wichtige Interessengruppen im Migrationsprozess und sollten in der RACI-Matrix während der Planungsphase berücksichtigt werden. Sie müssen in der Funktionsweise von Snowflake trainiert werden und die Unterschiede der Plattform genau verstehen. Auf diese Weise können sie ihre kundenspezifischen Abfragen und Berichte bei Bedarf ändern. Wir empfehlen in der Regel einen parallelen Schulungspfad für Business-User, gefolgt von offenen Sprechstunden mit Migrationsexperten, die dabei helfen, Plattformunterschiede zu erklären und die Benutzer bei den notwendigen Anpassungen zu unterstützen.
Die Geschäftsanwender sind letztendlich diejenigen, die die Migration „akzeptieren“. Sie haben die technische Migration möglicherweise aus IT-Sicht abgeschlossen, aber wenn die Business-User nicht einbezogen werden, verlassen sie sich möglicherweise weiterhin auf Tausende von Berichten, die für den Geschäftsbetrieb entscheidend sind. Wenn diese Berichte nicht so aktualisiert werden, dass sie mit Snowflake funktionieren, kann das Unternehmen nicht vollständig von der Altsystemplattform weg migrieren.
Teradata SQL hat einige Konstrukte, die nicht in Snowflake enthalten sind, und umgekehrt. Unterschiede:
Macros: Nicht unterstützt von Snowflake; werden in der Regel durch gespeicherte Prozeduren oder Ansichten ersetzt.
QUALIFY: Snowflake unterstütz
QUALIFYnicht direkt. Schreiben Sie die Logik mithilfe einer Unterabfrage oder eines Outer-SELECT um.Gespeicherte Prozeduren: Teradata SP vs. Snowflake SP (SQL oder JavaScript-basiert). Die prozedurale Sprache unterscheidet sich.
Join-Indizes: Haben kein direktes Äquivalent; verlassen sich auf das Bereinigen von Mikropartitionen und Gruppierungsschlüsseln.
COLLECT STATISTICS: Teradata verwendet explizite Statistiken, während Snowflake diesen Prozess automatisch durchführt.
SnowConvert AI für Teradata wird für die automatisierte Übersetzung empfohlen. Sie kann Makros, gespeicherte Prozeduren und BTEQ-Skripte verarbeiten, die Snowflake-kompatiblen Code ausgeben.
Phase 7: Datenvalidierung und -tests¶
Dies führt uns zur Datenvalidierung und -tests, zwei oft unterschätzten Schritten bei der Migrationsplanung. Natürlich ist das Ziel, die Daten so gut zu bereinigen wie möglich, bevor diese Phase beginnt.
Jedes Unternehmen hat seine eigenen Testmethoden und Anforderungen, um Daten in die Produktion zu verschieben. Diese müssen von Beginn des Projekts an vollständig verstanden werden. Was sind also nützliche Strategien für die Datenvalidierung?
Durchführen umfassender Tests bei der Snowflake-Migration: Während des Snowflake-Migrationsprozesses müssen umfassende Tests durchgeführt werden, einschließlich:
Funktionstests: Überprüfen, ob alle migrierten Anwendungen und Funktionalitäten in der neuen Umgebung wie erwartet funktionieren, um Datenintegrität und -genauigkeit sicherzustellen.
Performance-Tests: Zur Bewertung der Abfrage-Performance, der Geschwindigkeit beim Laden von Daten und der allgemeinen Reaktionsfähigkeit des Systems, um Performance-Engpässe zu erkennen und zu beheben.
Benutzerakzeptanztests (UAT): Einbeziehung der Endbenutzer in den Testprozess, um sicherzustellen, dass das migrierte System deren Anforderungen entspricht, und um Feedback für mögliche Verbesserungen zu sammeln.
Bereitstellen von Training und Dokumentation für die Snowflake-Migration:
Umfassende Schulungen für Endbenutzer zu Features, Funktionen und Best Practices von Snowflake zu Themen wie Datenzugriff, Abfrageoptimierung und Sicherheit.
Erstellen Sie eine umfassende Dokumentation, einschließlich Abbildungen der Systemarchitektur, Datenflussdiagramme, betriebliche Prozeduren, Benutzerhandbücher, Anleitungen zur Problembehandlung und FAQs zum einfachen Verweisen.
Phase 8: Bereitstellung¶
Wenn Sie schließlich für die Umstellung bereit sind, stellen Sie sicher, dass alle Interessengruppen auf einer Liste abgestimmt sind und verstehen, dass von diesem Zeitpunkt an Snowflake das System der Datensätze und nicht die alte Plattform sein wird. Sie benötigen die endgültigen und formalen Genehmigungen aller Beteiligten, bevor Sie fortfahren. Für alle Berichte, die nicht migriert wurden, sind nun die Geschäftsanwender verantwortlich. Aus diesem Grund ist es wichtig, die Benutzer nicht erst in letzter Minute einzubeziehen – Sie sollten von Anfang an in den Prozess einbezogen werden und sich des Zeitrahmens der Migration bewusst sein.
