クリーンルームにカスタムテンプレートを追加する¶
プロバイダーもコンシューマーも、クリーンルームにカスタムテンプレートを追加することができます。カスタムテンプレートは、Snowflakeが提供するテンプレートと同じ方法で実行されます。カスタムテンプレートは、APIを使用して作成され、APIまたは(そのために設計されている場合)UIを使用して実行されます。
クリーンルームテンプレートは有効な JinjaSQL テンプレートです。独自のクリーンルームテンプレートを作成する前に、カスタムテンプレートのクリーンルームリファレンスガイドを読む 必要があります。
プロバイダー記述のカスタムテンプレート¶
プロバイダーは、コンシューマーの承認なしに、クリーンルームにカスタムテンプレートを追加することができます。コンシューマーは承認を得ずに、プロバイダーが記述したテンプレートを実行することができます。次のセクションでは、プロバイダーがカスタムテンプレートを追加し、コンシューマーが API を使用してそのテンプレートを実行する方法について説明します。
プロバイダーは、コンシューマーがクリーンルーム UI で実行できるテンプレートを設計する場合、テンプレート用の:ref:`ユーザー入力フォームを作成 <label-dcr_define_user_form>`する必要があります。
プロバイダー記述のテンプレートを追加する¶
プロバイダーは、provider.add_custom_sql_template を呼び出すことでカスタムテンプレートを一度に1つ追加し、テンプレート JinjaSQL を文字列として渡します。カスタムテンプレートはクリーンルームのテンプレートリストに表示され、Snowflakeが提供するテンプレートと同じように動作します。クリーンルームには、カスタムテンプレートとSnowflakeが提供するテンプレートを自由に組み合わせて含めることができます。
呼び出すテンプレート用に カスタムPython UDFs をアップロードすることもできます。
Tip
コンシューマーが使用するカスタムテンプレートを追加する場合は、テンプレートの動作と、テンプレートが使用する必須引数およびオプション引数を説明するドキュメントを提供する必要があります。
以下の SQL の例は、プロバイダーがシンプルなカスタムテンプレートをクリーンルームに追加する方法を示しています。
このテンプレートには、4つの必須パラメーター( my_table 配列、 source_table 配列、 consumer_id 列名、および provider_id 列名)と、WHERE 句を指定するオプションの where_clause パラメーターがあります。
前述の例を含め、ほとんどのテンプレートでは、列名の競合を避けるために、ユーザーが提供する列名はテーブル名で完全修飾されていなければなりません。これは、テーブル名プレフィックスをプレフィックスの列名に連結し、有効な識別子を取得するのが簡単ではないためです(IDENTIFIER(p.{{ col_name | sqlsafe }}) はエラー)。そのため、呼び出し元に列名だけではなく、完全修飾テーブル名を提供するように求める必要があります。テーブル名には承認された小文字の p および c エイリアスを使用する必要があります。
プロバイダー記述テンプレートを実行する¶
クリーンルーム API を使用する場合、コンシューマーは consumer.run_analysis を呼び出してテンプレートを実行し、プロバイダーは プロバイダー実行の分析 のために provider.submit_analysis_request を呼び出します。
クリーンルーム UI でテンプレートを実行できるようにしたい場合、プロバイダーはテンプレート用の ユーザー入力フォームを作成 する必要があります。クリーンルーム UI では、プロバイダー記述のテンプレートのみを実行できます。
プロバイダーが テンプレートを難読化 <dcr_provider_add_custom_sql_template>`しない限り、クリーンルームのコラボレーターは ``consumer.view_template_definition` を呼び出して、クリーンルーム内のテンプレートの JinjaSQL を確認できます。難読化できるのは、プロバイダー記述のテンプレートのみです。
consumer.get_arguments_from_template を呼び出して、テンプレートで使用される変数を解析してリスト化できます。ただし、大規模なテンプレートまたは複雑なテンプレートの場合、この手順ではすべてのテンプレート変数がリスト化されない可能性があるため、テンプレートユーザーに役立つドキュメントを提供するようにしてください。
