TeradataからSnowflakeへの移行ガイド¶
Snowflake移行フレームワーク¶
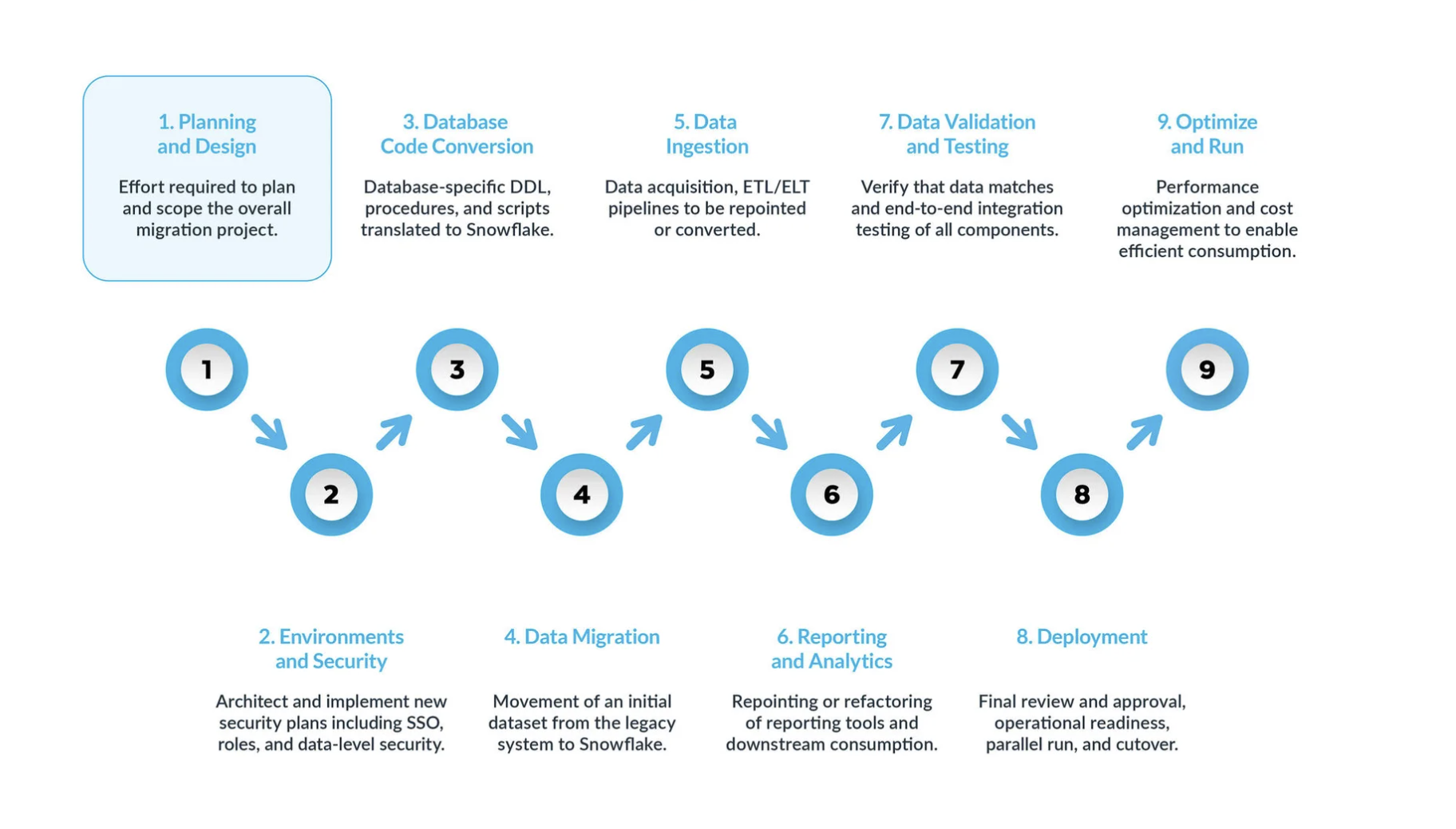
典型的なTeradataからSnowflakeへの移行は、5つの主要ステップに分けることができます。
計画と設計 は、移行プロセスにおいて見落とされがちなステップです。その主な理由は、企業は通常、プロジェクトの範囲を完全に理解していない場合であっても、進捗状況を迅速に示したいと考えるからです。だからこそ、このフェーズは移行プロジェクトを理解し、優先順位をつけるために非常に重要なのです。
環境とセキュリティ が、計画、明確なタイムライン、RACI マトリックス、すべての利害関係者の賛同とともに整ったら、いよいよ実行モードに移ります。 可動要素が多いことを考えると、移行を開始するために必要な環境とセキュリティ対策を設定することは、移行フェーズ開始前の非常に重要な工程です。また、移行を進める前にすべてのセットアップが完了していれば、移行プロジェクトへの影響はさらに大きくなります。
データベースコード変換 プロセスでは、テーブル定義、ビュー、ストアドプロシージャ、関数など、ソースシステムのデータベースカタログから直接コードを抽出します。いったん抽出したら、このコードをすべてSnowflakeの同等のデータ定義言語(DDLs)に移行します。このステップには、ビジネスアナリストがレポートやダッシュボードを作成するために使用するデータ操作言語(DML)スクリプトの移行も含まれます。 このコードをすべて移行し、Snowflakeで動くように調整する必要があります。その調整には、命名規則やデータ型のマッピングといった単純な変更から、構文やプラットフォームのセマンティクスなどのより複雑な違いの調整まで、さまざまなものがあります。これを支援するために、Snowflakeでは SnowConvert AI という強力なソリューションを提供し、データベースコード変換プロセスの大部分を自動化しています。
データ移行 には、異なるストレージシステム、フォーマット、またはコンピュータシステム間でデータを転送することが含まれます。TeradataからSnowflakeへの移行という文脈では、特にTeradata環境から新しいSnowflake環境にデータを移動することを指します。 このガイドでは、主に2つのタイプについて説明します。
履歴データ移行: 特定の時点でTeradataデータのスナップショットを取得し、Snowflakeに転送します。これは多くの場合、最初の一括転送として行われます。
増分データ移行: 最初に行った履歴データの移行後、継続的にTeradataからSnowflakeへ新規または変更データを移行します。これにより、Snowflake環境がソースシステムに対して常に最新の状態に保たれます。
データ取り込み: 履歴データを移行した後、次のステップはデータ取り込みプロセスを移行し、様々なソースからライブデータを取り込むことです。通常、このプロセスは、ビジネスユーザーがデータを利用できるようになる前に、いつ、どこでデータ変換が行われるかによって、抽出、変換、ロード(ETL)、または抽出、ロード、変換(ELT)モデルに従って行われます。
レポーティングとアナリティクス: データベースが履歴データと継続的に新しいデータをインポートするライブパイプラインの両方を備えた今、次のステップは BI を介してこのデータから値を抽出することです。レポーティングは、標準的な BI ツールまたはカスタムクエリを使用して行うことができます。どちらの場合も、データベースに送信される SQL は、Snowflakeの要件を満たすように調整する必要がある場合があります。このような調整には、単純な名前の変更(移行時によくある)から、構文やより複雑な意味の違いまで、さまざまなものがあります。これらすべてを特定し、対処する必要があります。
データの検証とテスト: このフェーズに入る前に、データを可能な限りクリーンにしておくことが目標です。 各組織には独自のテスト方法とデータを実稼働環境に移行するための要件があります。これらはプロジェクト開始当初から十分に理解されている必要があります。
