Add custom templates to a clean room¶
End-of-life notice
The legacy Provider and Consumer Data Clean Rooms are being discontinued. Migrate to the Collaboration API using the migration tool before the dates below.
- 2026-10-01: New legacy clean rooms may not be created via the web application user interface.
- 2027-02-01: The web application user interface will no longer be accessible, and new legacy clean rooms may not be created via the Provider and Consumer API.
- 2027-06-01: Legacy Provider and Consumer clean rooms will no longer be accessible. Use the Collaboration API to create and manage clean rooms.
Both providers and consumers can add custom templates to a clean room. Custom templates are run the same way as Snowflake-provided templates. Custom templates are created using the API, and are run using the API or (if designed for it) the UI.
A clean room template is a valid JinjaSQL template. You should read the clean room reference guide for custom templates before trying to create your own clean room templates.
Provider-written custom templates¶
Providers can add a custom template to a clean room without consumer approval. Consumers can run a provider-written template without approval. The next sections describe how a provider can add a custom template, and a consumer run that template, using the API.
If the provider wants to design a template that a consumer can run in the clean rooms UI, they must create a user input form for the template.
Add a provider-written template¶
Providers add custom templates one at a time by calling provider.add_custom_sql_template, passing in the template JinjaSQL as a string.
Custom templates appear in the clean room’s template list, and behave the same as Snowflake-provided templates. A clean room can contain
any mix of custom and Snowflake-provided templates.
You can also upload custom Python UDFs for your template to call.
Tip
When you add a custom template for consumers to use, you should provide documentation that describes what the template does, and the required and optional arguments used by the template.
The following SQL example shows how a provider adds a simple custom template to a clean room:
This template takes four required parameters (my_table array, source_table array, consumer_id column name, and provider_id
column name) and an optional where_clause parameter that specifies a WHERE clause.
In most templates, including the previous example, column names provided by the user must be fully qualified with the table name to avoid column name conflicts. This is because it is not easy to concatenate a table name prefix to a column name in the prefix and get a valid identifier (IDENTIFIER(p.{{ col_name | sqlsafe }}) is an error). Therefore, you might need the caller to provide a fully qualified table name rather than just a column name. Table names should use the approved lowercases p and c aliases.
Run a provider-written template¶
When using the clean rooms API, consumers call consumer.run_analysis to run a template, and providers call
provider.submit_analysis_request for provider-run analyses.
If you want a template to be runnable in the clean rooms UI, the provider must create a user input form for the template. Only provider-written templates can be run in the clean rooms UI.
Clean room collaborators can see the JinjaSQL for any template in a clean room by calling consumer.view_template_definition, unless
the provider obfuscated the template. Only provider-written templates can be obfuscated.
You can call consumer.get_arguments_from_template to parse and list the variables used in a template. However, for large or complex
templates this procedure might not list all template variables, so be sure to provide helpful documentation for your template users.
The following example shows how a consumer runs the provider’s custom template shown previously:
Provider template example code¶
Here is a full code example showing how a provider adds a custom template, and how the consumer runs it. You need two separate accounts with the clean rooms API installed to run the code; one account to act as the provider and the other account to act as the consumer.
Consumer-written custom templates¶
A consumer can add a custom template to the clean room if the provider approves. Once added to the clean room, the consumer-written template can be run the same as a provider-written template. Here is how a consumer adds a custom template:
-
The provider creates, shares, and publishes a clean room in the standard way.
-
The consumer installs and configures the clean room in the standard way.
-
The consumer calls
consumer.create_template_requestand passes in the custom template string. -
The provider calls
provider.list_pending_template_requeststo see pending requests. -
The provider can approve (
provider.approve_template_request) or reject (provider.reject_template_request) the consumer’s request to run their own template. (There are also bulk versions of these methods for approving or rejecting multiple requests.) If the provider approves the template, the template is added to the clean room immediately.- Before the provider approves the template, the provider should first declare any necessary join and column policies on their data.