次の例は、コンシューマーが、先ほど示されたプロバイダーのカスタムテンプレートをどのように実行するかを示しています。
プロバイダーテンプレートのサンプルコード¶
以下は、プロバイダーがカスタムテンプレートを追加する方法と、コンシューマーがそれを実行する方法を示した完全なコード例です。コードを実行するには、クリーンルーム API がインストールされた2つの別々のアカウントが必要です。1つのアカウントはプロバイダーとして機能し、もう1つのアカウントはコンシューマーとして機能します。
コンシューマー記述のカスタムテンプレート¶
コンシューマーは、プロバイダーが承認すれば、カスタムテンプレートをクリーンルームに追加することができます。クリーンルームに追加すると、コンシューマー記述テンプレートを、プロバイダー記述テンプレートと同じように実行できます。コンシューマーがカスタムテンプレートを追加する方法は次のとおりです。
プロバイダーは標準的な方法でクリーンルームを作成、共有、公開します。
コンシューマーは標準的な方法でクリーンルームをインストールし、構成します。
コンシューマーは
consumer.create_template_requestを呼び出し、カスタムテンプレート文字列に渡します。プロバイダーは
provider.list_pending_template_requestsを呼び出し、保留中のリクエストを確認します。プロバイダーは、独自のテンプレートを実行するためのコンシューマーのリクエストを承認(
provider.approve_template_request)または拒否(provider.reject_template_request)します。(複数のリクエストを承認または拒否するための、これらのメソッドの一括バージョンもあります。)プロバイダーがテンプレートを承認すると、そのテンプレートはすぐにクリーンルームに追加されます。プロバイダーがテンプレートを承認する前に、プロバイダーはまず、データに対して必要な結合および列のポリシーを宣言する必要があります。
コンシューマーは、
consumer.list_template_requests(承認ステータスを表示)またはconsumer.view_added_templates(テンプレートがクリーンルームに追加されたかどうかを確認する)を呼び出してリクエストのステータスを確認します。テンプレートはプロバイダーの承認後にのみクリーンルームに追加されます。コンシューマーは、標準的な方法で
consumer.run_analysisを呼び出してテンプレートを実行します。
注釈
プロバイダーは、:doc:` コンシューマーから権限を付与された </user-guide/cleanrooms/demo-flows/provider-run-analysis>`場合、コンシューマーが追加したテンプレートを実行できます。
コンシューマーテンプレートの例¶
以下は、コンシューマーがカスタムテンプレートを送信し、実行する方法を示した完全なコード例です。次のワークシートファイルをSnowflakeアカウントにアップロードします。コードを実行するには、クリーンルーム API がインストールされた2つの別々のアカウントが必要です。1つのアカウントはプロバイダーとして機能し、もう1つのアカウントはコンシューマーとして機能します。
カスタムテンプレート用のユーザー入力フォームを定義する¶
クリーンルーム UI でカスタムテンプレートを実行できるようにしたい場合、プロバイダーはテンプレート用の入力フォームを作成する必要があります。この要件は、テンプレートにコンシューマーが設定する引数がない場合でも適用されます。コンシューマーは、テンプレートのユーザー入力フォームを定義することはできません。
重要
provider.restrict_table_options_to_consumers または provider.restrict_template_options_to_consumers を使用して特定のユーザーにテーブルやテンプレートを制限した場合、これらの制限はクリーンルーム UI では想定どおりに機能しません。クリーンルームの UI でこれらの制限を伴うテンプレートを使用できるようにしないでください。
構成フォームにより、ユーザーは API を使用してテンプレートに値を渡すときと同じ方法で、クリーンルーム UI で値をカスタムテンプレートに渡すことができます。
以下の例は、3つの変数(max_age、favorite_color、source_table)を使用するカスタムテンプレートを示しています。
以下の例は、コードで先ほどのカスタムテンプレートを実行したときにテンプレート変数を渡す方法を示しています。
