Snowpipe Streaming¶
Snowpipe Streaming은 스트리밍 데이터를 Snowflake에 직접 짧은 지연 시간으로 지속적으로 로딩할 수 있는 서비스입니다. 실시간에 가까운 데이터 수집 및 분석이 가능하므로 시기적절한 인사이트와 즉각적인 작업 대응에 매우 중요합니다. 다양한 스트림 소스의 대용량 데이터를 몇 초 안에 쿼리하고 분석할 수 있습니다.
Snowpipe Streaming의 값¶
실시간 데이터 가용성: 기존의 일괄 로딩 방식과 달리 데이터가 도착하는 즉시 수집하여 실시간 대시보드, 실시간 분석, 사기 탐지와 같은 사용 사례를 지원합니다.
효율적인 스트림 워크로드: 중간 클라우드 저장소를 우회하여 테이블에 직접 행을 쓰기 위해 Snowflake Ingest SDKs 를 활용합니다. 이 직접적인 접근법은 지연 시간을 줄이고 수집 아키텍처를 간소화합니다.
간소화된 데이터 파이프라인: 애플리케이션 이벤트, IoT 센서, 변경 데이터 캡처(CDC) 스트림, 메시지 큐(예: Apache Kafka)와 같은 소스에서 지속적인 데이터 파이프라인을 위한 간소화된 접근법을 제공합니다.
서버리스 및 확장 가능: 서버리스 제품으로서 수집 로딩에 따라 컴퓨팅 리소스를 자동으로 확장하므로 수집 작업을 위한 수동 웨어하우스 관리가 필요하지 않습니다.
스트림에 비용 효율적입니다. 청구는 스트림 수집에 최적화되어 있어 빈번한 소규모 배치 COPY 작업에 비해 대용량, 저지연 데이터 피드에 더 비용 효율적인 솔루션을 제공할 수 있습니다.
Snowpipe Streaming을 사용하면 Snowflake 데이터 클라우드에서 실시간 데이터 애플리케이션을 구축할 수 있으므로 가장 최신의 데이터를 기반으로 의사결정을 내릴 수 있습니다.
Snowpipe Streaming 구현¶
Snowpipe Streaming은 다양한 데이터 수집 요구 사항과 기대 성능을 충족하기 위해 두 가지 구현을 제공합니다. 고성능 아키텍처(미리 보기)를 사용한 Snowpipe Streaming과 Classic 아키텍처를 사용한 Snowpipe Streaming입니다.
고성능 아키텍처를 사용한 Snowpipe Streaming(미리 보기)
Snowflake는 이 차세대 구현을 통해 처리량을 크게 개선하고, 스트림 성능을 최적화하며, 예측 가능한 비용 모델을 제공함으로써 고급 데이터 스트리밍 기능을 위한 스테이지를 설정했습니다.
주요 특징:
SDK: 새로운
snowpipe-streamingSDK 를 활용합니다.가격: 투명한 처리량 기반 가격 기능(비압축 GB 당 크레딧).
데이터 플로우 관리: PIPE오브젝트를 활용하여 데이터 플로우를 관리하고 수집 시 경량 변환을 활성화합니다. 이 PIPE 오브젝트에 대해 채널이 열립니다.
수집: PIPE 를 통해 직접 경량 데이터 수집을 위한 REST API 를 제공합니다.
스키마 유효성 검사: PIPE 에 정의된 스키마에 대해 수집하는 동안 서버 측에서 수행됩니다.
성능: 처리량이 크게 증가하고 수집된 데이터에 대한 쿼리 효율성이 향상되도록 설계되었습니다.
특히 새로운 스트림 프로젝트의 경우 이 고급 아키텍처를 살펴보는 것이 좋습니다.
Classic 아키텍처를 사용한 Snowpipe Streaming
이는 일반적으로 공급되는 최초의 구현으로, 기존 데이터 파이프라인에 안정적인 솔루션을 제공합니다.
주요 특징:
SDK: Snowflake-ingest-java SDK (4.x까지 모든 버전)를 사용합니다.
데이터 플로우 관리: 스트림 수집에 PIPE 오브젝트 개념을 사용하지 않습니다. 채널은 대상 테이블에 대해 직접 구성하고 열 수 있습니다.
가격: 수집에 사용된 서버리스 컴퓨팅 리소스와 활성 클라이언트 연결 수를 조합하여 산정합니다.
