Parsen von -Dokumenten mit AI_PARSE_DOCUMENT¶
AI_PARSE_DOCUMENT ist eine Cortex AI-Funktion, die Text, Daten, Layout-Elemente und Bilder aus Dokumenten extrahiert. Sie kann zusammen mit anderen Funktionen verwendet werden, um kundenspezifische Dokumentenverarbeitungspipelines für eine Vielzahl von Anwendungsfällen zu erstellen (siehe Cortex AI-Funktionen: Dokumente).
Weitere Informationen zur Verwendung von AI_PARSE_DOCUMENT um Bilder zu extrahieren, finden Sie zusammen mit Beispielen unter Cortex AI-Funktionen: Image-Extraktion mit AI_PARSE_DOCUMENT.
Die Funktion extrahiert Text und Layout aus Dokumenten, die in internen oder externen Stagingbereichen gespeichert sind, und behält die Lesereihenfolge und Strukturen wie Tabellen und Überschriften bei. Informationen zum Erstellen eines Stagingbereichs, der für die Speicherung von Dokumenten geeignet ist, finden Sie unter Stagingbereich für Mediendateien erstellen.
AI_PARSE_DOCUMENT orchestriert fortgeschrittene AI-Modelle für das Verständnis von Dokumenten und die Analyse von Layouts. Dabei werden komplexe mehrseitige Dokumente mit hoher Genauigkeit verarbeitet.
Die Funktion AI_PARSE_DOCUMENT bietet zwei Modi für die Verarbeitung von PDF-Dokumenten:
Der LAYOUT-Modus ist die bevorzugte Wahl für die meisten Anwendungsfälle, insbesondere bei komplexen Dokumenten. Der Modus ist speziell für das Extrahieren von Text und Layoutelementen wie Tabellen optimiert, was ihn zur besten Option für den Aufbau von Wissensdatenbanken, die Optimierung von Abrufsystemen und die Verbesserung AI-basierter Anwendungen macht.
Der OCR-Modus wird für eine schnelle, hochwertige Textextraktion aus Dokumenten wie Handbüchern, Vereinbarungen oder Verträgen, Produktdetailseiten, Versicherungspolicen und -ansprüchen sowie SharePoint-Dokumenten empfohlen.
Verwenden Sie für beide Modi die Option page_split, um mehrseitige Dokumente in der Antwort in separate Seiten aufzuteilen. Sie können auch die Option page_filter verwenden, um nur bestimmte Seiten zu verarbeiten. (Bei Verwendung von page_filter ist page_split impliziert, das heißt, Sie müssen dies nicht explizit festlegen.)
AI_PARSE_DOCUMENT ist horizontal skalierbar und ermöglicht eine effiziente Batch-Verarbeitung mehrere Dokumente gleichzeitig. Dokumente können direkt aus dem Objektspeicher verarbeitet werden, um unnötige Datenbewegungen zu vermeiden.
Bemerkung
AI_PARSE_DOCUMENT ist derzeit nicht mit den benutzerdefinierten von Netzwerkrichtlinien kompatibel.
Beispiele¶
Einfaches Layoutbeispiel¶
This example uses AI_PARSE_DOCUMENT’s LAYOUT mode to process a two-column research paper. The page_split parameter
is set to TRUE in order to separate the document into pages in the response. AI_PARSE_DOCUMENT returns the content in Markdown
format. The following shows rendered Markdown for one of the processed pages (page index 4 in the JSON output) next to
the original page. The raw Markdown is shown in the JSON response following the images.
Seite aus dem ursprünglichen Dokument |
Extrahiertes Markdown, gerendert als HTML |
|---|---|

|

|
Tipp
Um eines dieser Bilder in einer besser lesbaren Größe anzuzeigen, wählen Sie es durch Klicken oder Tippen aus.
Im Folgenden sehen Sie den SQL-Befehl zur Verarbeitung des ursprünglichen Dokuments:
Die Antwort von AI_PARSE_DOCUMENT ist ein JSON-Objekt, das Metadaten und Text von den Seiten des Dokuments enthält, wie im Folgenden. Einige Objekte der Seite wurden der Kürze halber weggelassen.
