클린룸에 사용자 지정 템플릿 추가¶
공급자와 컨슈머 모두 클린룸에 사용자 지정 템플릿을 추가할 수 있습니다. 사용자 지정 템플릿은 Snowflake에서 제공하는 템플릿과 동일한 방식으로 실행됩니다.
참고
클린룸 템플릿은 유효한 JinjaSQL 템플릿입니다. 클린룸 템플릿을 직접 만들기 전에 사용자 지정 템플릿에 대한 클린룸 참조 가이드 를 읽어보세요.
공급자가 작성한 사용자 지정 템플릿¶
공급자는 컨슈머 승인 없이 클린룸에 사용자 지정 템플릿을 추가할 수 있습니다. 컨슈머는 공급자가 작성한 템플릿을 승인 없이 실행할 수 있습니다. 다음 섹션에서는 공급자가 사용자 지정 템플릿을 추가하고 컨슈머가 API를 사용하여 해당 템플릿을 실행하는 방법을 설명합니다.
컨슈머가 클린룸 UI에서 실행할 수 있는 템플릿을 공급자가 설계하려는 경우 템플릿에 대해 사용자 입력 양식을 만들어야 합니다 .
공급자 작성 템플릿 추가¶
공급자는 provider.add_custom_sql_template 을 호출하고 템플릿 JinjaSQL 을 문자열로 전달하여 한 번에 하나씩 사용자 지정 템플릿을 추가합니다. 사용자 지정 템플릿은 클린룸의 템플릿 목록에 표시되며 Snowflake에서 제공하는 템플릿과 동일하게 동작합니다. 클린룸에는 사용자 지정 템플릿과 Snowflake에서 제공하는 템플릿을 함께 포함할 수 있습니다.
템플릿이 호출할 사용자 지정 Python UDFs 를 업로드할 수도 있습니다.
팁
컨슈머가 사용할 사용자 지정 템플릿을 추가할 때 템플릿이 수행하는 작업과 템플릿에서 사용하는 필수 인자 및 선택적 인자를 설명하는 설명서를 제공해야 합니다.
다음 예제에서는 공급자가 클린룸에 사용자 지정 템플릿을 추가하는 방법을 보여줍니다.
CALL samooha_by_snowflake_local_db.provider.add_custom_sql_template(
$cleanroom_name,
$basic_template_name,
$$
SELECT
COUNT(*) AS total_count
FROM IDENTIFIER({{ my_table[0] }}) AS c
INNER JOIN IDENTIFIER({{ source_table[0] }}) AS p
ON IDENTIFIER({{ consumer_id | join_policy }}) = IDENTIFIER({{ provider_id | join_policy }})
{% if where_clause %}
WHERE {{ where_clause | sqlsafe }}
{% endif %};
$$
);
이전 예제를 포함한 대부분의 템플릿에서 열 이름 충돌을 방지하려면 열 이름을 테이블 이름으로 정규화해야 합니다. 테이블 이름 접두사를 접두사의 열 이름에 연결하고 유효한 식별자를 가져오는 것은 쉽지 않기 때문입니다( IDENTIFIER(p.{{col_name | sqlsafe }}) 는 오류임). 따라서 호출자가 열 이름뿐만 아니라 정규화된 테이블 이름을 제공해야 할 수도 있습니다. 테이블 이름은 승인된 p 및 c 별칭을 사용해야 합니다.
공급자가 작성한 템플릿 실행¶
클린룸 API 사용 시 컨슈머는 ``consumer.run_analysis``를 호출하여 템플릿을 실행하고, 공급자는 ``provider.submit_analysis_request``를 호출하여 공급자 실행 분석 을 수행합니다.
클린룸 UI에서 템플릿을 실행할 수 있도록 하려면, 공급자는 템플릿에 대한 사용자 입력 양식을 만들어야 합니다. 공급자가 작성한 템플릿만 클린룸 UI에서 실행할 수 있습니다.
