Análise de documentos com AI_PARSE_DOCUMENT¶
AI_PARSE_DOCUMENT é uma função do Cortex AI que extrai texto, dados, elementos de layout e imagens de documentos. Ela pode ser usada com outras funções para criar pipelines de processamento de documentos personalizados para uma variedade de casos de uso (consulte Cortex AI Functions: documentos).
Para obter informações, com exemplos, sobre como usar AI_PARSE_DOCUMENT para extrair imagens, consulte Cortex AI Functions: extração de imagens com AI_PARSE_DOCUMENT.
A função extrai texto e layout de documentos armazenados em áreas de preparação internas ou externas e preserva a ordem de leitura e as estruturas, como tabelas e cabeçalhos. Para obter informações sobre como criar uma área de preparação adequada para armazenar documentos, consulte Criar área de preparação para arquivos de mídia.
A AI_PARSE_DOCUMENT orquestra os modelos de AI avançados para compreensão de documentos e análise de layout e processa documentos complexos de várias páginas com alta fidelidade.
A função AI_PARSE_DOCUMENT oferece dois modos para processamento de documentos PDF:
O modo LAYOUT é a escolha preferida na maioria dos casos de uso, especialmente para documentos complexos. Ele é especificamente otimizado para extrair texto e elementos de layout, como tabelas, o que faz dele a melhor opção para construir bases de conhecimento, otimizar sistemas de recuperação e aprimorar aplicativos baseados em AI.
O modo OCR é recomendado para extração de texto rápida e de alta qualidade de documentos como manuais, acordos ou contratos, páginas de detalhes de produtos, políticas e reivindicações de seguros e documentos do SharePoint.
