Snowpipe Streaming Classic과 함께 Kafka에 Snowflake Connector 사용하기¶
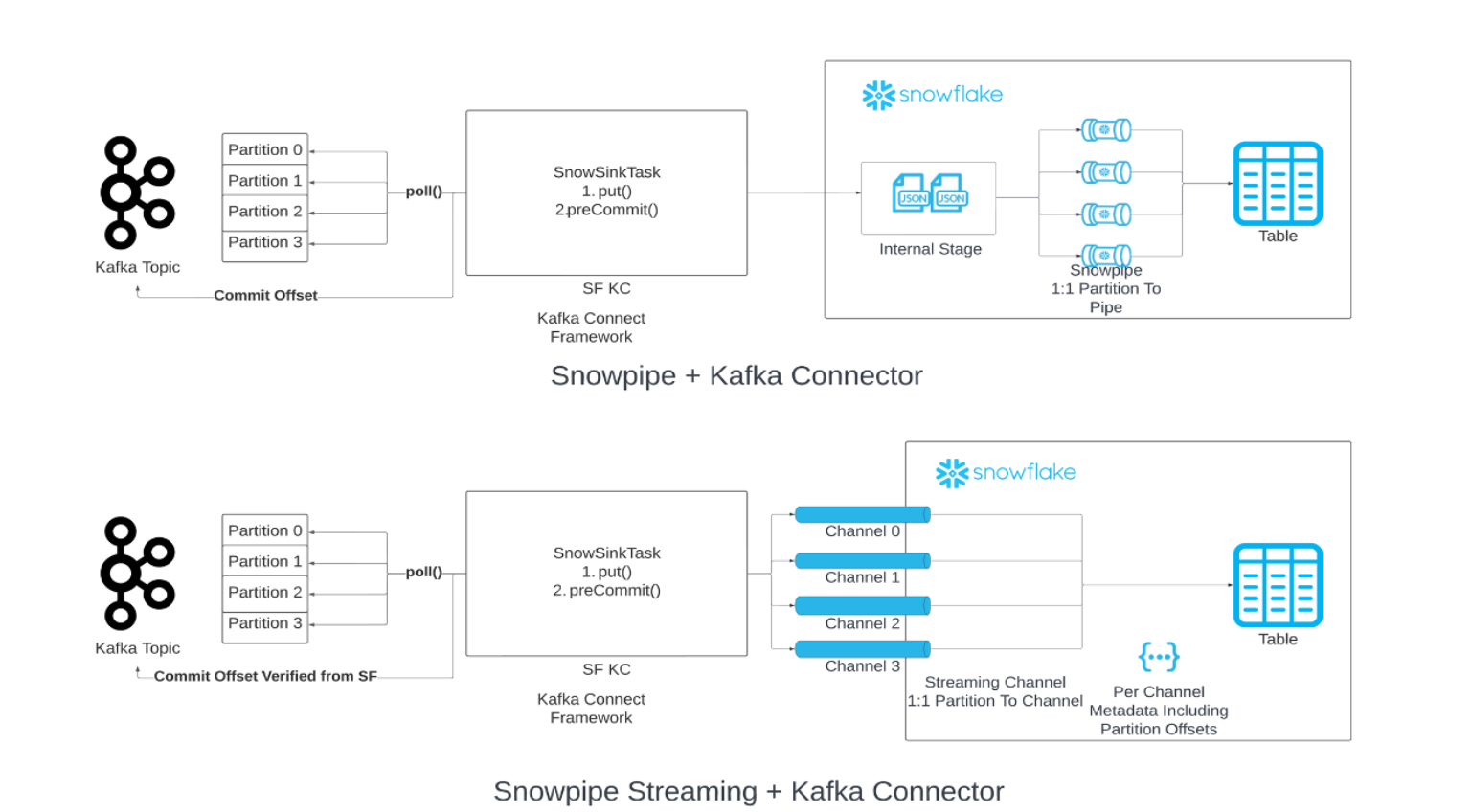
Kafka의 데이터 로딩 체인에서 Snowpipe를 Snowpipe Streaming 으로 바꿀 수 있습니다. 지정된 플러시 버퍼 임계값(시간, 메모리 또는 메시지 수)에 도달할 때 임시 스테이징된 파일에서 데이터를 쓰는 Snowpipe와는 달리, 커넥터가 Snowpipe Streaming API(“API”)를 호출하여 데이터 행을 Snowflake 테이블에 씁니다. 이 아키텍처에서는 비슷한 양의 데이터를 로딩하는 데 드는 비용이 낮아지는 것과 함께, 로드 지연 시간이 짧아집니다.
