Cortex AISQL Images¶
With Cortex AI Images, you can accomplish the following:
Compare images
Caption images
Classify images
Extract entities from images
Answering questions using data in graphs and charts
You can do those tasks with the following functions:
Input requirements¶
COMPLETE Multimodal can process images with the following characteristics:
Requirement |
Value |
|---|---|
Filename extensions |
|
Stage encryption |
Server-side encryption |
Data type |
Note
Processing files from stages is currently incompatible with custom network policies.
Create a stage for image processing¶
Create a stage suitable for storing the images to be processed. The stage must have a directory table and server-side encryption.
The SQL below creates a suitable internal stage.
CREATE OR REPLACE STAGE input_stage
DIRECTORY = ( ENABLE = true )
ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' );
The following SQL creates an external stage on Amazon S3. Azure and GCP external stages are also supported.
CREATE OR REPLACE STAGE input_stage
URL='s3://<s3-path>/'
DIRECTORY = ( ENABLE = true )
CREDENTIALS = (AWS_KEY_ID = <aws_key_id>
AWS_SECRET_KEY = <aws_secret_key>)
ENCRYPTION = ( TYPE = 'AWS_SSE_S3' );
Note
To automatically refresh the directory table for the external stage when new or updated files are available, pass the
AUTO_REFRESH = true option when creating the stage. For more information, see CREATE STAGE.
Process images¶
The COMPLETE function processes either a single image or multiple images (for example, extracting differences in entities across various images). The function call specifies the following:
The multimodal model to be used
A prompt
The stage path of the image file(s) via a FILE object
Single-image example¶
The following example uses Anthropic’s Claude Sonnet 3.5 model to summarize a pie chart science-employment-slide.jpeg stored in the @myimages stage.
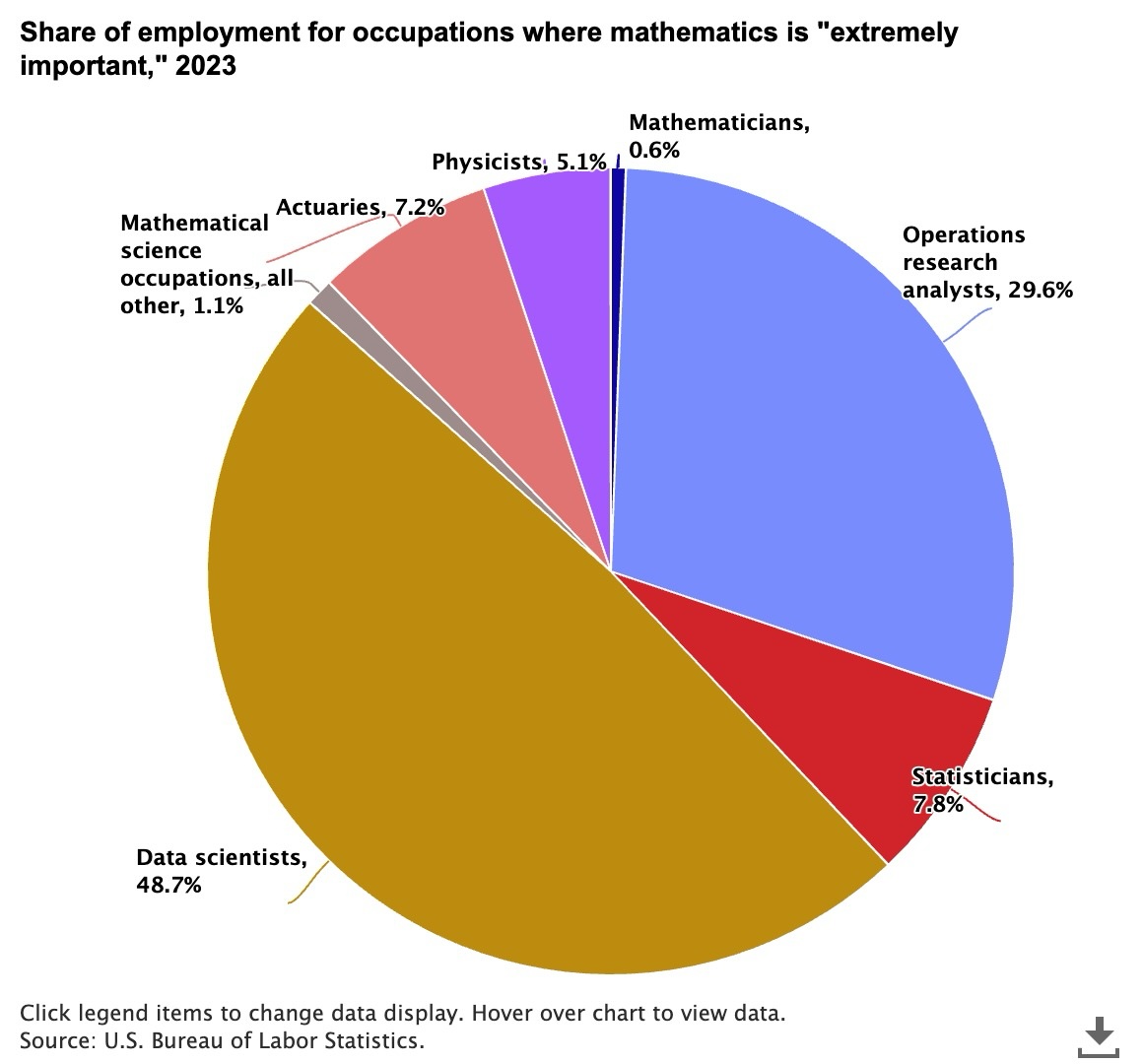
The distribution of occupations where mathematics is considered “extremely important” in 2023¶
SELECT AI_COMPLETE('claude-3-5-sonnet',
'Summarize the insights from this pie chart in 100 words',
TO_FILE('@myimages', 'science-employment-slide.jpeg'));
Response:
