Notebooks on Container Runtime¶
Vue d’ensemble¶
You can run Snowflake Notebooks on Container Runtime. Container Runtime is powered by Snowpark Container Services, giving you a flexible container infrastructure that supports building and operationalizing a wide variety of workflows entirely within Snowflake. Container Runtime provides software and hardware options to support advanced data science and machine learning workloads. Compared to virtual warehouses, Container Runtime provides a more flexible compute environment where you can install packages from multiple sources and select compute resources, including GPU machine types, while still running SQL queries on warehouses for optimal performance.
This document describes some considerations for using notebooks on Runtime de conteneur Snowflake. You can also try the Getting Started with Snowflake Notebook Container Runtime quickstart to learn more about using the Container Runtime in your development.
Conditions préalables¶
Before you start using Snowflake Notebooks on Container Runtime, the ACCOUNTADMIN role must complete the notebook setup steps for creating the necessary resources and granting privileges to those resources. For detailed steps, see Configurer l’administrateur.
Create a notebook on Container Runtime¶
When you create a notebook on Container Runtime, you choose a warehouse, runtime, and compute pool to provide the resources to run your notebook. The runtime you choose gives you access to different Python packages based on your use case. Different warehouse sizes or compute pools have different cost and performance implications. All of these settings can be changed later if needed.
Note
Un utilisateur titulaire du rôle ACCOUNTADMIN, ORGADMIN ou SECURITYADMIN ne peut pas créer ou posséder directement un notebook sur Container Runtime. Les éléments Notebooks créés par ou appartenant directement à ces rôles ne pourront pas s’exécuter. Cependant, si un notebook appartient à un rôle et que le rôle ACCOUNTADMIN, ORGADMIN ou SECURITYADMIN hérite de ses privilèges, comme le rôle PUBLIC, vous pouvez ensuite utiliser ce rôle pour exécuter ce notebook.
Pour créer un notebook Snowflake à exécuter sur Container Runtime, procédez comme suit :
Connectez-vous à Snowsight.
Dans le menu de navigation, sélectionnez Projects » Notebooks.
Sélectionnez + Notebook.
Saisissez un nom pour votre notebook.
Sélectionnez une base de données et un schéma dans lesquels stocker votre notebook. Ce paramètre ne peut pas être modifié après la création du notebook.
Note
La base de données et le schéma ne sont nécessaires que pour stocker vos notebooks. Vous pouvez interroger n’importe quelle base de données et n’importe quel schéma auxquels votre rôle a accès depuis votre notebook.
Sélectionnez Run on container pour le Runtime.
Sélectionnez la Runtime version dans les options duCPU ou du GPU.
- Sélectionnez un Compute pool.
Snowflake met à disposition automatiquement deux pools de calcul dans chaque compte pour l’exécution des notebooks : SYSTEM_COMPUTE_POOL_CPU et SYSTEM_COMPUTE_POOL_GPU.
Modifiez l’entrepôt sélectionné à utiliser pour exécuter des requêtes SQL et Snowpark.
Pour créer et ouvrir votre notebook, sélectionnez Create.
Runtime version :
Deux types de versions d’exécution sont disponibles : CPU et GPU. Chaque image de runtime contient un ensemble de base de paquets et de versions Python de base vérifiés et intégrés par Snowflake. Toutes les images de runtime prennent en charge l’analyse, la modélisation et l’apprentissage des données avec Snowpark Python, Snowflake ML et Streamlit.
Pour installer des paquets supplémentaires à partir d’un référentiel public, vous pouvez utiliser pip. Une intégration d’accès externe (EAI) est requise pour que Snowflake Notebooks puisse installer des paquets à partir de points de terminaison externes. Pour configurer des EAIs, voir Configurer l’accès externe pour Snowflake Notebooks. Cependant, si un paquet fait déjà partie de l’image de base, vous ne pouvez pas modifier la version du paquet en installant une version différente via pip install. Pour obtenir la liste des paquets préinstallés, exécutez la commande suivante à partir d’une cellule du notebook :
Compute pool :
Un pool de calcul fournit les ressources de calcul pour le noyau de votre notebook et le code Python. Utilisez des pools de calcul basés sur CPU plus petits pour commencer, et sélectionnez des pools de calcul basés sur GPU de mémoire supérieure pour optimiser les scénarios d’utilisation de GPU intensive tels que la vision par ordinateur ou les LLMs/VLMs.