クリーンルーム UI でこのテンプレートを実行するには、コンシューマーがこれらのテンプレート変数を割り当てるフォームを定義する必要があります。以下の例は、コンシューマーが値を max_age、favorite_color、source_table に割り当てる簡潔なフォームを定義する方法を示しています。
コンシューマーが Configure Analysis & Query ステップでテンプレートを実行すると、先ほど定義したフォームがクリーンルーム UI に表示されます。この画像に示されているように、フォームには Collaborator table というラベルが付いた source_table のテーブルセレクター、Maximum age というラベルが付いた max_age の整数セレクター要素、favorite_color というラベルが付いた Favorite color のカラー名ドロップダウンメニューが含まれます。
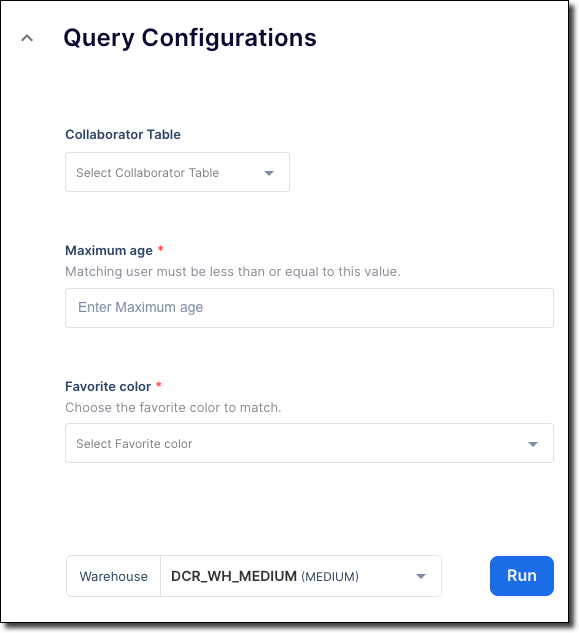
また、プロバイダーやコンシューマーの結合ポリシー、列ポリシー、テーブルなどのカラムが事前入力されたドロップダウンメニューを定義することもできます。フォームの要素タイプの詳細については、add_ui_form_customizations をご参照ください。
source_table および my_table を入力する¶
標準的な source_table および my_table テンプレート変数は以下のように入力できます。
デフォルトのテーブルセレクタードロップダウンメニューを有効にする: これらのドロップダウンメニューは単一選択です。
render_provider_table_dropdownおよびrender_consumer_table_dropdown設定を使用して、ドロップダウンメニューを表示または非表示にできます。ドロップダウンメニューは、完全修飾テーブル名をsource_tableおよびmy_tableテンプレート変数それぞれに渡します。
列名を修飾する¶
ほとんどのテンプレートでは、列名のあいまいさを避けるために、すべての列名が完全修飾されている必要があります。
テンプレートはすべてのテーブルを p または c としてエイリアスする必要があります。これは、プロバイダーかコンシューマーテーブルかによって異なります。テンプレートは、p または c エイリアスを使用してすべての列を参照する必要があります。エイリアスの詳細はご参照ください。
ドロップダウンの列セレクターを作成する場合は、ドロップダウンメニューの choices 配列で p または c テーブルエイリアスを明示的に指定するか、テンプレートにエイリアスを追加する必要があります。
以下の例は、ドロップダウンメニューでテーブルエイリアスを指定する方法を示しています。
ただし、すべての列名を事前に知る必要があるため、この方法には限界があります。
代わりに、references プロパティを指定することで、列のドロップダウンメニューを動的に入力できます。しかし、そのようなセレクターは、そのままの列名を返します。たとえば、完全修飾列名の p.hashed_email ではなく hashed_email を返します。そのままの列名が返される場合は、テンプレートで明示的に列をテーブルのスコープに含める必要があります。たとえば、次のコードは、ユーザーがプロバイダーの結合ポリシーから列を選択できるドロップダウンメニューを作成します。
テンプレートで列名を使用するには、次の例で示されているように、テンプレートが列名の前にテーブルエイリアスをハードコーディングする必要があります。
クリーンルーム UI で実行できるテンプレートの開発に関する推奨事項¶
以下のステップは、クリーンルーム UI で実行できるテンプレートを開発するための推奨ワークフローを示しています。
1. テンプレートを開発する¶
まず、プロバイダーとコンシューマーのアカウント両方で、クリーンルーム API のみを使用して呼び出すテンプレートと スクリプト を開発します。API を使用してテンプレートをテストすると、UI を使用するよりもはるかに高速で、エラーが発生しにくくなります。
プロバイダーとコンシューマー側両方で、API でテンプレートを:emph:`徹底的に`テストし、テンプレートが希望どおりに動くことを確認します。API でのテストは非常に迅速で、変更はすぐにコンシューマーアカウントに伝播されます。
テンプレートをテストし、期待どおりに実行されることがわかったら、入力フォームの設計に進みます。
2.入力フォームを開発する¶
テンプレートとアップロードされたスクリプトが意図したとおりに機能したら、入力フォームの作業を開始します。このステージでは、プロバイダーアカウントで API を使用しますが、コンシューマーアカウントでは UI を使用します。
