Snowpipe automatisé pour Google Cloud Storage¶
Ce sujet fournit des instructions pour déclencher automatiquement des chargements de données Snowpipe depuis des zones de préparation externes sur Google Cloud Storage à l’aide des messages Google Cloud Pub/Sub pour les événements Google Cloud Storage (GCS).
Notez que seuls les événements OBJECT_FINALIZE déclenchent Snowpipe pour charger des fichiers. Snowflake recommande de n’envoyer que des événements pris en charge par Snowpipe afin de réduire les coûts, le bruit des événements et la latence.
Prise en charge de la plateforme Cloud¶
Le déclenchement de chargements de données Snowpipe automatisés à l’aide de messages d’événements GCS Pub/Sub est pris en charge par les comptes Snowflake hébergés sur toutes les plates-formes Cloud prises en charge.
Configuration de l’accès sécurisé au stockage Cloud¶
Note
Si vous avez déjà configuré un accès sécurisé au compartiment GCS qui stocke vos fichiers de données, vous pouvez ignorer cette section.
Cette section décrit comment configurer un objet d’intégration de stockage Snowflake pour déléguer la responsabilité de l’authentification pour le stockage dans le Cloud à une entité Gestion des identités et des accès Snowflake (IAM).
Cette section explique comment utiliser les intégrations de stockage pour permettre à Snowflake de lire des données et de les écrire dans un compartiment de Google Cloud Storage référencé dans une zone de préparation externe (c’est-à-dire stockage Cloud). Les intégrations sont des objets Snowflake de première classe nommés, qui évitent de transmettre des identifiants de connexion explicites de fournisseur de Cloud, telles que des clés secrètes ou des jetons d’accès. Les objets d’intégration, quant à eux, font référence à un compte de service de stockage Cloud. Un administrateur de votre organisation accorde des autorisations au compte de service dans le compte Cloud Storage.
Les administrateurs peuvent également limiter les utilisateurs à un ensemble spécifique de compartiments Cloud Storage (et de chemins d’accès facultatifs) auxquels accèdent des zones de préparation externes utilisant l’intégration.
Note
Pour suivre les instructions de cette section, vous devez avoir accès à votre projet Cloud Storage en tant qu’éditeur de projet. Si vous n’êtes pas un éditeur de projet, demandez à votre administrateur Cloud Storage d’effectuer ces tâches.
Confirmez que Snowflake prend en charge la région Google Cloud Storage dans laquelle votre stockage est hébergé. Pour plus d’informations, voir Régions Cloud prises en charge.
Le diagramme suivant illustre le flux d’intégration d’une zone de préparation Cloud Storage :
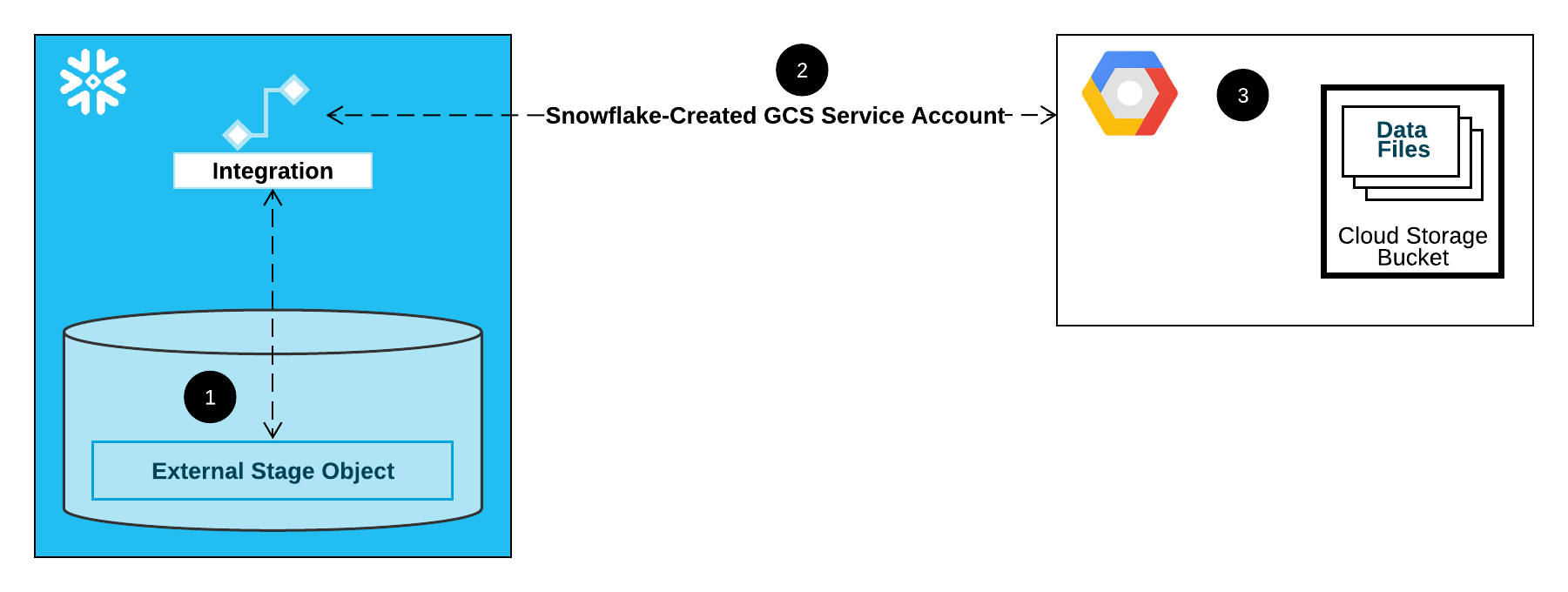
Une zone de préparation externe (c’est-à-dire le stockage Cloud) fait référence à un objet d’intégration de stockage dans sa définition.