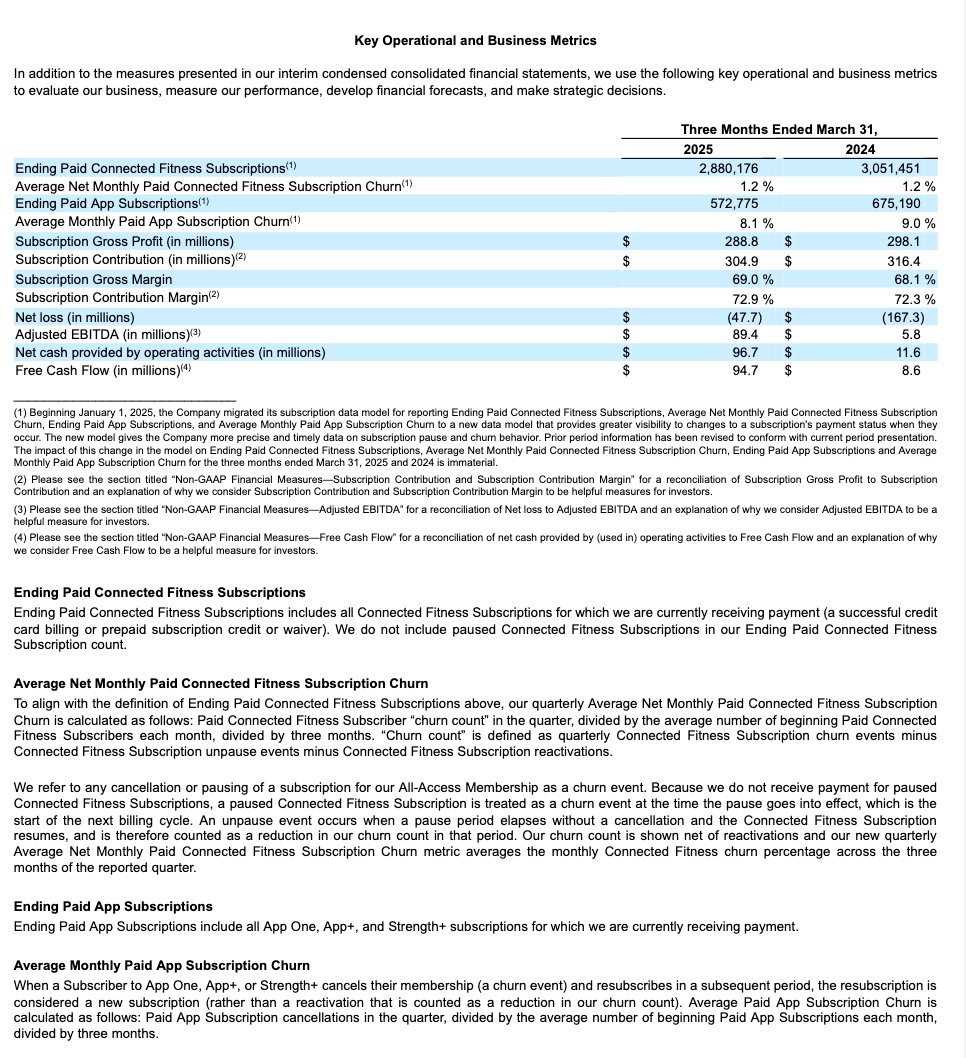
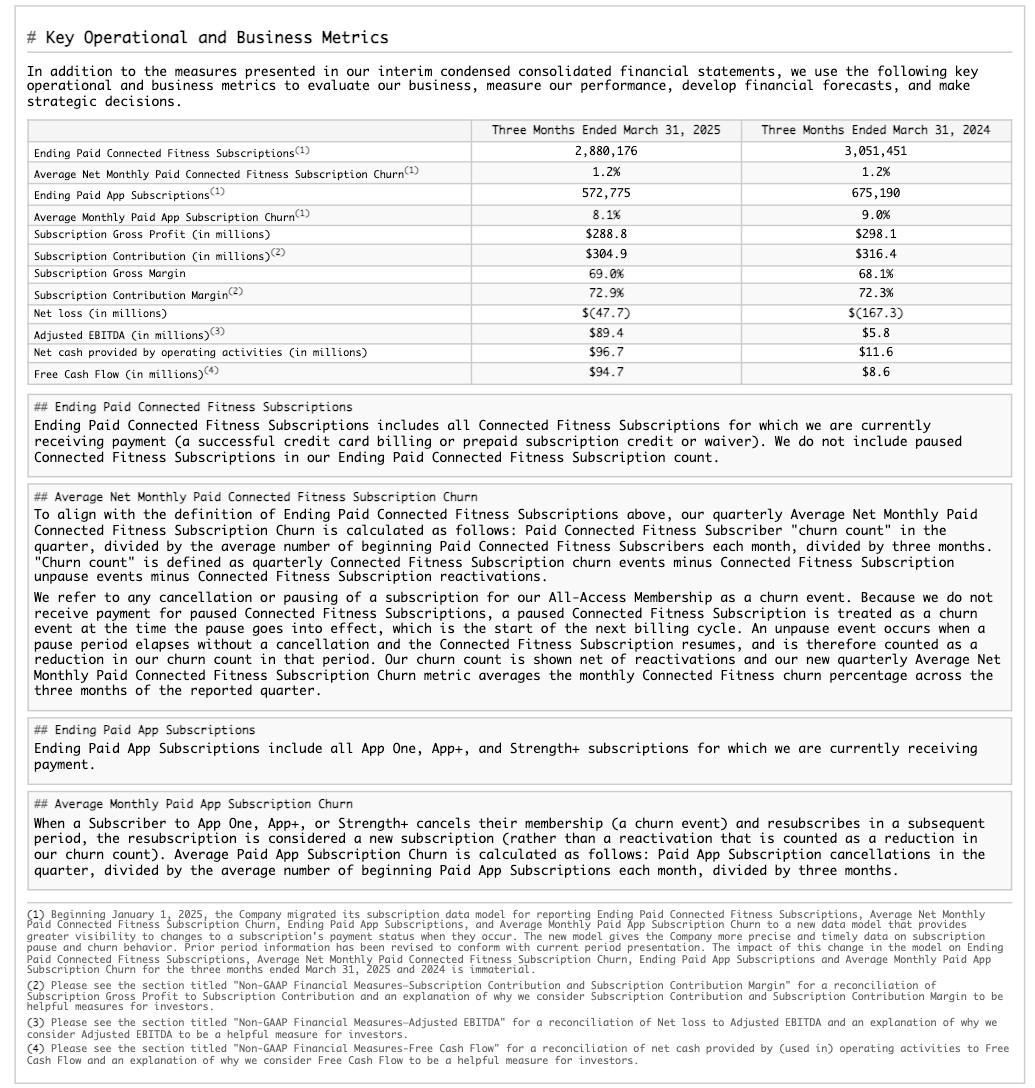
Beispiel für das Extrahieren einer Tabellenstruktur¶
Dieses Beispiel zeigt das Extrahieren eines strukturellen Layouts, einschließlich einer Tabelle, aus einem 10-K-Bericht. Im Folgenden werden die gerenderten Ergebnisse für eine der verarbeiteten Seiten angezeigt (Seitenindex 28 in der JSON-Ausgabe).
Seite aus dem ursprünglichen Dokument |
Extrahiertes Markdown, gerendert als HTML |
|---|---|
|
|
Tipp
Um eines dieser Bilder in einer besser lesbaren Größe anzuzeigen, wählen Sie es durch Klicken oder Tippen aus.
Im Folgenden sehen Sie den SQL-Befehl zur Verarbeitung des ursprünglichen Dokuments:
Die Antwort von AI_PARSE_DOCUMENT ist ein JSON-Objekt, das Metadaten und Text von den Seiten des Dokuments enthält, wie im Folgenden. Die Ergebnisse für alle bis auf die zuvor gezeigte Seite wurden der Kürze halber weggelassen.
Beispiel für eine Präsentation¶
Dieses Beispiel zeigt das Extrahieren eines strukturellen Layouts aus einer Präsentation. Unten sehen Sie die gerenderten Ergebnisse für eine der verarbeiteten Folien (Seitenindex 17 in der JSON-Ausgabe).
Folie aus dem ursprünglichen Dokument |
Extrahiertes Markdown, gerendert als HTML |
|---|---|

|

|
Tipp
Um eines dieser Bilder in einer besser lesbaren Größe anzuzeigen, wählen Sie es durch Klicken oder Tippen aus.
Im Folgenden sehen Sie den SQL-Befehl zur Verarbeitung des ursprünglichen Dokuments:
Die Antwort von AI_PARSE_DOCUMENT ist ein JSON-Objekt, das Metadaten und den Text aus den Folien der Präsentationen enthält, wie im Folgenden. Die Ergebnisse einiger Folien wurden der Kürze halber weggelassen.