デプロイ: このステージで、データが検証され、同等のシステムがセットアップされます。すべての ETLs が移行済みで、レポートは検証済みです。これで実稼働の準備は万全でしょうか。 焦ってはいけません。最終的に実稼働へと進める前に、まだいくつかの重要な検討事項があります。まず、従前のアプリケーションは複数のコンポーネントやサービスで構成されている可能性があります。理想的には、これらのアプリケーションを1つずつ移行し(並行移行も可能ですが)、同じ順番で実稼働環境に移行する必要があります。このプロセスでは、ビジネスユーザーがSnowflakeと従前のシステムの両方をクエリする必要がないように、ブリッジング戦略を確実に実施します。まだ移行されていないアプリケーションのデータ同期は、このブリッジングのメカニズムを通じて舞台裏で行われる必要があります。そうしなければ、ビジネスユーザーはハイブリッド環境で仕事をしなければならなくなり、このセットアップの意味を理解しておく必要が生じます。
最適化と実行: システムがSnowflakeに移行されると、通常のメンテナンスモードに入ります。すべてのソフトウェアシステムは、継続的なメンテナンスを必要とする生きた存在です。移行後のこのフェーズは、最適化と実行と呼ばれるもので、移行自体には含まれません。
移行フェーズ¶
フェーズ1計画と設計¶
このフェーズは、Snowflake移行を成功させるための重要な第一歩です。スコープ、目的、要件を定義することで、移行プロセス全体の土台を築きます。このフェーズでは、現在の環境を深く理解し、Snowflakeにおける将来の状態について明確なビジョンを描く必要があります。
このフェーズの間に、組織は以下のタスクを実行することで、Snowflakeに移行するための主要なビジネス推進要因と技術的目標を特定します。
Teradata環境の徹底的なアセスメントを実施する¶
現在の環境を徹底的に評価するためには、 既存のデータ資産の棚卸し から始めることが重要です。これには、データベースやファイルだけでなく、外部システムも含めて文書化し、データ型やスキーマ、データ品質に関する一般的な問題を注意深く記録する必要があります。同時に、頻繁に実行され、リソースを大量に消費するクエリを特定するためには、**クエリワークロード*の分析が不可欠です。これにより、データアクセスのパターンとユーザーの行動が明らかになります。最後に、 セキュリティとコンプライアンス要件 を評価することも譲れません。機密データ、規制上の義務、既存システム内の潜在的な脆弱性を特定する必要があります。
フェーズ2:環境とセキュリティ¶
私たちが推奨する最初のステップの1つは、移行を開始するために必要な環境とセキュリティ対策をセットアップすることです。可動要素は数多くありますが、まずはセキュリティから見ていきます。他のクラウドプラットフォームと同様に、Snowflakeはプラットフォームと管理者間での共有セキュリティモデルの下で運用されます。
¶
環境の設定¶
まず、必要なアカウントの数を決める必要があります。従前のプラットフォームでは、データベースインスタンスが一般的でしたが、Snowflakeではアカウントを中心にセットアップが行われます。最低でも、実稼働環境と開発環境をセットアップする必要があります。テスト戦略によっては、テストのステージごとに追加の環境が必要になることもあります。
セキュリティ対策¶
環境を整えたら、適切なセキュリティ対策を実施することが重要です。ネットワークポリシーから開始して、確実に VPN 内の承認済みユーザーのみがSnowflakeシステムにアクセスできるようにします。
Snowflakeのユーザーアクセス制御はロールベースであるため、管理者はビジネスニーズに応じてロールを定義する必要があります。ロールが定義されたら、ユーザーアカウントを作成し、すべてのユーザーに多要素認証(MFA)またはシングルサインオン(SSO)を強制します。さらに、サービスアカウントを設定し、これらのアカウントについて確実に従来のユーザー名とパスワードによる認証方式に頼らないようにする必要があります。
移行中のロール¶
移行中、移行自体を実行するユーザーの特定のロールも定義する必要があります。非実稼働環境でのロールは異なるかもしれませんが、移行中は実際のデータを扱うことになることを忘れないでください。たとえ非実稼働環境であっても、セキュリティの手を抜いてはいけません。
開発では、構造やコードへの変更をデプロイする際、移行チームの方が自由度が高いのが一般的です。これらはアクティブな開発環境であり、過度なセキュリティ制限で移行チームを妨害することは避けたいところです。しかし、非実稼働環境であっても、堅牢なセキュリティモデルを維持することが重要であることには変わりありません。