Para ambos os modos, use a opção page_split para dividir documentos de várias páginas em páginas separadas na resposta. Você também pode usar a opção page_filter para processar apenas as páginas especificadas. Se estiver usando page_filter, page_split estará implícita, e não será necessário defini-la explicitamente.
AI_PARSE_DOCUMENT é horizontalmente escalável, permitindo o processamento em lote eficiente de vários documentos simultaneamente. Os documentos podem ser processados diretamente do armazenamento de objetos para evitar movimentação desnecessária de dados.
Nota
AI_PARSE_DOCUMENT é atualmente incompatível com políticas de rede personalizadas.
Exemplos¶
Exemplo de layout simples¶
This example uses AI_PARSE_DOCUMENT’s LAYOUT mode to process a two-column research paper. The page_split parameter
is set to TRUE in order to separate the document into pages in the response. AI_PARSE_DOCUMENT returns the content in Markdown
format. The following shows rendered Markdown for one of the processed pages (page index 4 in the JSON output) next to
the original page. The raw Markdown is shown in the JSON response following the images.
Página do documento original |
Markdown extraído e renderizado como HTML |
|---|---|

|

|
Dica
Para visualizar uma dessas imagens em um tamanho mais legível, clique ou toque para selecioná-la.
O comando SQL a seguir processa o documento original:
A resposta da AI_PARSE_DOCUMENT é um objeto JSON com metadados e texto das páginas do documento, conforme mostrado a seguir. Alguns objetos da página foram omitidos para brevidade.
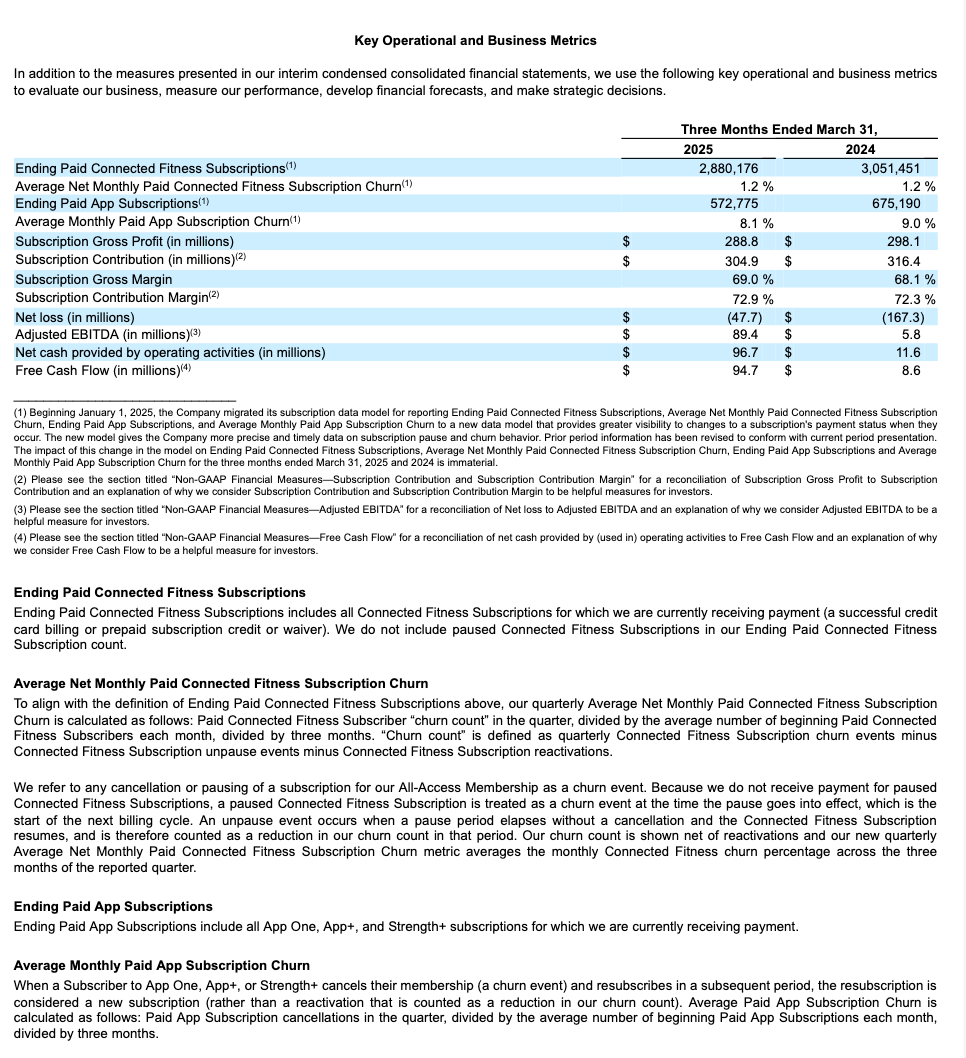
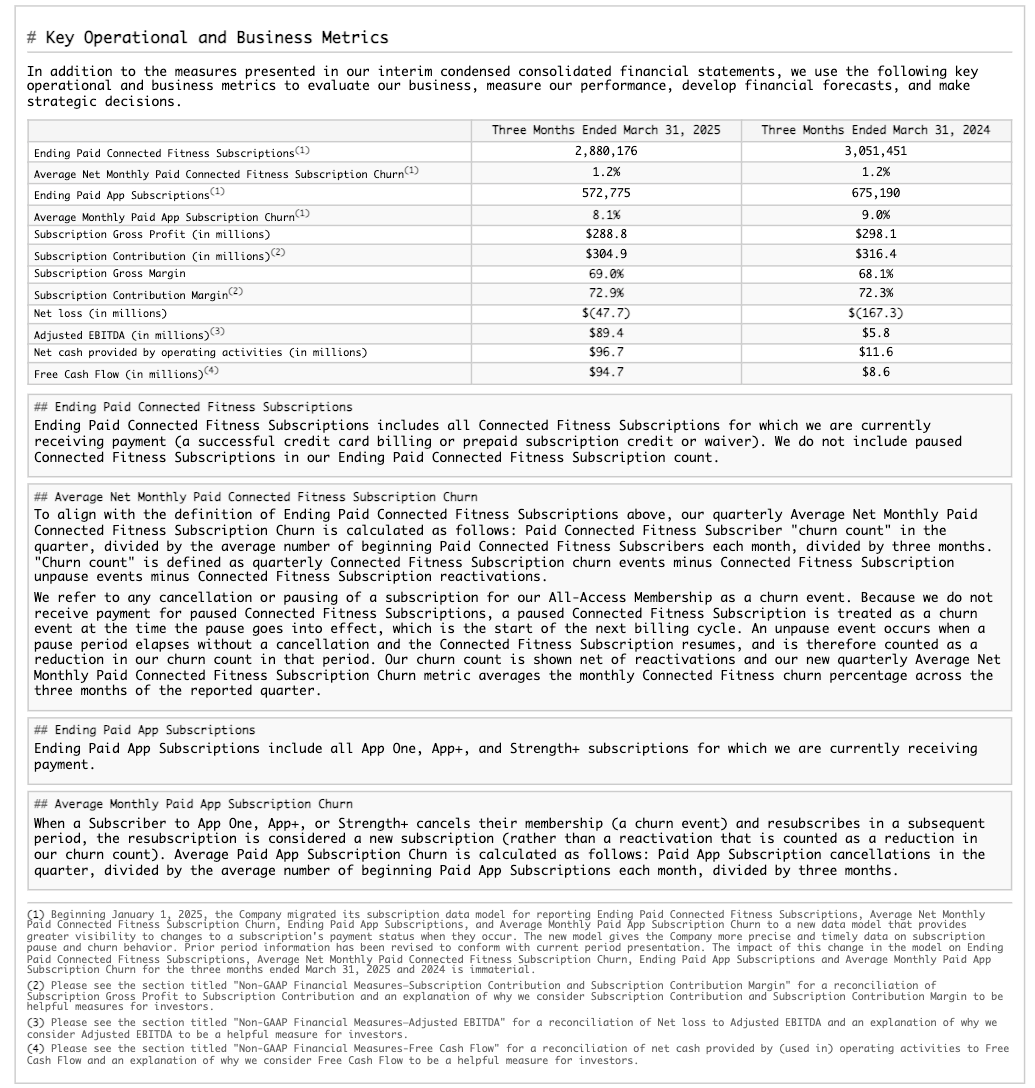
Exemplo de extração da estrutura da tabela¶
Este exemplo demonstra a extração do layout estrutural, incluindo uma tabela, de um relatório 10-K. Veja a seguir os resultados renderizados de uma das páginas processadas (índice de página 28 na saída JSON).