공급자가 템플릿을 난독 처리 한 경우가 아니면, 클린룸 공동 작업자는 consumer.view_template_definition 을 호출하여 클린룸의 모든 템플릿에 대해 JinjaSQL을 볼 수 있습니다. 공급자가 작성한 템플릿만 난독 처리할 수 있습니다.
consumer.get_arguments_from_template 을 호출하여 템플릿에 사용된 변수를 구문 분석하고 나열할 수 있습니다. 그러나 크거나 복잡한 템플릿의 경우, 이 프로시저를 실행할 때 모든 템플릿 변수가 나열되지는 않을 수 있으므로 템플릿 사용자에게 유용한 설명서를 제공해야 합니다.
다음 예제에서는 이전에 표시된 공급자의 사용자 지정 템플릿을 컨슈머가 실행하는 방법을 보여줍니다.
CALL samooha_by_snowflake_local_db.consumer.run_analysis(
$cleanroom_name,
'basic_template',
['SAMOOHA_SAMPLE_DATABASE.DEMO.CUSTOMERS'], -- Populates the my_table array.
['SAMOOHA_SAMPLE_DATABASE.DEMO.CUSTOMERS'], -- Populates the source_table array.
OBJECT_CONSTRUCT(
'consumer_id', 'c.hashed_email', -- hashed_email column from the consumer's table.
'provider_id', 'p.hashed_email', -- hashed_email column from the provider's table.
'where_clause','c.status = $$MEMBER$$ AND c.age_band > 30' -- $$...$$ is used to stringify the column value.
)
);
공급자 템플릿 예제 코드¶
다음은 공급자가 사용자 지정 템플릿을 추가하는 방법과 컨슈머가 템플릿을 실행하는 방법을 보여주는 전체 코드 예제입니다. 이 코드를 실행하려면 클린룸 API가 설치된 두 개의 별도 계정이 필요합니다. 한 계정은 공급자 역할을 하고 다른 계정은 컨슈머 역할을 합니다.
컨슈머가 작성한 사용자 지정 템플릿¶
공급자가 승인하는 경우 컨슈머는 클린룸에 사용자 지정 템플릿을 추가할 수 있습니다. 클린룸에 추가되면 컨슈머가 작성한 템플릿을 공급자가 작성한 템플릿과 동일하게 실행할 수 있습니다. 컨슈머가 사용자 지정 템플릿을 추가하는 방법은 다음과 같습니다.
공급자가 표준 방식으로 클린룸을 생성, 공유 및 게시합니다.
컨슈머가 표준 방식으로 클린룸을 설치하고 구성합니다.
컨슈머가
consumer.create_template_request를 호출하고 사용자 지정 템플릿 문자열을 전달합니다.공급자가
provider.list_pending_template_requests를 호출하여 보류 중인 요청을 확인합니다.공급자는 자체 템플릿을 실행하려는 컨슈머의 요청을 승인(
provider.approve_template_request) 또는 거부(provider.reject_template_request)할 수 있습니다. (여러 요청을 승인하거나 거부하기 위한 이러한 메서드의 대량 버전도 있습니다.) 공급자가 승인하면 템플릿이 클린룸에 즉시 추가됩니다.공급자는 템플릿을 승인하는 경우 해당 템플릿과 해당 데이터에 대한 필요한 조인 및 열 정책을 추가해야 합니다. 공급자의 클린룸에 조인 또는 열 정책이 없는 경우 기본적으로 공급자의 모든 열을 조인 및 프로젝션할 수 있습니다.
컨슈머는
consumer.list_template_requests(설명 및 거부 상태를 포함하는 상태 표시) 또는consumer.view_added_templates(템플릿이 클린룸에 추가되었는지 확인)를 호출하여 요청의 상태를 확인합니다.컨슈머는 선택적으로 템플릿에 대한 열 정책을 추가합니다.
컨슈머는 표준 방식으로
consumer.run_analysis를 호출하여 템플릿을 실행합니다.