アクセスモデルの再考¶
Snowflakeのセキュリティモデルは多くのレガシープラットフォームとは異なるため、この移行はアクセスモデルを再考する良い機会となります。システムへのアクセスを必要とするユーザーの階層を整理し、必要なユーザーだけが特定のリソースにアクセスできるようにします。
財務との調整¶
Snowflakeは消費ベースの価格設定モデルを採用しており、コストは使用量に連動します。ロールを定義する際に、財務チームと連携して、どの部署がどのようにSnowflakeを使用しているかを追跡するのが賢明です。また、Snowflakeでは、データベースオブジェクトにタグを付けることができます。このタグを使用すると、ビジネスレベルでの所有権を追跡し、部門ごとのコスト配分と使用状況を一致させることができます。
セキュリティと環境設定は複雑な作業であり、前もって計画する必要があります。新しいプラットフォームが長期的に管理可能であることを保証するために、場合によってはアクセスモデルの再設計を検討する必要もあります。時間をかけて正しくセットアップすることで、Snowflakeへのセキュアで効率的な移行のための強固な基盤を築くことができます。
フェーズ3:データベースコード変換¶
SnowConvert AI は、Teradataのソースコードを理解し、ソースコード内のデータ定義言語(DDL)、データ操作言語(DML)、および関数を、ターゲットであるSnowflake内の対応する SQL に変換します。SnowConvert AI は、.sql、.dml、ddl の3つの拡張子のソースコードを移行できます。
このフェーズでは、テーブル定義、ビュー、ストアドプロシージャ、関数など、ソースシステムのデータベースカタログから直接コードを抽出します。抽出したら、このコードをすべてSnowflakeの同等の DDLs (データ定義言語)に移行します。このステップには、ビジネスアナリストがレポートやダッシュボードを作成するために使用するデータ操作言語(DML)スクリプトの移行も含まれます。
推奨される抽出スクリプトは こちら でご確認ください
Teradata DDL には通常、 プライマリインデックス 、 フォールバック 、 または パーティショニング への参照が含まれています。Snowflakeでは、これらの構造は同じようには存在しません。
SnowConvert AI for Teradata を使用する と、データ定義言語(DDL)の変換プロセスが大幅に合理化され、特に多数のテーブルを扱う場合に便利です。プライマリインデックス定義やフォールバックオプションなど、Teradata特有の DDL 構造をSnowflakeの同等の構造に自動変換します。この自動化によって手作業が減り、エラーのリスクが最小限に抑えられるため、チームはより高度な移行戦略と検証に集中できます。 基本的な DDL 変換だけでなく、SnowConvert AI はデータ型のマッピングやスキーマの再編成といったニュアンスにも対応しています。Snowflakeが提供するサービスに合わせてデータ型を自動的に調整し、最適なパフォーマンスと管理性を実現するためにスキーマを統合するか分解するかを容易に判断できるようにします。この包括的なアプローチにより確実に、移行されたデータベース構造は機能的であるだけでなく、Snowflakeのアーキテクチャに最適化されたものになります。
必要に応じてデータ型を調整するか、Migrations AI アシスタントを使用してエラーまたは警告(EWI)を修正します。
スキーマを再編成するかどうか(たとえば、大規模なモノリシックスキーマを複数のSnowflakeデータベースに分割するなど)を決定します。
Teradata移行に関する考慮事項¶
TeradataからSnowflakeにデータを移行する場合、データベース間の機能的な違いを考慮することが極めて重要です。
Teradataのセッションモード¶
Teradataデータベースには、クエリを実行するためのさまざまなモードがあります: ANSI モード(ANSI SQL:2011仕様に基づくルール)と TERA モード(Teradataが定義したルール)。詳細情報については、以下の Teradataドキュメント を参照してください。
文字列情報テーブルのTeradataモード
文字列の場合、Teradataモードは異なる動作をします。Teradataのドキュメント に基づき、以下のテーブルで説明されています。
