Analyzing queries and troubleshooting with Snowpark Java¶
This topic provides some guidelines on analyzing queries and troubleshooting problems when working with the Snowpark library.
Viewing the execution plan for a query in Snowpark¶
To inspect the evaluation plan of a DataFrame, call the explain method of the DataFrame. This prints the SQL statements
used to evaluate the DataFrame. If there is only one SQL statement, the method also prints the logical plan for the statement.
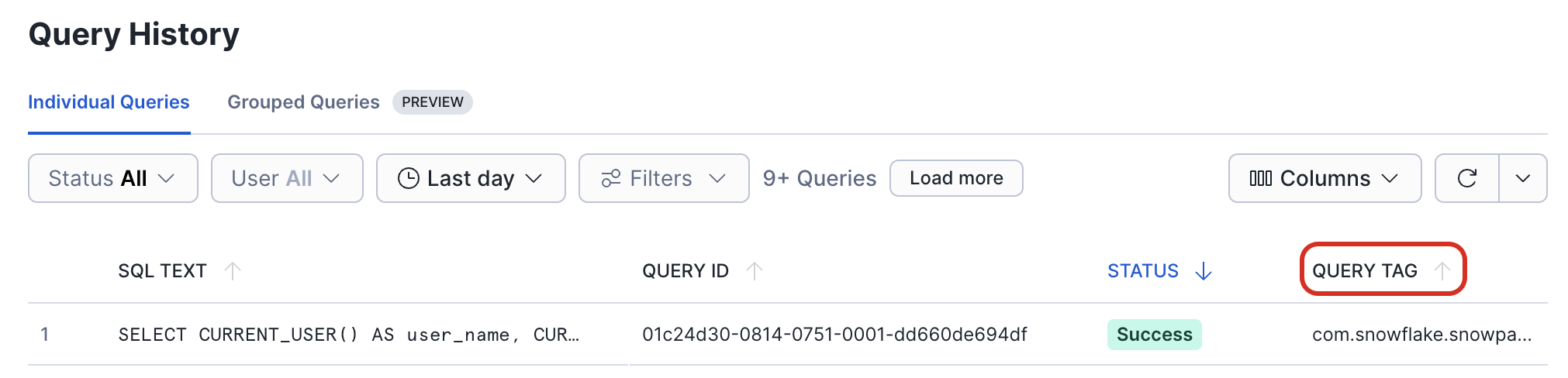
After the execution of a DataFrame has been triggered, you can check on the progress of the query in the Query History page in Snowsight.
In the Query Tag column, you can find the name of the function and the line number in your code that triggered this query.
Changing the logging settings¶
By default, the Snowpark library logs INFO level messages to stdout. To change the logging settings, create a
simplelogger.properties file, and configure the logger properties in that file. For example, to set the log level to
DEBUG:
Put this file in your classpath. If you are using a Maven directory layout, put the file in the src/main/resources/
directory.
java.lang.OutOfMemoryError exceptions¶
If a java.lang.OutOfMemoryError exception is thrown, increase the maximum heap size for the JVM (e.g. through the
-J-Xmxmaximum_size flag).
Unnamed module error on Java 17¶
When executing a Snowpark Java or Scala client on Java 17, you might see the following error:
This is because Snowpark uses the Apache Arrow connector, which depends on internal Java APIs that are not exposed by default after Java 9.
To work around this error, set the following parameter either as a command-line argument when running your application or in your system’s environment variables.
Note
The Snowpark API supports the following versions of Java:
- 11.x
- 17.x
- 21.x (Preview)
Setting the argument when running the application¶
You can set this argument from the command line when running your application.
For example, when calling the java command, you can add --add-opens=java.base/java.nio=ALL-UNNAMED, as in the following:
If you are also using RSA private key authentication, you will also need to allow sun.security.util, as in the following example:
Setting the parameter as an environment variable¶
You can set the parameter in your system’s environment variables. Refer to your operating system’s documentation for instructions on setting environment variables.
Create or update a JDK_JAVA_OPTIONS environment variable, as in the following Unix-based example:
If you are also using RSA private key authentication, you will also need to allow sun.security.util, as in the following example: