AI_PARSE_DOCUMENT を使用したドキュメントの解析¶
AI_PARSE_DOCUMENTは、ドキュメントからテキスト、データ、レイアウト要素、画像を抽出するCortex AI関数です。他の関数と組み合わせて、さまざまなユースケースに対応したカスタムドキュメント処理パイプラインを作成できます( Cortex AI 関数:ドキュメント をご参照ください)。
AI_PARSE_DOCUMENTを使用した画像の抽出に関する情報については、 Cortex AI関数:AI_PARSE_DOCUMENTによるイメージ抽出 をご参照ください。
関数は、内部ステージまたは外部ステージに保存されているドキュメントからテキストとレイアウトを抽出し、テーブルやヘッダーなどの読み取り順序と構造を保持します。ドキュメントの保存に適したステージの作成に関する詳細は、 メディアファイル用ステージを作成する をご参照ください。
AI_PARSE_DOCUMENTはドキュメントの理解とレイアウト分析のための高度なAIモデルをオーケストレーションし、複雑な複数ページのドキュメントを高い忠実性で処理します。
AI_PARSE_DOCUMENT 関数は、PDF ドキュメント処理のために2つのモードを提供します。
LAYOUT モードは、ほとんどのユースケース、特に複雑なドキュメントに適しています。テーブルのようなテキストとレイアウト要素の抽出用に特別に最適化されており、ナレッジベースを構築し、検索システムを最適化し、 AI ベースのアプリケーションを向上させるのに最適なオプションです。
OCR モードは、説明書、契約書、商品詳細ページ、保険ポリシー、請求書や SharePointドキュメント などのドキュメントから迅速で高品質なテキストを抽出するために推奨されます。
両方のモードには、 page_split``オプションを使用して、応答で複数ページのドキュメントを個別のページに分割します。また、 ``page_filter``オプションを使用して、指定されたページのみを処理することもできます。``page_filter を使用している場合、 page_split は暗黙的に設定されるため、明示的に設定する必要はありません。
AI_PARSE_DOCUMENTは水平方向にスケーラブルであり、複数のドキュメントを同時に効率的にバッチ処理できます。ドキュメントは、不要なデータ移動を回避するために、オブジェクトストレージから直接処理できます。
注釈
AI_PARSE_DOCUMENT は現在、カスタム ネットワークポリシー と互換性がありません。
例¶
簡単なレイアウト例¶
