Notebooks on Container Runtime¶
概要¶
You can run Snowflake Notebooks on Container Runtime. Container Runtime is powered by Snowpark Container Services, giving you a flexible container infrastructure that supports building and operationalizing a wide variety of workflows entirely within Snowflake. Container Runtime provides software and hardware options to support advanced data science and machine learning workloads. Compared to virtual warehouses, Container Runtime provides a more flexible compute environment where you can install packages from multiple sources and select compute resources, including GPU machine types, while still running SQL queries on warehouses for optimal performance.
This document describes some considerations for using notebooks on Snowflake Container Runtime. You can also try the Getting Started with Snowflake Notebook Container Runtime quickstart to learn more about using the Container Runtime in your development.
前提条件¶
Before you start using Snowflake Notebooks on Container Runtime, the ACCOUNTADMIN role must complete the notebook setup steps for creating the necessary resources and granting privileges to those resources. For detailed steps, see 管理者の設定.
Create a notebook on Container Runtime¶
When you create a notebook on Container Runtime, you choose a warehouse, runtime, and compute pool to provide the resources to run your notebook. The runtime you choose gives you access to different Python packages based on your use case. Different warehouse sizes or compute pools have different cost and performance implications. All of these settings can be changed later if needed.
注釈
ACCOUNTADMIN、 ORGADMIN、 SECURITYADMIN のロールを持つユーザーは、Container Runtime上でノートブックを直接作成したり、所有したりすることはできません。これらのロールが作成したNotebooksや直接所有するNotebooksは実行できません。しかし、 ACCOUNTADMIN、 ORGADMIN、 SECURITYADMIN のロールが権限を継承するロール(PUBLIC ロールなど)がノートブックを所有している場合、それらのロールを使用してそのノートブックを実行することができます。
Container Runtime上で実行するSnowflake Notebookを作成するには、以下の手順に従います。