구현 선택¶
구현을 선택할 때는 당면한 요구 사항과 장기적인 데이터 전략을 고려하십시오.
새로운 스트림 프로젝트: 미래 지향적인 설계, 더 나은 성능, 확장성, 비용 예측 가능성을 갖춘 Snowpipe Streaming 고성능 아키텍처(미리 보기)를 평가해 보시기 바랍니다.
성능 요구 사항: 고성능 아키텍처는 처리량을 극대화하고 실시간 성능을 최적화하도록 구축되었습니다.
가격 선호도: 고성능 아키텍처는 명확한 처리량 기반 가격을 제공하는 반면, 클래식 아키텍처는 서버리스 컴퓨팅 사용량과 클라이언트 연결을 기준으로 요금을 청구합니다.
기존 설정: 클래식 아키텍처를 사용하는 기존 애플리케이션은 계속 작업할 수 있습니다. 향후 확장 또는 재설계 시 고성능 아키텍처로 마이그레이션하거나 통합하는 것을 고려하십시오.
기능 세트 및 관리: 고성능 아키텍처의 PIPE 오브젝트는 기존 아키텍처에는 없는 개선된 관리 및 변환 기능을 도입했습니다.
Snowpipe Streaming과 Snowpipe 비교¶
Snowpipe Streaming은 Snowpipe를 대체하는 것이 아니라 Snowpipe를 보완하기 위한 것입니다. 데이터가 파일에 기록되는 대신 행(예: Apache Kafka 항목)으로 스트림되는 스트리밍 시나리오에서는 Snowpipe Streaming API 를 사용하십시오. 이 API는 레코드를 생성하거나 수신하는 기존 사용자 지정 Java 애플리케이션을 포함하는 수집 워크플로에 적합합니다. API 를 사용하면 파일을 생성하지 않고도 Snowflake 테이블에 데이터를 로딩할 수 있으며, API 를 사용하는 경우 데이터를 사용할 수 있게 되면 데이터 스트림이 Snowflake에 자동으로 연속적으로 로드됩니다.
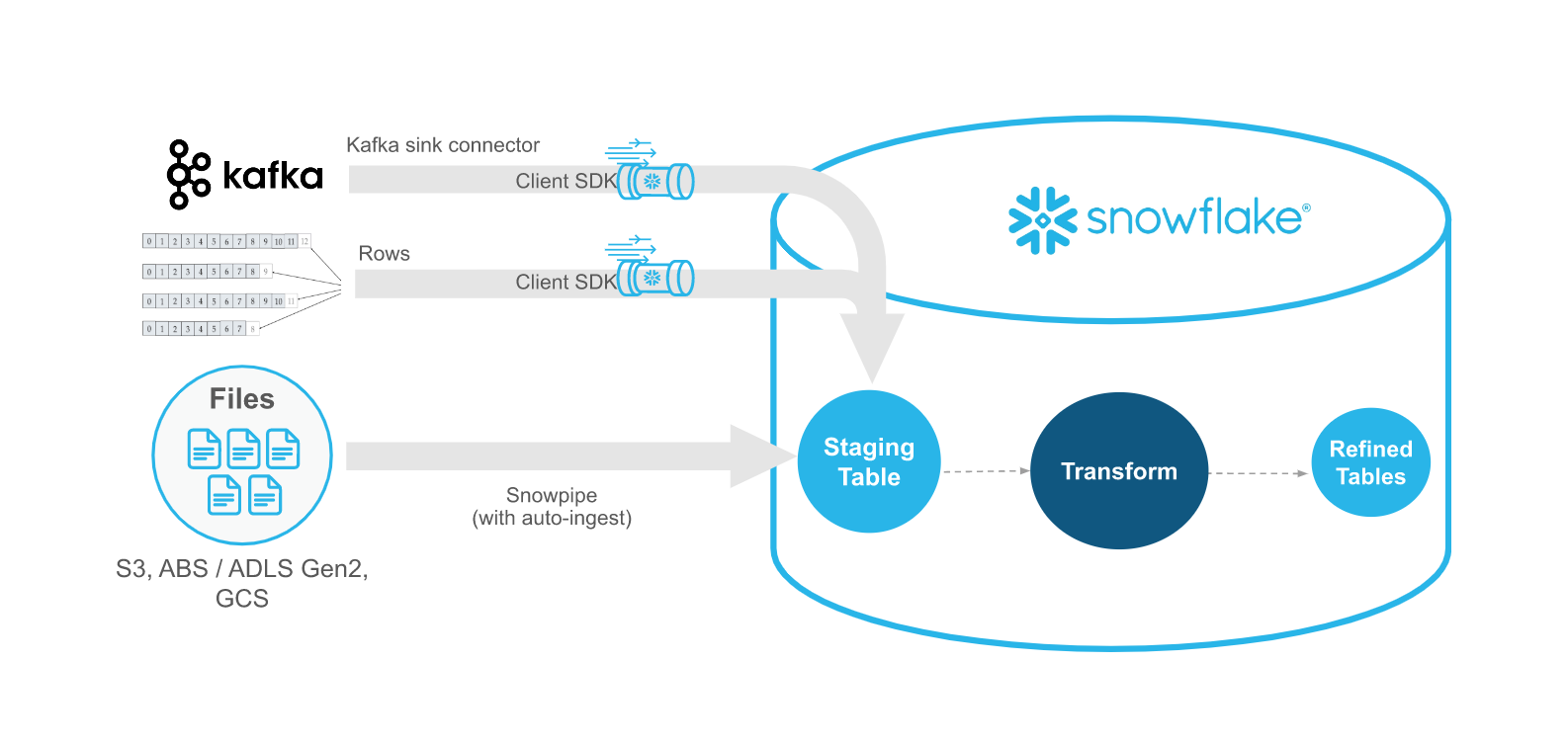
다음 표에 Snowpipe Streaming과 Snowpipe의 차이점이 설명되어 있습니다.
카테고리 |
Snowpipe Streaming |
Snowpipe |
|---|---|---|
로드할 데이터의 형식 |
행 |
파일. 기존 데이터 파이프라인이 Blob 저장소에서 파일을 생성하는 경우 API 대신 Snowpipe를 사용하는 것이 좋습니다. |
타사 소프트웨어 요구 사항 |
Snowflake Ingest SDK용 사용자 지정 Java 애플리케이션 코드 래퍼 |
없음 |
데이터 순서 지정 |
각 채널 내에서 순서가 지정된 삽입 |