This example uses AI_PARSE_DOCUMENT's LAYOUT mode to process a two-column research paper. The page_split parameter
is set to TRUE in order to separate the document into pages in the response. AI_PARSE_DOCUMENT returns the content in Markdown
format. The following shows rendered Markdown for one of the processed pages (page index 4 in the JSON output) next to
the original page. The raw Markdown is shown in the JSON response following the images.
元のドキュメントからのページ |
抽出されたMarkdownは HTML としてレンダリングされました |
|---|---|

|

|
Tip
これらの画像をより読みやすいサイズで表示するには、クリックするか、タップして選択します。
以下は元のドキュメントを処理する SQL コマンドです。
AI_PARSE_DOCUMENT からの応答は、次のようにドキュメントのページのメタデータとテキストを含む JSON オブジェクトです。簡潔にするために、一部のページオブジェクトを省略しています。
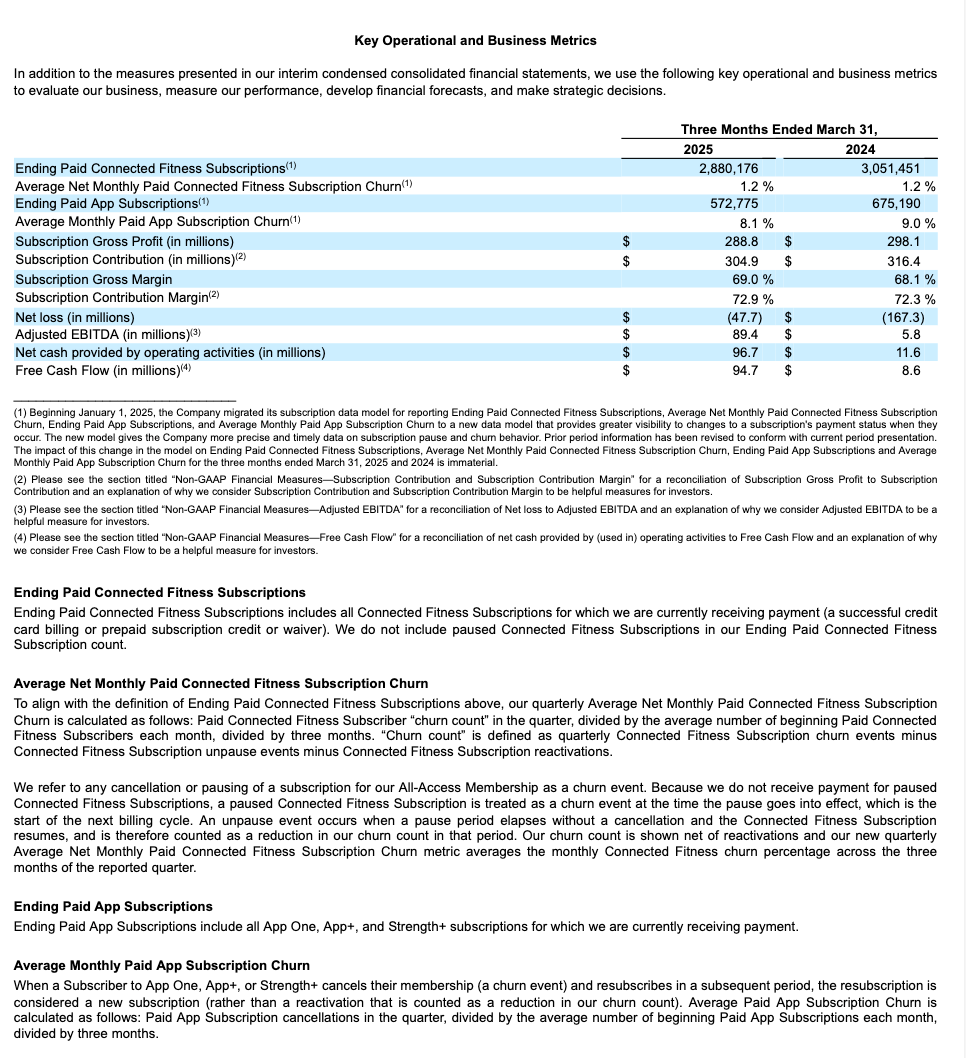
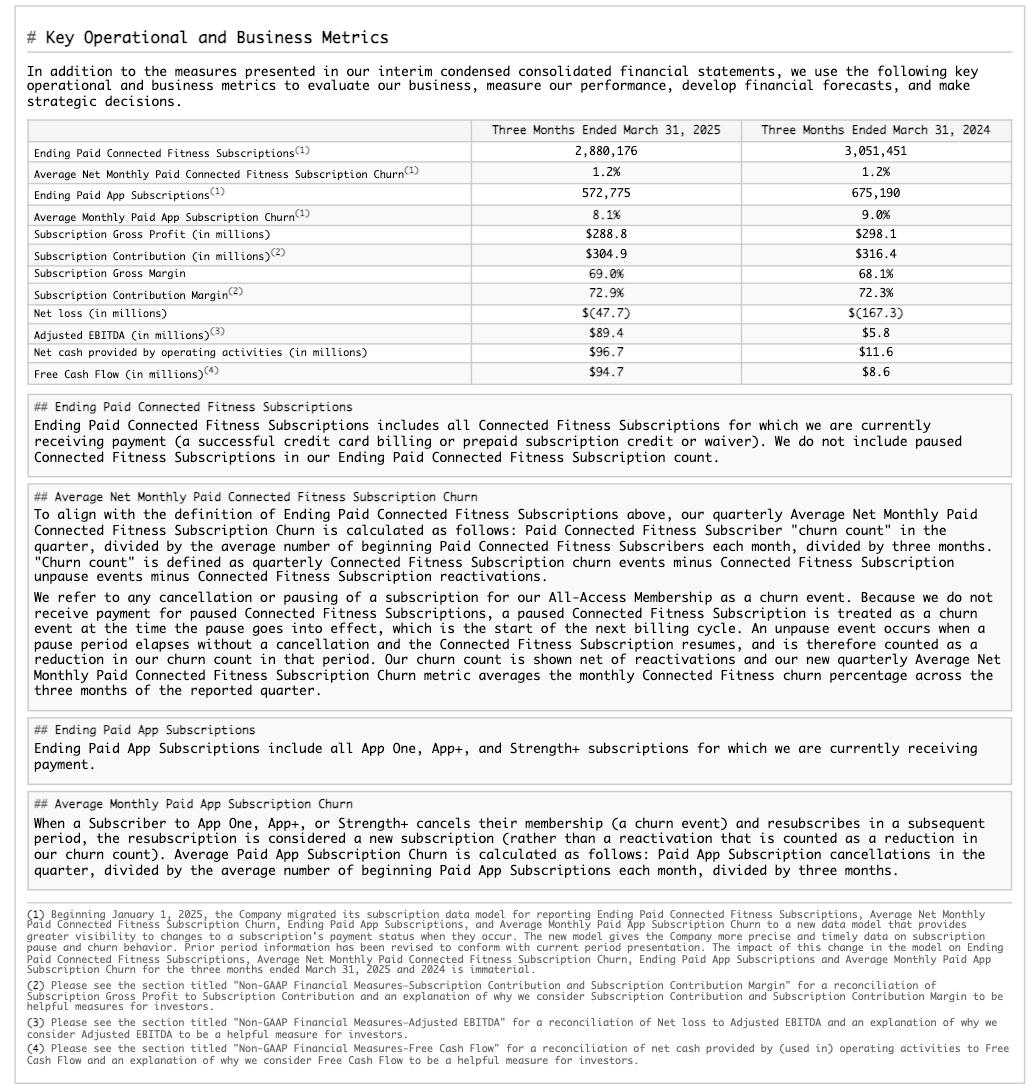
テーブル構造抽出の例¶
この例では、10-K提出書類からテーブルを含む構造レイアウトを抽出しています。以下は、処理されたページの1つのレンダリング結果を示しています(JSON 出力のページインデックス28)。
元のドキュメントからのページ |
抽出されたMarkdownは HTML としてレンダリングされました |
|---|---|
|
|
Tip
これらの画像をより読みやすいサイズで表示するには、クリックするか、タップして選択します。
以下は元のドキュメントを処理する SQL コマンドです。
AI_PARSE_DOCUMENT からの応答は、次のようにドキュメントのページのメタデータとテキストを含む JSON オブジェクトです。以前に表示されたページを除くすべての結果は、簡潔にするために省略されています。
スライドデッキの例¶
この例では、プレゼンテーションから構造レイアウトを抽出します。 以下に、処理されたスライドの1つのレンダリング結果を示します(JSON 出力のページインデックス17)。
