Uso do driver JDBC¶
Este tópico fornece informações sobre como usar o driver JDBC.
Extensões de API JDBC do Snowflake¶
O driver JDBC do Snowflake suporta métodos adicionais além da especificação JDBC padrão. Esta seção documenta como usar o desencapsulamento para acessar os métodos específicos do Snowflake e, em seguida, descreve três das situações nas quais você pode precisar desencapsular:
Carregamento de arquivos de dados diretamente de um fluxo para um estágio interno.
Download de arquivos de dados diretamente de um estágio interno para um fluxo.
Desencapsulamento de classes específicas do Snowflake¶
O driver JDBC do Snowflake suporta métodos específicos do Snowflake. Estes métodos são definidos em interfaces Java específicas do Snowflake, tais como SnowflakeConnection, SnowflakeStatement e SnowflakeResultSet. Por exemplo, a interface SnowflakeStatement contém um método getQueryID() que não está na interface Statement do JDBC.
Quando o driver JDBC do Snowflake é solicitado a criar um objeto JDBC (por exemplo, criar um objeto JDBC Statement chamando um método createStatement() de um objeto Connection), o driver JDBC do Snowflake realmente cria objetos específicos do Snowflake que implementam não apenas os métodos do padrão JDBC, mas também os métodos adicionais das interfaces do Snowflake.
Para acessar estes métodos do Snowflake, você “desencapsula” um objeto (como um objeto Statement) para expor o objeto Snowflake e seus métodos. Você pode então chamar os métodos adicionais.
O código a seguir mostra como desencapsular um objeto JDBC Statement para expor os métodos da interface SnowflakeStatement e depois chamar um desses métodos, neste caso setParameter:
Realização de uma consulta assíncrona¶
O driver JDBC do Snowflake oferece suporte a consultas assíncronas, como as que devolvem o controle ao usuário antes de serem concluídas. Você pode iniciar uma consulta e, em seguida, usar a sondagem para determinar quando a consulta foi concluída. Quando isso acontece, o usuário pode ler o conjunto de resultados.
Este recurso permite que um programa cliente execute várias consultas em paralelo sem o programa cliente em si, usando vários threads.
Consultas assíncronas utilizam métodos adicionados às classes SnowflakeConnection, SnowflakeStatement, SnowflakePreparedStatement e SnowflakeResultSet.
Nota
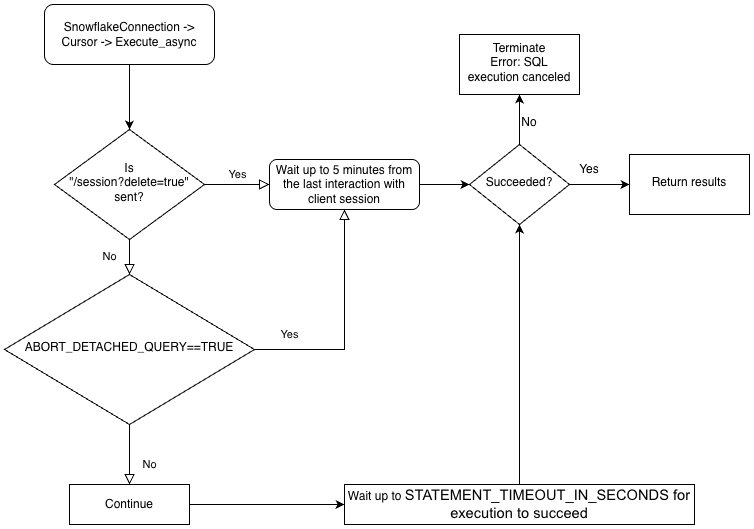
Para realizar consultas assíncronas, é necessário garantir que o parâmetro de configuração ABORT_DETACHED_QUERY seja FALSE (valor padrão).
Se a conexão com o cliente for perdida:
Para consultas síncronas, todas as consultas síncronas em andamento são abortadas imediatamente, independentemente do valor do parâmetro.
Para consultas assíncronas:
Se ABORT_DETACHED_QUERY estiver definido como
FALSE, as consultas assíncronas em andamento continuarão a ser executadas até terminarem normalmente.Se ABORT_DETACHED_QUERY estiver definido como
TRUE, o Snowflake abortará automaticamente todas as consultas assíncronas em andamento quando uma conexão do cliente não for restabelecida após cinco minutos.Você pode evitar que a consulta assíncrona seja abortada na marca de cinco minutos chamando
cursor.query_result(queryId). Embora essa chamada não recupere o resultado real de consulta, pois a consulta ainda está em execução, ela impede que a consulta seja cancelada. Invocarquery_resulté uma operação síncrona, que pode ou não ser apropriada para o seu caso de uso específico.