Überprüfen Sie außerdem, ob alle Berechtigungen ordnungsgemäß gewährt wurden. Wenn Sie z. B. Active Directory-basierte Rollen verwenden, stellen Sie sicher, dass diese in Snowflake erstellt und konfiguriert werden.
Einige zusätzliche Szenarien werden normalerweise bis zum Schluss aufgeschoben, sollten jedoch nicht übersehen werden:
Ersatzschlüssel: Wenn Sie Ersatzschlüssel verwenden, beachten Sie, dass sich deren Lebenszyklus zwischen dem Altsystem und Snowflake unterscheiden kann. Diese Schlüssel müssen während der Umstellung synchronisiert werden.
Cutover-Zeitpunkt: Abhängig von Ihrer Branche kann es im Laufe des Jahres mehr oder weniger erfolgreiche Zeitpunkte für die Durchführung einer Umstellung geben. Prüfen Sie den Zeitpunkt sorgfältig.
Legacy-Plattformlizenz: Vergessen Sie nicht, dass Ihnen im Zusammenhang mit der Lizenz der alten Plattform möglicherweise strenge Fristen gesetzt werden. Achten Sie darauf, dass Sie bei der Umstellung solche Fristen berücksichtigen.
Phase 9: Optimieren und ausführen¶
Sobald ein System auf Snowflake migriert wurde, wechselt es in den normalen Wartungsmodus. Alle Softwaresysteme sind lebende Organismen, die eine laufende Wartung benötigen. Wir bezeichnen diese Phase nach der Migration als „Optimieren“ und „Ausführen“ und betonen, dass sie nicht Teil der Migration selbst ist.
Optimierung und kontinuierliche Verbesserung sind fortlaufende Prozesse, die nach der Migration stattfinden. Zu diesem Zeitpunkt übernimmt Ihr Team die volle Eigentümerschaft für das System in Snowflake. Das System wird sich weiter weiterentwickeln, und die Optimierung wird von Nutzungsmustern bestimmt.
Im Allgemeinen stellen wir fest, dass Jobs in Snowflake tendenziell schneller ausgeführt werden als auf den ursprünglichen Plattformen. Wenn die Leistung nicht den Erwartungen entspricht, müssen Sie möglicherweise einige Optimierungen vornehmen, um die einzigartige Architektur von Snowflake voll auszunutzen. Snowflake bietet verschiedene Abfrageanalyse-Tools, die helfen können, Engpässe zu identifizieren und gezielt bestimmte Teile des Workflows zu optimieren.
Während der Optimierungsphase müssen Sie möglicherweise verschiedene Aspekte des Systems erneut berücksichtigen. Der Vorteil ist, dass Sie bereits von den Möglichkeiten von Snowflake profitieren und Optimierungsaufgaben Teil Ihrer regelmäßigen Wartungsarbeiten werden.
Es wird empfohlen, sich in der Migrationsphase nur auf die Behebung kritischer Performance-Probleme zu konzentrieren. Die Optimierung wird am besten nach der Migration durchgeführt.
Sie benötigen Unterstützung bei der Migration?¶
Für komplexe Migrationsszenarien, die Behandlung spezifischer funktionaler Unterschiede oder allgemeine Unterstützung bietet Snowflake spezielle Support-Kanäle an, wie zum Beispiel snowconvert-support@snowflake.com. Darüber hinaus kann die Nutzung der umfangreichen Migrationsressourcen von Snowflake – einschließlich Masterclasses, Webinaren und detaillierten Referenzhandbüchern speziell für Teradata-Migrationen – die Erfolgschancen der Migration erheblich steigern.
Eine erfolgreiche Migration der Datenplattform von Teradata hängt nicht nur vom Konvertierungstool selbst ab. Stattdessen basiert sie auf einer ganzheitlichen Strategie, die die Effizienz der Automatisierung (bereitgestellt durch SnowConvert AI), das kritische Urteilsvermögen und die Problemlösungsfähigkeiten menschlicher Experten (wie Datenarchitekten) sowie die umfassende Unterstützung und die Ressourcen des Zielplattform-Ökosystems (einschließlich der Snowflake-Dokumentation, Support-Services und Best Practices) integriert. Dies bedeutet, dass Unternehmen strategisch nicht nur in das Migrationstool investieren sollten, sondern auch in die Weiterbildung ihrer Teams in Snowflake-nativen Funktionen sowie in den Aufbau robuster Validierungsprozesse. Das übergeordnete Ziel besteht nicht nur darin, die Daten zu verschieben, sondern die gesamte Datenlandschaft zu modernisieren – hin zu einer widerstandsfähigeren, leistungsfähigeren und zukunftssicheren Cloud-Datenplattform.