Página do documento original |
Markdown extraído e renderizado como HTML |
|---|---|
|
|
Dica
Para visualizar uma dessas imagens em um tamanho mais legível, clique ou toque para selecioná-la.
O comando SQL a seguir processa o documento original:
A resposta da AI_PARSE_DOCUMENT é um objeto JSON com metadados e texto das páginas do documento, conforme mostrado a seguir. Os resultados de todas as páginas, exceto a que foi mostrada, foram omitidos para brevidade.
Exemplo de conjunto de slides¶
Este exemplo demonstra a extração do layout estrutural de uma apresentação. Mostramos a seguir os resultados renderizados de um dos slides processados (índice de página 17 na saída JSON).
Slide do documento original |
Markdown extraído e renderizado como HTML |
|---|---|

|

|
Dica
Para visualizar uma dessas imagens em um tamanho mais legível, clique ou toque para selecioná-la.
O comando SQL a seguir processa o documento original:
A resposta da AI_PARSE_DOCUMENT é um objeto JSON com metadados e texto dos slides da apresentação, conforme mostrado a seguir. Os resultados de alguns slides foram omitidos para brevidade.
Exemplo de documento multilíngue¶
Este exemplo demonstra os recursos multilíngues da AI_PARSE_DOCUMENTextraindo o layout estrutural de um artigo alemão. A AI_PARSE_DOCUMENT preserva a ordem de leitura do texto principal mesmo quando há imagens e citações.
Página do documento original |
Markdown extraído e renderizado como HTML |
|---|---|

|

|
Dica
Para visualizar uma dessas imagens em um tamanho mais legível, clique ou toque para selecioná-la.
O comando SQL a seguir processa o documento original. Como o documento tem uma única página, você não precisa de divisão neste exemplo.
A resposta da AI_PARSE_DOCUMENT é um objeto JSON com metadados e texto do documento, conforme mostrado a seguir.
O Snowflake Cortex pode traduzir para qualquer idioma com suporte (inglês, código do idioma 'en', neste caso) da seguinte forma:
A tradução é a seguinte:
Uso do modo OCR¶
O modo OCR extrai texto de documentos digitalizados, como capturas de tela ou PDFs com imagens de texto. Ele não preserva o layout.
Saída:
Processamento apenas de determinadas páginas de um documento¶
This example demonstrates using the page_filter option to extract specific pages from a document, specifically
the first page of a 55-page research paper. Keep in mind that page indexes starts at 0 and ranges are inclusive of
the start value but exclusive of the end value. For example, start: 0, end: 1 returns only the first page (index 0).
Resultado:
Classificação de vários documentos¶
Para classificar vários documentos, primeiro crie uma tabela dos arquivos recuperando os locais dos documentos de um diretório, convertendo esses locais em objetos FILE.
Em seguida, aplique AI_PARSE_DOCUMENT para cada documento na tabela e processa os resultados, por exemplo, passando-os para AI_CLASSIFY a fim de categorizar os documentos por tipo. Essa é uma abordagem eficiente para análise de documentos em lote em uma coleção de documentos.
A consulta retorna rótulos de classificação para cada documento.