지원 안 됨. Snowpipe는 클라우드 저장소의 파일 생성 타임스탬프와 다른 순서로 파일에서 데이터를 로드할 수 있습니다. |
로드 내역 |
SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY 뷰 (Account Usage)에 기록된 로드 내역 |
COPY_HISTORY (Account Usage) 및 COPY_HISTORY 함수 (Information Schema)에 기록된 레코드 로드 |
파이프 오브젝트 |
클래식 아키텍처에서는 파이프 오브젝트가 필요하지 않습니다. API 는 대상 테이블에 직접 레코드를 씁니다. 고성능 아키텍처에는 파이프 오브젝트가 필요합니다. |
큐에 넣은 스테이징된 파일 데이터를 대상 테이블로 로드하는 파이프 오브젝트가 필요합니다. |
소프트웨어 요구 사항¶
Java SDK¶
특정 Java SDKs 는 Snowpipe Streaming 서비스와의 상호 작용을 용이하게 합니다. Maven 중앙 리포지토리에서 SDKs 를 다운로드할 수 있습니다. 다음 목록은 사용하는 Snowpipe Streaming 아키텍처에 따라 달라지는 요구 사항을 보여줍니다.
고성능 아키텍처를 갖춘 Snowpipe Streaming:
SDK: 새로운 snowpipe-streaming SDK 를 사용합니다.
Java 버전: Java 11 이상이 필요합니다.
Snowpipe Streaming Classic의 경우:
SDK: snowflake-ingest-sdk 버전 4.X 이상을 사용합니다.
Java 버전: Java 8 이상이 필요합니다.
추가 사전 요구 사항: Java 8 환경에는 Java 암호화 확장자(JCE) Unlimited Strength Jurisdiction Policy Files 이 설치되어 있어야 합니다.
중요
SDK는 Snowflake와 상호 작용하기 위해 REST API 호출을 수행합니다. 연결을 허용하려면 네트워크 방화벽 규칙을 조정해야 할 수 있습니다.
사용자 지정 클라이언트 애플리케이션¶
API 에는 데이터 행을 펌핑하고 발생하는 오류를 처리할 수 있는 사용자 지정 Java 애플리케이션 인터페이스가 필요하며, 애플리케이션이 지속적으로 실행되고 장애로부터 복구할 수 있는지 확인해야 합니다. 주어진 행 배치의 경우 API는 ON_ERROR = CONTINUE | SKIP_BATCH | ABORT 에 해당하는 기능을 지원합니다.