Beispiel für ein mehrsprachiges Dokument¶
Dieses Beispiel zeigt die AI_PARSE_DOCUMENT-Funktionen zur Mehrsprachigkeit, indem das strukturelle Layout aus einem deutschen Artikel extrahiert wird. AI_PARSE_DOCUMENT behält die Lesereihenfolge des Haupttextes bei, auch wenn Bilder und Zitate vorhanden sind.
Seite aus dem ursprünglichen Dokument |
Extrahiertes Markdown, gerendert als HTML |
|---|---|

|

|
Tipp
Um eines dieser Bilder in einer besser lesbaren Größe anzuzeigen, wählen Sie es durch Klicken oder Tippen aus.
Im Folgenden sehen Sie den SQL-Befehl zur Verarbeitung des ursprünglichen Dokuments. Da das Dokument eine einzige Seite hat, ist für dieses Beispiel keine Seitenaufteilung erforderlich.
Die Antwort von AI_PARSE_DOCUMENT ist ein JSON-Objekt, das Metadaten und den Text aus dem Dokument enthält, wie im Folgenden.
Snowflake Cortex kann wie folgt eine Übersetzung in jede unterstützte Sprache (in diesem Fall Englisch, Sprachcode 'en') generieren:
Die Übersetzung lautet wie folgt:
Verwenden des OCR-Modus¶
Der OCR-Modus extrahiert Text aus gescannten Dokumenten, wie z. B. Screenshots oder PDFs mit Bildern des Textes. Das Layout wird nicht beibehalten.
Ausgabe:
Nur bestimmte Seiten eines Dokuments verarbeiten¶
This example demonstrates using the page_filter option to extract specific pages from a document, specifically
the first page of a 55-page research paper. Keep in mind that page indexes starts at 0 and ranges are inclusive of
the start value but exclusive of the end value. For example, start: 0, end: 1 returns only the first page (index 0).
Ergebnis:
Mehrere Dokumente klassifizieren¶
Um mehrere Dokumente zu klassifizieren, erstellen Sie zuerst eine Tabelle mit den Dateien, indem Sie die Speicherorte der Dokumente aus einem Verzeichnis abrufen und diese Speicherorte in FILE-Objekte konvertieren.
Wenden Sie dann AI_PARSE_DOCUMENT auf jedes Dokument in der Tabelle an, und verarbeiten Sie die Ergebnisse, indem Sie sie zum Beispiel an AI_CLASSIFY übergeben, um die Dokumente nach Typ zu kategorisieren. Dies ist ein effizienter Ansatz zur Batch-Dokumentenanalyse in einer Dokumentensammlung.
Die Abfrage gibt Klassifizierungslabel für jedes Dokument zurück.
Eingabeanforderungen¶
AI_PARSE_DOCUMENT ist sowohl für digital erstellte als auch für gescannte Dokumente optimiert. In der folgenden Tabelle sind die Beschränkungen und Anforderungen für Eingabedokumente aufgeführt:
Maximale Dateigröße |
100 MB |
|---|---|
Maximale Seitenzahl pro Dokument |
500 |
Maximale Seitenauflösung |
|
Unterstützte Dateitypen |
PDF, PPTX, DOCX, JPEG, JPG, PNG, TIFF, TIF, HTML, TXT |
Stagingbereich-Verschlüsselung |
Serverseitige Verschlüsselung: |
Schriftgröße |
8 Punkte oder größer für beste Ergebnisse |
Unterstützte Dokumentenfeatures und Einschränkungen¶
Seitenausrichtung |
AI_PARSE_DOCUMENT erkennt automatisch die Seitenausrichtung. |
|---|---|
Seitenaufteilung |
AI_PARSE_DOCUMENT kann mehrseitige Dokumente in einzelne Seiten aufteilen und jede separat analysieren. Dies ist nützlich bei der Verarbeitung großer Dokumente, die die maximal Größe überschreiten. |
Filtern von Seiten |
AI_PARSE_DOCUMENT kann einige der Seiten eines Dokuments – anstatt alle – verarbeiten, indem Seitenbereiche angegeben werden. Dies ist nützlich, wenn Sie wissen, auf welchen Seiten sich die Informationen befinden, nach denen Sie suchen. |
Zeichen |
AI_PARSE_DOCUMENT erkennt die folgenden Zeichen:
|
Bilder |
AI_PARSE_DOCUMENT generiert Markup für Bilder im Dokument, extrahiert aber derzeit nicht die eigentlichen Bilder. |
