Incorporações de vetor¶
Uma incorporação refere-se à redução de dados de alta dimensão, como texto não estruturado, a uma representação com menos dimensões, como um vetor. As técnicas modernas de aprendizagem profunda podem criar incorporações de vetores, que são representações numéricas estruturadas, a partir de dados não estruturados, como textos e imagens, preservando noções semânticas de similaridade e dissimilaridade na geometria dos vetores que produzem.
A ilustração a seguir é um exemplo simplificado da incorporação de vetores e da similaridade geométrica do texto em linguagem natural. Na prática, as redes neurais produzem vetores de incorporação com centenas ou até milhares de dimensões, e não duas como mostrado aqui, mas o conceito é o mesmo. Texto semanticamente similar produz vetores que “apontam” na mesma direção geral.
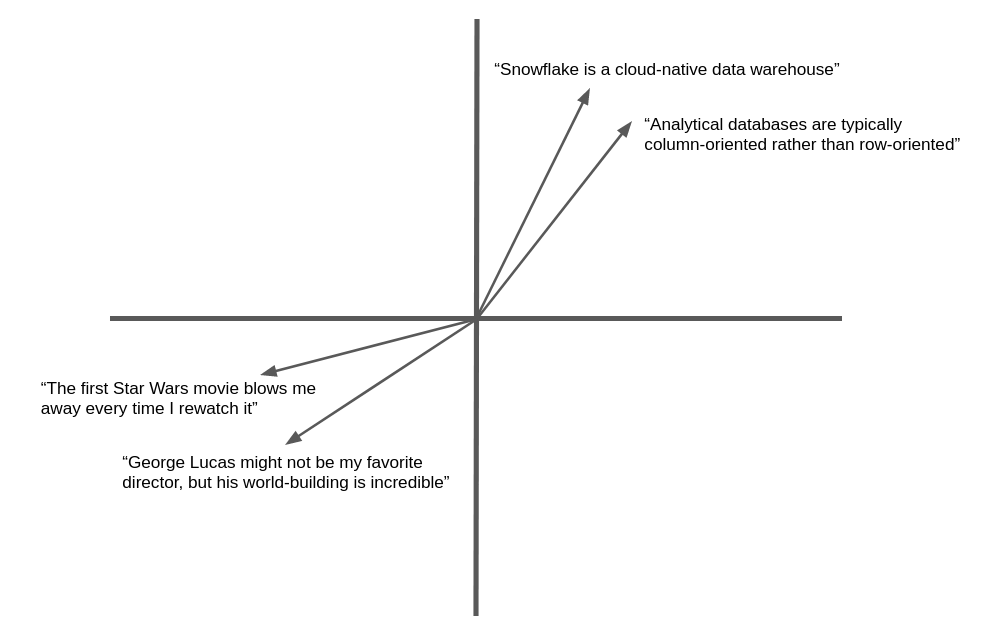
Muitos aplicativos podem se beneficiar da capacidade de encontrar texto ou imagens similares a uma meta. Por exemplo, quando um novo chamado de suporte é registrado em um help desk, a equipe de suporte pode se beneficiar da capacidade de encontrar chamados semelhantes que já foram resolvidos. A vantagem de usar vetores de incorporação neste aplicativo é que eles irão além da correspondência de palavras-chave para similaridade semântica, de modo que registros relacionados podem ser encontrados mesmo que não contenham exatamente as mesmas palavras.
O Snowflake Cortex oferece as funções EMBED_TEXT_768 e EMBED_TEXT_1024 e várias Funções vetoriais para compará-las em vários aplicativos.
Modelos de incorporação de texto¶
O Snowflake oferece os seguintes modelos de incorporação de texto. Consulte abaixo para mais detalhes.
Nome do modelo |
Dimensões de saída |
Janela de contexto |
Suporte a idiomas |
|---|---|---|---|
snowflake-arctic-embed-m-v1.5 |
768 |
512 |
Somente em inglês |
snowflake-arctic-embed-m |
768 |
512 |
Somente em inglês |
e5-base-v2 |
768 |
512 |
Somente em inglês |
snowflake-arctic-embed-l-v2.0 |
1024 |
512 |
Multilíngue |
voyage-multilingual-2 |
1024 |
32000 |
Multilíngue (idiomas compatíveis) |
nv-embed-qa-4 |
1024 |
512 |
Somente em inglês |
Os modelos suportados podem ter custos diferentes.
Sobre as funções de similaridade vetorial¶
A medição de similaridade entre vetores é uma operação fundamental na comparação semântica. O Snowflake Cortex oferece quatro funções de similaridade de vetores: VECTOR_INNER_PRODUCT, VECTOR_L1_distance, VECTOR_L2_DISTANCE e VECTOR_COSINE_SIMILARITY. Para saber mais sobre essas funções, consulte Funções vetoriais.
Para obter detalhes de sintaxe e uso, consulte a página de referência de cada função:
Exemplos¶
Os exemplos a seguir usam funções de similaridade vetorial.
