Développez et exécutez du code dans des Snowflake Notebooks¶
Cette rubrique décrit comment écrire et exécuter du code SQL, Python et Markdown dans Snowflake Notebooks.
Principes de base des cellules des notebooks¶
Cette section présente quelques opérations de base sur les cellules. Lorsque vous créez un notebook, trois cellules d’exemple sont affichées. Vous pouvez modifier ces cellules ou en ajouter de nouvelles.
Créer une nouvelle cellule¶
Snowflake Notebooks prend en charge trois types de cellules : SQL, python et Markdown. Pour créer une nouvelle cellule, vous pouvez soit survoler une cellule existante, soit faire défiler la page jusqu’au bas du notebook, puis sélectionner l’un des boutons correspondant au type de cellule que vous souhaitez ajouter.

Changez la langue d’une cellule existante en utilisant l’une des méthodes suivantes :
Sélectionnez le menu déroulant de la langue et choisissez une autre langue.
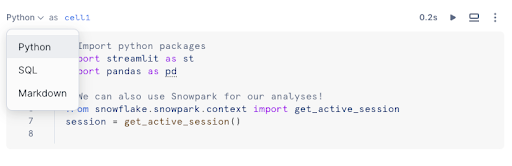
Utilisez les raccourcis clavier.
Modifier une cellule¶
Pour éviter les conflits d’édition, un seul utilisateur peut modifier une cellule à la fois. Si un autre utilisateur tente de modifier une cellule active, une notification s’affiche. La cellule devient disponible pour l’édition après 60 secondes d’inactivité.
Déplacer des cellules¶
Vous pouvez déplacer une cellule soit en la faisant glisser à l’aide de votre souris, soit en utilisant le menu d’actions :
(Option 1) Passez votre souris sur la cellule existante que vous souhaitez déplacer. Sélectionnez l’icône
 (glisser-déposer) sur le côté gauche de la cellule et déplacez la cellule vers son nouvel emplacement.
(glisser-déposer) sur le côté gauche de la cellule et déplacez la cellule vers son nouvel emplacement.(Option 2) Sélectionnez le menu vertical indiqué par une ellipse
 (actions). Sélectionnez ensuite l’action appropriée.
(actions). Sélectionnez ensuite l’action appropriée.
Note
Pour déplacer le curseur d’une cellule à l’autre, utilisez les flèches vers le haut and vers le bas.
Supprimer une cellule¶
Pour supprimer une cellule, effectuez les étapes suivantes dans un notebook :
Sélectionnez le menu vertical indiqué par une ellipse
(plus d’actions).Sélectionnez Delete.
Sélectionnez à nouveau Delete pour confirmer.
Vous pouvez également utiliser le raccourci clavier pour supprimer une cellule.
Pour les considérations relatives à l’utilisation de Python et des cellules SQL, voir Considérations relatives à l’utilisation de notebooks.
Exécuter des cellules dans Snowflake Notebooks¶
Pour exécuter des cellules Python et SQL dans des Snowflake Notebooks, vous pouvez :
Exécuter une seule cellule : Choisissez cette option lorsque vous effectuez des mises à jour fréquentes du code.
Appuyez sur CMD + Retour sur un clavier Mac, ou sur CTRL + Entrée sur un clavier Windows.
Sélectionnez
 , ou Run this cell only.
, ou Run this cell only.
Run all cells in a notebook in sequential order : Choisissez cette option avant de présenter ou de partager un notebook pour vous assurer que les destinataires voient les informations les plus récentes. Cette option exécute toutes les cellules de code SQL et Python dans le notebook, de haut en bas. Si une erreur survient dans une cellule, l’exécution s’arrête et les cellules suivantes ne s’exécutent pas. Ce comportement s’applique également aux notebook planifiés. Par exemple, si vous exécutez un notebook comportant 10 cellules et que la cellule 2 contient une erreur de syntaxe SQL, le notebook s’arrêtera après la cellule 2.
