Visão geral dos pontos de extremidade REST do Snowpipe para carregar dados¶
Este tópico fornece uma visão geral dos detalhes de uso ao chamar os pontos de extremidade REST públicos para carregar dados e recuperar relatórios de histórico de carregamento.
Neste tópico:
Autenticação¶
As chamadas para os pontos de extremidade REST públicos do Snowpipe usam autenticação baseada em chaves, em vez da autenticação típica com nome de usuário/senha, porque o serviço de ingestão não mantém sessões de clientes.
Para seguir o princípio geral do menor privilégio, recomendamos a criação de um usuário e função separados a serem usados para a ingestão de arquivos usando um canal. O usuário deve ser criado com esta função como sua função padrão e a função deve ter o conjunto mínimo de permissões necessárias para inserir arquivos na tabela de destino para carregamento de dados.
Fluxo de processo¶
Seu aplicativo cliente chama um ponto de extremidade REST público com uma lista de nomes de arquivos de dados e um nome de canal referenciado (SDKs Java e Python são fornecidos para sua conveniência). Se novos arquivos de dados correspondentes à lista forem descobertos no estágio, eles são colocados em fila para carregamento. Os recursos computacionais fornecidos pelo Snowflake carregam os dados da fila em uma tabela do Snowflake com base nos parâmetros definidos no canal.
O diagrama a seguir mostra o fluxo do processo da API REST do Snowpipe:
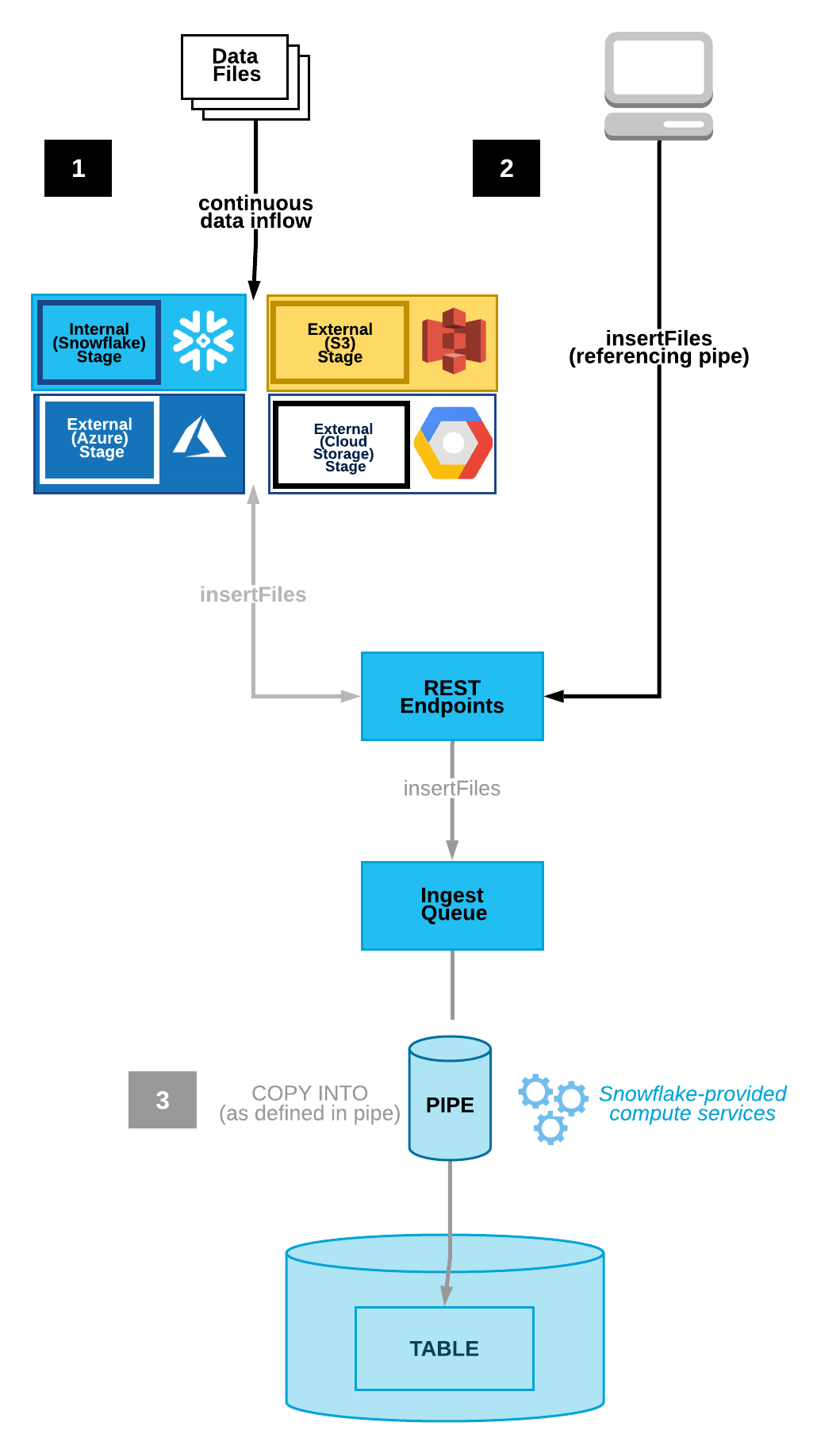
Os arquivos de dados são copiados para um estágio interno (Snowflake) ou externo (Amazon S3, Google Cloud Storage ou Microsoft Azure).
Um cliente chama o ponto de extremidade
insertFilescom uma lista de arquivos a serem ingeridos e um canal definido.O ponto de extremidade move esses arquivos para uma fila de ingestão.
Um warehouse virtual fornecido pelo Snowflake carrega os dados dos arquivos enfileirados na tabela de destino com base nos parâmetros definidos no canal especificado.
Fluxo de trabalho¶
Esta seção fornece uma visão geral de alto nível da configuração e do fluxo de trabalho de carga.
Configuração do Snowpipe¶
Crie um objeto de preparação nomeado onde seus arquivos de dados serão preparados. O Snowpipe é compatível tanto com os estágios internos (Snowflake) quanto com os estágios externos, ou seja, buckets S3.
Crie um objeto de canal usando CREATE PIPE.
Configure a segurança para o usuário que executará o carregamento contínuo de dados. Se você planeja restringir os carregamentos de dados do Snowpipe a um único usuário, você só precisa configurar a autenticação do par de chaves para o usuário uma única vez. Depois disso, você só precisa conceder privilégios de controle de acesso nos objetos de banco de dados usados para cada carregamento de dados.
Instale um SDK cliente (Java ou Python) para chamar os pontos de extremidade REST públicos do Snowpipe.
Uso da API REST Snowpipe para carregar dados¶
Opção 1: uso de um cliente para chamar a API REST¶
Use um cliente para chamar a API REST. É fornecido um código de amostra SDK Java e Python. Para obter mais informações, consulte Opção 1: carregamento de dados usando a API REST Snowpipe.
Chame um ponto de extremidade REST com uma lista de arquivos para carregar quando preparado.
Recupere o histórico de carregamento.
Opção 2: uso do AWS Lambda para chamar a API REST¶
Automatize o Snowpipe usando uma função AWS Lambda para chamar a API REST. Uma função Lambda só pode chamar a API REST para carregar dados de arquivos armazenados no Amazon S3. Para obter mais informações, consulte Opção 2: Automatização do Snowpipe com AWS Lambda.
Crie uma função AWS Lambda que chama a API REST do Snowpipe para carregar dados de seu estágio externo (ou seja, S3).
Recupere o histórico de carregamento.