CONTINUE: 허용 가능한 데이터 행을 계속 로드하고 모든 오류를 반환합니다.SKIP_BATCH: 전체 행 배치에서 오류가 발생하면 로딩을 건너뛰고 모든 오류를 반환합니다.ABORT(기본 설정): 전체 행 배치를 중단하고 첫 번째 오류가 발생하면 예외를 발생시킵니다.
Snowpipe Streaming Classic의 경우 애플리케이션은 insertRow (단일 행) 또는 insertRows (행 세트) 메서드의 응답을 사용하여 스키마 유효성 검사를 수행합니다. 고성능 아키텍처에 대한 오류 처리에 대해서는 오류 처리 섹션을 참조하십시오.
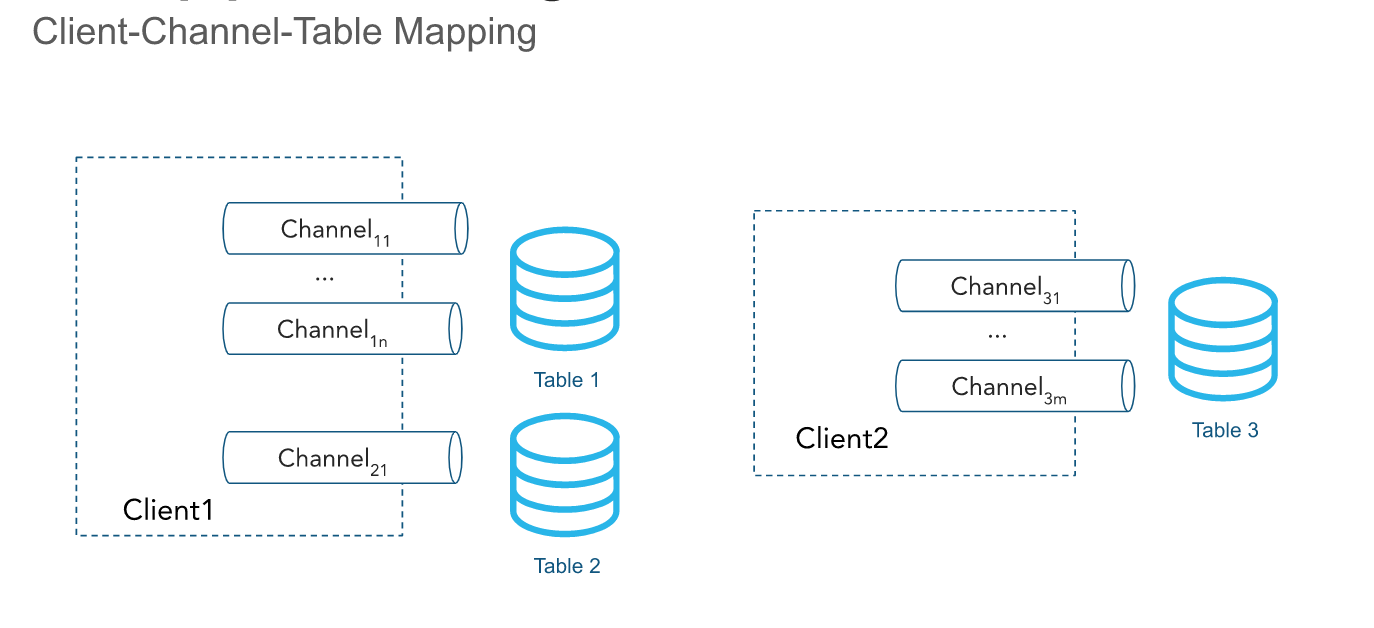
채널¶
API 는 1개 이상의 채널 을 통해 행을 수집합니다. 채널은 테이블에 데이터를 로드하기 위한 Snowflake에 대한 논리적이고 명명된 스트리밍 연결을 나타냅니다. 단일 채널이 Snowflake에서 정확히 한 테이블에 매핑되지만, 여러 채널이 같은 테이블을 가리킬 수 있습니다. 클라이언트 SDK 는 여러 테이블에 여러 채널을 열 수 있지만, SDK 는 계정 간에 채널을 열 수 없습니다. 행의 순서와 해당 오프셋 토큰은 채널 내에서 유지되지만, 동일한 테이블을 가리키는 채널 간에는 유지되지 않습니다.