Snowsight にサインインします。
ナビゲーションメニューで Projects » Notebooks を選択します。
+ Notebook を選択します。
ノートブックの名前を入力します。
ノートブックを格納するデータベースとスキーマを選択します。これらはノートブック作成後に変更することはできません。
注釈
データベースとスキーマは、ノートブックを格納するためだけに必要です。ノートブック内で、自分のロールがアクセスできるデータベースやスキーマをクエリすることができます。
Runtime に Run on container を選択します。
CPU または GPU オプションから Runtime version を選択します。
- Compute pool を選択します。
Snowflakeは、各アカウントでノートブック(SYSTEM_COMPUTE_POOL_CPU、 SYSTEM_COMPUTE_POOL_GPU)を実行するための2つの コンピューティングプール を自動的にプロビジョニングします。
SQL クエリとSnowparkクエリを実行するために使用する選択済みのウェアハウスを変更します。
ノートブックを作成して開くには、 Create を選択します。
Runtime version:
使用可能なランタイムバージョンタイプは CPU および GPU です。それぞれのランタイムの画像には、Snowflakeによって検証・統合されたPythonパッケージとバージョンの基本セットが含まれています。すべてのランタイムの画像は、Snowpark Python、Snowflake ML、およびStreamlitによるデータ解析、モデリング、およびトレーニングをサポートします。
パブリックリポジトリから追加パッケージをインストールするには、pipを使用することができます。Snowflake Notebooksが外部エンドポイントからパッケージをインストールするには、外部アクセス統合(EAI)が必要です。EAIs を構成するには、 Snowflake Notebooks の外部アクセスの設定 をご参照ください。ただし、パッケージがすでにベース画像の一部になっている場合、pipインストールで異なるバージョンをインストールしても、パッケージのバージョンを変更することはできません。事前インストール済みのパッケージのリストについては、ノートブックのセルから以下のコマンドを実行してください。
Compute pool:
コンピューティングプールは、ノートブックカーネルとPythonコードにコンピューティングリソースを提供します。より小さな CPU ベースのコンピューティングプールの使用からスタートし、コンピュータービジョンや LLMs/VLMs などの負荷の高い GPU 使用シナリオに最適化するために、より高メモリの GPU ベースのコンピューティングプールを選択するようにします。
各コンピュートノードが一度に実行できるノートブックは、ユーザー当たり1つに制限されています。ノートブックのコンピューティングプールを作成する際には、 MAX_NODES パラメーターを1より大きい値に設定する必要があります。例については、 コンピューティングリソース をご参照ください。Snowpark Container Services コンピューティングプールの詳細については、 Snowpark Container Services: コンピューティングプールの操作 をご参照ください。
ノートブックが使用されていないときは、ノードのリソースを解放するためにシャットダウンすることを検討してください。接続ドロップダウンから End session を選択すると、ノートブックをシャットダウンできます。
Container Runtime上でノートブックが実行される場合、ロールは、ノートブックウェアハウス上ではなく、コンピューティングプール上で USAGE 権限を必要とします。コンピューティングプールは、Snowflakeによって管理される CPU ベースまたは GPU ベースの仮想マシンです。コンピューティングプールを作成する際には、 MAX_NODES パラメーターを1より大きくセットしてください。なぜなら、各ノートブックは、実行するために1つのフルノードを必要とするからです。詳細については、 Snowpark Container Services: コンピューティングプールの操作 をご参照ください。