Notez que chaque nœud de calcul est limité à l’exécution d’un seul notebook par utilisateur à la fois. Vous devez définir le paramètre MAX_NODES sur une valeur supérieure à celle utilisée lors de la création de pools de calcul pour notebooks. Pour un exemple, voir Ressources de calcul. Pour plus de détails sur les pools de calcul Snowpark Container Services, voir Snowpark Container Services : utilisation des pools de calcul.
Lorsqu’un notebook n’est pas utilisé, pensez à l’arrêter pour libérer les ressources de nœud. Vous pouvez fermer un notebook en sélectionnant End session dans le bouton de connexion déroulant.
Si un notebook s’exécute dans Container Runtime, le rôle doit disposer du privilège USAGE sur un pool de calcul plutôt que sur l’entrepôt de ce notebook. Les pools de calcul sont des machines virtuelles basées sur CPU ou GPUgérées par Snowflake. Lors de la création d’un pool de calcul, définissez le paramètre MAX_NODES sur une valeur supérieure à un, car chaque notebook nécessitera un nœud complet pour fonctionner. Pour plus d’informations, voir Snowpark Container Services : utilisation des pools de calcul.
Vous pouvez afficher l’utilisation de vos ressources. Pour plus d’informations, voir À propos des Legacy Snowflake Notebooks.
Note
Sur AWS, les notebooks fonctionnant sur les pools de calcul GPU utilisent le stockage haute performance NVMe comme appareil de démarrage par défaut.
Exécuter un notebook sur Container Runtime¶
Après avoir créé votre notebook, vous pouvez immédiatement commencer à exécuter du code en ajoutant et en exécutant des cellules. Pour obtenir des informations sur l’ajout de cellules, consultez Développez et exécutez du code dans des Snowflake Notebooks.
Importation de davantage de paquets¶
Outre les paquets préinstallés pour que votre notebook soit opérationnel, vous pouvez installer des paquets provenant de sources publiques pour lesquelles vous avez configuré un accès externe. Vous pouvez également utiliser des paquets stockés dans une zone de préparation ou un référentiel privé. Vous devez utiliser le rôle ACCOUNTADMIN ou un rôle capable de créer des intégrations d’accès externes (EAIs) pour pouvoir effectuer la configuration et vous accorder l’accès vous permettant de consulter des points de terminaison externes spécifiques. Utilisez la commande ALTER NOTEBOOK pour activer l’accès externe sur votre notebook. Une fois l’accès accordé, vous verrez apparaître les EAIs dans Notebook settings. Activez les EAIs avant de démarrer l’installation à partir de canaux externes. Pour obtenir des instructions, voir Configurer un notebook avec un accès externe et des secrets.
L’exemple suivant installe un paquet externe à l’aide de pip install dans une cellule de code :
Mettre à jour les paramètres de notebook¶
Vous pouvez à tout moment mettre à jour les paramètres tels que les pools de calcul ou l’entrepôt à utiliser dans Notebook settings, accessible via le menu Actions de notebook  dans le coin supérieur droit.
dans le coin supérieur droit.
L’un des paramètres que vous pouvez mettre à jour dans Notebook settings est le paramètre de délai d’inactivité. Le délai d’inactivité par défaut est d’1 heure et vous pouvez le définir sur un maximum de 72 heures. Pour définir cette valeur dans SQL, utilisez la commande CREATE NOTEBOOK ou ALTER NOTEBOOK pour définir la propriété IDLE_AUTO_SHUTDOWN_TIME_SECONDS propriété du notebook.
Installation de paquets privés¶
Pip prend en charge l’installation de paquets provenant de sources privées avec authentification de base, telles que JFrog Artifactory. Configurez le notebook pour l’intégration de l’accès externe (EAI) afin qu’il puisse accéder au dépôt.
Créez une règle réseau pour spécifier le dépôt auquel vous souhaitez accéder. Par exemple, cette règle réseau spécifie un dépôt JFrog :
Créez un secret qui représente les identifiants de connexion requis pour s’authentifier auprès de l’emplacement réseau externe.
Créez une intégration d’accès externe qui permet l’accès au dépôt :
Associez l’intégration d’accès externe et le secret au notebook.
