Criação de tabelas híbridas¶
Este tópico fornece uma visão geral sobre a criação de tabelas híbridas no Snowflake.
Nota
Para criar uma tabela híbrida, você deve ter um warehouse em execução especificado como o warehouse atual da sua sessão. Podem ocorrer erros se nenhum warehouse em execução for especificado ao criar uma tabela híbrida. Para obter mais informações, consulte Como trabalhar com warehouses.
Opções CREATE HYBRID TABLE¶
Você pode criar uma tabela híbrida usando um dos seguintes métodos.
CREATE HYBRID TABLE. O exemplo a seguir cria uma tabela híbrida com uma restrição PRIMARY KEY obrigatória, insere algumas linhas, exclui uma linha e consulta a tabela:
CREATE HYBRID TABLE … AS SELECT (CTAS) ou CREATE HYBRID TABLE … LIKE. Por exemplo:
Carregamento de dados¶
Nota
Como o armazenamento primário para tabelas híbridas é um armazenamento de linhas, as tabelas híbridas normalmente têm uma área de armazenamento maior do que as tabelas padrão. O principal motivo para a diferença é que dados em colunas para tabelas padrão geralmente atingem taxas mais altas de compressão. Para obter detalhes sobre custos de armazenamento, consulte Avaliar custo para tabelas híbridas.
Otimização de carregamentos em massa¶
É possível carregar dados em massa em tabelas híbridas copiando-os de um estágio de dados ou de outras tabelas (usando CTAS, COPY INTO <tabela> ou INSERT INTO … SELECT).
A otimização dos carregamentos em massa depende de a tabela ter sido criada recentemente, sem nunca ter tido nenhum registro carregado, ou ter sido criada usando uma consulta CTAS.
Quando uma tabela híbrida está vazia, todos os três métodos de carregamento (CTAS, COPY e INSERT INTO … SELECT) usam o carregamento em massa otimizado para acelerar o processo de carregamento. Depois que a tabela é carregada, aplica-se o desempenho normal do INSERT. Você ainda pode executar cargas em lote incrementais com as operações COPY e INSERT INTO … SELECT, mas elas normalmente serão menos eficientes. Velocidades de carregamento em massa de aproximadamente 1 milhão de registros por minuto são comuns, mas podem variar muito com base na estrutura da tabela (por exemplo, registros maiores são mais lentos para carregar). O carregamento em massa otimizado será estendido para oferecer suporte a carregamentos em lote incrementais em um lançamento futuro.
Você pode verificar as informações de Statistics nos perfis de consulta do Snowsight para saber se o caminho rápido de carregamento em massa foi usado. Number of rows inserted é chamado de Number of rows bulk loaded quando o caminho rápido é usado. Por exemplo, esta operação de CTAS carregou em massa 200.000 linhas em uma nova tabela:
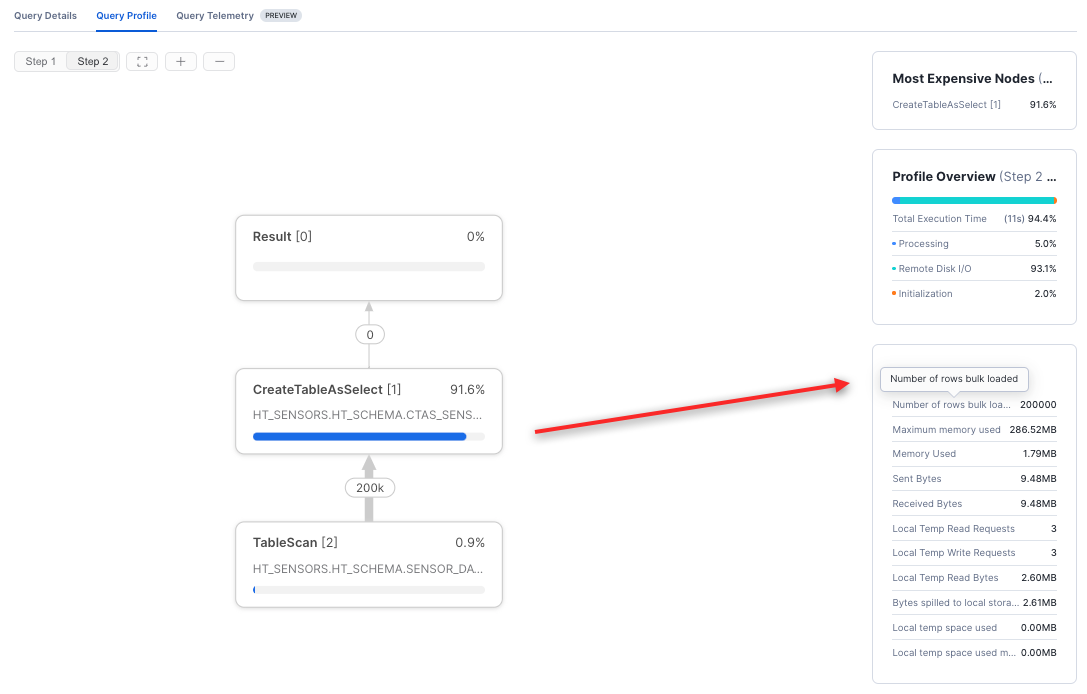
Um carregamento de lote incremental subsequente na mesma tabela não usaria o carregamento em massa otimizado.
Para obter mais informações sobre perfis de consulta, consulte Analisar perfis de consulta para tabelas híbridas e Monitoramento da atividade de consulta com o Histórico de consultas.
Atenção
Comandos CTAS não são compatíveis com as restrições FOREIGN KEY. Se sua tabela híbrida exigir restrições FOREIGN KEY, use COPY ou INSERT INTO … SELECT para carregar a tabela.
Nota
Outros métodos de carregamento de dados em tabelas Snowflake (por exemplo, Snowpipe) não são suportados atualmente.
Erros de construção de índice durante os carregamentos¶
Os tamanhos de índice são limitados em largura. Ao criar índices em colunas de uma tabela híbrida, especialmente índices em um grande número de colunas, qualquer comando que carregue a tabela (incluindo CTAS, COPY ou INSERT INTO … SELECT) pode retornar o seguinte erro. Nesse caso, a tabela contém um índice chamado IDX_HT100_COLS:
Esse erro ocorre porque o armazenamento baseado em linhas impõe um limite no tamanho dos dados (e metadados) que podem ser armazenados por registro. Para reduzir o tamanho do registro, tente criar a tabela sem especificar colunas maiores (como colunas VARCHAR largas) como colunas indexadas. Você também pode tentar criar índices em menos colunas.
Você também pode tentar usar colunas INCLUDE em índices secundários ao criar uma tabela híbrida ou um índice em uma tabela híbrida. Para obter mais informações, consulte Colunas de INCLUDE.