Anhang¶
Anhang 1: Teradata-Datenbanken, die bei der Migration zu Snowflake ausgeschlossen werden sollen¶
Die folgende Liste von Datenbanken wird nur für Teradata benötigt und sollte nicht nach Snowflake migriert werden:
DBC Crashdumps Dbcmngr External_AP EXTUSER LockLogShredder QCD SQLJ Sys_Calendar |
SysAdmin SYSBAR SYSJDBC SYSLIB SYSSPATIAL SystemFE SYSUDTLIB SYSUIF TD_SERVER_DB |
TD_SYSFNLIB TD_SYSGPL TD_SYSXML TDPUSER TDQCD TDStats tdwm |
|---|
Anhang 2: Teradata-Datentypen zu Snowflake-Datentypen¶
Teradata-Spaltentyp |
Teradata-Datentyp |
Snowflake-Datentyp |
|---|---|---|
++ |
TD_ANYTYPE |
Der Datentyp TD_ANYTYPE wird in Snowflake nicht unterstützt. |
A1 |
ARRAY |
ARRAY |
AN |
ARRAY |
ARRAY |
AT |
TIME |
TIME |
BF |
BYTE |
BINARY |
BO |
BLOB |
Der Datentyp BLOB wird nicht direkt unterstützt, kann aber durch BINARY (begrenzt auf 8MB) ersetzt werden. |
BV |
VARBYTE |
BINARY |
CF |
CHAR |
VARCHAR |
CO |
CLOB |
Der Datentyp CLOB wird nicht direkt unterstützt, kann aber durch VARCHAR (begrenzt auf 16MB) ersetzt werden. |
CV |
VARCHAR |
VARCHAR |
D |
DECIMAL |
NUMBER |
DA |
DATE |
DATE |
DH |
INTERVAL DAY TO HOUR |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
DM |
INTERVAL DAY TO MINUTE |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
DS |
INTERVAL DAY TO SECOND |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
DT |
DATASET |
Der Datentyp DATASET wird in Snowflake nicht unterstützt. |
DY |
INTERVAL-DAY |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
F |
FLOAT |
FLOAT |
HM |
INTERVAL HOUR TO MINUTE |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
HR |
INTERVAL-HOUR |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
HS |
INTERVAL HOUR TO SECOND |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
I1 |
BYTEINT |
NUMBER |
I2 |
SMALLINT |
NUMBER |
I8 |
BIGINT |
NUMBER |
I |
INTEGER |
NUMBER |
JN |
JSON |
VARIANT |
LF |
CHAR |
Dieser Datentyp ist nur in DBC vorhanden und kann nicht nach Snowflake konvertiert werden. |
LV |
VARCHAR |
Dieser Datentyp ist nur in DBC vorhanden und kann nicht nach Snowflake konvertiert werden. |
MI |
INTERVAL-MINUTE |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
MO |
INTERVAL-MONTH |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
MS |
INTERVAL MINUTE TO SECOND |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
N |
NUMBER |
NUMBER |
PD |
PERIOD(DATE) |
Kann in VARCHAR oder auf zwei separate Daten aufgeteilt werden. |
PM |
PERIOD(TIMESTAMP WITH TIME ZONE) |
Kann in VARCHAR oder in zwei separate Zeitstempel (TIMESTAMP_TZ) aufgeteilt werden. |
PS |
PERIOD(TIMESTAMP) |
Kann in VARCHAR oder in zwei separate Zeitstempel (TIMESTAMP_NTZ) aufgeteilt werden. |
PT |
PERIOD(TIME) |
Kann in VARCHAR oder in zwei separate Zeiten aufgeteilt werden. |
PZ |
PERIOD(TIME WITH TIME ZONE) |
Kann in VARCHAR oder in zwei separate Zeiten aufgeteilt werden. WITH TIME ZONE wird für TIME jedoch nicht unterstützt. |
SC |
INTERVAL SECOND I |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
SZ |
TIMESTAMP WITH TIME ZONE |
TIMESTAMP_TZ |
TS |
TIMESTAMP |
TIMESTAMP_NTZ |
TZ |
TIME WITH TIME ZONE |
TIME WITH TIME ZONE wird nicht unterstützt, da TIME nur mit der sogenannten „Wall-Clock“-Zeit ohne Zeitzonenoffset gespeichert wird. |
UF |
CHAR |
Dieser Datentyp ist nur in DBC vorhanden und kann nicht nach Snowflake konvertiert werden. |
UT |
UDT |
Der Datentyp UDT wird in Snowflake nicht unterstützt. |
UV |
VARCHAR |
Dieser Datentyp ist nur in DBC vorhanden und kann nicht nach Snowflake konvertiert werden. |
XM |
XML |
VARIANT |
YM |
INTERVAL YEAR TO MONTH |
Die Datentypen INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |
YR |
INTERVAL-YEAR |
Die Datentypen YR INTERVAL YEAR INTERVAL werden in Snowflake nicht unterstützt, aber Datumsberechnungen können mit den Datumsvergleichsfunktionen durchgeführt werden (z. B DATEDIFF und DATEADD). |