-
The consumer checks the status of their request by calling either
consumer.list_template_requests(which shows the approval status) orconsumer.view_added_templates(to see if their template was added to the clean room). A template is added to the clean room only after the provider approves it. -
The consumer runs the template by calling
consumer.run_analysisin the standard way.
Note
A provider can run a template added by a consumer if the consumer grants permission.
Consumer template example¶
Here is a full code example showing how a consumer can submit and run a custom template. Upload the following worksheet files into your Snowflake account. You need two separate accounts with the clean rooms API installed to run the code; one account to act as the provider and the other to act as the consumer.
Define a user input form for a custom template¶
For a custom template to be runnable in the clean rooms UI, the provider must define an input form for the template. This requirement applies even if the template has no arguments for the consumer to set. Consumers cannot define a user input form for a template.
Important
If you used provider.restrict_table_options_to_consumers or provider.restrict_template_options_to_consumers to restrict
tables or templates to specific users, these restrictions won’t work as expected in the clean rooms UI. You should not enable templates
for UI usage in clean rooms with these restrictions.
A configuration form enables users in the clean rooms UI to pass values to the custom template, similar to how you pass values to a template when using the API.
The following example shows a custom template that uses three variables, max_age, favorite_color, and source_table:
The following example shows how to pass in the template variables when you run the previous custom template in code:
To run this template in the clean rooms UI, you must define a form where the consumer assigns these template variables. The following
example shows how to define a simple form where the consumer can assign values to max_age, favorite_color, and source_table:
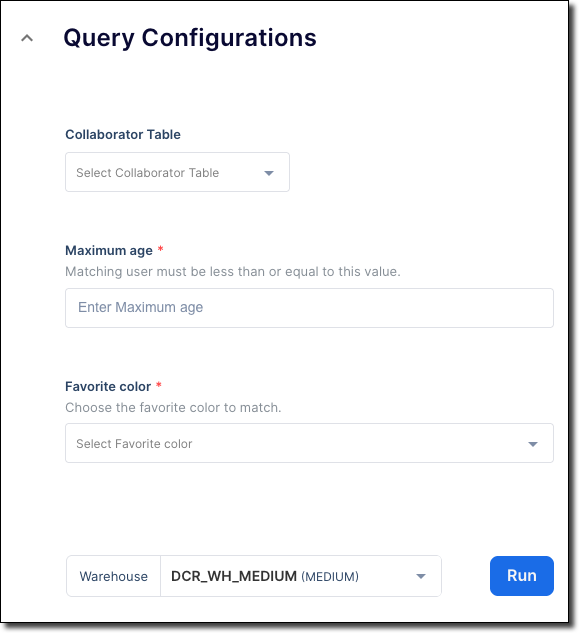
The previously defined form appears in the clean rooms UI when the consumer runs the template in the Configure Analysis & Query step.
The form includes a table chooser for source_table, labeled Collaborator table, an integer chooser element for max_age
labeled Maximum age, and a dropdown menu of color names for favorite_color labeled Favorite color, as shown in this image:
You can also define drop-down menus that are pre-populated with columns from the provider’s or consumer’s join policies, column policies, tables, and more. For more information about form element types, see .
Populate source_table and my_table¶
The standard source_table and my_table template variables can be populated as follows:
- Enable the default table selector drop-down menus: These drop-down menus are single-selection. You can show or hide them by using the
render_provider_table_dropdownandrender_consumer_table_dropdownsettings. The drop-down menus pass fully qualified table names to thesource_tableandmy_tabletemplate variables, respectively.
Qualify your column names¶
Most templates require all column names to be fully qualified to avoid column-name ambiguity.
The template must alias all tables as p or c, depending on whether they are provider or consumer tables. The template should
reference all columns using their p or c aliases. Learn more about aliasing.
If you create a drop-down column selector, you must either supply the p or c table alias explicitly in a choices array of the
drop-down menu, or you must add the alias in your template.
The following example shows how to provide the table alias in a drop-down menu:
However, this method is limiting because you must know all the column names in advance.