참고
공급자는 컨슈머가 권한을 부여 하는 경우 컨슈머가 추가한 템플릿을 실행할 수 있습니다.
컨슈머 템플릿 예제¶
다음은 컨슈머가 사용자 지정 템플릿을 제출하고 실행하는 방법을 보여주는 전체 코드 예제입니다. 다음 통합 문서 파일을 Snowflake 계정에 업로드합니다. 이 코드를 실행하려면 클린룸 API가 설치된 두 개의 별도 계정이 필요합니다. 한 계정은 공급자 역할을 하고 다른 계정은 컨슈머 역할을 합니다.
사용자 지정 템플릿에 대한 사용자 입력 양식 정의¶
클린룸 UI에서 사용자 지정 템플릿을 실행하려면 공급자는 템플릿에 대한 입력 양식을 정의해야 합니다. 이 요구 사항은 템플릿에 컨슈머가 설정할 인자가 없는 경우에도 적용됩니다. 컨슈머는 템플릿에 대한 사용자 입력 양식을 정의할 수 없습니다.
중요
provider.restrict_table_options_to_consumers 또는 provider.restrict_template_options_to_consumers 를 사용하여 테이블이나 템플릿을 특정 사용자로 제한한 경우 이러한 제한은 클린룸 UI에서 예상대로 작동하지 않습니다. 이러한 제한이 있는 클린룸에서는 UI 사용을 위해 템플릿을 활성화하면 안 됩니다.
구성 양식을 통해 클린룸 UI 사용자는 API를 사용할 때 템플릿에 값을 전달하는 방법과 유사하게 사용자 지정 템플릿에 값을 전달할 수 있습니다.
다음 예제에서는 3개의 변수 max_age, favorite_color 및 source_table 을 사용하는 사용자 지정 템플릿을 보여줍니다.
CALL samooha_by_snowflake_local_db.provider.add_custom_sql_template(
$cleanroom_name,
'color_picker_template',
$$
SELECT p.hashed_email
FROM source_table[0] AS p
WHERE
p.age <= {{ max_age }} AND
UPPER(p.favorite_color) = UPPER({{ favorite_color }});
$$);
다음 예제의 코드에서는 이전 사용자 지정 템플릿을 실행할 때 템플릿 변수를 전달하는 방법을 보여줍니다.
CALL samooha_by_snowflake_local_db.consumer.run_analysis(
$cleanroom_name,
'color_picker_template',
[], -- Consumer tables, assigned to my_table array.
['MYDB.MYSCH.COLOR_PREFERENCES'], -- Provider tables, assigned to source_table array.
object_construct(
'max_age', 30, -- Assign max_age.
'favorite_color', 'blue' -- Assign favorite_color.
)
);
클린룸 UI에서 이 템플릿을 실행하려면 컨슈머가 이러한 템플릿 변수를 할당하는 양식을 정의해야 합니다. 다음 예제에서는 컨슈머가 max_age, favorite_color 및 source_table 에 값을 할당할 수 있는 간단한 양식을 정의하는 방법을 보여줍니다.
CALL samooha_by_snowflake_local_db.provider.add_ui_form_customizations(
$cleanroom_name,
'color_picker_template',
{ -- Top-level template settings.
'display_name': 'Color matcher',
'description': 'See which users like the same color as you',
'methodology': 'Choose a color and a max age',
'render_table_dropdowns': {
'render_consumer_table_dropdown': false,
'render_provider_table_dropdown': true -- Show a dropdown of provider tables.
} -- Chosen value is assigned to source_table.
},
{ -- Form entry elements, one per template argument.
'max_age': {
'type': 'integer',
'display_name': 'Maximum age',
'description': 'Matching user must be less than or equal to this value.',
'required': TRUE
},
'favorite_color': {
'type': 'dropdown',
'display_name': 'Favorite color',
'description': 'Choose the favorite color to match.',
'choices': ['Red', 'Blue', 'Green', 'Yellow'],
'required': TRUE
}
},
{} -- Output config not used in this example.