Kafka 커넥터 버전 2.0.0(또는 그 이상)은 Snowpipe Streaming Classic과 함께 사용해야 합니다. Snowpipe Streaming Classic이 포함된 Kafka 커넥터에는 Snowflake Ingest SDK 가 포함되어 있으며, Apache Kafka 항목의 행을 대상 테이블로 직접 스트리밍하는 것을 지원합니다.
이 항목의 내용:
최소 필수 버전¶
Snowpipe Streaming을 지원하는 최소 필수 Kafka 커넥터 버전은 2.0.0입니다.
Kafka 구성 속성¶
Kafka 커넥터 속성 파일에 연결 설정을 저장하십시오. 자세한 내용은 Kafka 커넥터 구성하기 섹션을 참조하십시오.
필수 속성¶
Kafka 커넥터 속성 파일에서 연결 설정을 추가하거나 편집합니다. 자세한 내용은 Kafka 커넥터 구성하기 섹션을 참조하십시오.
snowflake.ingestion.methodKafka 커넥터를 스트리밍 수집 클라이언트로 사용할 경우에만 필요합니다. Snowpipe Streaming 또는 표준 Snowpipe를 사용하여 Kafka 주제 데이터를 로드할지 여부를 지정합니다. 지원되는 값은 다음과 같습니다.
SNOWPIPE_STREAMINGSNOWPIPE(기본값)
주제 데이터를 큐에 넣고 로드할 백엔드 서비스를 선택하는 데 추가로 설정할 필요가 없습니다. 평소와 같이 Kafka 커넥터 속성 파일에서 추가 속성을 구성하면 됩니다.
snowflake.role.name테이블에 행을 삽입할 때 사용할 액세스 제어 역할입니다.
클라이언트 최적화 속성¶
enable.streaming.client.optimization단일 클라이언트 최적화를 활성화할지 여부를 지정합니다. 이 속성은 Kafka 커넥터 릴리스 버전 2.1.2 이상에서 지원됩니다. 이 속성은 기본적으로 활성화되어 있습니다.
단일 클라이언트 최적화를 사용하면 Kafka 커넥터당 여러 항목 파티션에 대해 클라이언트가 하나만 생성됩니다. 이 기능으로 더 큰 파일을 만들어 클라이언트 런타임을 줄이고 마이그레이션 비용을 절감할 수 있습니다.
- 값:
truefalse
- 기본값:
true
처리량이 높은 시나리오에서(예: 커넥터당 50MB/s) 이 속성을 활성화하면 대기 시간이 늘고 비용이 높아질 수 있습니다. 처리량이 많은 시나리오에서는 이 속성을 비활성화하는 것이 좋습니다.
버퍼 및 폴링 속성¶
buffer.flush.time버퍼 플러시 사이의 시간(초)으로, 플러시할 때마다 버퍼링된 레코드에 대한 삽입 작업이 발생합니다. Kafka 커넥터는 매번 플러시 후 한 번씩 Snowpipe Streaming API를 호출합니다.