Você pode executar uma mistura de consultas síncronas e assíncronas na mesma sessão.
Nota
Consultas assíncronas não oferecem suporte a instruções PUT/GET.
Quando executeAsyncQuery(query) é usado, o driver JDBC do Snowflake automaticamente mantém o controle das consultas enviadas de forma assíncrona. Quando a conexão é explicitamente fechada com connection.close(), a lista de consultas assíncronas é examinada e, se alguma delas ainda estiver em execução, a sessão do lado do Snowflake não será excluída.
Se nenhuma consulta assíncrona estiver em execução dentro da mesma conexão, a sessão do Snowflake pertencente à conexão será desconectada quando connection.close() for chamado, o que implicitamente cancela todas as outras consultas sendo executadas na mesma sessão.
Esse comportamento também depende do parâmetro SQL ABORT_DETACHED_QUERY. Para obter mais informações, consulte a documentação do parâmetro ABORT_DETACHED_QUERY.
Como prática recomendada, isole todas as tarefas assíncronas de longa duração (especialmente aquelas que devem continuar após o fechamento da conexão) em uma conexão separada.
Para entender melhor a hierarquia da lógica de negócios dos drivers e a interação do parâmetro ABORT_DETACHED_QUERY, consulte o seguinte fluxograma:
Práticas recomendadas para consultas assíncronas¶
Certifique-se de que você saiba quais consultas dependem de outras antes de executar qualquer consulta em paralelo. Consultas que são interdependentes e sensíveis à ordem não são adequadas para paralelização. Por exemplo, uma instrução INSERT não deve começar até que a instrução CREATE TABLE correspondente tenha sido concluída.
Assegure-se de não fazer muitas consultas para a memória que você tem disponível. Executar várias consultas em paralelo normalmente consome mais memória, especialmente se mais de um ResultSet estiver armazenado na memória ao mesmo tempo.
Ao realizar uma sondagem, trate dos raros casos em que uma consulta não tenha êxito. Por exemplo, evite o seguinte potencial loop infinito:
Em vez disso, use um código semelhante ao seguinte:
Em vez disso, use um código semelhante ao seguinte:
Certifique-se de que as instruções de controle de transações (BEGIN, COMMIT e ROLLBACK) não sejam executadas em paralelo com outras instruções.
Exemplos de consultas assíncronas¶
A maioria desses exemplos exige que o programa importe classes, como mostrado abaixo:
Este é um exemplo muito simples:
Este exemplo armazena a ID da consulta, fecha a conexão, reabre a conexão e usa a ID da consulta para recuperar os dados:
Este é um exemplo muito simples:
Este exemplo armazena a ID da consulta, fecha a conexão, reabre a conexão e usa a ID da consulta para recuperar os dados:
Upload de arquivos de dados diretamente de um fluxo para um estágio interno¶
Você pode fazer o upload de arquivos de dados usando o comando PUT. Entretanto, às vezes faz sentido transferir dados diretamente de um fluxo para um estágio interno (ou seja, o Snowflake) como um arquivo. (O estágio pode ser qualquer tipo de estágio interno: estágio de tabela, estágio de usuário ou estágio nomeado. O driver JDBC não suporta o upload para um estágio externo). Aqui está o método exposto na classe SnowflakeConnection:
Uso de amostras:
Uso de amostras:
Código escrito para versões do driver JDBC anteriores a 3.9.2 podem converter SnowflakeConnectionV1 em vez de desencapsular SnowflakeConnection.class. Por exemplo:
Nota
Os clientes que utilizam versões mais recentes do driver devem atualizar seu código para usar unwrap.
Download de arquivos de dados diretamente de um estágio interno para um fluxo¶
Você pode baixar arquivos de dados usando o comando GET. Entretanto, às vezes faz sentido transferir dados diretamente de um arquivo em um estágio interno (ou seja, o Snowflake) para um fluxo. (O estágio pode ser qualquer tipo de estágio interno: estágio de tabela, estágio de usuário ou estágio nomeado. O driver JDBC não suporta o download para um estágio externo). Aqui está o método exposto na classe SnowflakeConnection:
Uso de amostras:
Uso de amostras:
Código escrito para versões do driver JDBC anteriores a 3.9.2 podem converter SnowflakeConnectionV1 em vez de desencapsular SnowflakeConnection.class. Por exemplo:
Suporte para múltiplas instruções¶
Esta seção descreve como executar várias instruções em uma única solicitação usando o Driver JDBC.