채널은 클라이언트가 데이터를 능동적으로 삽입할 때 오랫동안 유지되어야 하며 오프셋 토큰 정보가 유지되므로 재사용되어야 합니다. 채널 내부의 데이터는 기본적으로 1초마다 자동으로 플러시되며 채널을 닫을 필요가 없습니다. 자세한 내용은 대기 시간 섹션을 참조하십시오.
채널 및 관련 오프셋 메타데이터가 더 이상 필요하지 않은 경우 DropChannelRequest API 를 사용하여 채널을 영구 삭제할 수 있습니다. 채널은 다음의 두 가지 방법으로 삭제할 수 있습니다.
종료할 때 채널 삭제. 채널 내부의 데이터는 채널이 삭제되기 전에 자동으로 플러시됩니다.
무작정 채널 삭제. 채널을 삭제하면 보류 중인 모든 데이터가 무작위로 삭제되고 이미 개설된 채널이 무효화될 수 있으므로 이 방법은 권장하지 않습니다.
SHOW CHANNELS 명령을 실행하여 액세스 권한이 있는 채널을 나열할 수 있습니다. 자세한 내용은 SHOW CHANNELS 섹션을 참조하십시오.
참고
오프셋 토큰과 함께 비활성 채널은 30일 후에 자동으로 삭제됩니다.
오프셋 토큰¶
오프셋 토큰 은 클라이언트가 행 제출 메서드 요청(예: 단일 또는 다중 행)에 포함시켜 채널별로 수집 진행 상황을 추적할 수 있는 문자열입니다. 사용되는 구체적인 방법은 클래식 아키텍처의 경우 insertRow 또는 insertRows, 고성능 아키텍처의 경우 appendRow 또는 appendRows 에서 확인할 수 있습니다. 토큰은 채널 생성 시 NULL로 초기화되며 제공된 오프셋 토큰이 있는 행이 비동기 프로세스를 통해 Snowflake에 커밋될 때 업데이트됩니다. 클라이언트는 주기적으로 getLatestCommittedOffsetToken 메서드 요청을 통해 특정 채널에 대한 최신 커밋된 오프셋 토큰을 가져와 수집 진행 상황을 추론하는 데 사용할 수 있습니다. 이 토큰은 Snowflake에서 중복 제거를 수행하는 데 사용되지 않지만, 클라이언트는 이 토큰을 사용하여 사용자 지정 코드를 통해 중복 제거를 수행할 수 있습니다.
클라이언트가 채널을 다시 열면 최신 지속형 오프셋 토큰이 반환됩니다. 클라이언트는 동일한 데이터를 두 번 전송하지 않도록 토큰을 사용하여 데이터 원본에서 위치를 재설정할 수 있습니다. 채널 다시 열기 이벤트가 발생할 때 이를 커밋하지 않도록 Snowflake에 버퍼링된 데이터가 전부 삭제됩니다.
가장 최근에 커밋된 오프셋 토큰을 사용하여 다음과 같은 일반적인 사용 사례를 수행할 수 있습니다.
수집 진행 상황 추적
가장 최근에 커밋된 오프셋 토큰과 비교하여 특정 오프셋이 커밋되었는지 확인
원본 오프셋 진행 및 이미 커밋된 데이터 제거
중복 제거 활성화 및 정확히 한 번만 데이터 전달
예를 들어 Kafka 커넥터는 파티션이 채널 이름으로 인코딩된 경우 <partition>:<offset> 또는 단순히 <offset> 과 같은 주제에서 오프셋 토큰을 읽을 수 있습니다. 다음 시나리오를 생각해보십시오.
Kafka 커넥터가 온라인 상태가 되어 채널 이름이
T:P1인 Kafka 주제T의Partition 1에 해당하는 채널을 엽니다.커넥터가 Kafka 파티션에서 레코드를 읽기 시작합니다.
커넥터는 API를 호출하여 레코드와 연결된 오프셋을 오프셋 토큰으로 사용하여
insertRows메서드 요청을 만듭니다.예를 들어 오프셋 토큰은 Kafka 파티션의 10번째 레코드를 참조하는
10일 수 있습니다.커넥터는 수집 진행률을 확인하기 위해 주기적으로
getLatestCommittedOffsetToken메서드 요청을 만듭니다.