Appuyez sur CMD + Maj + Retour sur un clavier Mac, ou sur CTRL + Maj + Entrée sur un clavier Windows.
Sélectionnez Run all.
Exécuter une cellule et passer à la cellule suivante : choisissez cette option pour exécuter une cellule et passer à la cellule suivante plus rapidement.
Appuyez sur Maj + Retour sur un clavier Mac, ou sur Maj + Entrée sur un clavier Windows.
Sélectionnez le menu des points de suspension verticaux
(plus d’actions) d’une cellule et choisissez Run cell and advance.
Exécuter tous les éléments ci-dessus : choisissez cette option lorsque vous exécutez une cellule qui fait référence aux résultats des cellules précédentes.
Sélectionnez le menu des points de suspension verticaux
(plus d’actions) d’une cellule et choisissez Run all above.
Exécuter tous les éléments ci-dessous : choisissez cette option lorsque vous exécutez une cellule dont dépendent d’autres cellules. Cette option exécute la cellule actuelle et toutes les cellules suivantes.
Sélectionnez le menu des points de suspension verticaux
(plus d’actions) d’une cellule et choisissez Run all below.
Lorsqu’une cellule est en cours d’exécution, les autres requêtes d’exécution sont mises en file d’attente et seront exécutées une fois que la cellule en cours d’exécution aura terminé.
Réduire et développer les cellules¶
Vous pouvez contrôler la partie visible d’un notebook en sélectionnant l’une des options d’affichage des cellules proposées en haut de ce notebook :
Sélectionnez le menu vertical indiqué par une ellipse
(plus d’actions).Sélectionnez Show/hide all et choisissez l’option appropriée :
Show all : affiche à la fois le code et les résultats pour chaque cellule.
Show code only : cache les résultats et n’affiche que les cellules de code.
Show results only : cache le code et n’affiche que la sortie.
Hide all : réduit à la fois le code et les résultats pour toutes les cellules.
Ces options sont utiles lorsque :
Vous souhaitez vous concentrer sur la lecture du code ou l’examen des résultats.
Vous présentez ou partagez votre notebook.
Vous avez besoin de naviguer plus efficacement dans de grands notebooks.
Cellules en double¶
La duplication d’une cellule peut être utile dans les cas suivants :
Test des variantes d’une requête ou d’une fonction.
Débogage sans écraser la version de travail.
Comparaison de différentes sorties côte à côte.
Réutilisation du code ou modification d’une cellule existante sans perte de l’original.
Pour dupliquer une cellule d’un notebook :
Dans la cellule à dupliquer, sélectionnez le menu ellipse verticale
(plus d’actions).Sélectionnez Duplicate.
Une copie de la cellule apparaît immédiatement sous l’original.
Minimap des cellules¶
La minimap des cellules apparaît dans la barre latérale droite du notebook et fournit une liste compacte et déplaçable de toutes des cellules qu’il contient. Chaque entrée de la minimap correspond à une cellule de code ou de texte et reflète l’ordre dans lequel les cellules apparaissent.
Current cell : la cellule sélectionnée est mise en évidence sur la minimap.
Reordering : faites glisser et déposez des éléments dans la minimap pour modifier rapidement l’ordre des cellules dans le notebook.
Navigation : cliquez sur le nom d’une cellule dans la minimap pour accéder directement à cette cellule.