Nota
A execução de várias instruções em uma única consulta requer que um warehouse válido esteja disponível em uma sessão.
Por padrão, o Snowflake retorna um erro para consultas emitidas com múltiplas instruções para proteger contra injeção SQL. A execução de várias instruções em uma única consulta aumenta o risco de injeção SQL. A Snowflake recomenda usá-la com moderação. Para reduzir o risco de injeção SQL, use o método
setParameter()da classeSnowflakeStatementpara especificar o número de instruções a serem executadas, o que torna mais difícil injetar uma instrução anexando-a. Para obter mais informações sobreSnowflakeStatement, consulte Interface: SnowflakeStatement.
Envio de múltiplas instruções e tratamento de resultados¶
Consultas contendo múltiplas instruções podem ser executadas da mesma forma que consultas com uma única instrução, exceto que a cadeia de caracteres de consulta contém múltiplas instruções separadas por ponto e vírgula.
Há duas maneiras de permitir múltiplas instruções:
Call Statement.setParameter(“MULTI_STATEMENT_COUNT“, n) para especificar quantas instruções de cada vez este Statement deve poder executar. Consulte abaixo para mais detalhes.
Defina o parâmetro MULTI_STATEMENT_COUNT no nível da sessão ou no nível da conta executando um dos seguintes comandos:
Ou:
Definir o parâmetro como 0 permite um número ilimitado de instruções. A definição do parâmetro como 1 permite apenas uma instrução de cada vez.
A fim de tornar ataques de injeção SQL mais difíceis, os usuários podem chamar o método setParameter para especificar o número de instruções a serem executadas em uma única chamada, como mostrado abaixo. Neste exemplo, o número de instruções a serem executadas em uma única chamada é 3:
O número padrão de instruções é 1; em outras palavras, o modo de múltiplas instruções está desativado.
Para executar instruções múltiplas sem especificar o número exato, passe um valor de 0.
O parâmetro MULTI_STATEMENT_COUNT não faz parte do padrão JDBC; ele é uma extensão do Snowflake. Este parâmetro afeta mais de um driver/conector do Snowflake.
Quando múltiplas instruções são executadas em uma única chamada execute(), o resultado da primeira instrução está disponível através dos métodos padrão getResultSet() e getUpdateCount(). Para acessar os resultados das instruções que se seguem, use o método getMoreResults(). Este método retorna true quando mais instruções estão disponíveis para iteração e false, caso contrário.
O exemplo abaixo define o parâmetro MULTI_STATEMENT_COUNT, executa 3 instruções e recupera contagens de atualização e conjuntos de resultados:
O Snowflake recomenda o uso de execute() para consultas com múltiplas instruções. Os métodos executeQuery() e executeUpdate() também suportam instruções múltiplas, mas geram uma exceção se o primeiro resultado não for o tipo de resultado esperado (conjunto de resultados e contagem de atualizações, respectivamente).
Falha nas instruções¶
Se qualquer uma das instruções SQL não for compilada ou executada, a execução é abortada. Todas as instruções anteriores não são afetadas.
Por exemplo, se as instruções abaixo forem executadas como uma única consulta com múltiplas instruções, a consulta falhará na terceira instrução, e uma exceção será gerada.
Se você consultasse o conteúdo da tabela test, os valores 1 e 2 estariam presentes.
Recursos sem suporte¶
Instruções PUT e GET não têm suporte para consultas com múltiplas instruções.
A preparação de instruções e o uso de variáveis de vinculação também não têm suporte para consultas com múltiplas instruções.
Vinculação de variáveis a instruções¶
A vinculação permite que uma instrução SQL use um valor que está armazenado em uma variável Java.
Vinculação simples¶
Sem a vinculação, uma instrução SQL especifica valores especificando literais dentro da instrução. Por exemplo, a seguinte instrução usa o valor literal 42 em uma instrução UPDATE:
Com a vinculação, você pode executar uma instrução SQL que usa um valor que está dentro de uma variável. Por exemplo:
O ? dentro da cláusula VALUES especifica que a instrução SQL usa o valor de uma variável. O método setInt() especifica que o primeiro ponto de interrogação na instrução SQL deve ser substituído pelo valor na variável chamada my_integer_variable. Observe que setInt() usa valores baseados em 1, ao invés de baseados em 0 (ou seja, o primeiro ponto de interrogação é referenciado por 1, e não por 0).