);
-- You must always call this procedure to propagate UI changes.
CALL samooha_by_snowflake_local_db.provider.create_or_update_cleanroom_listing(
$cleanroom_name);
컨슈머가 Configure Analysis & Query 단계에서 템플릿을 실행할 때 이전에 정의된 양식이 클린룸 UI에 나타납니다. 이 양식에는 다음 이미지와 같이 Collaborator table 레이블이 지정된 source_table 에 대한 테이블 선택기, Maximum age 레이블이 지정된 max_age 에 대한 정수 선택기 요소, Favorite color 레이블이 지정된 favorite_color 에 대한 색상 이름 드롭다운 메뉴가 포함되어 있습니다.
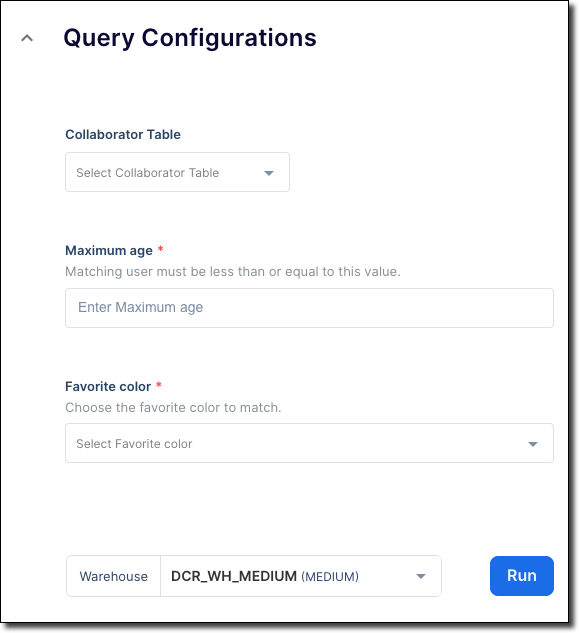
공급자 또는 컨슈머의 조인 정책, 열 정책, 테이블 등의 열로 미리 채워진 드롭다운 메뉴를 정의할 수도 있습니다. 양식 요소 유형에 대한 자세한 내용은 add_ui_form_customizations 섹션을 참조하세요.
source_table 및 my_table 채우기¶
표준 source_table 및 my_table 템플릿 변수는 다음과 같이 채울 수 있습니다.
기본 테이블 선택기 드롭다운 메뉴 활성화: 이러한 드롭다운 메뉴는 단일 선택입니다.
render_provider_table_dropdown및render_consumer_table_dropdown설정을 사용하여 표시하거나 숨길 수 있습니다. 이 드롭다운 메뉴는 정규화된 테이블 이름을source_table및my_table템플릿 변수에 각각 전달합니다.
열 이름 정규화¶
대부분의 템플릿에서는 열 이름의 모호성을 방지하기 위해 모든 열 이름을 정규화해야 합니다.
템플릿은 공급자 테이블인지 컨슈머 테이블인지에 따라 모든 테이블의 별칭을 p 또는 c 로 지정해야 합니다. 템플릿은 p 또는 c 별칭을 사용하여 모든 열을 참조해야 합니다. 별칭 지정에 대해 자세히 알아보세요.
드롭다운 열 선택기를 만드는 경우 드롭다운 메뉴의 choices 배열에 p 또는 c 테이블을 명시적으로 제공하거나 템플릿에 별칭을 추가해야 합니다.
다음 예제에서는 드롭다운 메뉴에 테이블 별칭을 제공하는 방법을 보여줍니다.
'provider_join_col': {
'display_name': 'Provider Join Column',
'choices': ['p.HASHED_EMAIL', 'p.HASHED_SSN'],
'type': 'dropdown',
'description': 'Select the provider column to join users on.',
'infoMessage': 'We recommend using HASHED_EMAIL.',
'size': 'M',
'group': 'Enable Provider Features'
}
그러나 이 방법은 모든 열 이름을 미리 알고 있어야 한다는 점에서 한계가 있습니다.