Cette fonction est utile pour naviguer dans des notebook de grande taille et pour réorganiser le contenu plus efficacement.
Exécution de notebooks avec des paramètres¶
Lorsque vous utilisez la commande EXECUTE NOTEBOOK pour exécuter un notebook, vous pouvez transmettre des arguments au notebook. Dans une cellule Python du notebook, vous pouvez accéder à ces arguments en utilisant la variable sys.argv, qui est une liste Python intégrée contenant des arguments de ligne de commande.
En passant des arguments aux notebooks vous pouvez personnaliser le comportement des notebooks. Vous pouvez :
Personnaliser l’exécution du notebook.
Réutiliser le même notebook pour plusieurs entrées.
Prendre en charge l’automatisation ou la planification des tâches.
Exemples¶
Dans une cellule Python du notebook, vous pouvez accéder aux arguments en utilisant la variable sys.argv.
Voir tous les arguments transmis au notebook¶
Imprimez la liste complète des arguments transmis au notebook.
Si le notebook est exécuté avec cette commande :
La sortie sera :
Imprimer chaque argument¶
Effectuer une boucle dans chaque argument et imprimer chaque argument individuellement.
La sortie sera :
Accéder à un argument spécifique¶
Accédez au deuxième argument.
La sortie sera :
Analyser un argument contenant des valeurs séparées par des virgules¶
Si un argument contient une liste de valeurs séparées par des virgules, vous pouvez la diviser en valeurs individuelles.
La sortie sera :
Vous pouvez également parcourir les valeurs en boucle :
Extraire un argument contenant une paire clé-valeur¶
Si un argument comprend une paire clé-valeur (par exemple, key=value), extrayez la valeur.
La sortie sera :
Syntaxe alternative pour une seule chaîne¶
Vous pouvez définir une variable de session à la valeur d’un argument et transmettre la variable de session au notebook.
Afficher les résultats d’une exécution paramétrée¶
Pour voir le résultat d’une exécution du notebook qui a été déclenchée à l’aide de EXECUTE NOTEBOOK :
Connectez-vous à Snowsight.
Dans le menu de navigation, sélectionnez Projects » Notebooks.
Sélectionnez l’icône Calendar.
Sélectionnez View run history.
Recherchez l’exécution du notebook et ouvrez le résultat.
Un notebook en lecture seule s’ouvre contenant le résultat de cette exécution.
Remarques¶
sys.argvne contient que les chaînes passées via EXECUTE NOTEBOOK.Seules les chaînes sont prises en charge. Si un autre type de données (tel qu’un nombre entier) est transmis, il sera interprété comme NULL. Pour plus d’informations, voir EXECUTE NOTEBOOK.
Vérifier le statut de la cellule¶
Le statut de l’exécution de la cellule est indiqué par les couleurs affichées par la cellule. Cette couleur de statut est affichée à deux endroits, sur le côté gauche de la cellule et dans la carte de navigation de la cellule de droite.
Couleur du statut de la cellule :
Point bleu : La cellule a été modifiée mais n’a pas encore été exécutée.
Rouge : La cellule a été exécutée dans la session en cours et une erreur s’est produite.
Vert : La cellule s’est exécutée sans erreur dans la session en cours.
Vert clignotant : La cellule est en cours d’exécution.
