Query directory tables¶
Cette rubrique explique comment interroger une table de répertoire pour récupérer une liste de tous les fichiers d’une zone de préparation avec des métadonnées, telles que l’URL de fichier Snowflake, pour chaque fichier.
Syntaxe pour interroger une table de répertoire :
Où :
stage_nameNom d’une zone de préparation qui a une table de répertoire activée.
Pour plus d’informations sur SELECT en tant qu’instruction, et sur les autres clauses de cette instruction, voir Syntaxe de requête dans la référence de commande SQL Snowflake.
Sortie¶
La sortie d’une requête de table de répertoire peut inclure les colonnes suivantes :
Colonne
Type de données
Description
RELATIVE_PATH
TEXT
Chemin vers les fichiers auxquels accéder en utilisant l’URL de fichier.
SIZE
NUMBER
Taille du fichier (en octets).
LAST_MODIFIED
TIMESTAMP_TZ
Horodatage de la dernière mise à jour du fichier dans la zone de préparation.
MD5
HEX
MD5 somme de contrôle pour le fichier.
ETAG
HEX
ETag en-tête pour le fichier.
FILE_URL
TEXT
URL du fichier hébergé par Snowflake vers le fichier.
L’URL de fichier a le format suivant :
Où :
account_identifierNom d’hôte du compte Snowflake pour votre zone de préparation. Le nom d’hôte commence par un localisateur de compte (fourni par Snowflake) et se termine par le domaine Snowflake (
snowflakecomputing.com) :
account_locator.snowflakecomputing.comPour plus de détails, voir Identificateurs de compte.
Note
Pour les comptes Business Critical , un segment
privatelinkest ajouté à l’URL juste avantsnowflakecomputing.com(privatelink.snowflakecomputing.com), même si la connectivité privée au service Snowflake n’est pas activée pour votre compte.db_nameNom de la base de données qui contient la zone de préparation où se trouvent vos fichiers.
schema_nameNom du schéma qui contient la zone de préparation où se trouvent vos fichiers.
stage_nameNom de la zone de préparation où se trouvent vos fichiers.
relative_pathChemin vers les fichiers auxquels accéder en utilisant l’URL de fichier.
Notes sur l’utilisation¶
Si les fichiers téléchargés à partir d’une zone de préparation interne sont corrompus, vérifiez avec le créateur de zone de préparation que
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE')est défini pour la zone de préparation.
Exemples¶
L’exemple récupère toutes les colonnes de métadonnées dans une table de répertoire pour une zone de préparation nommée mystage :
Cet exemple récupère les valeurs de colonne FILE_URL d’une table de répertoire pour les fichiers d’une taille supérieure à 100 Ko :
Cet exemple récupère les valeurs de colonne FILE_URL d’une table de répertoire pour les fichiers de valeurs séparées par des virgules :
Create a view for unstructured data using a directory table¶
Vous pouvez joindre une table de répertoire à d’autres tables Snowflake pour produire une vue de données non structurées qui combine des URLs de fichiers avec des métadonnées sur les fichiers.
Le diagramme suivant illustre comment utiliser une zone de préparation avec une table de répertoire activée avec une table de données distincte pour créer une vue complète des fichiers non structurés sur une zone de préparation.
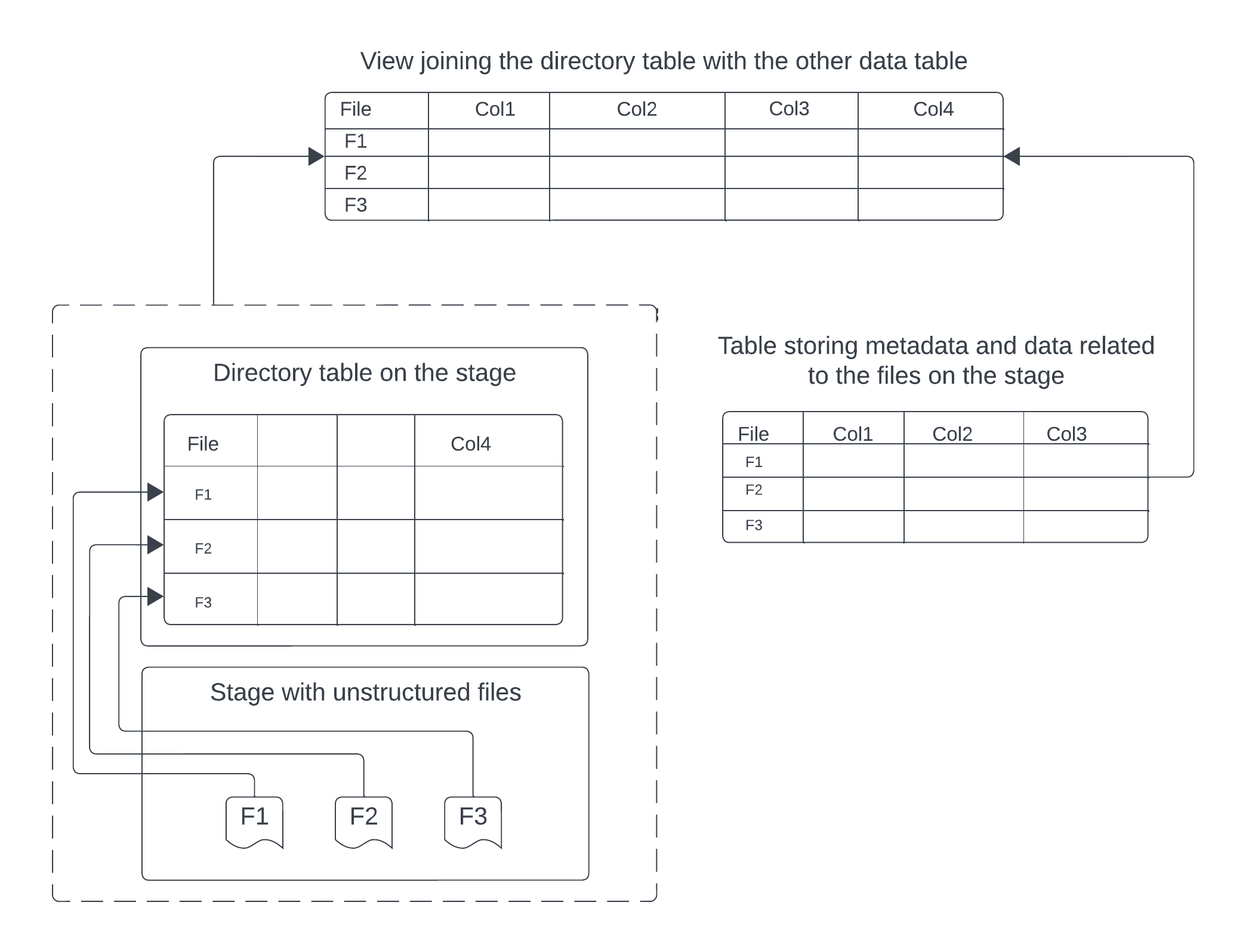
Example: Create a view of PDF files and their data
L’exemple suivant crée une vue appelée reports_information en joignant une table de répertoire sur une zone de préparation nommée my_pdf_stage avec une table nommée report_metadata à l’aide de la clé file_url. La zone de préparation contient des rapports en PDF, tandis que la table report_metadata contient des informations structurées sur chaque rapport en PDF, tels que author et publish_date. La vue résultante fournit un moyen d’obtenir des informations sur les PDFs non structurés et leurs métadonnées structurées associées.