buffer.flush.time속성에 지원되는 최소값은1(초)입니다. 평균 데이터 흐름 속도를 더 높이려면 기본값을 줄여 지연 시간을 개선하는 것이 좋습니다. 지연 시간보다 비용이 더 큰 문제인 경우에는 버퍼 플러시 시간을 늘릴 수 있습니다. 메모리 부족 예외를 방지하려면 Kafka 메모리 버퍼가 가득 차기 전에 플러시하도록 주의하십시오.- 값:
최소값:
1최대값: 상한 없음
- 기본값:
10
Snowpipe Streaming은 1초마다 자동으로 데이터를 플러시하는데, 이는 Kafka 커넥터의 버퍼 플러시 시간과 다릅니다. Kafka 버퍼 플러시 시간에 도달하면 Snowpipe Streaming을 통해 1초의 대기 시간으로 데이터가 Snowflake로 전송됩니다. 자세한 내용은 Snowpipe Streaming 대기 시간 을 참조하십시오.
buffer.count.recordsSnowflake로 수집하기 전에 Kafka 파티션당 메모리에 버퍼링된 레코드 수입니다.
- 값:
최소값:
1최대값: 상한 없음
- 기본값:
10000
buffer.size.bytesSnowflake에서 데이터 파일로 수집되기 전에 Kafka 파티션별로 메모리에 버퍼링된 레코드의 누적 크기(바이트)입니다.
레코드는 데이터 파일에 기록될 때 압축됩니다. 그 결과, 버퍼에 있는 레코드의 크기가 레코드에서 생성된 데이터 파일의 크기보다 클 수 있습니다.
- 값:
최소값:
1최대값: 상한 없음
- 기본값:
20000000(20MB)
snowflake.streaming.max.client.lagSnowflake Ingest Java 가 데이터를 Snowflake로 플러시하는 빈도(초)를 지정합니다.
이 값이 낮으면 지연 시간은 낮게 유지되지만, 특히
snowflake.streaming.enable.single.buffer가 활성화된 경우 쿼리 성능이 저하될 수 있습니다. 자세한 내용은 Snowpipe Streaming의 권장 대기 시간 구성 섹션을 참조하십시오.- 값:
최소:
1초최대:
600초
- 기본값:
버전 3.1.1 이상의 경우
30초, 버전 3.0.0 및 3.1.0의 경우120초, 그렇지 않은 경우1초
snowflake.streaming.enable.single.bufferSnowpipe Streaming에 대해 단일 버퍼를 활성화할지 여부와 커넥터의 내부 버퍼에서 데이터 버퍼링을 건너뛸지 여부를 지정합니다.
이 속성은 Kafka 커넥터 버전 2.3.1 이상에서 지원됩니다.
스트리밍 커넥터는 내부 버퍼와 Snowflake Ingest Java 에서 제공하는 버퍼를 함께 사용합니다. 이 속성을
true로 설정하면 지연 시간을 줄이기 위해 Kafka 커넥터가 내부 버퍼를 건너뛰게 됩니다.이 속성을
true로 설정하면buffer.flush.time및buffer.count.records가 서로 관련되지 않습니다.- 값:
truefalse
- 기본값:
버전 3.0.0 이상의 경우
false, 그렇지 않은 경우true
Kafka 커넥터 속성 외에도, 단일 폴링에서 Kafka가 Kafka Connect에 반환하는 최대 레코드 수를 제어하는 Kafka 컨슈머 max.poll.records 속성에 유의하십시오. 500 의 기본값을 늘릴 수 있지만 메모리 제약 조건에 유의하십시오. 이 속성에 대한 자세한 내용은 Kafka 패키지 설명서를 참조하십시오.
오류 처리 및 DLQ 속성¶
errors.toleranceKafka 커넥터에서 발생한 오류를 처리하는 방법을 지정합니다.
이 속성에서 지원되는 값은 다음과 같습니다.
- 값:
NONE: 첫 번째 오류가 발생하면 데이터 로딩을 중지합니다.ALL: 모든 오류를 무시하고 데이터 로딩을 계속합니다.
- 기본값:
NONE
errors.log.enableKafka Connect 로그 파일에 오류 메시지를 기록할지 여부를 지정합니다.
이 속성에서 지원되는 값은 다음과 같습니다.
- 값:
TRUE: 오류 메시지를 작성합니다.FALSE: 오류 메시지를 작성하지 마십시오.