Gris : La cellule a été exécutée lors d’une session précédente et les résultats affichés sont ceux de la session précédente. Les résultats des cellules de la session interactive précédente sont conservés pendant 7 jours. Session interactive signifie que l’utilisateur exécute le notebook de manière interactive dans l”Snowsight plutôt que ceux qui ont été exécutés par une planification ou la commande EXECUTE NOTEBOOK SQL.
Gris clignotant : La cellule est en attente d’exécution après que vous avez sélectionné Run All.
Note
Les cellules Markdown n’affichent aucun statut.
Une fois l’exécution d’une cellule terminée, la durée de l’exécution est affichée en haut de la cellule. Sélectionnez ce texte pour voir les détails de l’exécution, y compris les heures de début et de fin et le temps total écoulé.
Les cellules SQL contiennent des informations supplémentaires, telles que l’entrepôt utilisé pour exécuter la requête, les lignes retournées et un lien hypertexte vers la page d’ID de la requête.
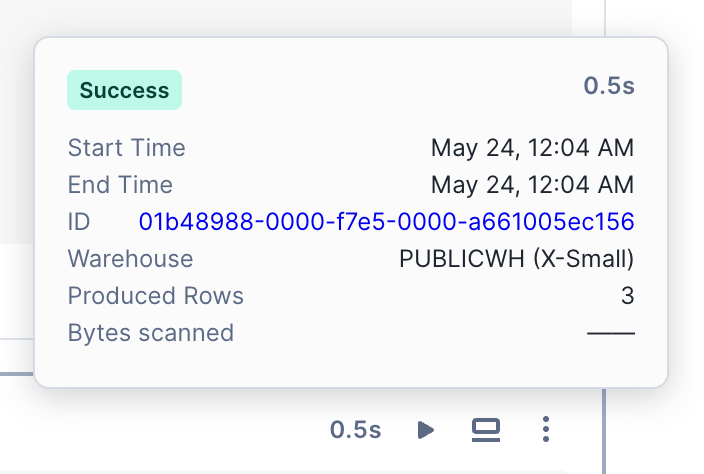
Arrêter une cellule en cours d’exécution.¶
Pour arrêter l’exécution de toute cellule de code en cours, sélectionnez Stop en haut à droite de la cellule. Vous pouvez également sélectionner Stop en haut à droite de la page de Notebooks. Pendant l’exécution des cellules, Run all devient Stop.
Cette opération arrête l’exécution de la cellule en cours et de toutes les cellules suivantes dont l’exécution a été planifiée.
Raccourcis clavier¶
Les Snowflake Notebooks prennent en charge divers raccourcis clavier afin d’accélérer votre processus de développement.
Vous pouvez également consulter la liste des raccourcis clavier en sélectionnant l’icône du clavier dans le coin inférieur droit, puis en sélectionnant Keyboard shortcuts.
Tâche |
MacOS |
Windows |
|---|---|---|
Exécuter toutes les cellules |
CMD + Maj + Retour |
CTRL + Maj + Entrer |
Supprimer la cellule sélectionnée |
CMD + Retour |
CTRL + Entrer |
Exécuter la cellule sélectionnée et passer à la cellule suivante |
Maj + Retour |
Maj + Entrer |
Passer d’une cellule à l’autre |
Flèche haut et Flèche bas |
Flèche haut et Flèche bas |
Arrêter toutes les cellules |
ii |
ii |
Effectuer une recherche dans la cellule |
CMD + f |
CTRL + f |
Déplacer d’une cellule vers le haut |
CMD + SHIFT + Flèche haut |
CTRL + SHIFT + Flèche haut |
Déplacer d’une cellule vers le bas |
CMD + SHIFT + Flèche bas |
CTRL + SHIFT + Flèche bas |
Ajouter une cellule au-dessus de la cellule sélectionnée |
a |
a |
Ajouter une cellule sous la cellule actuellement sélectionnée |
b |
b |
Supprimer la cellule actuellement sélectionnée |
dd ou DELETE |
dd ou DELETE |
Convertir une cellule SQL ou Python en cellule Markdown |
m |
m |
Convertir une cellule en cellule de code :
|
y |
y |
Afficher les raccourcis clavier |
Shift + ? |
Shift + ? |
En outre, vous pouvez utiliser les mêmes raccourcis clavier que pour les feuilles de calcul. Voir Exécution de tâches à l’aide des raccourcis clavier.
Formater du texte avec Markdown¶
Pour inclure le format Markdown dans votre notebook, ajoutez une cellule Markdown :
Utilisez un raccourci clavier et sélectionnez Markdown, ou sélectionnez + Markdown.
Sélectionnez l’icône en forme de crayon Edit markdown ou double-cliquez sur la cellule et commencez à écrire en Markdown.
Vous pouvez saisir du Markdown valide pour formater une cellule de texte. Au fur et à mesure que vous tapez, le texte formaté apparaît sous la syntaxe Markdown.
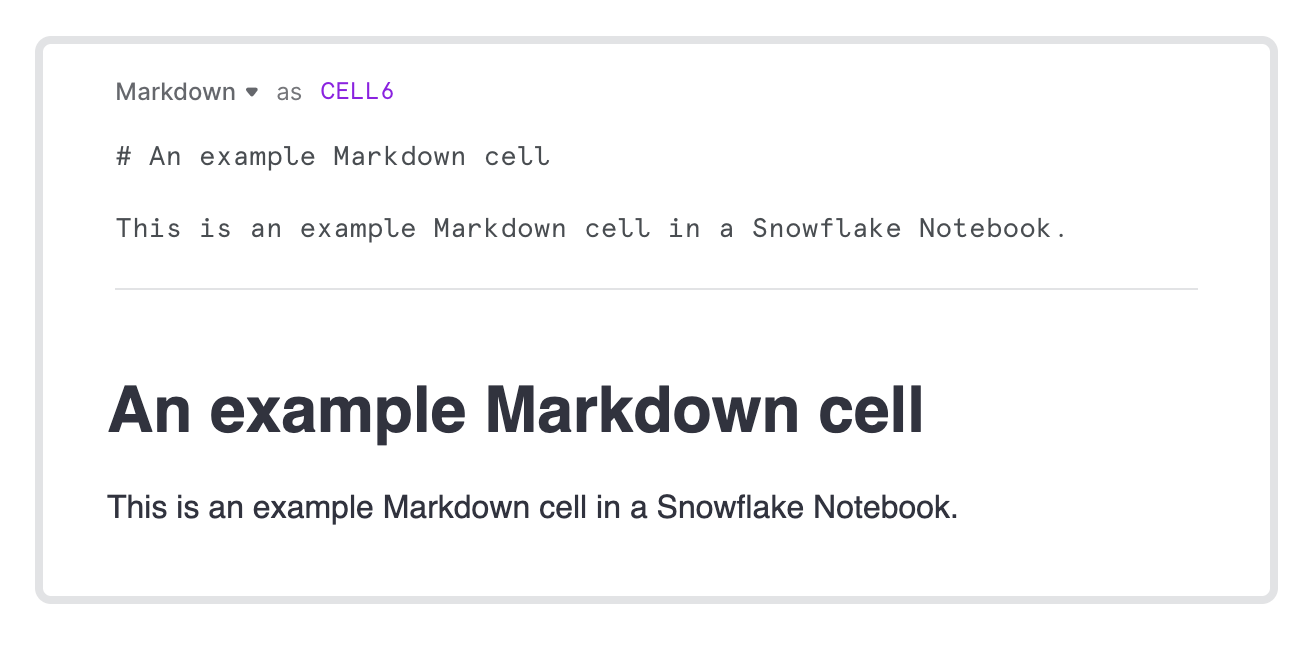
Pour ne voir que le texte formaté, sélectionnez l’icône de coche Done editing.