機能 |
ANSI モード |
Teradataモード |
|---|---|---|
文字比較のデフォルト属性 |
CASESPECIFIC |
NOT に CASESPECIFIC |
デフォルトの TRIM 動作 |
TRIM(BOTH FROM) |
TRIM(BOTH FROM) |
翻訳仕様の概要
モード |
列の制約値 |
Teradataの動作 |
SC の期待される動作 |
|---|---|---|---|
ANSI モード |
CASESPECIFIC |
CASESPECIFIC |
制約は追加されない。 |
NOT に CASESPECIFIC |
CASESPECIFIC |
列定義に COLLATE 'en-cs' を追加する。 |
|
Teradataモード |
CASESPECIFIC |
CASESPECIFIC |
ほとんどの場合、COLLATE を追加せず、文字列比較の用法を RTRIM(式) に変換する。 |
NOT に CASESPECIFIC |
NOT に CASESPECIFIC |
ほとんどの場合、COLLATE を追加せず、文字列比較の用法をRTRIM(UPPER(式)) に変換する。 |
利用可能な翻訳仕様オプション
SQL変換リファレンス¶
TeradataからSnowflakeに移行する際に、変換されたコードがどのように見えるかを理解するためのガイドとして使用してください。SQL には、方言間での類似した構文がありますが、各方言は新しい機能を拡張または追加することができます。
このため、ある環境(Teradataなど)と別の環境(Snowflakeなど)で SQL を実行するとき、変換、さらには削除が必要となるステートメントが多くあります。これらの変換は SnowConvert AI によって行われます。
特定のトピックに関する詳細情報は、以下のページをご覧ください。
SQL から JavaScript(プロシージャ)¶
スクリプトからSnowflake SQL への翻訳リファレンス¶
TeradataスクリプトファイルをSnowflake SQL に変換するための翻訳リファレンス
スクリプトからPythonへの翻訳リファレンス¶
このセクションでは、SnowConvert AI が Teradata スクリプト(BTEQ、FastLoad、MultiLoad、TPUMP など)をSnowflakeと互換性のあるスクリプト言語に変換する方法について詳しく説明します。
特定のトピックに関する詳細情報は、以下のページをご覧ください。
フェーズ4:データ移行¶
まず、履歴データの移行と新しいデータの追加を区別することが重要です。履歴データの移行とは、特定の時点におけるデータのスナップショットを取得して、それをSnowflakeに転送することを指します。まず、Snowflakeに変換せずにデータの完全コピーを実行することが推奨されます。この初期コピーはレガシープラットフォームに負荷をかけるので、一度だけ行い、Snowflakeに保存しておくのが便利です。
行動可能なステップ:
履歴データの移行を実行する:特定の時点におけるTeradataデータのスナップショットを取得し、Snowflakeに転送します(最初の一括転送として行うことが多い)。最初は変換なしで完全コピーを行うことが推奨されます。
増分データの移行を計画する:最初の履歴移行後、Snowflake環境を最新の状態に保つため、継続的に新しいデータや変更されたデータをTeradataからSnowflakeに移行するプロセスを設定します。
フェーズ5:データの取り込み¶
Snowflakeへパイプラインを移行するには、BTEQ スクリプト、ストアドプロシージャ、マクロ、または特殊な ETL フローなど、Teradataベースのロジックを移動または書き換える必要があります。これには、BTEQ またはスケジュールされたTeradataジョブを、Snowflake内のストリームとタスクに置き換えることで増分の変換を行う、オーケストレーションの移行が含まれます。また、ソースとシンクの再編成により、Teradataに到着する複数のインバウンドデータソースをSnowflakeの取り込みパターン(COPY、Snowpipe)にリダイレクトすることも必要です。
クエリの変換と最適化のステージ中に、Teradata SQL はSnowflake SQL に変換されます。これには、マクロをストアドプロシージャやビューに置き換えること、QUALIFY ロジックを書き換えること、ストアドプロシージャや結合インデックスを調整することなどが含まれます。SnowConvert AI for Teradata では、この翻訳の大部分を自動化できます。