Snowflake associe automatiquement l’intégration de stockage à un compte de service Cloud Storage créé pour votre compte. Snowflake crée un seul compte de service référencé par toutes les intégrations de stockage GCS de votre compte Snowflake.
Un éditeur de projet pour votre projet Cloud Storage accorde des autorisations au compte de service pour accéder au compartiment référencé dans la définition de la zone de stockage. Notez que de nombreux objets de zone de stockage externes peuvent référencer différents compartiments et chemins et utiliser la même intégration pour l’authentification.
Lorsqu’un utilisateur charge ou décharge des données depuis ou vers une zone de préparation, Snowflake vérifie les autorisations accordées au compte de service sur le compartiment avant d’autoriser ou de refuser l’accès.
Dans cette section :
Étape 1 : Création d’une intégration de stockage Cloud dans Snowflake¶
Créez une intégration à l’aide de la commande CREATE STORAGE INTEGRATION. Une intégration est un objet Snowflake qui délègue la responsabilité de l’authentification pour un stockage externe dans le Cloud à une entité générée par Snowflake (c’est-à-dire un compte de service de stockage Cloud). Pour accéder aux compartiments Cloud Storage, Snowflake crée un compte de service auquel des autorisations peuvent être accordées pour accéder aux compartiments dans lesquels vos fichiers de données sont stockés.
Une seule intégration de stockage peut prendre en charge plusieurs zones de préparation externe (c’est-à-dire GCS). L’URL dans la définition de zone de préparation doit correspondre aux compartiments GCS (et aux chemins facultatifs) spécifiés pour le paramètre STORAGE_ALLOWED_LOCATIONS.
Note
Seuls les administrateurs de compte (utilisateurs dotés du rôle ACCOUNTADMIN) ou un rôle disposant du privilège global CREATE INTEGRATION peuvent exécuter cette commande SQL.
Où :
integration_nameest le nom de la nouvelle intégration.bucketest le nom d’un compartiment de stockage Cloud qui stocke vos fichiers de données (c’est-à-diremybucket). Les paramètres STORAGE_ALLOWED_LOCATIONS requis et STORAGE_BLOCKED_LOCATIONS facultatif limitent ou bloquent l’accès à ces compartiments, respectivement, lors de la création ou de la modification de zones de préparation faisant référence à cette intégration.pathest un chemin facultatif qui peut être utilisé pour fournir un contrôle granulaire sur les objets du compartiment.
L’exemple suivant crée une intégration qui limite explicitement les zones de préparation externes utilisant l’intégration pour faire référence à l’un des deux compartiments et des chemins. Dans une étape ultérieure, nous allons créer une zone de préparation externe qui fait référence à l’un de ces compartiments et chemins.
Les zones de préparation externes supplémentaires qui utilisent également cette intégration peuvent faire référence aux compartiments et aux chemins autorisés :
Étape 2 : Récupérer le compte de service Cloud Storage de votre compte Snowflake¶
Exécutez la commande DESCRIBE INTEGRATION pour extraire l’ID du compte de service Cloud Storage créé automatiquement pour votre compte Snowflake :
Où :
integration_nameest le nom de l’intégration que vous avez créée dans l’Étape 1 : Création d’une intégration de stockage Cloud dans Snowflake (dans ce sujet).