Strukturierte Elemente |
AI_PARSE_DOCUMENT erkennt und extrahiert Tabellen und Formulare automatisch. |
Schriftarten |
AI_PARSE_DOCUMENT erkennt Text in den meisten Serifen- und serifenlosen Schriftarten, kann jedoch Schwierigkeiten mit dekorativen oder Schreibschriftarten haben. Die Funktion erkennt keine Handschrift. |
Unterstützte Sprachen¶
AI_PARSE_DOCUMENT ist für die folgenden Sprachen trainiert:
OCR-Modus |
LAYOUT-Modus |
|---|---|
|
|
Regionale Verfügbarkeit¶
Unterstützung für AI_PARSE_DOCUMENT ist für Konten in den folgenden Snowflake-Regionen verfügbar:
AWS |
Azure |
Google Cloud Platform |
|---|---|---|
US West 2 (Oregon) |
East US 2 (Virginia) |
US Central 1 (Iowa) |
US East (Ohio) |
West US 2 (Washington) |
|
US East 1 (N. Virginia) |
Europa (Niederlande) |
|
Europa (Irland) |
||
Europe Central 1 (Frankfurt) |
||
Europe West 2 (London) |
||
Asia Pacific (Sydney) |
||
Asia Pacific (Tokio) |
AI_PARSE_DOCUMENT bietet regionsübergreifende Unterstützung in anderen Snowflake-Regionen. Weitere Informationen zur Aktivierung der regionenübergreifenden Unterstützung von Cortex AI finden Sie unter Regionenübergreifende Inferenz.
Anforderungen an die Zugriffssteuerung¶
Um die Funktion AI_PARSE_DOCUMENT zu verwenden, muss ein Benutzer mit der Rolle ACCOUNTADMIN dem Benutzer, der die Funktion aufruft, die Datenbankrolle SNOWFLAKE.CORTEX_USER erteilen. Siehe Cortex LLM-Berechtigungen für weitere Informationen.
Hinweise zu Kosten¶
Bei der Cortex-Funktion AI_PARSE_DOCUMENT fallen Rechenkosten an, die sich nach der Anzahl der verarbeiteten Seiten pro Dokument richten. Im Folgenden wird beschrieben, wie Seiten für verschiedene Dateiformate gezählt werden:
Für Seitendateiformate (PDF, DOCX) wird jede Seite im Dokument als Seite abgerechnet.
Bei Bilddateiformaten (JPEG, JPG, TIF, TIFF, PNG) wird jede einzelne Bilddatei als eine Seite abgerechnet.
Bei HTML- und TXT-Dateien wird jeder Block mit 3.000 Zeichen als eine Seite abgerechnet, einschließlich des letzten Blocks, der weniger als 3.000 Zeichen lang sein kann.
Snowflake empfiehlt die Ausführung von Abfragen, die die Cortex-Funktion AI_PARSE_DOCUMENT aufrufen, in einem kleineren Warehouse (nicht größer als MEDIUM). Größere Warehouses erhöhen die Leistung nicht.
Fehlerbedingungen¶
Snowflake Cortex AI_PARSE_DOCUMENT kann die folgenden Fehlermeldungen erzeugen:
Meldung |
Erläuterung |
|---|---|
|
Das Eingabedokument enthält eine nicht unterstützte Sprache. |
|
Das Dokument hat ein nicht unterstütztes Format. |
|
Das Dateiformat wird nicht unterstützt und wird als Binärdatei betrachtet. |
|
Das Dokument überschreitet das Limit von 500 Seiten. |
|
Ein eingegebenes Bild oder eine konvertierte Dokumentseite ist größer als die unterstützten Abmessungen. |
|
Die Seite ist größer als die unterstützten Abmessungen. |
|
Das Dokument ist größer als 100 MB. |
|
Die Datei ist nicht vorhanden. |
|
Auf die Datei kann aufgrund unzureichender Berechtigungen nicht zugegriffen werden. |
|
Timeout aufgetreten. |
|
Es ist ein Systemfehler aufgetreten. Warten Sie und versuchen Sie es erneut. |
Rechtliche Hinweise¶
Die Datenklassifizierung der Eingaben und Ausgaben ist in der folgenden Tabelle aufgeführt.
Klassifizierung von Eingabedaten |
Klassifizierung von Ausgabedaten |
Benennung |
|---|---|---|
Usage Data |
Customer Data |
Die allgemein verfügbaren Funktionen sind abgedeckte AI-Features. Die Vorschaufunktionen sind Vorschau-AI-Features. [1] |
Weitere Informationen dazu finden Sie unter KI und ML in Snowflake.