Kafka 커넥터의 작동이 중단되는 경우 다음 절차를 완료하여 Kafka 파티션의 올바른 오프셋에서 레코드 읽기를 재개할 수 있습니다.
Kafka 커넥터가 다시 온라인 상태가 되어 이전과 같은 이름을 사용하여 채널을 다시 엽니다.
커넥터가 API를 호출해
getLatestCommittedOffsetToken메서드 요청을 만들어 파티션에 대해 커밋된 최신 오프셋을 가져옵니다.예를 들어 지속된 최신 오프셋 토큰이
20이라고 가정합니다.커넥터는 Kafka 읽기 API를 사용하여 오프셋에 1을 더한 값에 해당하는 커서를 재설정하는데, 이 예에서는
21입니다.커넥터가 레코드 읽기를 재개합니다. 읽기 커서의 위치가 올바로 변경된 후에는 중복 데이터가 검색되지 않습니다.
또 다른 예에서는 애플리케이션이 디렉터리에서 로그를 읽고 Snowpipe Streaming Client SDK를 사용하여 해당 로그를 Snowflake로 내보냅니다. 다음을 수행하는 로그 내보내기 애플리케이션을 만들 수 있습니다.
로그 디렉터리의 파일을 나열합니다.
로깅 프레임워크가 사전순으로 정렬할 수 있는 로그 파일을 생성하고 새 로그 파일이 이 정렬의 끝에 배치된다고 가정합니다.
로그 파일을 한 줄씩 읽고 API를 호출하여 로그 파일 이름과 줄 수 또는 바이트 위치에 해당하는 오프셋 토큰으로
insertRows메서드 요청을 만듭니다.예를 들어 오프셋 토큰은
messages_1.log:20일 수 있는데, 여기서messages_1.log는 로그 파일의 이름이고20은 줄 번호입니다.
애플리케이션은 비정상 종료되거나 다시 시작해야 하는 경우 API를 호출하여 마지막으로 내보낸 로그 파일과 줄에 해당하는 오프셋 토큰을 불러오는 getLatestCommittedOffsetToken 메서드 요청을 만듭니다. 예제를 계속 진행하면 오프셋 토큰이 messages_1.log:20 일 수 있습니다. 그런 다음 애플리케이션은 messages_1.log 를 열고 21 행을 검색하여 같은 로그 행이 두 번 수집되지 않도록 합니다.
참고
오프셋 토큰 정보가 손실될 수 있습니다. 오프셋 토큰은 채널 오브젝트에 연결되며 30일 동안 채널을 사용하여 새로운 수집이 수행되지 않을 경우에는 채널이 자동으로 지워집니다. 오프셋 토큰을 잃어버리지 않도록 별개의 오프셋을 유지 관리하고 필요한 경우 채널의 오프셋 토큰을 재설정하십시오.
offsetToken 및 :code:`continuationToken`의 역할¶
offsetToken 및 :code:`continuationToken`은 모두 정확히 한 번만 데이터가 전달되도록 보장하는 데 사용되지만, 목적이 다르며 서로 다른 시스템에서 관리됩니다. 주요 차이점은 토큰 값을 제어하는 주체와 사용 범위입니다.
:code:`continuationToken`(고성능 아키텍처에만 적용됨):
이 토큰은 Snowflake에서 관리하며 단일 연속 스트리밍 세션의 상태를 유지하는 데 필수적입니다. 클라이언트가
Append RowsAPI를 사용하여 데이터를 보낼 때, Snowflake는 :code:`continuationToken`을 반환합니다. 클라이언트는 데이터가 올바른 순서로 간격 없이 수신되도록 다음 요청에서 이 토큰을 사용해야 합니다. Snowflake는 토큰을 사용하여 SDK 재시도 이벤트 발생 시 중복 데이터를 감지하고 방지합니다.:code:`offsetToken`(클래식 및 고성능 아키텍처 모두에 적용됨):
이 토큰은 외부 소스에서 정확히 한 번만 전달할 수 있는 사용자 정의 식별자입니다. Snowflake는 자체 내부 작업이나 재수집을 방지하기 위해 이 토큰을 사용하지 않습니다. 대신, Snowflake는 단순히 이 값을 저장합니다. 외부 시스템(예: Kafka 커넥터)은 Snowflake에서 오프셋 토큰을 읽고 이를 사용하여 자체 수집 진행 상황을 추적하고 외부 스트림을 재생해야 하는 경우 중복 데이터 전송을 방지할 책임이 있습니다.