Par exemple :
La propriété STORAGE_GCP_SERVICE_ACCOUNT dans la sortie indique le compte du service de stockage Cloud créé pour votre compte Snowflake (c’est-à-dire service-account-id@project1-123456.iam.gserviceaccount.com). Nous fournissons un seul compte de service Cloud Storage pour l’ensemble de votre compte Snowflake. Toutes les intégrations Cloud Storage utilisent ce compte de service.
Étape 3 : Accorder au compte de service des autorisations lui permettant d’accéder à des objets du compartiment¶
Les instructions pas à pas suivantes décrivent comment configurer les autorisations d’accès IAM à Snowflake dans votre Google Cloud console afin que vous puissiez utiliser un compartiment de stockage Cloud pour charger et décharger des données :
Create a custom IAM role¶
Créez un rôle personnalisé disposant des autorisations requises pour accéder au compartiment et obtenir des objets.
Connectez-vous à Google Cloud console en tant qu’éditeur de projet.
Dans le tableau de bord d’accueil, sélectionnez IAM & Admin » Roles.
Sélectionnez Create Role.
Saisissez un Title et un Description facultatif pour le rôle personnalisé.
Sélectionnez Add Permissions.
Filtrez la liste des autorisations et ajoutez les éléments suivants dans la liste :
Action(s)
Autorisations requises
Chargement des données uniquement
storage.buckets.getstorage.objects.getstorage.objects.list
Chargement de données avec option de purge, exécution de la commande REMOVE sur la zone de préparation
storage.buckets.getstorage.objects.deletestorage.objects.getstorage.objects.list
Chargement et déchargement des données
storage.buckets.get(pour le calcul des coûts de transfert des données)storage.objects.createstorage.objects.deletestorage.objects.getstorage.objects.list
Déchargement des données uniquement
storage.buckets.getstorage.objects.createstorage.objects.deletestorage.objects.list
Utiliser COPY FILES pour copier des fichiers dans une zone de préparation externe
Vous devez disposer des autorisations supplémentaires suivantes :
storage.multipartUploads.abortstorage.multipartUploads.createstorage.multipartUploads.liststorage.multipartUploads.listParts
Sélectionnez Add.
Sélectionnez Create.
Assign the custom role to the Cloud Storage Service Account¶
Connectez-vous à Google Cloud console en tant qu’éditeur de projet.
Dans le tableau de bord d’accueil, sélectionnez Cloud Storage » Buckets.
Filtrez la liste des compartiments et sélectionnez le compartiment que vous avez spécifié lors de la création de votre intégration de stockage.
Sélectionnez Permissions » View by principals, puis sélectionnez Grant access.
Sous Add principals, collez le nom du compte de service que vous avez récupéré à partir de la sortie de commande DESC STORAGE INTEGRATION.
Sous Assign roles, sélectionnez le rôle personnalisé IAM que vous avez créé précédemment, puis Save.
Important
Si votre organisation Google Cloud a été créée le 3 mai 2024 ou après cette date, Google Cloud applique une contrainte de restriction de domaine dans les politiques d’organisation du projet. La contrainte par défaut répertorie votre domaine comme seule valeur autorisée.
Pour permettre au compte de service Snowflake d’accéder à votre stockage, vous devez mettre à jour la restriction du domaine.
Grant the Cloud Storage service account permissions on the Cloud Key Management Service cryptographic keys¶
Note
Cette étape n’est requise que si votre compartiment GCS est chiffré à l’aide d’une clé stockée dans Google Cloud Key Management Service (Cloud KMS).
Connectez-vous à Google Cloud console en tant qu’éditeur de projet.
Depuis le tableau de bord d’accueil, recherchez et sélectionnez Security » Key Management.
Sélectionnez le porte-clés affecté à votre compartiment GCS.
Cliquez sur SHOW INFO PANEL dans le coin supérieur droit. Le panneau d’information du porte-clés s’affiche.
Cliquez sur le bouton ADD PRINCIPAL.
Dans le champ New principals, recherchez le nom du compte de service à partir de la DESCRIBEINTEGRATION sortie dans Étape 2 : Récupération du compte de service de stokage Cloud pour votre compte Snowflake (dans ce sujet).
Dans la liste déroulante Select a role, sélectionnez le rôle
Cloud KMS CrytoKey Encryptor/Decryptor.Cliquez sur le bouton Save. Le nom du compte de service est ajouté à la liste déroulante des rôles Cloud KMS CrytoKey Encryptor/Decryptor dans le panneau d’informations.
Note
Vous pouvez utiliser la fonction SYSTEM$VALIDATE_STORAGE_INTEGRATION pour valider la configuration de votre intégration de stockage.
