Build a data processing pipeline using a directory table¶
Créez un pipeline de traitement des données en combinant une table de répertoire, qui suit et stocke les métadonnées de niveau fichier sur une zone de préparation, avec d’autres objets Snowflake tels que les flux et les tâches.
Un flux enregistre les modifications apportées en langage de manipulation des données (DML) à une table de répertoire, une table, une table externe ou les tables sous-jacentes d’une vue. Une tâche exécute une action unique, qui peut être une commande SQL ou une fonction définie par l’utilisateur (UDF). Vous pouvez planifier l’exécution d’une tâche à intervalles réguliers ou l’exécuter à la demande.
Exemple : Création d’un pipeline simple pour traiter des PDFs¶
Cet exemple crée un pipeline de traitement de données simple qui effectue les opérations suivantes :
Détecte les fichiers PDF ajoutés à une zone de préparation.
Récupère des données à partir des fichiers.
Insère les données dans une table Snowflake.
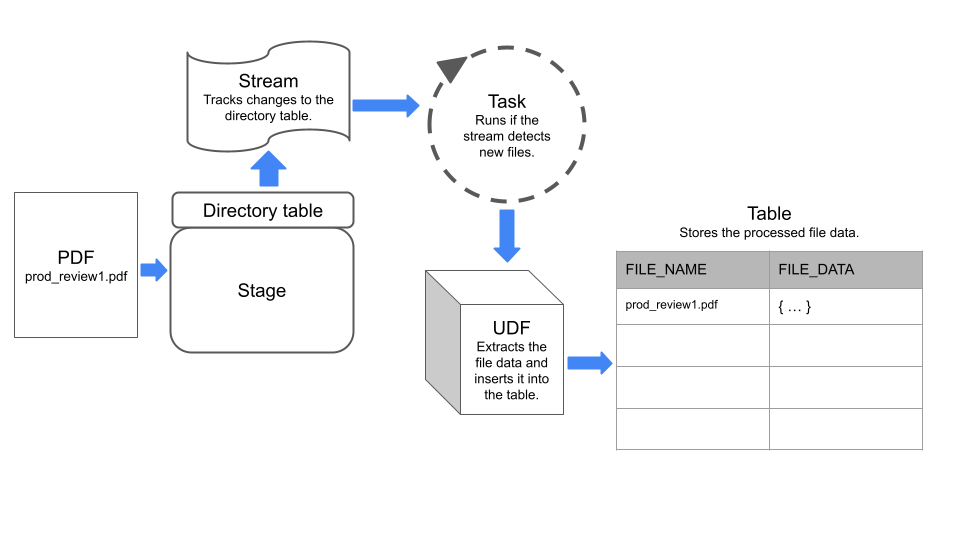
Le pipeline utilise un flux pour détecter les modifications apportées à une table de répertoire sur la zone de préparation, et une tâche qui exécute un site UDF pour extraire les données des fichiers.
Le diagramme suivant résume le fonctionnement de l’exemple de pipeline :
Étape 1 : Création d’une zone de préparation avec une table de répertoire activée¶
Étape 2 : Création d’un flux sur la table du répertoire¶
Créez un flux sur la table de répertoire en spécifiant la zone de préparation à laquelle appartient la table de répertoire. Le flux suivra les modifications apportées à la table de répertoire. À l’étape 5 de cet exemple, nous utilisons ce flux pour construire une tâche.
CREATESTREAMmy_pdf_streamONSTAGEmy_pdf_stage;
Étape 3 : Création d’une fonction définie par l’utilisateur pour analyser des PDFs¶
Créez un site UDF qui extrait les données des fichiers PDF. La tâche que vous créerez dans une étape ultérieure appellera cette adresse UDF pour traiter les fichiers nouvellement ajoutés sur la zone de préparation.
L’instruction suivante crée une UDF Python nommée PDF_PARSE qui traite les fichiers PDF contenant des données sur les produits. L’UDF extrait les données des champs de forme à l’aide de la bibliothèque PyPDF2. Elle renvoie un dictionnaire contenant les noms et les valeurs du formulaire sous forme de paires clé-valeur.
Étape 4 : Création d’une table pour stocker le contenu du fichier¶
Créez ensuite une table dans laquelle chaque ligne stocke des informations sur un fichier sur la zone de préparation dans des colonnes nommées file_name et file_data. La tâche que vous créerez dans une étape ultérieure chargera les données dans cette table.
Créez une tâche planifiée qui vérifie le flux pour les nouveaux fichiers sur la zone de préparation et insère les données du fichier dans la table prod_reviews.
L’instruction suivante crée une tâche planifiée en utilisant le flux créé précédemment. La tâche utilise la fonction SYSTEM$STREAM_HAS_DATA pour vérifier si le flux contient des enregistrements de capture de données modifiées (CDC).