Pour accéder à la configuration de l’accès externe, sélectionnez le menu
(Notebook actions) en haut à droite de votre notebook.Sélectionnez Notebook settings puis l’onglet External access.
Sélectionnez le EAI pour vous connecter au dépôt.
Le notebook redémarre.
Une fois que le notebook a redémarré, vous pouvez procéder à l’installation à partir du dépôt :
Installer des paquets privés avec une connectivité privée¶
Si votre dépôt privé de paquets nécessite une connectivité privée, suivez les étapes suivantes pour configurer votre compte. Si vous avez besoin d’aide, vous pouvez demander à votre administrateur de compte de définir la règle réseau.
Suivez les étapes décrites dans Sortie réseau par connectivité privée pour définir la sortie du réseau à l’aide de la connectivité privée.
Créez un secret qui représente les identifiants de connexion requis pour s’authentifier auprès de l’emplacement réseau externe.
Créez un EAI avec la règle réseau de l’étape 1. Par exemple :
Associez l’intégration d’accès externe et le secret au notebook.
Pour accéder à la configuration de l’accès externe, sélectionnez le menu
(Notebook actions) en haut à droite de votre notebook.Sélectionnez Notebook settings puis l’onglet External access.
Sélectionnez le EAI pour vous connecter à votre dépôt privé.
Le notebook redémarre.
Après le redémarrage du notebook, vous pouvez fournir l’adresse
--index-urlde votre dépôt :
Exécution de charges de travail ML¶
Les notebooks sur Container Runtime sont bien adaptés à l’exécution de charges de travail ML telles que l’entraînement de modèles et le réglage de paramètres. Les environnements d’exécution sont préinstallés avec les paquets les plus courants de ML. Une fois l’accès à l’intégration externe défini, vous pouvez installer tous les autres paquets dont vous avez besoin à l’aide de !pip install.
Pour une expérience optimale, utilisez les bibliothèques OSS pour développer le modèle ou pour importer des notebooks qui utilisent des composants OSS. Le Container Runtime comporte des APIs optimisées comme les suivantes :
DataConnectorpour une ingestion plus rapide des donnéesAPIs distribuées d’entraînement pour un ajustement de modèle évolutif
APIs distribuées de réglage des hyperparamètres pour utiliser efficacement toutes les ressources disponibles.
Pour plus d’informations, voir Runtime de conteneur Snowflake.
Note
L’environnement d’exécution étant préinstallé avec de nombreux paquets, tout changement de version nécessite un redémarrage du noyau. Pour plus d’informations, voir Explore Legacy Notebooks.
Utiliser des bibliothèques OSS ML¶
L’exemple suivant utilise une bibliothèque OSS ML, xgboost, avec une session Snowpark active pour récupérer les données directement en mémoire pour l’apprentissage :
Limitations¶
Après le démarrage d’une session du notebook Container Runtime, celle-ci peut s’exécuter jusqu’à sept jours sans interruption. Après sept jours, elle peut être interrompue et fermée en cas d’événement planifié de maintenance du service SPCS. Les paramètres de temps d’inactivité du notebook continuent de s’appliquer. Pour plus de détails sur la maintenance du service SPCS, voir Maintenance du pool de calcul.
Considérations relatives aux coûts et à la facturation¶
Lors de l’exécution de notebooks sur Container Runtime, vous pouvez encourir des coûts de calcul d’entrepôt et des :doc:` coûts de calcul SPCS</developer-guide/snowpark-container-services/accounts-orgs-usage-views>`. Les entrepôts sont nécessaires non seulement pour exécuter des requêtes, mais aussi pour prendre en charge certaines fonctionnalités Front End dans les Snowflake Notebooks. Par exemple, lorsque vous utilisez un pool de calcul pour l’exécution de Python, un entrepôt peut toujours être nécessaire pour le rendu des sorties ou la gestion de composants interactifs.
Les Snowflake Notebooks s’appuient sur des entrepôts virtuels pour exécuter des requêtesSQL et Snowpark. Par conséquent, vous pouvez encourir des coûts de calcul d’entrepôt lors de l’exécution des cellules SQL ou des requêtes pushdown Snowpark dans des cellules Python.