Esse exemplo de SQL usa a função VECTOR_INNER_PRODUCT para determinar quais vetores na tabela estão mais próximos entre si entre as colunas a e b:
Esse exemplo de SQL chama a função VECTOR_COSINE_SIMILARITY para encontrar o vetor mais próximo de [1,2,3]:
Snowflake Python Connector¶
Esses exemplos mostram como usar o tipo de dados VECTOR e as funções de similaridade de vetor com o Python Connector.
Nota
O suporte ao tipo VECTOR foi introduzido na versão 3.6 do Snowflake Python Connector.
Snowpark Python¶
Esses exemplos mostram como usar o tipo de dados VECTOR e as funções de similaridade de vetores com a Snowpark Python Library.
Nota
O suporte ao tipo VECTOR foi introduzido na versão 1.11 da Snowpark Python Library.
A Snowpark Python Library não oferece suporte à função VECTOR_COSINE_SIMILARITY.
Como criar incorporações vetoriais a partir de texto¶
Para criar uma incorporação vetorial a partir de um trecho de texto, é possível usar as funções EMBED_TEXT_768 (SNOWFLAKE.CORTEX) ou EMBED_TEXT_1024 (SNOWFLAKE.CORTEX), dependendo das dimensões de saída do modelo. Esta função retorna a incorporação vetorial para um determinado texto em inglês. Este vetor pode ser usado com as funções de comparação de vetores para determinar a similaridade semântica de dois documentos.
Dica
Você pode usar outros modelos de incorporação através de Snowpark Container Services. Para mais informações, consulte Serviço de contêiner de texto incorporado.
Importante
EMBED_TEXT_768 e EMBED_TEXT_1024 são funções LLM do Cortex, portanto seu uso é regido pelos mesmos controles de acesso que as outras funções LLM do Cortex. Para obter instruções sobre como acessar essas funções, consulte Privilégios necessários das funções LLM do Cortex.
Exemplos de casos de uso¶
Esta seção mostra como usar incorporações, funções de similaridade vetorial e tipo de dados VECTOR para implementar casos de uso populares, como pesquisa de similaridade vetorial e geração aumentada de recuperação (RAG).
Pesquisa de similaridade vetorial¶
Para implementar uma busca por documentos semanticamente similares, primeiro armazene as incorporações dos documentos a serem pesquisados. Mantenha as incorporações atualizadas quando os documentos forem adicionados ou editados.
Neste exemplo, os documentos são problemas do call center registrados por representantes de suporte. O problema é armazenado em uma coluna chamada issue_text na tabela issues. A seguir, o SQL cria uma nova coluna de vetor para armazenar as incorporações dos problemas.
Para realizar uma pesquisa, crie uma incorporação do termo de pesquisa ou do documento de destino e, em seguida, use uma função de similaridade de vetor para localizar documentos com incorporações semelhantes. Use as cláusulas ORDER BY e LIMIT para selecionar os principais documentos correspondentes k e, opcionalmente, use uma condição WHERE para especificar uma similaridade mínima.
Geralmente, a chamada para a função de similaridade vetorial deve aparecer na cláusula SELECT, não na cláusula WHERE. Dessa forma, a função é chamada apenas para as linhas especificadas pela cláusula WHERE, que pode restringir a consulta com base em algum outro critério, em vez de operar em todas as linhas da tabela. Para testar um valor de similaridade na cláusula WHERE, defina um alias de coluna para a chamada VECTOR_COSINE_SIMILARITY na cláusula SELECT e use esse alias em uma condição na cláusula WHERE.
Este exemplo encontra até cinco problemas correspondentes ao termo de pesquisa dos últimos 90 dias, supondo que a similaridade do cosseno com o termo de pesquisa seja de pelo menos 0,7.
Geração aumentada de recuperação (RAG)¶
Na geração aumentada de recuperação (RAG), a consulta de um usuário é usada para encontrar documentos semelhantes usando a similaridade vetorial. O documento superior é então passado para um modelo de linguagem grande (LLM) junto com a consulta do usuário, fornecendo contexto para a resposta generativa (conclusão). Isso pode melhorar significativamente a adequação da resposta.
No exemplo a seguir, wiki é uma tabela com uma coluna de texto content, e query é uma tabela de linha única com uma coluna de texto text.
Considerações sobre custo¶
As funções de LLM do Snowflake Cortex, incluindo EMBED_TEXT_768 e EMBED_TEXT_1024, incorrem em custos de computação com base no número de tokens processados.
Nota
Um token é a menor unidade de texto processada pelas funções de LLM do Snowflake Cortex, aproximadamente igual a quatro caracteres de texto. A equivalência do texto bruto de entrada ou saída com tokens pode variar de acordo com o modelo.
Para as funções EMBED_TEXT_768 e EMBED_TEXT_1024, apenas tokens de entrada são contados para o total faturável.
Funções de similaridade vetorial não incorrem em custos baseados em tokens.
Para obter mais informações sobre o faturamento das funções Cortex LLM, consulte Considerações de custo das funções Cortex LLM. Para obter informações gerais sobre custos de computação, consulte Explicação dos custos de computação.