Configuration de l’automatisation à l’aide de Pub/Sub GCS¶
Conditions préalables¶
Les instructions de cette rubrique supposent que les éléments suivants ont été créés et configurés :
- Compte GCP:
Sujet Pub/Sub qui reçoit des messages d’événement depuis le compartiment GCS. Pour plus d’informations, voir Création du sujet Pub/Sub (dans cette rubrique).
Abonnement qui reçoit les messages d’événement du sujet Pub/Sub. Pour plus d’informations, voir Création de l’abonnement Pub/Sub (dans cette rubrique).
Pour obtenir des instructions, voir Documentation Pub/Sub.
- Snowflake:
Table cible dans la base de données Snowflake où vous souhaitez charger les données.
Création du sujet Pub/Sub¶
Créez un sujet Pub/Sub à l’aide de Cloud Shell ou du SDK Cloud.
Exécutez la commande suivante pour créer le sujet et lui permettre d’écouter l’activité dans le compartiment GCS spécifié :
Où :
<sujet>est le nom du sujet.<nom-compartiment>est le nom de votre compartiment GCS.
Si le sujet existe déjà, la commande l’utilise ; sinon, la commande crée un nouveau sujet.
Pour plus d’informations, voir la page Utiliser les notifications Pub/Sub pour le stockage Cloud dans la documentation Pub/Sub.
Création de l’abonnement Pub/Sub¶
Créez un abonnement au sujet avec transmission de type pull Pub/Sub à l’aide de la console Cloud, de l’outil de ligne de commande gcloud ou de l’API Cloud Pub/Sub. Pour obtenir des instructions, voir Gérer les sujets et les abonnements dans la documentation Pub/Sub.
Note
Seuls les abonnements Pub/Sub qui utilisent la transmission de type pull par défaut sont pris en charge par Snowflake. La transmission de type push n’est pas prise en charge.
Récupération de l’ID d’abonnement Pub/Sub¶
L’ID d’abonnement au sujet Pub/Sub est utilisé dans ces instructions pour permettre à Snowflake d’accéder aux messages d’événement.
Connectez-vous à la console Google Cloud Platform en tant qu’éditeur de projet.
Dans le tableau de bord d’accueil, sélectionnez Big Data » Pub/Sub » Subscriptions.
Copiez l’ID dans la colonne Subscription ID pour l’abonnement au sujet.
Étape 1 : créer une intégration de notification dans Snowflake¶
Créez une intégration de notification à l’aide de la commande CREATE NOTIFICATION INTEGRATION.
L’intégration des notifications fait référence à votre abonnement Pub/Sub. Snowflake associe l’intégration de la notification à un compte de service GCS créé pour votre compte. Snowflake crée un seul compte de service référencé par toutes les notifications de stockage GCS de votre compte Snowflake.
Note
Seuls les administrateurs de compte (utilisateurs dotés du rôle ACCOUNTADMIN) ou un rôle disposant du privilège global CREATE INTEGRATION peuvent exécuter cette commande SQL.
Le compte de service GCS pour les intégrations de notification est différent du compte de service créé pour les intégrations de stockage.
Une seule intégration de notification prend en charge un seul abonnement Google Cloud Pub/Sub. Le référencement du même abonnement Pub/Sub dans plusieurs intégrations de notification peut entraîner la perte de données dans les tables cibles, car les notifications d’événements sont réparties entre les intégrations de notification. Par conséquent, la création de canal est bloquée si un canal fait référence au même abonnement Pub/Sub que celui d’un canal existant.
Où :
integration_nameest le nom de la nouvelle intégration.subscription_idest le nom de l’abonnement que vous avez enregistré dans Récupération de l’ID d’abonnement Pub/Sub.
Par exemple :
Étape 2 : Accorder un accès à Snowflake à l’abonnement Pub/Sub¶
Exécutez la commande DESCRIBE INTEGRATION pour récupérer l’ID de compte de service Snowflake :
Où :
integration_nameest le nom de l’intégration créée à l”étape 1 : Créer une intégration de notification dans Snowflake.
Par exemple :
Enregistrez le nom du compte de service dans la colonne GCP_PUBSUB_SERVICE_ACCOUNT, qui a le format suivant :
Connectez-vous à la console Google Cloud Platform en tant qu’éditeur de projet.
Dans le tableau de bord d’accueil, sélectionnez Big Data » Pub/Sub » Subscriptions.
Sélectionnez l’abonnement à configurer pour l’accès.
Cliquez sur SHOW INFO PANEL dans le coin supérieur droit. Le panneau d’information de l’abonnement s’affiche en coulissant.