As an alternative, you can dynamically populate a column drop-down menu by providing a references property. However, such a
selector returns bare column names — for example, hashed_email — rather than fully-qualified column names — for example,
p.hashed_email. If bare column names are returned, you must scope the column to the table explicitly in your template. For example, the
following code creates a drop-down menu where a user can select a column from the provider’s join policy:
To use the column name in a template, the template must hard-code the table alias in front of the column name as shown in the following example:
Recommendations for developing a template that can be run in the clean rooms UI¶
The following steps show a recommended workflow for developing a template that can be run in the clean rooms UI:
1. Develop the template¶
First develop your template and any scripts that it calls by using only the clean rooms API in both the provider and consumer accounts. Testing the template in the API is much faster and less error-prone than using the UI.
Test your template thoroughly in the API, both on the provider and consumer side, to ensure that the template does exactly what you want it to do. Testing in the API is very quick, and changes are propagated immediately to the consumer account.
After you test your template and it runs exactly as you want, then move on to designing the input form.
2. Develop the input form¶
When the template and any uploaded scripts are working as intended, then start working on the input form. At this stage, you use the API in the provider account, but the UI in the consumer account.
When you make changes using the API, some values in the UI are refreshed immediately, some are refreshed when the user clicks Refresh, and some are refreshed only every 10 minutes. Therefore, when you work on the input form, create and update the form on the provider side using the API, but install and configure the clean room in the consumer account using the clean rooms UI, not the API. This ensures that you are using fresh data in the clean room UI.
Additionally, each time that you make changes to the input form in the API, create a new clean room to ensure that you use the latest clean room data. Use an incrementing number in the name; for example, “My clean room 1,” “My clean room 2,” and so on. Then, install the clean room in the client by using the UI. Finally, delete the old clean rooms because there is a limit to the number of clean rooms an account can hold.
An input form must be attached to a template, otherwise the clean room and form won’t be runnable in the clean rooms UI. When you develop your form, consider using a template that simply mirrors back all the values that are selected in the form so that you can verify what values are sent to the template.
For example, let’s suppose that your production template looks like the following template:
You could create the following template that mirrors back all the values of that production template:
Then design a form that sets those six variable values, and attach the form to the mirror template rather than the production template.
General tips for developing the input form
The following list provides detailed tips to help you develop an effective input form:
- If you encounter a generic “Installation failed” or “Something went wrong” message when you install, configure, or run a clean room in the UI, the message could mean that there is an error with the UI form or associated template that was not caught when you added the form or template.
- When one field depends on another field — for example, a column drop-down menu that is based on the value chosen by a table drop-down menu — put the parent field first, possibly right above the child field, so that users populate the parent field before they populate the child field. With dependent fields, the child drop-down menu is empty until a value is chosen for the parent field.
- If you don’t specify an
orderorgroupvalue, items are rendered in the order that they are defined. - Include informative
infoMessageanddescriptiontext, and show example values that a user might enter. - Choose the precise element type for the variable data type. For example, for an integer, choose
integerrather than a free-form text box. Your template can cast values by using Jinja filters; for example:SELECT {{ max_age | int }};. - If you don’t define a minimal configuration form for a custom template, the template can’t be run in the clean rooms UI.
- If you don’t define a form element for a variable in the template, a plain text box is rendered for that variable in the user form. This is probably not what you want, because the text box is labeled with the template variable name and has no description or suggestions.
- Form elements specified in
add_ui_form_customizationsaren’t rendered unless there is a matching template variable with the same name as the element. - Template changes made in the API propagate quickly and reliably to the UI, so you don’t need to create a new clean room for template changes. However, you should develop and test your template in the API before you reach the UI stage.
- You can’t auto-populate a drop-down menu with column values from a given table. You can hard-code values in a drop-down menu, but can’t show values from a table at runtime.
3. Connect the input form to the production template¶
After the form looks exactly like you want it and the form makes all template variables accessible by the user, then assign your working
template to the input form in your call to provider.add_ui_form_customizations.