Note
Les cellules Markdown ne prennent actuellement pas en charge le rendu HTML.
Notions de base sur Markdown¶
Cette section décrit la syntaxe Markdown de base pour vous aider à démarrer.
En-têtes
Niveau de titre |
Syntaxe Markdown |
Exemple |
|---|---|---|
Niveau supérieur |

|
|
2e niveau |

|
|
3e niveau |

|
Formatage de texte en ligne
Format de texte |
Syntaxe Markdown |
Exemple |
|---|---|---|
Italique |

|
|
Gras |

|
|
Lien |

|
Listes
Type de liste |
Syntaxe Markdown |
Exemple |
|---|---|---|
Liste triée |

|
|
Liste non triée |

|
Formatage de code
Langage |
Syntaxe Markdown |
Exemple |
|---|---|---|
Python |
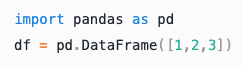
|
|
SQL |

|
Images intégrées
Type de fichier |
Syntaxe Markdown |
Exemple |
|---|---|---|
Image |

|
Pour voir un notebook qui illustre ces exemples Markdown, consulter la section Cellules Markdown du notebook de récits de données visuelles.
Compréhension des es sorties de cellules¶
Lorsque vous exécutez une cellule Python, le notebook affiche les types de sortie suivants de la cellule sont affichés dans les résultats :
Tous les résultats écrits sur la console, tels que les journaux, les erreurs, les avertissements et la sortie des instructions print().
Les DataFrames sont automatiquement imprimés à l’aide de l”écran de table interactif de Streamlit,
st.dataframe().Les types d’affichage DataFrame pris en charge sont le DataFrame Pandas, les DataFrames Snowpark et les tables Snowpark.
Pour Snowpark, les DataFrames imprimés sont évalués avec empressement sans qu’il soit nécessaire d’exécuter la commande
.show(). Si vous préférez ne pas évaluer le DataFrame immédiatement, par exemple lorsque vous exécutez le notebook en mode non interactif, Snowflake vous recommande de supprimer les instructions d’impression de DataFrame afin d’accélérer l’environnement d’exécution global de votre code Snowpark.
Les visualisations sont présentées sous forme de sorties. Pour en savoir plus sur la visualisation de vos données, voir Visualiser des données dans les Snowflake Notebooks.
En outre, vous pouvez accéder aux résultats de votre requête SQL en Python et vice versa. Voir Cellules et variables de référence dans les Snowflake Notebooks.
Limites de sortie des cellules¶
Seules 10 000 lignes ou 8 MB de sortie DataFrame sont affichés comme résultats de cellules, la valeur la plus faible étant retenue. Cependant, l’intégralité du DataFrame est toujours disponible dans la session du notebook. Par exemple, même si l’ensemble du DataFrame n’est pas rendu, vous pouvez toujours effectuer des tâches de transformation des données.
Pour chaque cellule, seule une sortie de 20 MB est autorisée. Si la taille de la sortie de la cellule dépasse 20 MB, la sortie sera abandonnée. Envisagez de diviser le contenu en plusieurs cellules si cela se produit.
Cellules et variables de référence dans les Snowflake Notebooks¶
Vous pouvez référencer les résultats de la cellule précédente dans une cellule de notebook. Par exemple, pour référencer le résultat d’une cellule SQL ou la valeur d’une variable Python, voir les tableaux suivants :
Note
Le nom de la cellule de la référence est sensible à la casse et doit correspondre exactement au nom de la cellule référencée.