データそのものがSnowflakeにあるので、次は BTEQ スクリプト、ストアドプロシージャ、マクロ、または特殊な ETL フローなど、 Teradataベースのロジックの移行または書き換え に移ります。
オーケストレーションの移行¶
ネイティブSnowflake:増分の変換を行うために、BTEQ またはスケジュールされたTeradataジョブをSnowflake内の ストリームとタスク に置き換えます。
外部オーケストレーター:サードパーティのスケジューラ(Airflow、Control-Mなど)を使用していた場合は、それらの指定先をSnowflakeにし、埋め込みのTeradata SQL を書き換えます。
ソースとシンクの再編成¶
Teradataに複数のインバウンドデータソースがある場合、それらをSnowflake取り込みパターン(COPY 、Snowpipe)にリダイレクトします。
ダウンストリームシステムがTeradataから読み込んでいる場合は、パイプラインが安定してから、それらをSnowflakeに指定し直すことを計画します。
自動翻訳には SnowConvert AI for Teradata が推奨されます。マクロ、ストアドプロシージャ、BTEQ スクリプトを扱うことができ、Snowflake互換のコードを出力します。
フェーズ6:レポートと分析¶
履歴データと新しいデータを継続的にインポートするライブパイプラインの両方を備えたデータベースができたので、次のステップでは ビジネスインテリジェンス (BI)を通じてこのデータから価値を抽出します。レポーティングは、標準的な BI ツールまたはカスタムクエリを使用して行うことができます。どちらの場合も、データベースに送信される SQL は、Snowflakeの要件を満たすように調整する必要がある場合があります。このような調整には、単純な名前の変更(移行時によくある)から、構文の違いやより複雑な意味の違いまで、さまざまなものがあります。これらのすべてを特定し、対処する必要があります。
取り込みプロセスと同様に、レガシープラットフォームの使用状況をすべて精査し、その結果を移行計画に反映させることが極めて重要です。一般的に検討すべきレポートには、IT 部門が所有するレポートとビジネス部門が所有するレポートの2種類があります。通常、IT 部門が所有するレポートを追跡するのは簡単ですが、ビジネス部門が所有するレポートやビジネスユーザーが作成した複雑なクエリには、別のアプローチが必要です。
ビジネスユーザーは、移行プロセスにおける重要な利害関係者であり、計画段階で RACI マトリックス に含める必要があります。Snowflakeの操作方法についてトレーニングを受け、プラットフォームの違いを明確に理解する必要があります。これにより、必要に応じてカスタムクエリやレポートを変更することができるようになります。一般的には、ビジネスユーザー向けの並行トレーニングコースの後に、ユーザーがプラットフォームの違いに対応して必要な調整を行うための支援を行う移行の専門家との「相談時間」を設けることが推奨されます。
最終的に移行を「受け入れる」のはビジネスユーザーです。IT 視点から見れば技術的な移行は完了したかもしれませんが、ビジネスユーザーがこの移行に関与していない場合、ビジネス運営に不可欠な何千ものレポートに依存し続けている可能性があります。これらのレポートがSnowflakeで動作するように更新されなければ、ビジネスはレガシープラットフォームから完全に移行することはできません。
Teradata SQL にはSnowflakeにはない構造があり、その逆も然りです。主要な違いは次のとおりです。
マクロ:Snowflakeではサポートされていません。通常、ストアドプロシージャまたはビューで置き換えられます。
QUALIFY:Snowflakeは
QUALIFYを直接サポートしていません。サブクエリまたは外側の SELECT を使用してロジックを書き換えます。ストアドプロシージャ:Teradata SP とSnowflake SP の違い(SQL ベースか JavaScript ベースか)。手続き型言語が異なります。
結合インデックス直接的に相当するものはありません。マイクロパーティションのプルーニングとクラスタリングキーに頼ります。