元のドキュメントからのスライド |
抽出されたMarkdownは HTML としてレンダリングされました |
|---|---|

|

|
Tip
これらの画像をより読みやすいサイズで表示するには、クリックするか、タップして選択します。
以下は元のドキュメントを処理する SQL コマンドです。
AI_PARSE_DOCUMENT からの応答は、次のようにプレゼンテーションのスライドのメタデータとテキストを含む JSON オブジェクトです。一部のスライドの結果は、簡潔にするために省略されています。
多言語ドキュメントの例¶
この例では、ドイツ語の記事から構造レイアウトを抽出することで、 AI_PARSE_DOCUMENT の多言語対応力を示しています。AI_PARSE_DOCUMENT は、画像や引用符が存在する場合でも、本文の読み取り順序を保持します。
元のドキュメントからのページ |
抽出されたMarkdownは HTML としてレンダリングされました |
|---|---|

|

|
Tip
これらの画像をより読みやすいサイズで表示するには、クリックするか、タップして選択します。
以下は元のドキュメントを処理する SQL コマンドです。ドキュメントは単一のページであるため、この例ではページ分割は必要ありません。
AI_PARSE_DOCUMENT からの応答は、次のようにドキュメントのメタデータとテキストを含む JSON オブジェクトです。
Snowflake Cortexは、サポートされている言語(この場合は英語、言語コード 'en')への翻訳を生成できます。
翻訳は次のとおりです。
OCR モードの使用¶
OCR モードは、スクリーンショットやテキスト画像を含む PDFs などのスキャンされたドキュメントからテキストを抽出します。レイアウトは保持されません。
出力:
ドキュメントの特定ページのみの処理¶
This example demonstrates using the page_filter option to extract specific pages from a document, specifically
the first page of a 55-page research paper. Keep in mind that page indexes starts at 0 and ranges are inclusive of
the start value but exclusive of the end value. For example, start: 0, end: 1 returns only the first page (index 0).