Référencement de la sortie SQL dans les cellules Python :
Type de cellule de référence |
Type de cellule actuel |
Syntaxe de référence |
Exemple |
|---|---|---|---|
SQL |
Python |
|
Convertissez une table de résultats SQL en DataFrame Snowpark. Si vous avez ce qui suit dans une cellule SQL appelée Vous pouvez faire référence à la cellule pour accéder au résultat SQL : Convertissez le résultat en DataFrame Pandas : |
Référence aux variables dans le code SQL :
Important
Dans le code SQL, vous ne pouvez référencer que des variables Python de type string. Vous ne pouvez pas référence de DataFrame Snowpark, de DataFrame Pandas ni d’autre format DataFrame natif Python.
Type de cellule de référence |
Type de cellule actuel |
Syntaxe de référence |
Exemple |
|---|---|---|---|
SQL |
SQL |
|
Par exemple, dans une cellule SQL nommée |
Python |
SQL |
|
Par exemple, dans une cellule Python nommée Utiliser une variable Python comme valeur Vous pouvez faire référence à la valeur de la variable Utiliser une variable Python comme identificateur Si la variable Python représente un identificateur SQL tel qu’un nom de colonne ou de table : Si la variable Python représente un identificateur SQL, tel qu’un nom de colonne ou de table ( Veillez à faire la différence entre les variables utilisées comme valeurs (avec des guillemets) et comme identificateurs (sans guillemets). Remarque : Le référencement de DataFrames Python n’est pas pris en charge. |
Considérations relatives à l’utilisation de notebooks¶
Les notebooks fonctionnent en utilisant les droits de l’appelant. Pour d’autres considérations, voir Modifier le contexte de la session pour un notebook.
Vous pouvez importer des bibliothèques Python pour les utiliser dans un notebook. Pour plus de détails, voir Importer des paquets Python pour les utiliser dans les notebooks.
Lorsque vous faites référence à des objets dans les cellules SQL, vous devez utiliser des noms d’objets entièrement qualifiés, sauf si vous faites référence à des noms d’objets dans une base de données ou un schéma spécifique. Voir Modifier le contexte de la session pour un notebook.
Les brouillons de notebooks sont enregistrés toutes les trois secondes.
Vous pouvez utiliser l”intégration Git pour maintenir les versions des notebooks.
Vous pouvez configurer un paramètre de délai d’expiration pour arrêter automatiquement la session du notebook une fois le paramètre atteint. Pour plus d’informations, voir Temps d’inactivité et reconnexion.
Les résultats de la cellule du notebook ne sont visibles que par l’utilisateur qui a exécuté le notebook et sont mis en cache au fil des sessions. La réouverture d’un notebook affiche les résultats de la dernière fois que l’utilisateur a exécuté le notebook à l’aide de l”Snowsight.
BEGIN … END (Exécution de scripts Snowflake) n’est pas pris en charge dans les cellules SQL. Au lieu de cela, utilisez la méthode Session.sql().collect() dans une cellule Python pour exécuter le bloc de script. Chaînez l’appel à
sqlavec un appel àcollectpour exécuter immédiatement la requête SQL.Le code suivant exécute un bloc Exécution de scripts Snowflake à l’aide de la méthode
session.sql().collect():