Cliquez sur le bouton ADD PRINCIPAL.
Dans le champ New principals, recherchez le nom du compte de service que vous avez enregistré.
Dans la liste déroulante Select a role, sélectionnez Pub/Sub Subscriber.
Cliquez sur le bouton Save. Le nom du compte de service est ajouté à la liste déroulante des rôles Pub/Sub Subscriber dans le panneau d’informations.
Accédez à la page Dashboard de la console Cloud et sélectionnez votre projet dans la liste déroulante.
Cliquez sur le bouton ADD PEOPLE TO THIS PROJECT .
Ajoutez le nom du compte de service que vous avez enregistré.
Dans la liste déroulante Select a role, sélectionnez Monitoring Viewer.
Cliquez sur le bouton Save . Le nom du compte de service est ajouté au rôle Monitoring Viewer.
Étape 3 : Création d’une zone de préparation (si nécessaire)¶
Créez une zone de préparation externe qui fait référence à votre compartiment GCS à l’aide de la commande CREATE STAGE. Snowflake lit vos fichiers de données en zone de préparation dans les métadonnées de la table externe. Vous pouvez aussi utiliser une zone de préparation externe.
Note
Pour configurer un accès sécurisé à l’emplacement de stockage Cloud, voir Configuration de l’accès sécurisé au stockage Cloud (dans cette rubrique).
Pour faire référence à une intégration de stockage dans l’instruction CREATE STAGE, le rôle doit avoir le privilège USAGE sur l’objet d’intégration de stockage.
L’exemple suivant crée une zone de préparation nommée mystage dans le schéma actif de la session utilisateur. L’URL de stockage Cloud inclut le chemin files. La zone de préparation fait référence à une intégration de stockage nommée my_storage_int.
Étape 4 : Création d’un canal avec l’intégration automatique activée¶
Créez un canal à l’aide de la commande CREATE PIPE . Le canal définit l’instruction COPY INTO <table> utilisée par Snowpipe pour charger les données de la file d’attente d’acquisition dans la table cible.
Par exemple, créez un canal dans le schéma snowpipe_db.public qui charge les données des fichiers mis dans une zone de préparation externe (GCS) nommée mystage dans une table de destination nommée mytable :
Le paramètre INTEGRATION fait référence à my_notification_int l’intégration de notification créée à l” étape 1 : création d’une intégration Cloud Storage dans Snowflake. Le nom de l’intégration doit être fourni en majuscule.
Important
Vérifiez que la référence de l’emplacement de stockage dans l’instruction COPY INTO <table> ne chevauche pas la référence dans les canaux existants du compte. Sinon, plusieurs canaux pourraient charger le même ensemble de fichiers de données dans les tables cibles. Par exemple, cette situation peut se produire lorsque plusieurs définitions de canaux font référence au même emplacement de stockage avec différents niveaux de granularité, tels que <storage_location>/path1/ et <storage_location>/path1/path2/. Dans cet exemple, si les fichiers sont en zone de préparation dans <storage_locationstorage_location>/path1/path2/, les deux canaux chargeront une copie des fichiers.
Visualisez les instructions COPY INTO <table> dans les définitions de tous les canaux du compte en exécutant SHOW PIPES ou en interrogeant la vue PIPES dans Account Usage ou la vue PIPES dans Information Schema.
Snowpipe avec l’intégration automatique est maintenant configuré !
Lorsque de nouveaux fichiers de données sont ajoutés au compartiment GCS, le message d’événement indique à Snowpipe de les charger dans la table cible définie dans le canal.
Étape 5 : Chargement de fichiers historiques¶
Pour charger les retards de traitement des fichiers de données qui existaient dans la zone de préparation externe avant que les messages Pub/Sub aient été configurés, exécutez une instruction ALTER PIPE … REFRESH.
Étape 6 : Suppression de fichiers en zone de préparation¶
Supprimez les fichiers en zone de préparation après avoir chargé avec succès les données et lorsque vous n’avez plus besoin des fichiers. Pour obtenir des instructions, voir Suppression de fichiers en zone de préparation après le chargement des données par Snowpipe.
Sortie SYSTEM$PIPE_STATUS¶
La fonction SYSTEM$PIPE_STATUS récupère une représentation JSON du statut actuel d’un canal.
Pour les canaux avec AUTO_INGEST défini sur TRUE, la fonction renvoie un objet JSON contenant les paires nom/valeur suivantes (si applicable au statut actuel du canal) :
Pour la description des valeurs de sortie, consultez la rubrique de référence de la fonction SQL.