結果:
複数のドキュメントの分類¶
複数のドキュメントを分類するには、まずディレクトリからドキュメントの場所を取得して、ファイルのテーブルを作成し、これらの場所をFILEオブジェクトに変換します。
次にAI_PARSE_DOCUMENTをテーブルの各ドキュメントに適用し、たとえばAI_CLASSIFYに渡してタイプ別にドキュメントを分類するなどして、結果を処理します。これは、ドキュメントコレクションのバッチドキュメント分析に対する効率的なアプローチです。
クエリは、各ドキュメントの分類ラベルを返します。
入力要件¶
AI_PARSE_DOCUMENT はデジタル作成およびスキャン済みドキュメントの両方に最適化されています。次のテーブルは、入力ドキュメントの制限と要件のリストです。
最大ファイルサイズ |
100 MB |
|---|---|
1ドキュメントあたりの最大ページ数 |
500 |
最大ページ解像度 |
|
サポートされているファイルタイプ |
PDF 、 PPTX 、 DOCX 、 JPEG 、 JPG 、 PNG 、 TIFF 、 TIF 、 HTML 、 TXT |
ステージ暗号化 |
サーバー側の暗号化 |
文字サイズ |
最良の結果を得るには8ポイント以上 |
サポートされるドキュメントの機能と制限¶
ページオリエンテーション |
AI_PARSE_DOCUMENT は自動的にページオリエンテーションを検出します。 |
|---|---|
ページ分割 |
AI_PARSE_DOCUMENTは、複数ページのドキュメントを個々のページに分割し、それぞれを個別に解析します。これは、最大サイズを超える大きなドキュメントを処理するのに便利です。 |
ページのフィルタリング |
AI_PARSE_DOCUMENTは、ページ範囲を指定することにより、ドキュメント内のすべてのページではなく、一部のページを処理できます。これは、探している情報がどのページにあるかがわかっている場合に役立ちます。 |
文字 |
AI_PARSE_DOCUMENT は以下の文字を検出します。
|
画像 |
AI_PARSE_DOCUMENT はドキュメント内の画像のマークアップを生成しますが、現在実際の画像は抽出しません。 |
構造化要素 |
AI_PARSE_DOCUMENT は自動的にテーブルとフォームを検出して抽出します。 |
フォント |
AI_PARSE_DOCUMENT は、ほとんどのセリフおよびサンセリフフォントのテキストを認識しますが、装飾やスクリプトフォントでは難しい場合があります。機能はハンドを認識しません。 |
サポートされている言語¶
AI_PARSE_DOCUMENT は以下の言語でトレーニングされます。
OCR モード |
LAYOUT モード |
|---|---|
|
|
リージョンの可用性¶
AI_PARSE_DOCUMENT のサポートは、以下のSnowflakeリージョンのアカウントで利用可能です。
AWS |
Azure |
Google Cloud Platform |
|---|---|---|
US 西部2(オレゴン州) |
東 US 2(バージニア) |
US 中央部1(アイオワ) |
US 東部(オハイオ) |
西 US 2(ワシントン) |
|
US 東部1(北部バージニア) |
ヨーロッパ (オランダ) |
|
ヨーロッパ(アイルランド) |
||
ヨーロッパ中部1(フランクフルト) |
||
Europe West 2 (London) |
||
アジア太平洋(シドニー) |
||
アジア太平洋(東京) |
AI_PARSE_DOCUMENTは、他のSnowflakeリージョンのクロスリージョンサポートがあります。Cortex AI クロスリージョンのサポートの有効化については、 クロスリージョン推論 をご参照ください。
アクセス制御の要件¶
さらに、 AI_PARSE_DOCUMENT 関数を使用するには、 ACCOUNTADMIN ロールは、 SNOWFLAKE.CORTEX_USER データベースロールを関数を呼び出せるユーザーに付与する必要があります。詳細については Cortex LLM 権限 をご参照ください。
コストの考慮事項¶
Cortex AI_PARSE_DOCUMENT関数では、処理されるドキュメントごとのページ数に応じて計算コストが発生します。以下は、ファイル形式別のページ数のカウント方法について説明したものです。
ページ化されたファイル形式の場合(PDF 、 DOCX)、ドキュメントの各ページはページごとに請求されます。
画像ファイル形式 (JPEG, JPG, TIF, TIFF, PNG) の場合、個々の画像ファイルは1ページとして請求されます。
HTML および TXT ファイルの場合、3,000文字の各チャンクは、最後のチャンク(3,000文字未満になる場合があります)も含めて1ページとして課金されます。
Snowflake は、Cortex AI_PARSE_DOCUMENT 関数を呼び出すクエリを、小規模なウェアハウス(MEDIUM 以下)で実行することを推奨しています。ウェアハウスが大きくなってもパフォーマンスは向上しません。
エラー条件¶
Snowflake Cortex AI_PARSE_DOCUMENT は以下のエラーメッセージを生成する可能性があります。
メッセージ |
説明 |
|---|---|
|
入力ドキュメントにサポートされていない言語が含まれています。 |
|
ドキュメントがサポートされていない形式です。 |
|
ファイル形式はサポートされておらず、バイナリファイルとして理解されます。 |
|
ドキュメントが500ページの制限を超えています。 |
|
画像入力または変換されたドキュメントページが、サポートされているディメンションよりも大きいです。 |
|
ページがサポートされているディメンションよりも大きいです。 |
|
ドキュメントが100 MB を超えています。 |
|
ファイルが存在しない。 |
|
権限が不十分なため、ファイルにアクセスできません。 |
|
タイムアウトが発生しました。 |
|
システムエラーが発生しました。待って、もう一度お試しください。 |
法的通知¶
インプットとアウトプットのデータ分類は以下の表の通りです。
入力データの分類 |
出力データの分類 |
指定 |
|---|---|---|
Usage Data |
Customer Data |
一般的に利用可能な関数は、カバーされている AI 機能です。プレビュー関数は、 AI 機能をプレビューします。[1] |
詳細については、 Snowflake AI と ML をご参照ください。