Cortex AI Functions: Images¶
Com o Cortex AI Images, você pode realizar o seguinte:
Comparar imagens
Gerar legendas para imagens
Classificar imagens
Extrair entidades de imagens
Gerar vetores de incorporação para uso em sistemas de recuperação
Responder a perguntas usando os dados em gráficos e tabelas
Você pode realizar essas tarefas com as seguintes funções:
Requisitos de entrada¶
A multimodal COMPLETE pode processar imagens com as seguintes características:
Requisito |
Valor |
|---|---|
Extensões de nome de arquivo |
|
Criptografia de estágio |
Criptografia do lado do servidor |
Tipo de dados |
Nota
Atualmente, o processamento de arquivos de estágios é incompatível com políticas de rede personalizadas.
Análise de imagens¶
A função COMPLETE processa uma única imagem ou várias imagens (por exemplo, extraindo as diferenças nas entidades de várias imagens) armazenadas em uma área de preparação. Consulte Criar área de preparação para arquivos de mídia para obter informações sobre como criar uma área de preparação adequada.
A chamada de função especifica o seguinte:
O modelo multimodal a ser usado
Um prompt
O caminho do estágio do(s) arquivo(s) de imagem por meio de um objeto FILE
Exemplo de perguntas e respostas de visão¶
The following example uses Anthropic’s Claude Sonnet 4.6 model to summarize a pie chart science-employment-slide.jpeg stored in the @myimages stage.
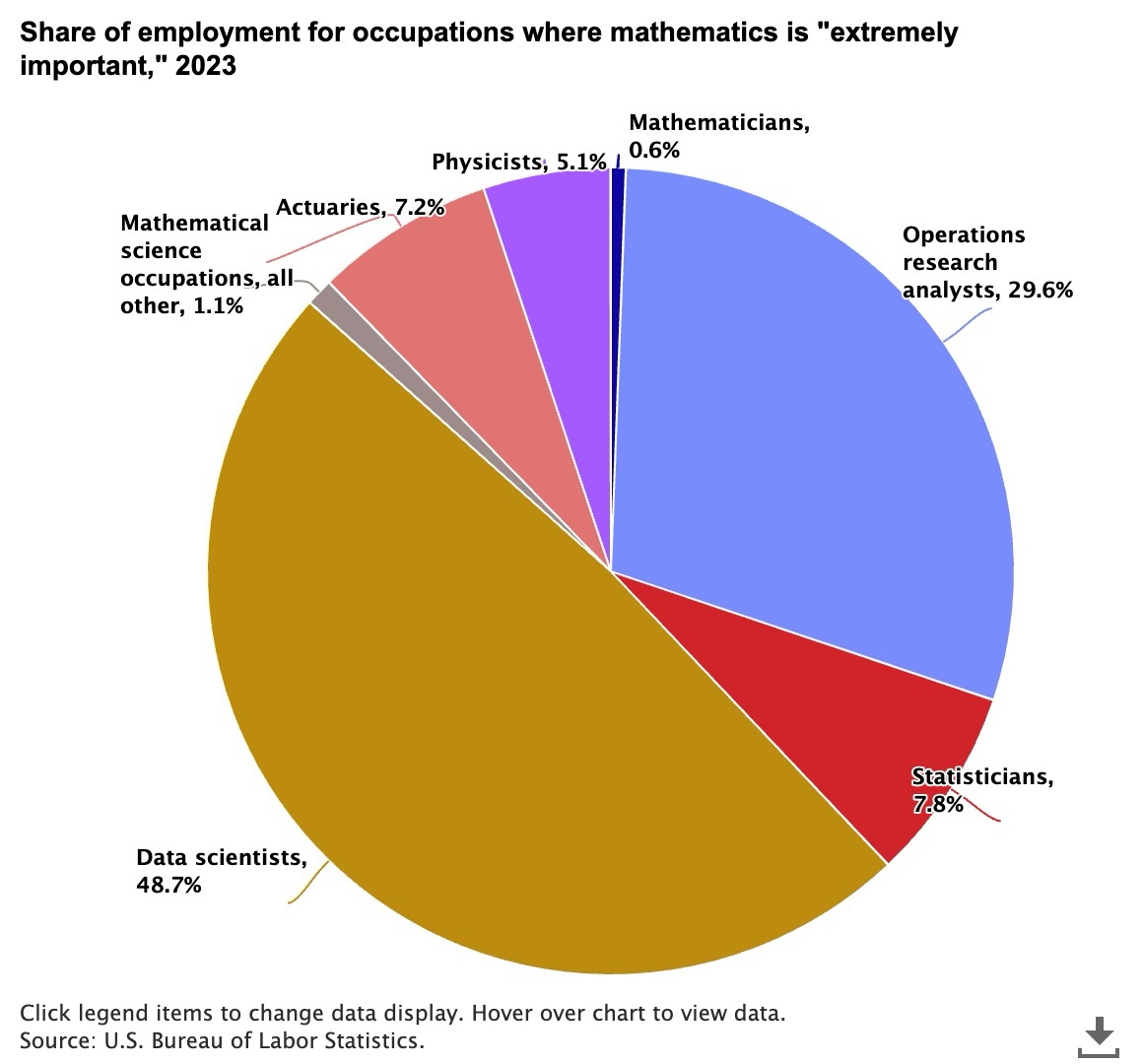
A distribuição das ocupações em que a matemática é considerada “extremamente importante” em 2023¶
Resposta:
Exemplo de comparação de imagens¶
Nota
Atualmente, apenas os modelos Anthropic (claude) e Meta (llama) podem fazer referência a várias imagens em um único prompt. O suporte a várias imagens para outros modelos poderá estar disponível em um lançamento futuro.
Use the PROMPT helper function to process multiple images in a single COMPLETE call. The following example uses
Anthropic’s Claude Sonnet 4.6 model to compare two different ad creatives from the @myimages stage.

Imagem de dois anúncios de carros elétricos¶
Resposta:
Exemplo de classificação de imagens¶
O exemplo a seguir usa AI_CLASSIFY para classificar uma imagem de um aplicativo de imóveis.

O SQL a seguir usa a função AI_CLASSIFY para classificar a imagem como uma foto de sala de estar, cozinha, sala de banho, jardim ou quarto principal.
Resposta:
O SQL abaixo categoriza os objetos encontrados na imagem acima como sofá, janela, mesa, televisão ou obra de arte.
Resposta:
Pesquisa de imagens¶
Você pode usar AI_EMBED para encontrar imagens semelhantes a uma imagem de destino. Primeiro, use a função AI_EMBED para gerar um vetor de incorporação para a imagem de destino, mapeando suas características visuais em um espaço vetorial abstrato, uma representação numérica das características da imagem. Depois disso, você pode usar funções de similaridade vetorial para comparar esse vetor de incorporação com os de outras imagens, o que produz uma pontuação de similaridade baseada nas características visuais comuns ou semelhantes. Essa pontuação pode ser usada para classificar, pontuar ou filtrar imagens com base na similaridade com a imagem de destino.

|

|
Por exemplo, para cada uma das imagens acima, o SQL a seguir gera um vetor de incorporação e os compara usando a similaridade por cosseno. O resultado, cerca de 0,5, indica que as imagens são de alguma forma semelhantes. Ambas as fotos foram tiradas em um cenário urbano e mostram uma multidão de fundo, mas os elementos principais são diferentes.
Para encontrar imagens semelhantes a uma imagem de destino, você pode usar a AI_SIMILARITY. O exemplo a seguir calcula uma pontuação de similaridade para possivelmente milhares de imagens e retorna os criativos de anúncio mais semelhantes ao anúncio da motocicleta abaixo.

