Cortex AI Functions: Images¶
Cortex AI Imagesを使えば、以下のことが可能です。
画像の比較
画像のキャプション
画像の分類
画像からのエンティティ抽出
検索システムで使用する埋め込みベクトルを生成します。
グラフとチャートのデータを使用して質問に答える
これらのタスクは以下の関数で実行できます。
入力要件¶
COMPLETE マルチモーダルでは、以下のような特徴を持つ画像を処理することができます。
要件 |
値 |
|---|---|
ファイル名の拡張子 |
|
ステージ暗号化 |
サーバー側の暗号化 |
データ型 |
注釈
ステージングされたファイルを処理することは、現在、カスタムネットワークポリシーと互換性がありません。
画像を分析する¶
COMPLETE 関数は、ステージに格納された単一の画像または複数の画像(例: さまざまな画像のエンティティの違いを抽出)を処理します。適切なステージの作成に関する情報については、 メディアファイル用ステージを作成する をご参照ください。
関数の呼び出しでは、次の事項を指定します。
使用するマルチモーダルモデル
プロンプト
FILE オブジェクトを介した画像ファイルのステージパス。
ビジョンQ&Aの例¶
The following example uses Anthropic's Claude Sonnet 4.6 model to summarize a pie chart science-employment-slide.jpeg stored in the @myimages stage.
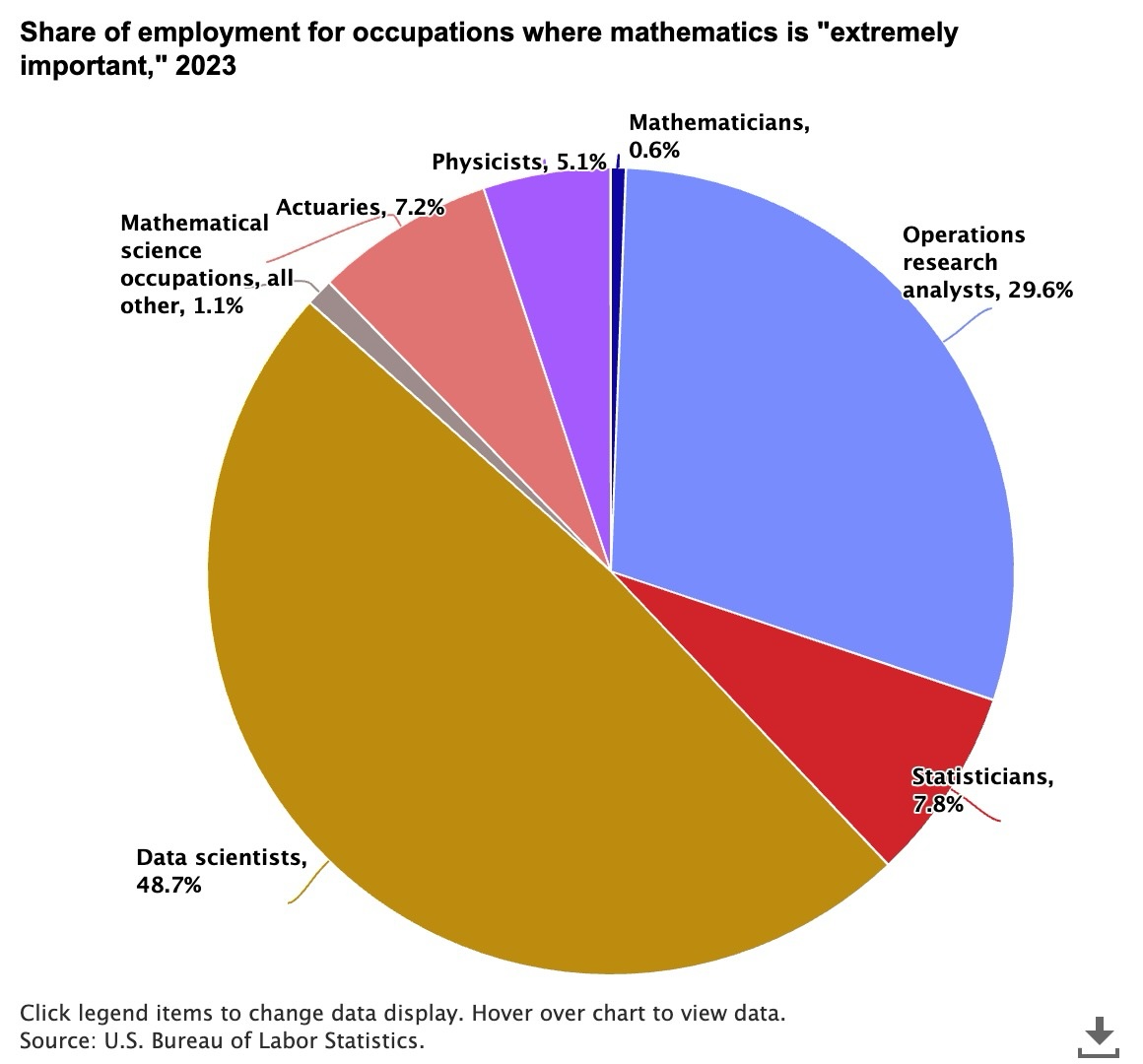
2023年に数学が「極めて重要」と考えられる職業の分布¶
応答:
画像の例を比較する¶
注釈
現在、一つのプロンプトで複数の画像をリファレンスできるのは、Anthropic (claude) と Meta (llama) モデルだけです。他のモデルの複数画像サポートは、将来のリリースで利用可能になる可能性があります。
Use the PROMPT helper function to process multiple images in a single COMPLETE call. The following example uses
Anthropic's Claude Sonnet 4.6 model to compare two different ad creatives from the @myimages stage.