- 기본값:
FALSE
errors.deadletterqueue.topic.nameSnowflake 테이블에 수집할 수 없는 메시지를 Kafka로 전달하기 위해 Kafka에서 DLQ(배달 못한 편지 큐) 주제의 이름을 지정합니다. 자세한 내용은 이 항목의 배달 못한 편지 큐 를 참조하십시오.
- 값:
사용자 지정 텍스트 문자열
- 기본값:
없음
정확히 한 번 의미 체계¶
정확히 한 번 의미 체계는 중복이나 데이터 손실 없이 Kafka 메시지가 전달되도록 보장합니다. 이 전달 보장은 Snowpipe Streaming을 사용하는 Kafka 커넥터에 기본적으로 설정됩니다.
Kafka 커넥터는 파티션과 채널 사이에 일대일 매핑을 채택하고 다음 두 가지 별개의 오프셋을 사용합니다.
컨슈머 오프셋: Kafka에서 관리하며 컨슈머가 소비한 가장 최근 오프셋을 추적합니다.
오프셋 토큰: Snowflake에서 관리하며 Snowflake에서 가장 최근에 커밋된 오프셋을 추적합니다.
Kafka 커넥터가 항상 누락된 오프셋을 처리하지는 않는다는 점에 유의하십시오. Snowflake에서는 모든 레코드에서 오프셋이 순차적으로 증가할 것으로 예상합니다. 오프셋이 누락되면 특정 사용 사례에서 Kafka 커넥터가 손상됩니다. NULL 레코드 대신 삭제 표식 레코드를 사용하는 것이 좋습니다.
Kafka 커넥터는 다음 모범 사례를 구현하여 정확히 한 번 전달하는 결과를 달성합니다.
채널 열기/다시 열기:
주어진 파티션의 채널을 열거나 다시 열 때 Kafka 커넥터는
getLatestCommittedOffsetTokenAPI를 통해 Snowflake에서 검색된 최신 커밋 오프셋 토큰을 정보 소스로 사용하고 그에 따라 적절히 Kafka의 컨슈머 오프셋을 재설정합니다.컨슈머 오프셋이 데이터 보존 기간 내에 더 이상 들지 않을 경우 예외가 발생하며 적절히 취할 조치 사항을 결정할 수 있습니다.
Kafka Connector가 Kafka에서 컨슈머 오프셋을 재설정하지 않고 정보 소스로 사용하는 유일한 상황은 Snowflake의 오프셋 토큰이 NULL인 경우입니다. 이 경우, 커넥터는 Kafka에서 보낸 오프셋을 수락하고 오프셋 토큰은 이후에 업데이트됩니다.
레코드 처리:
Kafka의 잠재적인 버그로 인해 발생할 수 있는 비연속적 오프셋에 대한 추가 안전 계층을 보장하고자, Snowflake는 가장 최근에 처리된 오프셋을 추적하는 메모리 내 변수를 유지 관리합니다. Snowflake는 현재 행의 오프셋이 최근에 처리된 오프셋에 1을 더한 값과 같을 경우에만 행을 수락하므로, 수집 프로세스가 지속적이고 정확하도록 여분의 보호 계층을 추가합니다.
예외, 실패, 충돌 복구 처리:
복구 프로세스의 일부로, Snowflake는 채널을 다시 열고 가장 최근에 커밋된 오프셋 토큰으로 컨슈머 오프셋을 재설정하여 앞에서 설명한 채널 열기/다시 열기 논리를 일관되게 준수합니다. 이를 통해 Snowflake는 가장 최근에 커밋된 오프셋 토큰보다 1이 더 큰 오프셋 값에서 데이터를 보내도록 Kafka에 신호를 보내 데이터 손실 제로화로 장애 지점에서 수집을 재개할 수 있도록 합니다.
재시도 메커니즘 구현:
발생 가능한 일시적인 문제를 설명하기 위해, Snowflake는 API 호출에 재시도 메커니즘을 포함합니다. Snowflake는 이러한 API 호출을 여러 번 재시도하여 성공 가능성을 높이고 수집 프로세스에 영향을 미치는 간헐적인 실패가 발생할 위험을 완화합니다.
