Sample asynchronous remote service for AWS¶
This topic contains a sample asynchronous AWS Lambda Function (remote service). You can create this sample function by following the same steps described in Step 1: Create the remote service (AWS Lambda function) in the Management Console.
Overview of the code¶
This section of the documentation provides information about creating an asynchronous external function on AWS. (Before implementing your first asynchronous external function, you might want to read the conceptual overview of asynchronous external functions.)
On AWS, asynchronous remote services must overcome the following restrictions:
Because the HTTP POST and GET are separate requests, the remote service must keep information about the workflow launched by the POST request so that the state can later be queried by the GET request.
Typically, each HTTP POST and HTTP GET invokes a separate instance of the handler function(s) in a separate process or thread. The separate instances do not share memory. In order for the GET handler to read the status or the processed data, the GET handler must access a shared storage resource that is available on AWS.
The only way for the POST handler to send the initial HTTP 202 response code is via a
returnstatement (or equivalent), which terminates the execution of the handler. Therefore, prior to returning HTTP 202, the POST handler must launch an independent process (or thread) to do the actual data processing work of the remote service. This independent process typically needs access to the storage that is visible to the GET handler.
One way for an asynchronous remote service to overcome these restrictions is to use 3 processes (or threads) and shared storage:
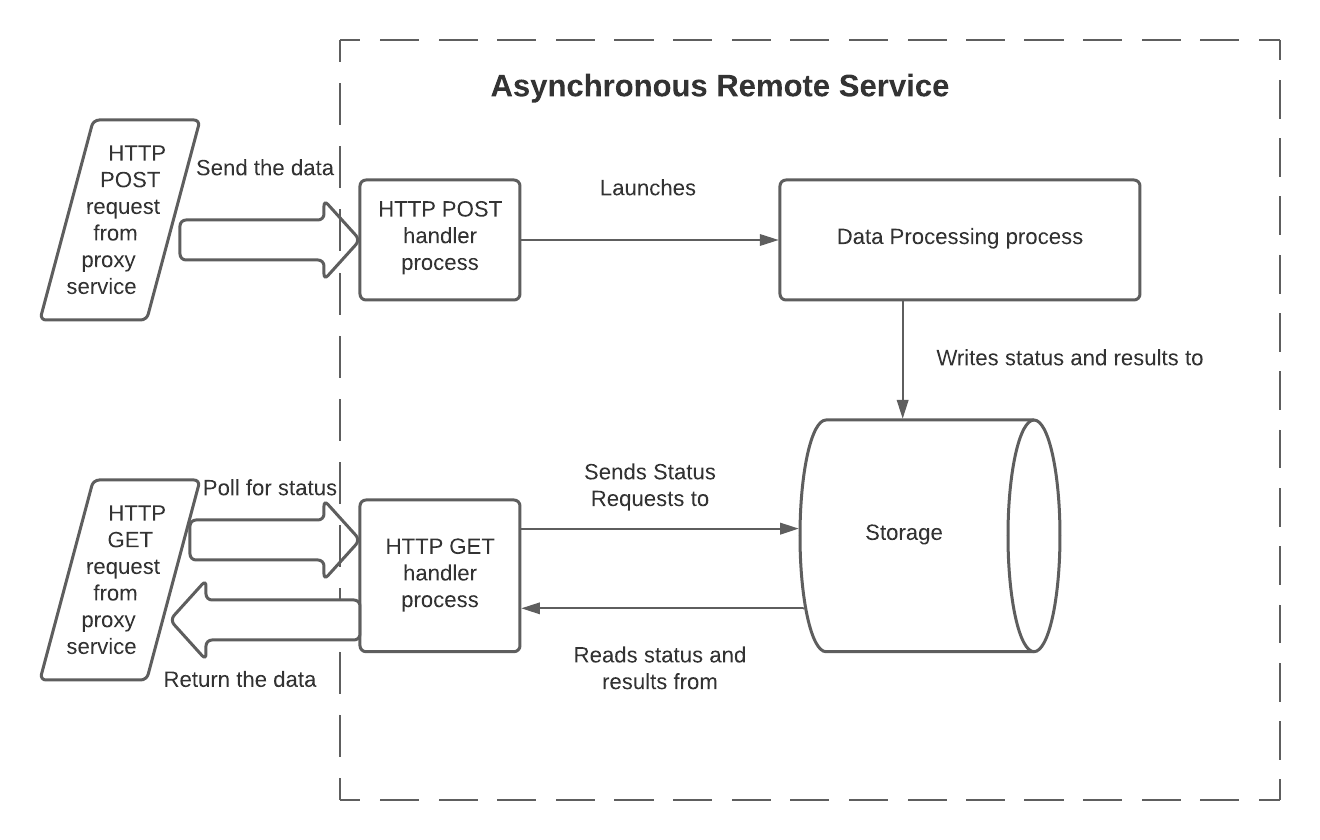
In this model, the processes have the following responsibilities:
The HTTP POST handler:
Reads the input data. In a Lambda Function, this is read from the body of the handler function’s
eventinput parameter.Reads the batch ID. In a Lambda Function, this is read from the header of the
eventinput parameter.Starts the data processing process, and passes it the data and the batch ID. The data is usually passed during the call, but could be passed by writing it to external storage.