A consulta retorna imagens de uma tabela multimodal em que a pontuação de similaridade é maior que 0,50. Uma das imagens identificadas (image_226.jpg) é a que usamos como referência.
Limitações do modelo¶
All models available to Snowflake Cortex have limitations on the total number of input and output tokens, known as the model’s context window. The context window size is measured in tokens. Inputs exceeding the context window limit result in an error. Output which would exceed the context window limit is truncated.
Para modelos de texto, os tokens geralmente representam aproximadamente quatro caracteres de texto, portanto, a contagem de palavras correspondente a um limite é menor que a contagem de tokens.
Para modelos de imagem, a contagem de tokens por imagem depende da arquitetura do modelo de visão. Os tokens em um prompt (por exemplo, “que animal é esse?”) também contribuem para a janela de contexto do modelo.
Modelo |
Janela de contexto (tokens) |
Tipos de arquivo |
Tamanho do arquivo |
Imagens por prompt |
|---|---|---|---|---|
|
1,047,576 |
.jpg, .jpeg, .png, .webp, .gif |
10MB |
5 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3,75 MB [L1] |
20 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3,75 MB [L1] |
20 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3,75 MB [L1] |
20 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3,75 MB [L1] |
20 |
|
128,000 |
.jpg, .jpeg, .png, .webp, .gif, .bmp |
10 MB |
10 |
|
128,000 |
.jpg, .jpeg, .png, .webp, .gif, .bmp |
10 MB |
10 |
|
128,000 |
.jpg, .jpeg, .png, .webp, .gif, .bmp |
10 MB |
1 |
|
32,768 |
.jpg, .png, .pg, .gif, .bmp |
10 MB |
1 |
Considerações sobre custo¶
O faturamento é escalonado de acordo com o número de tokens processados. O número de tokens por imagem depende da arquitetura do modelo de visão.
A fórmula dos modelos antrópicos (
claude) é aproximadamente: tokens = (largura em pixels × altura em pixels)/750.Os modelos Mistral (
pixtral) dividem cada imagem em lotes de 16 × 16 pixels e convertem cada lote em um token. O número total de tokens é equivalente a aproximadamente (largura em pixels/16) * (altura em pixels/16).Os modelos Meta (
llama) tentam colocar a imagem em blocos quadrados. Dependendo da proporção e do tamanho da imagem, o número de blocos pode ser de até 16, cada uma representada por cerca de 153 tokens.Open AI models rescale the image and tile it with square patches. For
openai-gpt-4.1, depending on the image ratio and size, the number of tokens can be 211 (images up to 512x512px), 352 (non-square images with longer side length 1024px), or from 630 tokens (square images at least 1024x1024px) to 913 tokens (non-square images with shorter side length 1024px).O
voyage-multimodal-3opera em uma matriz de quadrados de imagem com tamanho aproximado de 14 x 14 px. A imagem é redimensionada de maneira que fique coberta por uma grade, que tem um mínimo de 64 e um máximo de 2.500 quadrados. Dois tokens de imagem extras são adicionados, de modo que a entrada varia de 66 a 2.502 tokens, dependendo do tamanho e da proporção da imagem.
Nota
No momento, a função COUNT_TOKENS não é compatível com entradas de imagem.
Escolha de um modelo de visão¶
A função COMPLETE é compatível com vários modelos de capacidade, latência e custo variados. Para obter o melhor desempenho por crédito, escolha um modelo que se alinhe ao tamanho do conteúdo e à complexidade da tarefa.
Modelo |
MMMU |
Mathvista |
ChartQA |
DocVQA |
VQAv2 |
|---|---|---|---|---|---|
GPT-4o |
68,6 |
64,6 |
85,1 |
88,9 |
77,8 |
|
75 |
72 |
|||
|
73,4 |
73,7 |
90 |
94,4 |
|
|
69,4 |
70,7 |
88,8 |
94,4 |
|
|
64,0 |
69,4 |
88,1 |
85,7 |
67 |
Os benchmarks são:
MMMU: avalia modelos multimodais em tarefas multidisciplinares que exigem raciocínio de nível universitário.
Mathvista: referência de raciocínio matemático em um contexto visual.
ChartQA: avalia questões de raciocínio complexas sobre gráficos.
DocVQA e VQv2: benchmarks para responder a perguntas visuais em documentos.
Para incorporações multimodais, apenas o modelo voyage-multimodal-3 está disponível no momento. O voyage-multimodal-3 é um modelo de incorporação multimodal de última geração capaz de incorporar texto e imagens. Ele pode extrair as principais características visuais de fontes, como capturas de tela de PDFs, slides, tabelas e figuras, reduzindo a necessidade de fluxos de trabalho de análise de documentos complexos. De acordo com os parâmetros de comparação internos da Voyage AI, o modelo voyage-multimodal-3 supera os da concorrência, como OpenAI CLIP Large, Amazon Titan Multimodal e Cohere Multimodal v3.
Disponibilidade regional¶
O suporte a esse recurso está disponível nativamente para contas nas seguintes regiões do Snowflake:
A AI_COMPLETE está disponível em regiões adicionais por meio da inferência entre regiões.
Condições de erro¶
Mensagem |
Explicação |
|---|---|
Falha na solicitação da função externa SYSTEM$COMPLETE_WITH_IMAGE_INTERNAL com erro de serviço remoto: 400 “invalid image path” |
A extensão do arquivo ou o próprio arquivo não é aceito pelo modelo. A mensagem também pode significar que o caminho do arquivo está incorreto, ou seja, o arquivo não existe no local especificado. Os nomes de arquivos diferenciam maiúsculas de minúsculas. |
Erro no objeto seguro |
Pode indicar que o estágio não existe. Verifique o nome do estágio e certifique-se de que o estágio exista e esteja acessível. Não se esqueça de usar o sinal de arroba (@) no início do caminho do estágio, como |
Falha na solicitação da função externa _COMPLETE_WITH_PROMPT com erro de serviço remoto: 400 “invalid request parameters: unsupported image format: image/**” |
Unsupported image format given to |
Falha na solicitação da função externa _COMPLETE_WITH_PROMPT com erro de serviço remoto: 400 “invalid request parameters: Image data exceeds the limit of 5.00 MB” |
The provided image given to |
Jurídico¶
A classificação dos dados de entradas e saídas é definido na tabela a seguir.
Classificação de dados de entrada |
Classificação de dados de saída |
Designação |
|---|---|---|
Usage Data |
Customer Data |
As funções disponíveis ao público em geral são recursos de AI cobertos. As funções em versão preliminar são recursos de AI em versão preliminar. [1] |
Para obter informações adicionais, consulte AI e ML Snowflake.