This pie chart shows the distribution of occupations where mathematics is considered "extremely important" in 2023.
Data scientists dominate with nearly half (48.7%) of all such positions, followed by operations research analysts
at 29.6%. The remaining positions are distributed among statisticians (7.8%), actuaries (7.2%), physicists (5.1%),
mathematicians (0.6%), and other mathematical science occupations (1.1%). This distribution highlights the growing
importance of data science in mathematics-intensive careers, while traditional mathematics roles represent a smaller
share of the workforce.
Multiple-image example¶
Note
Currently, only Anthropic (claude) and Meta (llama) models can reference multiple images in a single prompt.
Multiple image support for other models may be available in a future release.
Use the PROMPT helper function to process multiple images in a single COMPLETE call. The following example uses
Anthropic’s Claude Sonnet 3.5 model to compare two different ad creatives from the @myimages stage.

Image of two ads for electric cars¶
SELECT AI_COMPLETE('claude-3-5-sonnet',
PROMPT('Compare this image {0} to this image {1} and describe the ideal audience for each in two concise bullets no longer than 10 words',
TO_FILE('@myimages', 'adcreative_1.png'),
TO_FILE('@myimages', 'adcreative_2.png')
));
Response:
First image ("Discover a New Energy"):
• Conservative luxury SUV buyers seeking a subtle transition to electrification
Second image ("Electrify Your Drive"):
• Young, tech-savvy urbanites attracted to bold, progressive automotive design
Model limitations¶
All models available to Snowflake Cortex have limitations on the total number of input and output tokens, known as the model’s context window. The context window size is measured in tokens. Inputs exceeding the context window limit result in an error.
For text models, tokens generally represent approximately four characters of text, so the word count corresponding to a limit is less than the token count.
For image models, the token count per image depends on the vision model’s architecture. Tokens within a prompt (for example, “what animal is this?”) also contribute to the model’s context window.