COLLECT STATISTICS:Teradataは明示的な統計を使用しますが、Snowflakeはこれを自動的に行います。
自動翻訳には SnowConvert AI for Teradata が推奨されます。マクロ、ストアドプロシージャ、BTEQ スクリプトを扱うことができ、Snowflake互換のコードを出力します。
フェーズ7:データ検証とテスト¶
これで、移行計画プロセスにおいて過小評価されがちな2つのステップ、データの検証とテストに進めます。もちろん、この段階に入る前に、できるだけデータをクリーンにしておくことが目標です。
各組織には独自のテスト方法とデータを実稼働環境に移行するための要件があります。これらはプロジェクト開始当初から十分に理解されている必要があります。それでは、データ検証に有用な戦略を確認していきます。
Snowflake移行での包括的なテストを実施する: Snowflake移行プロセス中に、次のものを含む包括的なテストを実施する必要があります。
機能テスト:移行されたすべてのアプリケーションと機能が新しい環境内で期待通りに動作することを確認し、データの整合性と正確性を確保。
パフォーマンステスト:クエリのパフォーマンス、データのロード速度、システム全体の応答性を評価。これはパフォーマンスのボトルネックを特定して対処するのに役立ちます。
ユーザー受け入れテスト(UAT):テストプロセスにエンドユーザーを参加させ、移行されたシステムがエンドユーザーの要件を満たしていることを確認し、フィードバックを集めて改善の余地を確認。
Snowflake移行に関するトレーニングとドキュメントを提供する:
Snowflakeの特徴、機能、ベストプラクティスについてエンドユーザーに包括的なトレーニングを提供します。データアクセス、クエリの最適化、セキュリティなどのトピックを扱います。
システムアーキテクチャ図、データフロー図、操作手順、ユーザーガイド、トラブルシューティングガイド、FAQs などを含め、参照しやすい包括的なドキュメントを作成します。
フェーズ8:デプロイ¶
最終的にカットオーバーの準備ができたら、確実にすべての利害関係者が足並みを揃えて、この時点からレガシーシステムではなく Snowflake が記録システムになることを理解するようにします。作業を進める前に、すべての利害関係者から最終的かつ正式な承認を得る必要があります。移行されなかったレポートは、ここでビジネスユーザーの責任となります。最後の段階になってからユーザーを関与させるのではいけない理由はここにあります。 必要なのは、最初からプロセスに参加 させて、移行タイムラインを把握してもらうことです。
さらに、すべての権限が適切に付与されていることを確認します。たとえば、Active Directoryベースのロールを使用している場合、確実にSnowflakeでこれらのロールが作成および構成されているようにします。
通常、いくつかの追加シナリオが最後まで残されますが、見落としてはいけません。
代理キー:代理キーを使用する場合は、そのライフサイクルがレガシーシステムとSnowflakeシステムで異なる可能性があることに注意してください。これらのキーは、カットオーバー時に同期させる必要があります。
カットオーバーのタイミング業種によっては、1年の中でカットオーバーを実施するのに適した時期が多い場合も少ない場合もあります。タイミングは慎重に検討します。
レガシープラットフォームのライセンス:レガシープラットフォームのライセンスに関連して、厳しい期限に直面する可能性があることに注意してください。そのような期限がある場合は、必ずその期限に合わせてカットオーバーを計画してください。
フェーズ9:最適化と実行¶
システムがSnowflakeに移行されると、通常のメンテナンスモードに入ります。すべてのソフトウェアシステムは、継続的なメンテナンスを必要とする生きた存在です。移行後のこのフェーズを最適化と実行と呼んでいます。強調しておきますが、これは移行自体には含まれません。
最適化と継続的改善は、移行後に生じる継続的なプロセスです。この時点で、お客様のチームがSnowflakeのシステムを完全に所有することになります。システムは進化し続け、利用パターンによって最適化が進められます。