電気自動車の広告¶
応答:
画像の例を分類する¶
次の例では、AI_CLASSIFY を使用して不動産アプリケーションの画像を分類しています。

次の SQL は AI_CLASSIFY 関数を使用して画像を居住エリア、キッチン、浴室、庭または主寝室の写真として分類します。
応答:
以下に示す SQL は、上の画像で見つかったオブジェクトを長椅子、窓、テーブル、テレビ、または芸術作品として分類します。
応答:
画像を検索する¶
AI_EMBED を使用してターゲット画像に類似した画像を検索できます。まず、AI_EMBED 関数を使用して、ターゲット画像の埋め込みベクトルを生成し、その視覚的特徴を画像の特徴の数値表現である抽象的なベクトル空間にマッピングします。その後、ベクトル類似度関数を使用して、この埋め込みベクトルを他の画像の埋め込みベクトルと比較し、共通または類似の視覚的特徴に基づいて類似度スコアを生成できます。このスコアは、ターゲット画像との類似性に基づいて、画像を分類、ランク付け、またはフィルタリングするために使用できます。

|

|
たとえば、上記の画像がある場合、次の SQL は各画像の埋め込みベクトルを生成し、コサイン類似度を用いてベクトルを比較します。約0.5である結果は、画像がやや類似していることを示しています。どちらの写真も都市の設定で取得されており、背景には大衆が写っていますが、メインのタイトルが異なります。
ターゲット画像に類似した画像を検索するには、AI_SIMILARITY を使用します。以下の例では、おそらく数千存在する画像に対して類似性スコアを計算し、以下のバイクの広告に最も類似した広告クリエイティブを返します。