Model |
Context window (tokens) |
File types |
File size |
Images per prompt |
|---|---|---|---|---|
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3.75 MB [L1] |
20 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3.75 MB [L1] |
20 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3.75 MB [L1] |
20 |
|
200,000 |
.jpg, .jpeg, .png, .webp, .gif |
3.75 MB [L1] |
20 |
|
128,000 |
.jpg, .jpeg, .png, .webp, .gif, .bmp [L2] |
10 MB |
10 |
|
128,000 |
.jpg, .jpeg, .png, .webp, .gif |
10 MB |
10 |
|
128,000 |
.jpg, .jpeg, .png, .webp, .gif, .bmp [L2] |
10 MB |
1 |
Cost considerations¶
Billing scales with the number of tokens processed. The number of tokens per image depends on the architecture of the vision model.
Anthropic (
claude) models’ formula is roughly: tokens = (Width in pixels x Height in pixels) / 750.Mistral (
pixtral) models divide each image into batches of 16x16 pixels and converts each batch to a token. The total number of tokens is equivalent to roughly (Width in pixels / 16) * (Height in pixels / 16).Meta (
llama) models try to tile the image with square tiles. Depending on the image’s aspect ratio and size, the number of tiles can be up to 16, each represented by around 153 tokens.
Note
The COUNT_TOKENS function does not currently support image inputs.
Choosing a vision model¶
The COMPLETE function supports multiple models of varying capability, latency, and cost. To achieve optimal performance per credit, choose a model that aligns with the content size and task complexity.
Model |
MMMU |
Mathvista |
ChartQA |
DocVQA |
VQAv2 |
|---|---|---|---|---|---|
GPT-4o |
68.6 |
64.6 |
85.1 |
88.9 |
77.8 |
claude-3-5-sonnet |
68.0 |
64.4 |
87.6 |
90.3 |
70.7 |
llama-4-maverick |
73.4 |
673.7 |
90 |
94.4 |
|
llama-4-scout |
69.4 |
70.7 |
88.8 |
94.4 |
|
pixtral-large |
64.0 |
69.4 |
88.1 |
85.7 |
67 |
The benchmarks are:
MMMU: Evaluates multimodal models on multidisciplinary tasks that require college-level reasoning.
Mathvista: Mathematical reasoning benchmark within a visual context.
ChartQA: Evaluates complex reasoning questions about charts.
DocVQA and VQv2: Benchmarks for visual question-answering on documents.
Regional availability¶
Support for this feature is available natively to accounts in the following Snowflake regions:
Model
|
AWS US West 2
(Oregon)
|
AWS US East 1
(N. Virginia)
|
AWS Europe Central 1
(Frankfurt)
|
|---|---|---|---|
|
✔ |
✔ |
|
|
|||
|
|||
|
|||
|
✔ |
✔ |
✔ |
|
✔ |
||
|
✔ |
COMPLETE multimodal is available in other regions through Cross-region inference.
Error Conditions¶
Message |
Explanation |
|---|---|
Request failed for external function SYSTEM$COMPLETE_WITH_IMAGE_INTERNAL with remote service error: 400 ‘“invalid image path” |
Either the file extension or the file itself is not accepted by the model. The message might also mean that the file path is incorrect; that is, the file does not exist at the specified location. Filenames are case-sensitive. |
Error in secure object |
May indicate that the stage does not exist. Check the stage name and ensure that the stage exists and is accessible. Be sure
to use the at (@) sign at the beginning of the stage path, such as |
Request failed for external function _COMPLETE_WITH_PROMPT with remote service error: 400 ‘“invalid request parameters: unsupported image format: image/** |
Unsupported image format given to |
Request failed for external function _COMPLETE_WITH_PROMPT with remote service error: 400 ‘“invalid request parameters: Image data exceeds the limit of 5.00 MB” |
The provided image given to |
Legal¶
The data classification of inputs and outputs are as set forth in the following table.
Input data classification |
Output data classification |
Designation |
|---|---|---|
Usage Data |
Customer Data |
Generally available functions are Covered AI Features. Preview functions are Preview AI Features. [1] |
For additional information, refer to Snowflake AI and ML.