Query directory tables¶
Este tópico aborda como consultar uma tabela de diretório para recuperar uma lista de todos os arquivos em um estágio com metadados, como o URL de arquivo Snowflake, para cada arquivo.
Sintaxe para consultar uma tabela de diretório:
Onde:
stage_nameNome de um estágio que tem uma tabela de diretório ativada.
Para obter mais informações sobre SELECT como uma instrução e as outras cláusulas dentro da instrução, consulte Sintaxe de consulta na Referência de comandos SQL Snowflake.
Saída¶
A saída de uma consulta de tabela de diretório pode incluir as seguintes colunas:
Coluna
Tipo de dados
Descrição
RELATIVE_PATH
TEXT
Caminho para os arquivos a serem acessados usando o URL do arquivo.
SIZE
NUMBER
Tamanho do arquivo (em bytes).
LAST_MODIFIED
TIMESTAMP_TZ
Carimbo de data/hora em que o arquivo foi atualizado pela última vez no estágio.
MD5
HEX
Soma de verificação MD5 para o arquivo.
ETAG
HEX
Cabeçalho ETag para o arquivo.
FILE_URL
TEXT
URL do arquivo Snowflake para o arquivo.
O URL do arquivo tem o seguinte formato:
Onde:
account_identifierNome do host da conta Snowflake para seu estágio. O nome do host começa com um localizador de conta (fornecido pelo Snowflake) e termina com o domínio Snowflake (
snowflakecomputing.com):
account_locator.snowflakecomputing.comPara obter mais detalhes, consulte Identificadores de conta.
Nota
Para contas Business Critical, um segmento
privatelinké anexado ao URL logo antes desnowflakecomputing.com(privatelink.snowflakecomputing.com), mesmo se a conectividade privada ao serviço Snowflake são estiver habilitado para sua conta.db_nameNome do banco de dados que contém o estágio em que seus arquivos estão localizados.
schema_nameNome do esquema que contém o estágio em que seus arquivos estão localizados.
stage_nameNome do estágio em que seus arquivos estão localizados.
relative_pathCaminho para os arquivos a serem acessados usando o URL do arquivo.
Notas de uso¶
Se os arquivos baixados de um estágio interno estiverem corrompidos, verifique com o criador do estágio se
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE')está definido para o estágio.
Exemplos¶
Este exemplo recupera todas as colunas de metadados em uma tabela de diretório para um estágio chamado mystage:
Este exemplo recupera os valores da coluna FILE_URL de uma tabela de diretório para arquivos com tamanho superior a 100 K bytes:
Este exemplo recupera os valores da coluna FILE_URL de uma tabela de diretório para arquivos de valores separados por vírgula:
Create a view for unstructured data using a directory table¶
Você pode unir uma tabela de diretório a outras tabelas Snowflake para produzir uma exibição de dados não estruturados que combine os URLs de arquivo com metadados sobre os arquivos.
O diagrama a seguir ilustra como é possível usar um estágio com uma tabela de diretório ativada juntamente com uma tabela de dados separada para criar uma exibição abrangente para arquivos não estruturados em um estágio.
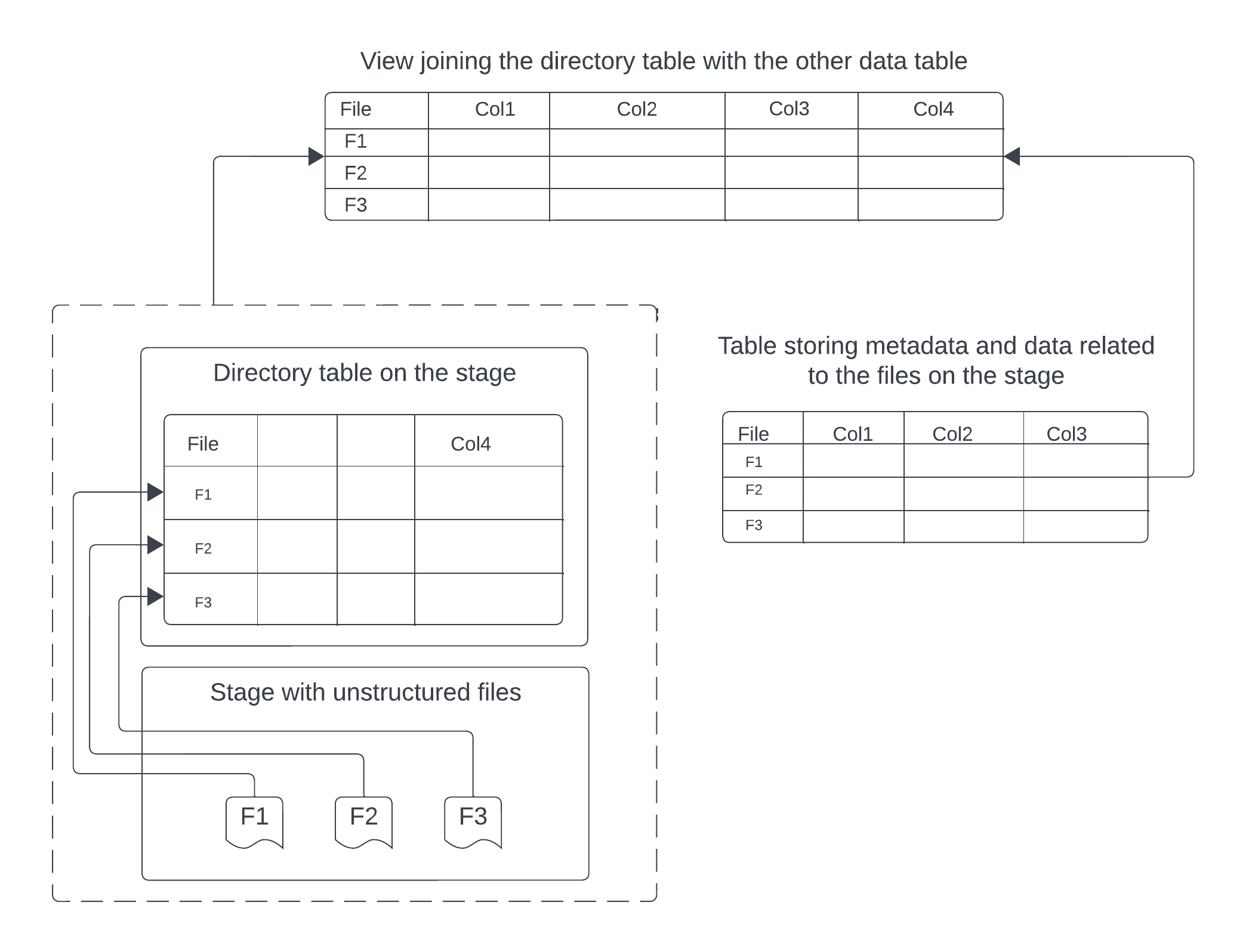
Example: Create a view of PDF files and their data
O exemplo a seguir cria uma exibição chamada reports_information unindo uma tabela de diretório em um estágio chamado my_pdf_stage com uma tabela chamada report_metadata usando a chave file_url. O estágio contém relatórios de PDF, enquanto a tabela report_metadata contém informações estruturadas sobre cada relatório de PDF, como author e publish_date. A exibição resultante fornece uma maneira de obter informações sobre PDFs não estruturado e seus metadados estruturados relacionados.