API を使用して変更を行う場合、UI の一部の値はすぐに更新されますが、ユーザーが Refresh をクリックしないと更新されないものや、10分ごとにしか更新されないものもあります。したがって、入力フォームの作業を行う場合は、プロバイダー側の API を使用してフォームを作成し更新しますが、コンシューマーアカウント側のクリーンルーム UI(API ではなく)を使用して、クリーンルームをインストールし構成します。これにより、クリーンルーム UI で新しいデータを使用することができます。
さらに、API で入力フォームに変更を加えるたびに、新しいクリーンルームを作成し、最新のクリーンルームデータを使用できるようにします。名前には、「My clean room 1」、「My clean room 2」など、連続して増える数字を使用します。次に、UI を使用してクライアント側でクリーンルームをインストールします。アカウントが保持できるクリーンルームの数に制限があるため、最後に古いクリーンルームを削除します。
入力フォームはテンプレートに添付する必要があります。そうしないと、クリーンルームとフォームはクリーンルーム UI で実行できません。フォームを開発するときは、フォームで選択されたすべての値を単純に反映するテンプレートの使用を検討してください。そうすることで、テンプレートに送信された値を確認できます。
たとえば、本番テンプレートが次のようなテンプレートになるとします。
その本番テンプレートのすべての値を反映する以下のテンプレートを作成できます。
次に、これら6つの変数値を設定するフォームを設計し、本番テンプレートではなく、ミラーテンプレートにそのフォームを添付します。
入力フォームを開発するための一般的なヒント
次のリストは、効果的な入力フォームの開発に役立つ詳細なヒントを示しています。
UI でクリーンルームをインストール、構成、または実行したときに、「インストールに失敗しました」または「問題が発生しました」という汎用メッセージが表示された場合、メッセージは、フォームまたはテンプレートを追加したときにキャッチされなかった UI フォームまたは関連するテンプレートのエラーがあることを意味している可能性があります。
あるフィールドが別のフィールドに依存している場合、たとえば、テーブルドロップダウンメニューで選択された値に基づく列ドロップダウンメニューの場合は、まず親フィールドを、できれば子フィールドのすぐ上に配置します。そうすることで、ユーザーが子フィールドに入力する前に、親フィールドに入力できます。依存フィールドの場合、親フィールドの値が選択されるまで、子ドロップダウンメニューは空になります。
orderまたはgroup値を指定しない場合、アイテムは定義された順序でレンダリングされます。情報を提供する
infoMessageおよびdescriptionテキストを含め、ユーザーが入力する可能性のある値の例を示します。変数データ型の正確な要素のタイプを選択します。たとえば、整数の場合は自由形式のテキストボックスではなく
integerを選択します。テンプレートは、SELECT {{ max_age | int }};など、Jinjaフィルターを使用して値をキャストできます。カスタムテンプレートの最小構成フォームを定義しないと、そのテンプレートはクリーンルーム UI で実行できません。
テンプレートで変数のフォーム要素を定義しない場合は、ユーザーフォームではその変数に対してプレーンテキストボックスがレンダリングされます。テキストボックスにはテンプレート変数名がラベル付けされ、説明や提案がないため、これは希望するものではない可能性があります。
add_ui_form_customizationsで指定されたフォーム要素は、その要素と同じ名前を持つテンプレート変数がない限り、レンダリングされません。API で行われたテンプレートの変更は迅速かつ確実に UI に伝播するので、テンプレート変更のために新しいクリーンルームを作成する必要はありません。ただし、UI ステージに到達する 前 に、API でテンプレートを開発し、テストする必要があります。
特定のテーブルの列値をドロップダウンメニューに自動入力することはできません。ドロップダウンメニューに値をハードコーディングすることはできますが、実行時にテーブルから値を表示することはできません。
3.入力フォームを本番テンプレートに接続する¶
フォームが希望するとおりに表示され、フォームによってすべてのテンプレート変数にユーザーがアクセスできるようになったら、provider.add_ui_form_customizations の呼び出しで作業したテンプレートを入力フォームに割り当てます。