또는 references 속성을 제공하여 열 드롭다운 메뉴를 동적으로 채울 수 있습니다. 그러나 이러한 선택기는 p.hashed_email 등의 정규화된 열 이름이 아닌 hashed_email 등의 순수한 열 이름을 반환합니다. 순수한 열 이름이 반환되는 경우 명시적으로 템플릿에 열 범위를 테이블로 만들어야 합니다. 예를 들어, 다음 코드는 사용자가 공급자의 조인 정책에서 열을 선택할 수 있는 드롭다운 메뉴를 만듭니다.
'p_join_col': { 'type': 'dropdown', 'references': ['PROVIDER_JOIN_POLICY'] }
템플릿에서 열 이름을 사용하려면 다음 예제와 같이 열 이름 앞에 테이블 별칭을 하드 코딩해야 합니다.
SELECT p.{{ p_join_col | sqlsafe }} FROM table_col AS p;
클린룸 UI에서 실행할 수 있는 템플릿 개발을 위한 권장 사항¶
다음 단계는 클린룸 UI에서 실행할 수 있는 템플릿을 개발하기 위한 권장 워크플로를 보여줍니다.
1. 템플릿 개발¶
먼저 공급자 및 컨슈머 계정 모두에서 클린룸 API만 사용하여 템플릿과 템플릿이 호출하는 스크립트 를 개발합니다. API에서 템플릿 테스트하는 것은 UI를 사용하는 것보다 훨씬 더 빠르고 오류 발생 가능성도 낮습니다.
공급자 측과 컨슈머 측 모두, API에서 템플릿을 철저히 테스트하여 템플릿이 원하는 작업을 정확히 수행하는지 확인합니다. API에서 테스트하는 것은 매우 빠르고 변경 사항은 컨슈머 계정에 즉시 전파됩니다.
템플릿을 테스트하고 원하는 대로 정확히 실행되면 입력 양식 디자인을 계속 진행합니다.
2. 입력 양식 개발¶
템플릿과 업로드된 스크립트가 의도한 대로 작동하면 입력 양식에서 작업을 시작합니다. 이 스테이지에서는 공급자 계정에서는 API를, 컨슈머 계정에서는 UI를 사용합니다.
API를 사용하여 변경할 때 UI의 일부 값은 즉시 새로 고쳐지고, 일부는 사용자가 Refresh 를 클릭하면 새로 고쳐집니다. 그리고 일부는 10분마다 새로 고쳐집니다. 따라서 입력 양식에서 작업할 때 공급자 측에서는 API를 사용하여 양식을 만들고 업데이트하지만 컨슈머 계정에서는 API가 아닌 클린룸 UI를 사용하여 클린룸을 설치하고 구성합니다. 이를 통해 클린룸 UI에서 최신 데이터를 사용할 수 있습니다.
또한 API에서 입력 양식을 변경할 때마다 최신 클린룸 데이터를 사용할 수 있도록 새 클린룸을 만듭니다. 이름에 증분하는 숫자를 사용합니다(예: “My cleanroom 1”, “My cleanroom 2” 등). 그런 다음, UI를 사용하여 클라이언트에 클린룸을 설치합니다. 마지막으로, 계정이 보유할 수 있는 클린룸의 수가 제한되어 있으므로 이전 클린룸을 삭제합니다.
입력 양식을 템플릿에 첨부해야 합니다. 그렇지 않으면 클린룸과 양식을 클린룸 UI에서 실행할 수 없습니다. 양식을 개발할 때 어떤 값이 템플릿으로 전송되는지 확인할 수 있도록, 양식에서 선택한 모든 값을 단순히 미러링하는 템플릿을 사용하는 것이 좋습니다.
예를 들어 프로덕션 템플릿이 다음 템플릿과 같다고 가정해 보겠습니다.