一般的に、Snowflakeのジョブは元のプラットフォームよりも高速に実行される傾向があることがわかっています。パフォーマンスが期待通りでない場合、Snowflakeの独自アーキテクチャを十分に活用するために、いくつかの最適化を実行する必要がある可能性があります。Snowflakeには、ボトルネックの特定に役立つさまざまなクエリ分析ツールが用意されており、ワークフローの特定の部分を最適化することができます。
最適化のフェーズでは、システムのさまざまな側面を見直す必要がある可能性があります。利点は、すでにSnowflakeの機能の恩恵を受けていることです。最適化タスクは定期的なメンテナンスルーチンの一部になります。
推奨事項として、移行フェーズでは、重要なパフォーマンス問題のみに対処することに重点を置く必要があります。最適化は移行後の取り組みとして扱うのがベストです。
移行のサポートが必要な場合¶
複雑な移行シナリオ、特定の機能差への対応、または一般的な支援について、Snowflakeは snowconvert-support@snowflake.com などの専用サポートチャネルを用意しています。さらに、Teradate移行に特化したマスタークラス、ウェビナー、詳細なリファレンスガイドなど、Snowflakeの広範な移行リソースを活用することで、移行成功の可能性を大幅に高めることができます。
Teradataからのデータプラットフォーム移行の成功は、変換ツール自体だけに依存するものではありません。そうではなく、自動化の効率性(SnowConvert AI による)、人間の専門家(データアーキテクトなど)の重要な判断と問題解決の能力、ターゲットプラットフォームのエコシステムが提供する包括的なサポートとリソース(Snowflakeのドキュメント、サポートサービス、ベストプラクティスなど)を統合する全体的な戦略にかかっています。このことから、組織は移行ツールだけでなく、Snowflakeネイティブ機能に関するチームのスキルアップや、強固な検証プロセスの確立にも戦略的に投資する必要があります。最終的な目標は、単にデータを 移動 させることではなく、データ運用全体を モダナイズ し、より弾力性があり、パフォーマンスが高く、将来に対応可能なクラウドデータプラットフォームを実現することです。
付録¶
付録1:Snowflakeへの移行時に除外するTeradataデータベース¶
以下にリストするデータベースはTeradataのみに必要なもので、Snowflakeに移行する必要はありません。
DBC Crashdumps Dbcmngr External_AP EXTUSER LockLogShredder QCD SQLJ Sys_Calendar |
SysAdmin SYSBAR SYSJDBC SYSLIB SYSSPATIAL SystemFE SYSUDTLIB SYSUIF TD_SERVER_DB |
TD_SYSFNLIB TD_SYSGPL TD_SYSXML TDPUSER TDQCD TDStats tdwm |
|---|
付録2:TeradataとSnowflakeのデータ型の対応¶
Teradata列タイプ |
Teradataデータ型 |
Snowflakeデータ型 |
|---|---|---|
++ |
TD_ANYTYPE |
TD_ANYTYPE データ型はSnowflakeではサポート対象外。 |
A1 |
ARRAY |
ARRAY |
AN |
ARRAY |
ARRAY |
AT |
TIME |
TIME |
BF |
BYTE |
BINARY |
BO |
BLOB |
BLOB データ型は直接はサポートされていない、BINARY で置き換えられる(8MB に制限)。 |
BV |
VARBYTE |
BINARY |
CF |
CHAR |
VARCHAR |
CO |
CLOB |
CLOB データ型は直接はサポートされていない、VARCHAR で置き換えられる(16MB に制限)。 |
CV |
VARCHAR |
VARCHAR |
D |
DECIMAL |
NUMBER |
DA |
DATE |
DATE |
DH |
INTERVAL DAY TO HOUR |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる |
DM |
INTERVAL DAY TO MINUTE |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる |
DS |
INTERVAL DAY TO SECOND |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる。 |