リソースの利用状況を表示できます。詳細については、 Legacy Snowflake Notebooksについて をご参照ください。
注釈
AWS では、 GPU コンピューティングプール上で動作するノートブックは、デフォルトのブートデバイスとしてハイパフォーマンスな NVMe ストレージを使用します。
Container Runtimeでノートブックを実行する¶
ノートブックを作成したら、セルを追加して実行することで、すぐにコードを実行し始めることができます。セルの追加については、 Snowflake Notebooks でコードを開発し、実行します。 をご参照ください。
追加パッケージのインポート¶
ノートブックを起動するためのプリインストールパッケージに加え、外部アクセスを設定したパブリックソースからパッケージをインストールすることができます。ステージやプライベートリポジトリに格納されているパッケージを使用することもできます。ACCOUNTADMIN ロール、または外部アクセス統合を作成できるロール(EAIs)を使用して、特定の外部エンドポイントへのアクセスをセットアップし、アクセス権を付与する必要があります。ノートブックの外部アクセスを有効にするには、 ALTER NOTEBOOK コマンドを使用します。アクセス権が付与されると、 Notebook settings に EAIs が表示されます。外部チャンネルからインストールを開始する前に、 EAIs を切り替えます。手順については、 外部アクセスとシークレットを持つノートブックの構成 をご参照ください。
以下の例では、コードセル内でpipインストールを使って外部パッケージをインストールします。
ノートブック設定の更新¶
どのコンピューティングプールやウェアハウスを使用するかなどの設定は、右上の  ノートブックアクション メニューからアクセスできる Notebook settings で随時更新できます。
ノートブックアクション メニューからアクセスできる Notebook settings で随時更新できます。
Notebook settings で更新できる設定の中に、アイドルタイムアウト設定があります。アイドルタイムアウトのデフォルトは1時間で、最大72時間まで設定できます。SQL でこれを設定するには、 CREATE NOTEBOOK または ALTER NOTEBOOK コマンドを使用して、ノートブックの IDLE_AUTO_SHUTDOWN_TIME_SECONDS プロパティを設定します。
プライベートパッケージのインストール¶
Pip は、 基本認証コード を持つプライベートなソース JFrog Artifactory などからのパッケージのインストールをサポートしています。外部アクセス統合 (EAI) 用にノートブックを構成し、リポジトリにアクセスできるようにします。
アクセスするリポジトリを指定するネットワークルールを作成します。たとえば、このネットワークルールは JFrog リポジトリを指定します。
外部ネットワークの場所で認証するために必要な認証情報を表すシークレットを作成します。
リポジトリへのアクセスを許可する外部アクセス統合 を作成します。
外部アクセス統合とシークレットをノートブックに関連付けます。
外部アクセス構成にアクセスするには、ノートブックの右上にある
(Notebook actions メニュー) を選択します。Notebook settings を選択し、 External access タブを選択します。
EAI を選択してリポジトリに接続します。
ノートブックが再起動します。
Notebooks が再起動したら、リポジトリからインストールできます。
プライベート接続によるプライベートパッケージのインストール¶
プライベートパッケージリポジトリにプライベート接続が必要な場合、以下の手順に従ってアカウントを構成してください。サポートが必要な場合は、アカウント管理者と連携してネットワークルールをセットアップすることができます。
プライベート接続を使用したネットワークエグレス の手順に従って、プライベート接続を使用したネットワーク・イグレスをセットアップしてください。
外部ネットワークの場所で認証するために必要な認証情報を表すシークレットを作成します。
ステップ1のネットワークルールで EAI を作成します。例:
外部アクセス統合とシークレットをノートブックに関連付けます。
外部アクセス構成にアクセスするには、ノートブックの右上にある