컨슈머 오프셋 진행:
Snowflake는 정기적으로 가장 최근에 커밋된 오프셋 토큰을 사용하여 컨슈머 오프셋을 진행해 수집 프로세스가 계속 Snowflake의 최신 데이터 상태에 맞춰 조정되도록 보장합니다.
변환기¶
Snowpipe Streaming은 다음과 같은 많은 커뮤니티 기반 변환기를 지원합니다.
io.confluent.connect.avro.AvroConverterorg.apache.kafka.connect.json.JsonConverterio.confluent.connect.protobuf.ProtobufConverterio.confluent.connect.json.JsonSchemaConverterorg.apache.kafka.connect.converters.ByteArrayConverterorg.apache.kafka.connect.storage.StringConverter
다른 커뮤니티 기반 변환기가 지원될 수 있지만, 아직 유효성 검사는 수행되지 않습니다. Snowflake 변환기는 Snowpipe Streaming에서 지원되지 않습니다.
배달 못한 편지 큐¶
Snowpipe Streaming을 사용하는 Kafka 커넥터는 손상된 레코드 또는 오류로 인해 성공적으로 처리할 수 없는 레코드에 대해 배달 못한 편지 큐(DLQ)를 지원합니다.
모니터링에 대한 자세한 내용은 Apache Kafka 설명서 를 참조하십시오.
스키마 감지 및 스키마 진화¶
Snowpipe Streaming을 사용하는 Kafka 커넥터는 스키마 감지 및 진화를 지원합니다. Snowflake의 테이블 구조는 Kafka 커넥터가 로드하는 새로운 Snowpipe Streaming 데이터의 구조를 지원하도록 자동으로 정의되고 진화할 수 있습니다. Snowpipe Streaming을 사용하는 Kafka 커넥터의 스키마 감지 및 진화를 활성화하려면 다음 Kafka 속성을 구성하십시오.
snowflake.ingestion.methodsnowflake.enable.schematizationschema.registry.url
자세한 내용은 Snowpipe Streaming Classic을 사용한 Kafka 커넥터의 스키마 탐지 및 진화 섹션을 참조하십시오.
수집 지연 예상하기¶
수집 대기 시간을 추정하려면 RECORD_METADATA의 SnowflakeConnectorPushTime 필드를 사용하십시오. 이 타임스탬프는 레코드가 Ingest SDK 버퍼로 푸시된 시점을 나타냅니다.
RECORD_METADATA 형식에 대한 자세한 내용은 Kafka용 테이블의 스키마 항목 을 참조하십시오.
참고
이 필드는 구성된 Snowpipe Streaming 지연 시간 을 고려하지 않기 때문에 레코드가 Snowflake 테이블에 표시된 시점을 나타내지 않습니다.
청구 및 사용량¶
Snowpipe Streaming 청구 정보는 Snowpipe Streaming Classic 비용 섹션을 참조하십시오.
제한 사항¶
Snowpipe Streaming 제한 사항¶
Snowpipe Streaming 제한 사항 섹션을 참조하세요.
장애 조치 제한 사항¶
보조 장애 조치 그룹이 기본 그룹으로 승격되면 Snowpipe Streaming을 사용하는 Kafka 커넥터에 수동 상호 작용이 필요합니다. 정확히 한 번만 실행되는 의미 체계는 여전히 유지됩니다.
enable.streaming.client.optimization 속성이 `false`로 설정된 경우 Kafka 커넥터를 다시 시작해야 합니다. 커넥터를 다시 시작하면 새 기본 배포를 대상으로 합니다.
enable.streaming.client.optimization 속성이 `true`로 설정된 경우 커넥터가 실행 중인 호스트 JVM은 종료했다가 다시 시작해야 합니다. 호스트 JVM을 다시 시작한 후 새로 시작된 Kafka 커넥터는 새로운 기본 배포를 대상으로 합니다.