DT |
DATASET |
DATASET データ型はSnowflakeではサポート対象外。 |
DY |
INTERVAL に DAY |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる。 |
F |
FLOAT |
FLOAT |
HM |
INTERVAL HOUR TO MINUTE |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる。 |
HR |
INTERVAL に HOUR |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる。 |
HS |
INTERVAL HOUR TO SECOND |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる。 |
I1 |
BYTEINT |
NUMBER |
I2 |
SMALLINT |
NUMBER |
I8 |
BIGINT |
NUMBER |
I |
INTEGER |
NUMBER |
JN |
JSON |
VARIANT |
LF |
CHAR |
このデータ型は DBC のみで、Snowflakeには変換できない。 |
LV |
VARCHAR |
このデータ型は DBC のみで、Snowflakeには変換できない。 |
MI |
INTERVAL に MINUTE |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる。 |
MO |
INTERVAL に MONTH |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる |
MS |
INTERVAL MINUTE TO SECOND |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる。 |
N |
NUMBER |
NUMBER |
PD |
PERIOD(DATE) |
VARCHAR に変換するか、2つの別々の日付に分割できる。 |
PM |
PERIOD(TIMESTAMP WITH TIME ZONE) |
VARCHAR に変換することも、2つのタイムスタンプ(TIMESTAMP_TZ)に分割することもできる。 |
PS |
PERIOD(TIMESTAMP) |
VARCHAR に変換することも、2つのタイムスタンプ(TIMESTAMP_NTZ)に分割することもできる。 |
PT |
PERIOD(TIME) |
VARCHAR に変換することも、2つの時間に分割することもできる。 |
PZ |
PERIOD(TIME WITH TIME ZONE) |
VARCHAR に変換することも、2つの時間に分けることもできるが、WITH TIME ZONE は TIME について非対応。 |
SC |
INTERVAL SECOND I |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる。 |
SZ |
TIMESTAMP WITH TIME ZONE |
TIMESTAMP_TZ |
TS |
TIMESTAMP |
TIMESTAMP_NTZ |
TZ |
TIME WITH TIME ZONE |
TIME WITH TIME ZONE は、TIME がタイムゾーンオフセットがない「壁掛け時計」の時間のみを使用して保存されるためサポート対象外。 |
UF |
CHAR |
このデータ型は DBC のみで、Snowflakeには変換できない。 |
UT |
UDT |
UDT データ型はSnowflakeではサポート対象外。 |
UV |
VARCHAR |
このデータ型は DBC のみであり、Snowflakeには変換できない。 |
XM |
XML |
VARIANT |
YM |
INTERVAL YEAR TO MONTH |
INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる |
YR |
INTERVAL に YEAR |
YR INTERVAL YEAR INTERVAL データ型はSnowflakeではサポートされていないが、日付比較関数(例: DATEDIFF および DATEADD など)で日付の計算はできる。 |