(Notebook actions メニュー) を選択します。Notebook settings を選択し、 External access タブを選択します。
EAI を選択してプライベートリポジトリに接続します。
ノートブックが再起動します。
Notebooksが再起動したら、リポジトリの
--index-urlをプロバイダーに指定します:
ML ワークロードの実行¶
Container Runtime上のNotebooksは、モデルトレーニングやパラメーターチューニングなどの ML ワークロードの実行に適しています。ランタイムは一般的な ML パッケージにプリインストールされています。外部統合アクセスをセットアップすれば、 !pip install を使って必要なパッケージをインストールすることができます。
最適なエクスペリエンスを得るには、 OSS ライブラリを使用してモデルを開発するか、 OSS コンポーネントを使用するノートブックをインポートしてください。Container Runtimeには、以下のような最適化された APIs があります。
より高速なデータ取り込みのための
DataConnectorスケーラブルなモデルフィッティングのための分散トレーニング APIs
利用可能なすべてのリソースを効率的に活用するための分散ハイパーパラメーターチューニング APIs。
詳細については、 Snowflake Container Runtime をご参照ください。
注釈
ランタイムには多くのパッケージがプリインストールされているため、バージョンを変更するにはカーネルの再起動が必要です。詳細については、 Explore Legacy Notebooks をご参照ください。
OSS ML ライブラリの使用¶
以下の例では、 OSS ML ライブラリ、 xgboost、アクティブなSnowparkセッションを使用して、トレーニングのためにデータをメモリに直接フェッチします。
制限事項¶
Container Runtimeノートブックセッションの開始後、中断することなく最大7日間実行できます。7日経過後、 SPCS サービスメンテナンスイベントが予定されている場合は、中断されシャットダウンされることがあります。ノートブックのアイドル時間設定はそのまま適用されます。SPCS サービスメンテナンスの詳細については、 コンピューティングプールのメンテナンス を参照してください。
コストと請求の考慮事項¶
コンテナランタイムでノートブックを実行する場合、 ウェアハウスコンピューティング と SPCSコンピューティングテスト の両方が発生する可能性があります。ウェアハウスは、クエリの実行だけでなく、 Snowflake Notebooks の特定のフロントエンド機能をサポートするためにも必要です。たとえば、Pythonの実行にコンピューティングプールを使用する場合でも、出力のレンダリングやインタラクティブなコンポーネントの処理のためにウェアハウスが必要になる場合があります。
Snowflake Notebooks は仮想ウェアハウスを利用して SQL およびSnowparkクエリを効率的に実行します。その結果、Pythonセルの SQLセルまたはSnowparkプッシュダウンクエリ実行時にウェアハウスのコンピューティングコストが発生する可能性があります。
次の図は、ノートブック内の SQL 、Snowpark、Pythonセルの計算が行われる場所を示しています。
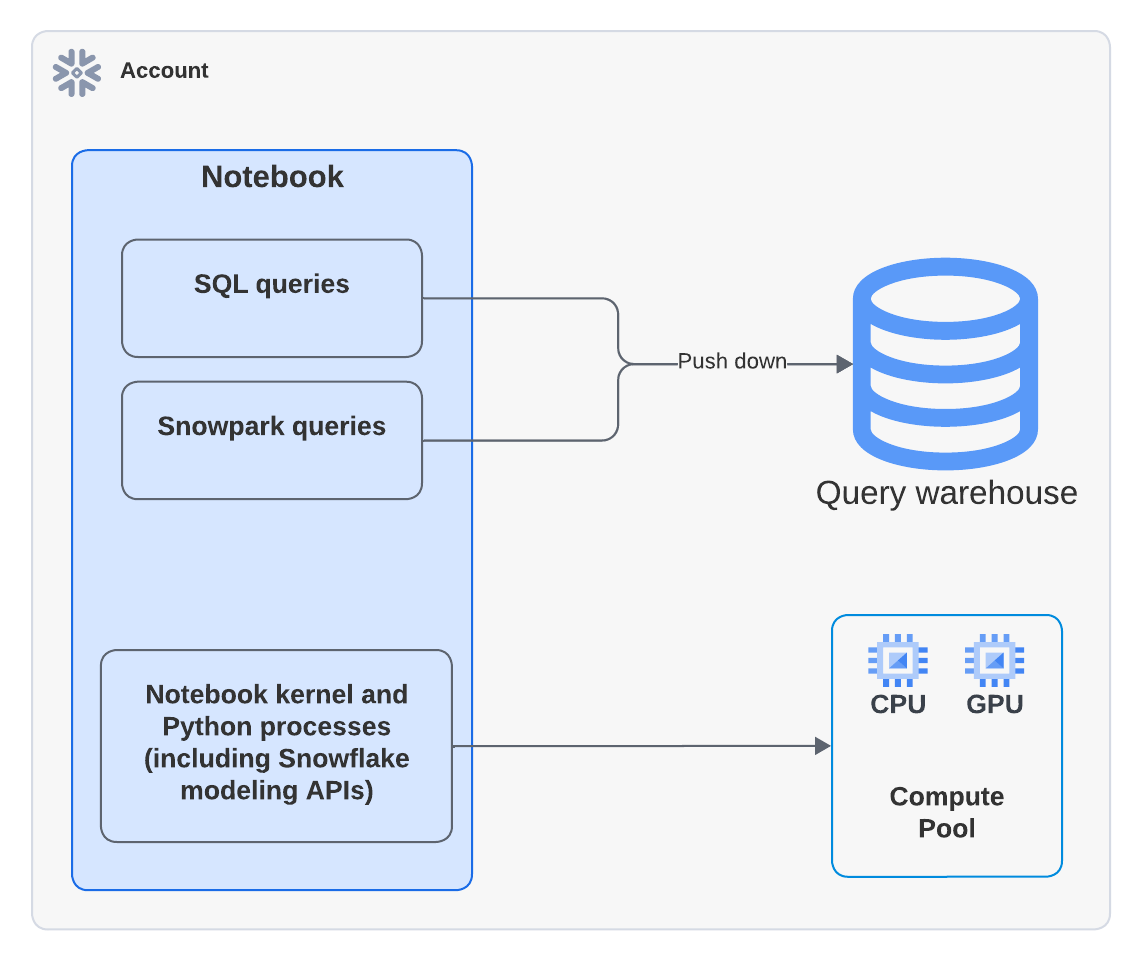
注釈
コンピューティングプールを使用するノートブックを実行すると、Pythonコードはコンピューティングプール上で実行されます。ただし、 EXECUTE NOTEBOOK コマンドを実行するためにウェアハウスが使用されたことを示すでアクティビティが Query History に表示される場合があります。これは想定内の動作です。ウェアハウスは実行環境を初期化するために一時的に使用されますが、ウェアハウスのクレジットは消費するません。すべてのコードの実行は、コンピューティングプールによって処理されます。
たとえば、以下のPythonの例では、 xgboost ライブラリを使用しています。データはコンテナに取り込まれ、コンピューティングは完全に Snowpark Container Services によって処理されます。
ウェアハウスのコストについては、 ウェアハウスの概要 をご覧ください。