Requisitos de entrada¶
A AI_PARSE_DOCUMENT é otimizada para documentos originalmente digitais e que foram digitalizados. A seguinte tabela lista as limitações e os requisitos dos documentos de entrada:
Tamanho máximo do arquivo |
100 MB |
|---|---|
Máximo de páginas por documento |
500 |
Resolução máxima de página |
|
Tipos de arquivos compatíveis |
PDF, PPTX, DOCX, JPEG, JPG, PNG, TIFF, TIF, HTML, TXT |
Criptografia de estágio |
Criptografia do lado do servidor |
Tamanho da fonte |
8 pontos ou mais para melhores resultados |
Recursos e limitações dos documentos compatíveis¶
Orientação da página |
AI_PARSE_DOCUMENT detecta automaticamente a orientação da página. |
|---|---|
Divisão de página |
AI_PARSE_DOCUMENT pode dividir documentos de várias páginas em páginas individuais e analisar cada um separadamente. Isso é útil para processar documentos grandes que excedam o tamanho máximo. |
Filtragem de página |
AI_PARSE_DOCUMENT pode processar algumas das páginas em um documento, em vez de todas elas, especificando intervalos de páginas. Isso é útil quando você sabe em quais páginas as informações que você está procurando estão. |
Caracteres |
AI_PARSE_DOCUMENT detecta os seguintes caracteres:
|
Imagens |
A AI_PARSE_DOCUMENT gera uma marcação para imagens no documento, mas não extrai as imagens reais no momento. |
Elementos estruturados |
A AI_PARSE_DOCUMENT detecta e extrai automaticamente tabelas e formulários. |
Fontes |
A AI_PARSE_DOCUMENT reconhece texto na maioria das fontes serif e sans-serif, mas pode ter dificuldade com fontes decorativas ou script. A função não reconhece escrita à mão. |
Linguagens compatíveis¶
A AI_PARSE_DOCUMENT foi treinada para os seguintes idiomas:
Modo OCR |
Modo LAYOUT |
|---|---|
|
|
Disponibilidade regional¶
O suporte para AI_PARSE_DOCUMENT está disponível para contas nas seguintes regiões Snowflake:
AWS |
Azure |
Google Cloud Platform |
|---|---|---|
US West 2 (Oregon) |
East US 2 (Virginia) |
US Central 1 (Iowa) |
US East (Ohio) |
West US 2 (Washington) |
|
US East 1 (N. Virginia) |
Europa (Holanda) |
|
Europe (Ireland) |
||
Europe Central 1 (Frankfurt) |
||
Europe West 2 (London) |
||
Asia Pacific (Sydney) |
||
Asia Pacific (Tokyo) |
Há suporte para AI_PARSE_DOCUMENT entre outras regiões do Snowflake. Para obter informações sobre como habilitar o suporte entre regiões do Cortex AI, consulte Inferência entre regiões.
Requisitos de controle de acesso¶
Para usar a função AI_PARSE_DOCUMENT, um usuário com a função ACCOUNTADMIN deve conceder a função de banco de dados SNOWFLAKECORTEX_USER ao usuário que chamará a função. Veja o tópico Privilégios de LLM do Cortex para mais detalhes.
Considerações sobre custo¶
A função AI_PARSE_DOCUMENT do Cortex incorre em custos de computação com base no número de páginas por documento processado. O seguinte descreve como as páginas são contadas para diferentes formatos de arquivo:
Para formatos de arquivo paginados (PDF, DOCX), cada página no documento é faturada como uma página.
Para formatos de arquivo de imagem (JPEG, JPG, TIF, TIFF, PNG), cada arquivo de imagem individual é cobrado como uma página.
Para arquivos HTML e TXT, cada parte de 3.000 caracteres é faturada como uma página, incluindo a última parte, que pode ter menos de 3.000 caracteres.
O Snowflake recomenda a execução de consultas que chamem a função AI_PARSE_DOCUMENT do Cortex em um warehouse menor (até o tamanho MEDIUM). Warehouses maiores não aumentam o desempenho.
Condições de erro¶
O Snowflake Cortex AI_PARSE_DOCUMENT pode produzir as seguintes mensagens de erro:
Mensagem |
Explicação |
|---|---|
|
O documento de entrada contém linguagem incompatível. |
|
O documento está em formato incompatível. |
|
O formato de arquivo não é compatível e é reconhecido como um arquivo binário. |
|
O documento excede o limite de 500 páginas. |
|
A entrada de imagem ou uma página de documento convertida é maior do que as dimensões permitidas. |
|
A página é maior do que as dimensões permitidas. |
|
O documento tem mais de 100 MB. |
|
O arquivo não existe. |
|
O arquivo não pode ser acessado devido a privilégios insuficientes. |
|
Tempo limite atingido. |
|
Ocorreu um erro no sistema. Aguarde e tente novamente. |
Avisos legais¶
A classificação dos dados de entradas e saídas é definido na tabela a seguir.
Classificação de dados de entrada |
Classificação de dados de saída |
Designação |
|---|---|---|
Usage Data |
Customer Data |
As funções disponíveis ao público em geral são recursos de AI cobertos. As funções em versão preliminar são recursos de AI em versão preliminar. [1] |
Para obter informações adicionais, consulte AI e ML Snowflake.