SELECT {{ col1 | sqlsafe | column_policy }}, {{ col2 | sqlsafe | column_policy }}
FROM IDENTIFIER({{ source_table[0] }}) AS p
JOIN IDENTIFIER({{ my_table[0] }}) AS c
해당 프로덕션 템플릿의 모든 값을 미러링하는 다음과 같은 템플릿을 만들 수 있습니다.
SELECT
{{ col1 | default('Undefined')}},
{{ col2 | default('Undefined') }},
{{ source_table[0] | default('Undefined') }},
{{ my_table[0] | default('Undefined') }},
{{ provider_join_col | default('Undefined') }},
{{ consumer_join_col | default('Undefined') }}
;
그런 다음, 6개의 변수 값을 설정하는 양식을 디자인하고, 프로덕션 템플릿이 아닌 미러 템플릿에 양식을 첨부합니다.
입력 양식 개발을 위한 일반 팁
다음 목록은 효과적인 입력 양식을 개발하는 데 도움이 되는 자세한 팁을 제공합니다.
UI에서 클린룸을 설치, 구성 또는 실행할 때 일반적인 “설치 실패” 또는 “문제가 발생했습니다” 메시지가 표시되는 경우 이 메시지는 UI 양식 또는 관련 템플릿을 추가할 때는 확인되지 않았던 오류가 발생했음을 의미할 수 있습니다.
한 필드가 다른 필드에 종속되는 경우(예: 테이블 드롭다운 메뉴에서 선택한 값을 기준으로 하는 열 드롭다운 메뉴) 사용자가 하위 필드를 채우기 전에 상위 필드를 채우도록 가능하면 상위 필드를 하위 필드 바로 위에 배치합니다. 종속 필드를 사용하면 상위 필드에 대한 값을 선택할 때까지 하위 드롭다운 메뉴는 비어 있습니다.
order또는group값을 지정하지 않으면 항목은 정의된 순서대로 렌더링됩니다.정보용
infoMessage및description텍스트를 포함하고, 사용자가 입력할 수 있는 예제 값을 표시합니다.변수 데이터 타입에 대한 정확한 요소 유형을 선택합니다. 예를 들어, 정수의 경우 자유 형식 텍스트 상자가 아닌
integer를 선택합니다. 템플릿은 Jinja 필터를 사용하여 값을 캐스팅할 수 있습니다(예:SELECT {{ max_age | int }};).사용자 지정 템플릿에 대한 최소 구성 양식을 정의하지 않으면 클린룸 UI에서 템플릿을 실행할 수 없습니다.
템플릿에서 변수에 대한 양식 요소를 정의하지 않으면 사용자 양식에서 해당 변수에 대한 일반 텍스트 상자가 렌더링됩니다. 텍스트 상자에는 템플릿 변수 이름으로 레이블이 지정되어 있고 설명이나 제안 사항이 없으므로 원하는 결과가 아닐 수 있습니다.
``add_ui_form_customizations``에 지정된 양식 요소는 요소와 이름이 같은 일치하는 템플릿 변수가 없는 경우에는 렌더링되지 않습니다.
API에서 수행된 템플릿 변경 사항은 빠르고 안정적으로 UI에 전파되므로 템플릿 변경을 위한 새로운 클린룸을 만들 필요가 없습니다. 그러나 UI 스테이지에 도달하기
전에API에서 템플릿을 개발하고 테스트해야 합니다.주어진 테이블의 열 값으로 드롭다운 메뉴를 자동으로 채울 수 없습니다. 드롭다운 메뉴에서 값을 하드 코딩할 수 있지만, 런타임에 테이블의 값을 표시할 수는 없습니다.
3. 입력 양식을 프로덕션 템플릿에 연결¶
양식이 원하는 대로 정확히 설정되고 사용자가 모든 템플릿 변수에 액세스할 수 있도록 했다면, 작업 중인 템플릿을 provider.add_ui_form_customizations 호출의 입력 양식에 할당합니다.