정확히 한 번 전달하는 모범 사례¶
정확히 한 번 전달하기란 어려운 일이 될 수 있으며, 사용자 지정 코드에서 다음 원칙을 준수하는 것이 매우 중요합니다.
예외, 실패 또는 비정상 종료 발생 시 적절한 복구를 보장하려면 항상 채널을 다시 열고 가장 최근에 커밋된 오프셋 토큰을 사용하여 다시 수집을 시작해야 합니다.
애플리케이션이 자체 오프셋을 유지할 수 있겠지만, Snowflake에서 제공하는 가장 최근에 커밋된 오프셋 토큰을 정보 소스로 사용하고 그에 따라 적절히 자체 오프셋을 재설정하는 것이 매우 중요합니다.
자체 오프셋을 정보 소스로 취급해야 하는 유일한 경우는 Snowflake의 오프셋 토큰이 NULL로 설정되거나 재설정될 때입니다. NULL 오프셋 토큰은 보통 다음 중 하나를 의미합니다.
이것은 새 채널이므로 설정된 오프셋 토큰이 없습니다.
대상 테이블이 삭제되고 다시 생성되었으므로 채널이 새 채널로 간주됩니다.
30일 동안 채널을 통한 수집 활동이 없어 채널이 자동으로 정리되었으며 오프셋 토큰 정보가 손실되었습니다.
필요한 경우 가장 최근에 커밋된 오프셋 토큰을 기반으로 이미 커밋된 원본 데이터를 주기적으로 제거하고 자체 오프셋을 진행할 수 있습니다.
Snowpipe Streaming 채널이 활성화되어 있을 때 테이블 스키마가 수정되면 채널을 다시 열어야 합니다. Snowflake Kafka 커넥터는 이 시나리오를 자동으로 처리하지만, Snowflake 수집 SDK를 직접 사용하는 경우에는 채널을 직접 다시 열어야 합니다.
Snowpipe Streaming을 사용하는 Kafka 커넥터가 정확히 한 번 전달하는 자세한 방법은 정확히 한 번 의미 체계 섹션을 참조하십시오.
Apache Iceberg™ 테이블에 데이터 로드.¶
Snowflake Ingest SDK 버전 3.0.0 이상에서, Snowpipe Streaming은 Snowflake가 관리하는 Apache Iceberg 테이블로 데이터를 수집할 수 있습니다. Snowpipe Streaming Ingest Java SDK 는 표준 Snowflake 테이블(비 Iceberg)과 Iceberg 테이블 모두에 대한 로딩을 지원합니다.
자세한 내용은 Apache Iceberg™ 테이블과 함께 Snowpipe Streaming Classic 사용하기 섹션을 참조하십시오.
대기 시간¶
Snowpipe Streaming은 1초마다 채널 내의 데이터를 자동으로 플러시합니다. 데이터를 플러시하려고 채널을 닫을 필요는 없습니다.
Snowflake Ingest SDK 버전 2.0.4 이상에서는 MAX_CLIENT_LAG 옵션을 사용하여 대기 시간을 구성할 수 있습니다.
표준 Snowflake 테이블(비Iceberg)의 경우 기본
MAX_CLIENT_LAG는 1초입니다.Iceberg 테이블(Snowflake Ingest SDK 버전 3.0.0 이상에서 지원됨)의 경우 기본
MAX_CLIENT_LAG는 30초입니다.
최대 대기 시간은 최대 10분까지 설정할 수 있습니다. 자세한 내용은 MAX_CLIENT_LAG 및 Snowpipe Streaming의 권장 대기 시간 구성 을 참조하십시오.
Snowpipe Streaming용 Kafka 커넥터에는 자체 버퍼가 있습니다. Kafka 버퍼 플러시 시간에 도달하면 Snowpipe Streaming을 통해 1초의 대기 시간으로 데이터가 Snowflake로 전송됩니다. 자세한 내용은 buffer.flush.time 을 참조하십시오.
기존 아키텍처에서 최적화된 파일로의 마이그레이션¶
API는 채널의 행을 클라우드 저장소의 Blob에 쓴 다음 대상 테이블에 커밋합니다. 처음에 대상 테이블에 쓴 스트리밍 데이터는 임시 중간 파일 형식으로 저장됩니다. 이 스테이지에서 테이블은 “혼합 테이블”로 간주되는데, 분할된 데이터가 기본 파일과 중간 파일이 혼합된 형식으로 저장되기 때문입니다. 자동화된 백그라운드 프로세스는 필요에 따라 활동 중인 중간 파일에서 쿼리 및 DML 작업에 최적화된 기본 파일로 데이터를 마이그레이션합니다.