CREATEORREPLACETASKload_new_file_dataWAREHOUSE='MY_WAREHOUSE'SCHEDULE='1 minute'COMMENT='Process new files on the stage and insert their data into the prod_reviews table.'WHENSYSTEM$STREAM_HAS_DATA('my_pdf_stream')ASINSERTINTOprod_reviews(SELECTrelative_pathasfile_name,PDF_PARSE(build_scoped_file_url('@my_pdf_stage',relative_path))asfile_dataFROMmy_pdf_streamWHEREMETADATA$ACTION='INSERT');
Étape 6 : Exécution de la tâche pour tester le pipeline¶
Pour vérifier que le pipeline fonctionne, vous pouvez ajouter des fichiers à la zone de préparation, exécuter manuellement la tâche, puis interroger la table product_reviews.
Commencez par ajouter quelques fichiers PDF à la zone de préparation my_pdf_stage, puis actualisez la zone de préparation.
Vous pouvez interroger le flux pour vérifier qu’il a enregistré les deux fichiers PDF que nous avons ajoutés à la zone de préparation.
SELECT*FROMmy_pdf_stream;
Maintenant, exécutez la tâche pour traiter les fichiers PDF et mettre à jour la table product_reviews.
EXECUTE TASKload_new_file_data;+----------------------------------------------------------+| status ||----------------------------------------------------------|| Task LOAD_NEW_FILE_DATA is scheduled to run immediately. |+----------------------------------------------------------+1Row(s)produced.TimeElapsed: 0.178s
Interrogez la table product_reviews pour voir que la tâche a ajouté une ligne pour chaque fichier PDF.
Enfin, vous pouvez créer une vue qui analyse les objets de la colonne FILE_DATA dans des colonnes distinctes. Vous pouvez ensuite interroger la vue pour analyser et travailler avec le contenu du fichier.
CREATEORREPLACEVIEWprod_review_info_vASWITHfile_dataAS(SELECTfile_name,parse_json(file_data)ASfile_dataFROMprod_reviews)SELECTfile_name,file_data:FirstName::varcharASfirst_name,file_data:LastName::varcharASlast_name,file_data:"Middle Name"::varcharASmiddle_name,file_data:Product::varcharASproduct,file_data:"Purchase Date"::dateASpurchase_date,file_data:Recommend::varcharASrecommended,build_scoped_file_url(@my_pdf_stage,file_name)ASscoped_review_urlFROMfile_data;SELECT*FROMprod_review_info_v;+------------------+------------+-----------+-------------+----------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| FILE_NAME | FIRST_NAME | LAST_NAME | MIDDLE_NAME | PRODUCT | PURCHASE_DATE | RECOMMENDED | SCOPED_REVIEW_URL ||------------------+------------+-----------+-------------+----------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|| prod_review1.pdf | John | Johnson | Michael | Tennis Shoes | 2022-03-15 | Yes | https://mydeployment.us-west-2.aws.privatelink.snowflakecomputing.com/api/files/01aefcdc-0000-6f92-0000-012900fdc73e/1275606224902/RZ4s%2bJLa6iHmLouHA79b94tg%2f3SDA%2bOQX01pAYo%2bl6gAxiLK8FGB%2bv8L2QSB51tWP%2fBemAbpFd%2btKfEgKibhCXN2QdMCNraOcC1uLdR7XV40JRIrB4gDYkpHxx3HpCSlKkqXeuBll%2fyZW9Dc6ZEtwF19GbnEBR9FwiUgyqWjqSf4KTmgWKv5gFCpxwqsQgofJs%2fqINOy%2bOaRPa%2b65gcnPpY2Dc1tGkJGC%2fT110Iw30cKuMGZ2HU%3d || prod_review2.pdf | Emily | Smith | Ann | Red Skateboard | 2023-01-10 | MayBe | https://mydeployment.us-west-2.aws.privatelink.snowflakecomputing.com/api/files/01aefcdc-0000-6f92-0000-012900fdc73e/1275606224902/g3glgIbGik3VOmgcnltZxVNQed8%2fSBehlXbgdZBZqS1iAEsFPd8pkUNB1DSQEHoHfHcWLsaLblAdSpPIZm7wDwaHGvbeRbLit6nvE%2be2LHOsPR1UEJrNn83o%2fZyq4kVCIgKeSfMeGH2Gmrvi82JW%2fDOyZJITgCEZzpvWGC9Rmnr1A8vux47uZj9MYjdiN2Hho3uL9ExeFVo8FUtR%2fHkdCJKIzCRidD5oP55m9p2ml2yHOkDJW50%3d |+------------------+------------+-----------+-------------+----------------+---------------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+