Records the batch ID in shared storage that both the data processing process and the HTTP GET handler process can access.
If needed, records that the processing of this batch has not yet finished.
Returns HTTP 202 if no error was detected.
The data processing code:
Reads the input data.
Processes the data.
Makes the result available to the GET handler (either by writing the result data to shared storage, or by providing an API through which to query the results).
Typically, updates this batch’s status (e.g. from
IN_PROGRESStoSUCCESS) to indicate that the results are ready to be read.Exits. Optionally, this process can return an error indicator. Snowflake does not see this directly (Snowflake sees only the HTTP return codes from the POST handler and GET handler), but returning an error indicator from the data processing process might help during debugging.
The GET handler:
Reads the batch ID. In a Lambda Function, this is read from the header of the
eventinput parameter.Reads the storage to get the current status of this batch (e.g.
IN_PROGRESSorSUCCESS).If the processing is still in progress, then return 202.
If the processing has finished successfully, then:
Read the results.
Clean up storage.
Return the results along with HTTP code 200.
If the stored status indicates an error, then:
Clean up storage.
Return an error code.
Note that the GET handler might be called multiple times for a batch if the processing takes long enough that multiple HTTP GET requests are sent.
There are many possible variations on this model. For example:
The batch ID and status could be written at the start of the data processing process rather than at the end of the POST process.
The data processing could be done in a separate function (e.g. a separate Lambda function) or even as a completely separate service.
The data processing code does not necessarily need to write to shared storage. Instead, the processed data could be made available another way. For example, an API could accept the batch ID as a parameter and return the data.
The implementation code should take into account the possibility that the processing will take too long or will fail, and therefore any partial results must be cleaned up to avoid wasting storage space.
The storage mechanism must be sharable across multiple processes (or threads). Possible storage mechanisms include:
Storage mechanisms provided by AWS, such as:
Disk space (e.g. Amazon Elastic File System (EFS) ).
A local database server available through AWS (e.g. Amazon DynamoDB ).
Storage that is outside AWS but accessible from AWS.
The code for each of the 3 processes above can be written as 3 separate Lambda Functions (one for the POST handler, one for the data processing function, and one for the GET handler), or as a single function that can be invoked in different ways.
The sample Python code below is a single Lambda Function that can be called separately for the POST, the data processing, and the GET processes.
Sample code¶
This code shows a sample query with output. The focus in this example is on the three processes and how they interact, not on the shared storage mechanism (DynamoDB) or data transformation (sentiment analysis). The code is structured to make it easy to replace the example storage mechanism and data transformation with different ones.
For simplicity, this example:
Hard-codes some important values (e.g. the AWS region).
Assumes the existence of some resources (e.g. the Jobs table in Dynamo).
Sample call and output¶
Here is a sample call to the asynchronous external function, along with sample output, including the sentiment analysis results:
Notes about the sample code¶
The data processing function is invoked by calling:
The InvocationType should be ‘Event’, as shown above, because the 2nd process (or thread) must be asynchronous and
Eventis the only type of non-blocking call available through theinvoke()method.The data processing function returns an HTTP 200 code. However, this HTTP 200 code is not returned directly to Snowflake. Snowflake does not see any HTTP 200 until a GET polls the status and sees that the data processing function finished processing this batch successfully.