클래식 아키텍처에서의 복제¶
Snowpipe Streaming는 Snowpipe Streaming과 이와 연결된 채널 오프셋으로 채워진 Snowflake 테이블의 복제와 장애 조치 를 지원하는데, 원본 계정에서 다른 리전 에 있는 대상 계정으로, 그리고 여러 클라우드 플랫폼 에 걸쳐 지원합니다.
고성능 아키텍처에는 복제가 지원되지 않습니다.
자세한 내용은 복제 및 Snowpipe Streaming 섹션을 참조하십시오.
Insert-only 작업¶
API 는 현재 행 삽입으로 제한됩니다. 데이터를 수정, 삭제 또는 결합하려면 하나 이상의 스테이징 테이블에 “원시” 레코드를 쓰십시오. 연속 데이터 파이프라인 을 사용하여 데이터를 병합, 조인 또는 변환하여 수정된 데이터를 대상 보고 테이블에 삽입합니다.
클래스 및 인터페이스¶
클래식 아키텍처의 클래스 및 인터페이스에 대한 설명서는 Snowflake Ingest SDK API 를 참조하십시오.
클래식 아키텍처와 고성능 아키텍처의 차이점은 API 차이점 섹션을 참조하십시오.
지원되는 Java 데이터 타입¶
다음 표에는 Snowflake 열로 수집하기 위해 지원되는 Java 데이터 타입이 요약되어 있습니다.
Snowflake 열 유형 |
허용되는 Java 데이터 타입 |
|---|---|
|
|
|
|
|
|
|
|
|
부울 변환 세부 정보 를 참조하십시오. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
필수 액세스 권한¶
Snowpipe Streaming API를 호출하려면 다음 권한이 있는 역할이 필요합니다.
오브젝트 |
권한 |
|---|---|
테이블 |
OWNERSHIP 또는 최소 INSERT 및 EVOLVE SCHEMA(Snowpipe Streaming과 함께 Kafka 커넥터에 대한 스키마 진화를 사용할 때만 필요함) |
데이터베이스 |
USAGE |
스키마 |
USAGE |
파이프 |
OPERATE(고성능 아키텍처에만 필요) |
제한 사항¶
Snowpipe Streaming Classic의 경우 다음 제한 사항에 유의하십시오.
Snowpipe Streaming Classic은 :doc:`2025_03 동작 변경 번들</release-notes/bcr-bundles/2025_03/bcr-1942>`의 일부인 데이터베이스 오브젝트의 최대 크기 제한 증가(VARCHAR, VARIANT, ARRAY, OBJECT의 경우 128MB, BINARY, GEOGRAPHY, GEOMETRY의 경우 64MB)를 지원하지 않습니다.
Fail-safe는 Snowpipe Streaming Classic에서 수집한 데이터가 포함된 테이블을 지원하지 않습니다. 이러한 테이블의 경우 해당 테이블의 장애 조치 작업은 완전히 실패하므로 복구에 장애 조치 기능을 사용할 수 없습니다.
Snowpipe Streaming은 데이터 암호화에 256비트 AES 키 사용만 지원합니다.
자동 클러스터링 이 Snowpipe Streaming이 삽입되는 동일한 테이블에서도 활성화되어 있으면 파일 마이그레이션을 위한 컴퓨팅 비용이 절감될 수 있습니다. 자세한 내용은 Snowpipe Streaming Classic 모범 사례 섹션을 참조하십시오.
다음 오브젝트 또는 유형은 지원되지 않습니다.
GEOGRAPHY 및 GEOMETRY 데이터 타입
데이터 정렬이 포함된 열
TEMPORARY 테이블
테이블당 총 채널 수는 10,000개를 초과할 수 없습니다. 필요한 경우 채널을 재사용하는 것이 좋습니다. 테이블당 10,000개 이상의 채널을 열어야 하는 경우 Snowflake 지원 에 문의하십시오.
고성능 아키텍처는 기존 아키텍처에 비해 다른 고려 사항과 제한 사항이 있습니다. 자세한 내용은 고성능 아키텍처 제한 사항 섹션을 참조하십시오.