Le schéma suivant montre où le calcul a lieu pour les cellules SQL, Snowpark et Python dans un notebook :
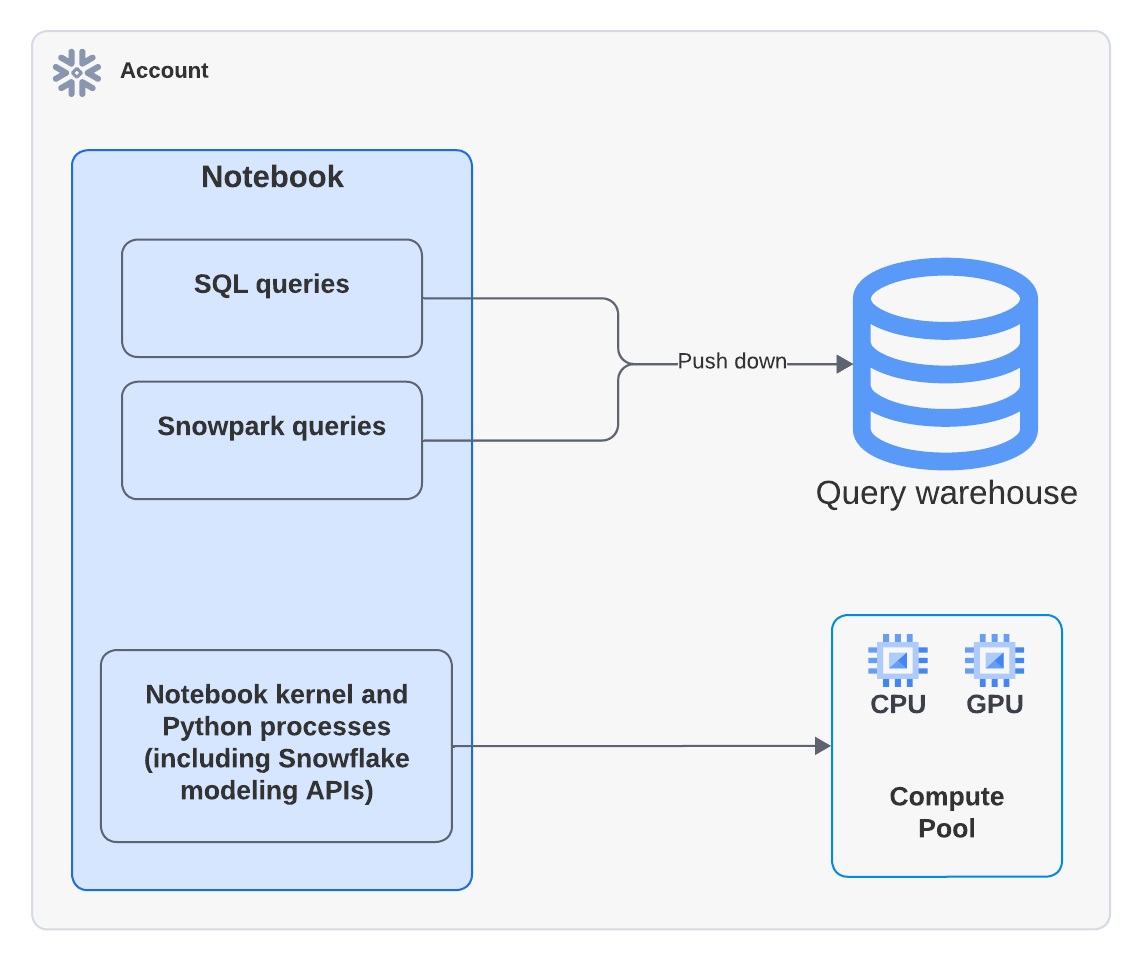
Note
Lorsque vous exécutez un notebook qui utilise un pool de calcul, le code Python s’exécute sur le pool de calcul. Cependant, vous pouvez voir une activité dans Query History montrant qu’un entrepôt a été utilisé pour exécuter la commande EXECUTE NOTEBOOK. Il s’agit d’un comportement attendu. L’entrepôt est utilisé brièvement pour initialiser l’environnement d’exécution mais ne consomme aucun crédit d’entrepôt. L’ensemble de l’exécution du code est gérée par le pool de calcul.
L’exemple Python suivant utilise la bibliothèque xgboost. Les données sont extraites dans le conteneur et le calcul est entièrement géré par Snowpark Container Services:
Pour en savoir plus sur les coûts des entrepôts, voir Vue d’ensemble des entrepôts.