クエリは、類似度スコアが0.50より大きいマルチモーダルテーブルから画像を返します。特定された画像の一つ(image_226.jpg)は、参照として使用したものです。
モデルの制限¶
All models available to Snowflake Cortex have limitations on the total number of input and output tokens, known as the model's context window. The context window size is measured in tokens. Inputs exceeding the context window limit result in an error. Output which would exceed the context window limit is truncated.
テキストモデルの場合、トークンは一般的に約4文字のテキストを表すため、制限に対応する単語数はトークン数よりも少なくなります。
画像モデルの場合、画像あたりのトークン数はビジョンモデルのアーキテクチャに依存します。プロンプト内のトークン(たとえば、「これは何の動物ですか」)も、モデルのコンテキストウィンドウに貢献します。
モデル |
コンテキストウィンドウ(トークン) |
ファイルタイプ |
ファイルサイズ |
プロンプトごとの画像 |
|---|---|---|---|---|
|
1,047,576 |
.jpg、.jpeg、.png、.webp、.gif |
10MB |
5 |
|
200,000 |
.jpg、.jpeg、.png、.webp、.gif |
3.75 MB [L1] |
20 |
|
200,000 |
.jpg、.jpeg、.png、.webp、.gif |
3.75 MB [L1] |
20 |
|
200,000 |
.jpg、.jpeg、.png、.webp、.gif |
3.75 MB [L1] |
20 |
|
200,000 |
.jpg、.jpeg、.png、.webp、.gif |
3.75 MB [L1] |
20 |
|
128,000 |
.jpg、.jpeg、.png、.webp、.gif、.bmp |
10 MB |
10 |
|
128,000 |
.jpg、.jpeg、.png、.webp、.gif、.bmp |
10 MB |
10 |
|
128,000 |
.jpg、.jpeg、.png、.webp、.gif、.bmp |
10 MB |
1 |
|
32,768 |
.jpg、.png、.pg、.gif、.bmp |
10 MB |
1 |
コストの考慮事項¶
請求はトークンの処理数に応じて変化します。画像あたりのトークン数はビジョンモデルのアーキテクチャに依存します。
Anthropic (
claude) モデルの計算式は、トークン = (ピクセル幅 x ピクセル高) / 750 です。Mistral (
pixtral) モデルは、各画像を16x16ピクセルのバッチに分割し、各バッチをトークンに変換します。トークンの総数は、おおよそ (ピクセル単位の幅 / 16) * (ピクセル単位の高さ / 16) に相当します。Meta (
llama) モデルは、正方形のタイルで画像をタイル化しようとします。画像の縦横比とサイズによって、タイルの数は最大16個になり、それぞれが約153個のトークンで表されます。Open AI models rescale the image and tile it with square patches. For
openai-gpt-4.1, depending on the image ratio and size, the number of tokens can be 211 (images up to 512x512px), 352 (non-square images with longer side length 1024px), or from 630 tokens (square images at least 1024x1024px) to 913 tokens (non-square images with shorter side length 1024px).voyage-multimodal-3は、サイズがおよそ14x14pxの画像パッチの配列を操作します。画像は、最小64個のパッチと最大2500個のパッチを持つグリッドでカバーされるように再スケールされます。2つの余分な画像トークンが追加されるため、入力は画像のサイズとアスペクト比率に応じて、66から2502トークンの範囲になります。
注釈
COUNT_TOKENS 関数は現在、画像入力をサポートしていません。
ビジョンモデルの選択¶
COMPLETE 関数は、能力、遅延、コストが異なる複数のモデルをサポートしています。クレジットあたりのパフォーマンスを最適化するには、コンテンツのサイズとタスクの複雑さに合ったモデルを選択します。
モデル |
MMMU |
Mathvista |
ChartQA |
DocVQA |
VQAv2 |
|---|---|---|---|---|---|
GPT-4o |
68.6 |
64.6 |
85.1 |
88.9 |
77.8 |
|
75.0 |
72.0 |
|||
|
73.4 |
73.7 |
90 |
94.4 |
|
|
69.4 |
70.7 |
88.8 |
94.4 |
|
|
64.0 |
69.4 |
88.1 |
85.7 |
67 |
ベンチマークは以下の通りです。
MMMU: 大学レベルの推論を必要とする学際的なタスクでマルチモーダルモデルを評価します。
Mathvista: 視覚的な文脈の中での数学的推論のベンチマーク。
ChartQA: チャートに関する複雑な推論問題を評価します。
DocVQA と VQv2: ドキュメント上の視覚的な質問応答のためのベンチマーク。
マルチモーダル埋め込みの場合は、voyage-multimodal-3 モデルのみが現在利用可能です。voyage-multimodal-3 は、テキストと画像を埋め込むことができる最先端のマルチモーダル埋め込みモデルです。PDFs、スライド、テーブル、図のスクリーンショットなどのソースから主要な視覚的特徴を抽出できます。これにより、複雑なドキュメント解析ワークフローの必要性が軽減されます。Voyage AI 内部ベンチマークによると、voyage-multimodal-3 モデルは、OpenAICLIP の大規模なAmazon Titanマルチモーダル、およびCohereマルチモーダルv3などの競合するモデルを上回る性能を発揮します。
リージョンの可用性¶
この機能のサポートは、以下のSnowflakeリージョンのアカウントでネイティブに利用可能です。
AI_COMPLETE は :doc:`クロスリージョン推論 </user-guide/snowflake-cortex/cross-region-inference>`を通じてその他のリージョンで利用可能です。
エラー条件¶
メッセージ |
説明 |
|---|---|
外部関数 SYSTEM$COMPLETE_WITH_IMAGE_INTERNAL リモートサービスエラーでリクエストに失敗しました:400 '"無効な画像パス" |
ファイル拡張子またはファイル自体のいずれかがモデルで受け入れられません。このメッセージは、ファイルパスが間違っている、つまり指定された場所にファイルが存在しないことを意味する場合もあります。ファイル名は大文字と小文字を区別します。 |
セキュアオブジェクトのエラー |
ステージが存在しない可能性があります。ステージ名を確認し、ステージが存在し、アクセス可能であることを確認します。ステージパスの先頭には、 |
リモートサービスエラーで外部関数 _COMPLETE_WITH_PROMPT のリクエストに失敗しました:400 '"リクエストパラメーターが無効です: サポート対象外のイメージ形式: イメージ/** |
Unsupported image format given to |
リモートサービスエラーで外部関数 _COMPLETE_WITH_PROMPT のリクエストに失敗しました:400 '"リクエストパラメーターが無効です: 画像データが5.00 MB を超えました" |
The provided image given to |
リーガル¶
インプットとアウトプットのデータ分類は以下の表の通りです。
入力データの分類 |
出力データの分類 |
指定 |
|---|---|---|
Usage Data |
Customer Data |
一般的に利用可能な関数は、カバーされている AI 機能です。プレビュー関数は、 AI 機能をプレビューします。[1] |
詳細については、 Snowflake AI と ML をご参照ください。