Vinculação de variáveis a colunas de carimbo de data/hora¶
O Snowflake suporta três variações diferentes para os carimbos de data/hora: TIMESTAMP_LTZ , TIMESTAMP_NTZ , TIMESTAMP_TZ. Quando você chama PreparedStatement.setTimestamp para vincular uma variável a uma coluna de data/hora, o driver JDBC interpreta o valor do carimbo de data/hora em termos do fuso horário local (TIMESTAMP_LTZ) ou o fuso horário do objeto Calendar passado como um argumento:
Se você quiser que o driver interprete o carimbo de data/hora usando uma variação diferente (por exemplo, TIMESTAMP_NTZ), use uma das seguintes abordagens:
Defina o parâmetro de sessão CLIENT_TIMESTAMP_TYPE_MAPPING para a variação.
Observe que o parâmetro afeta todas as operações de vinculação para a sessão atual. Se você precisar alterar a variação (por exemplo, voltar para
TIMESTAMP_LTZ), deve definir novamente este parâmetro de sessão.(Nas versões do driver JDBC 3.13.3 e posteriores) Chame o método
PreparedStatement.setObjecte use o parâmetrotargetSqlTypepara especificar uma das seguintes variações de carimbo de data/hora do Snowflake:SnowflakeType.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeType.EXTRA_TYPES_TIMESTAMP_TZSnowflakeType.EXTRA_TYPES_TIMESTAMP_NTZSnowflakeType.EXTRA_TYPES_VECTORSnowflakeType.EXTRA_TYPES_DECFLOATSnowflakeType.EXTRA_TYPES_YEAR_MONTH_INTERVALSnowflakeType.EXTRA_TYPES_DAY_TIME_INTERVAL
Por exemplo:
SnowflakeUtil.EXTRA_TYPES_TIMESTAMP_LTZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_TZSnowflakeUtil.EXTRA_TYPES_TIMESTAMP_NTZ
Por exemplo:
Inserções em lote¶
Em seu código de aplicação Java, você pode inserir várias linhas em um único lote vinculando parâmetros em uma instrução INSERT e chamando addBatch() e executeBatch().
Como exemplo, o código a seguir insere duas linhas em uma tabela que contém uma coluna INTEGER e uma coluna VARCHAR. O exemplo vincula os valores aos parâmetros da instrução INSERT e chama addBatch() e executeBatch() para executar uma inserção em lote.
Quando você usa esta técnica para inserir um grande número de valores, o driver pode melhorar o desempenho ao transmitir os dados (sem criar arquivos na máquina local) para um estágio temporário de ingestão. O driver faz isso automaticamente quando o número de valores excede um limite.
Além disso, o banco de dados e o esquema atual da sessão devem ser definidos. Se não forem definidos, o comando CREATE TEMPORARY STAGE executado pelo driver pode falhar com o seguinte erro:
Nota
Para formas alternativas de carregar dados no banco de dados Snowflake (incluindo carregamento em massa usando o comando COPY), consulte Carregamento de dados para o Snowflake.
Exemplo de programa Java¶
Para uma amostra de trabalho escrita em Java, clique com o botão direito do mouse no nome do arquivo, SnowflakeJDBCExample.java e salve o link/arquivo em seu sistema de arquivos local.
Solução de problemas¶
I/O Error: Connection Reset¶
Em alguns casos, o driver JDBC pode falhar com a seguinte mensagem de erro após um período de inatividade:
Você pode contornar o problema definindo um “tempo de vida” específico para as conexões. Se uma conexão estiver ociosa por mais tempo que o “tempo de vida”, o driver JDBC retira a conexão do pool de conexões e cria uma nova conexão.
Para definir o tempo de vida, defina a propriedade do sistema Java chamada net.snowflake.jdbc.ttl com o número de segundos que a conexão deve viver:
Para programar esta propriedade, chame
System.setProperty:Para definir esta propriedade ao executar o comando
java, use o sinalizador-D:
O valor padrão da propriedade net.snowflake.jdbc.ttl é -1, o que significa que as conexões ociosas não são removidas do pool de conexões.
Tratamento de erros¶
Ao tratar erros e exceções para um aplicativo JDBC, você pode usar o arquivo ErrorCode.java que o Snowflake fornece para determinar a causa dos problemas. Os códigos de erro específicos do driver JDBC começam com 2, no formato: 2NNNNN.
Nota
O link para o arquivo ErrorCode.java no repositório git público snowflake-jdbc aponta para a última versão do arquivo, que pode ser diferente da versão do driver JDBC que você usa atualmente.