Analyse de documents avec AI_PARSE_DOCUMENT¶
AI_PARSE_DOCUMENT est une fonction Cortex AI qui extrait du texte, des données, des éléments de mise en page et des images à partir de documents. Elle peut être utilisée avec d’autres fonctions pour créer des pipelines de traitement de documents personnalisés pour de nombreux cas d’utilisation (voir Fonctions Cortex AI : Documents).
Pour plus d’informations avec des exemples sur l’utilisation de AI_PARSE_DOCUMENT pour extraire des images, voir Fonctions Cortex AI : Extraction d’images avec AI_PARSE_DOCUMENT.
La fonction extrait le texte et la mise en page à partir de documents stockés sur des zones de préparation internes ou externes et préserve l’ordre de lecture et les structures telles que les tables et les en-têtes. Voir Créer une zone de préparation pour des fichiers médias pour des informations sur la création d’une zone de préparation adaptée au stockage de documents.
AI_PARSE_DOCUMENT orchestre des modèles d’AI avancés pour la compréhension des documents et l’analyse de la mise en page, en traitant des documents complexes de plusieurs pages de manière très fidèle.
La fonction AI_PARSE_DOCUMENT propose deux modes de traitement des documents PDF :
le mode LAYOUT est le choix préféré dans la plupart des cas d’utilisation, en particulier pour les documents complexes. il est spécifiquement optimisé pour l’extraction de texte et d’éléments de mise en page tels que des tables, ce qui en fait la meilleure option pour créer des bases de connaissances, optimiser les systèmes de récupération et améliorer les applications basées sur l’AI.
le mode OCR est recommandé pour une extraction de texte rapide et de haute qualité à partir de documents tels que les manuels, les accords ou les contrats, les pages d’informations sur les produits, les polices d’assurance et les réclamations, et les documents SharePoint.
Pour les deux modes, utilisez l’option page_split pour diviser des documents de plusieurs pages en pages distinctes dans la réponse. Vous pouvez également utiliser l’option page_filter pour ne traiter que les pages spécifiées. Si utiliser page_filter, page_split est implicite, vous n’avez pas besoin de le définir explicitement.
AI_PARSE_DOCUMENT est évolutif horizontalement, ce qui permet un traitement efficace par lots de plusieurs documents simultanément. Les documents peuvent être traités directement à partir du stockage d’objets pour éviter les mouvements de données inutiles.
Note
AI_PARSE_DOCUMENT est actuellement incompatible avec les politiques de réseau personnalisées.
Exemples¶
Exemple de mise en page simple¶
This example uses AI_PARSE_DOCUMENT’s LAYOUT mode to process a two-column research paper. The page_split parameter
is set to TRUE in order to separate the document into pages in the response. AI_PARSE_DOCUMENT returns the content in Markdown
format. The following shows rendered Markdown for one of the processed pages (page index 4 in the JSON output) next to
the original page. The raw Markdown is shown in the JSON response following the images.
Page du document d’origine |
Markdown extrait rendu en tant que HTML |
|---|---|

|

|
Astuce
Pour voir l’une de ces images à une taille plus lisible, sélectionnez-la en cliquant dessus ou en la touchant.
Ce qui suit est la commande SQL pour traiter le document original :
La réponse de AI_PARSE_DOCUMENT est un objet JSON contenant des métadonnées et du texte des pages du document, comme les suivants. Certains objets de page ont été omis par souci de brièveté.
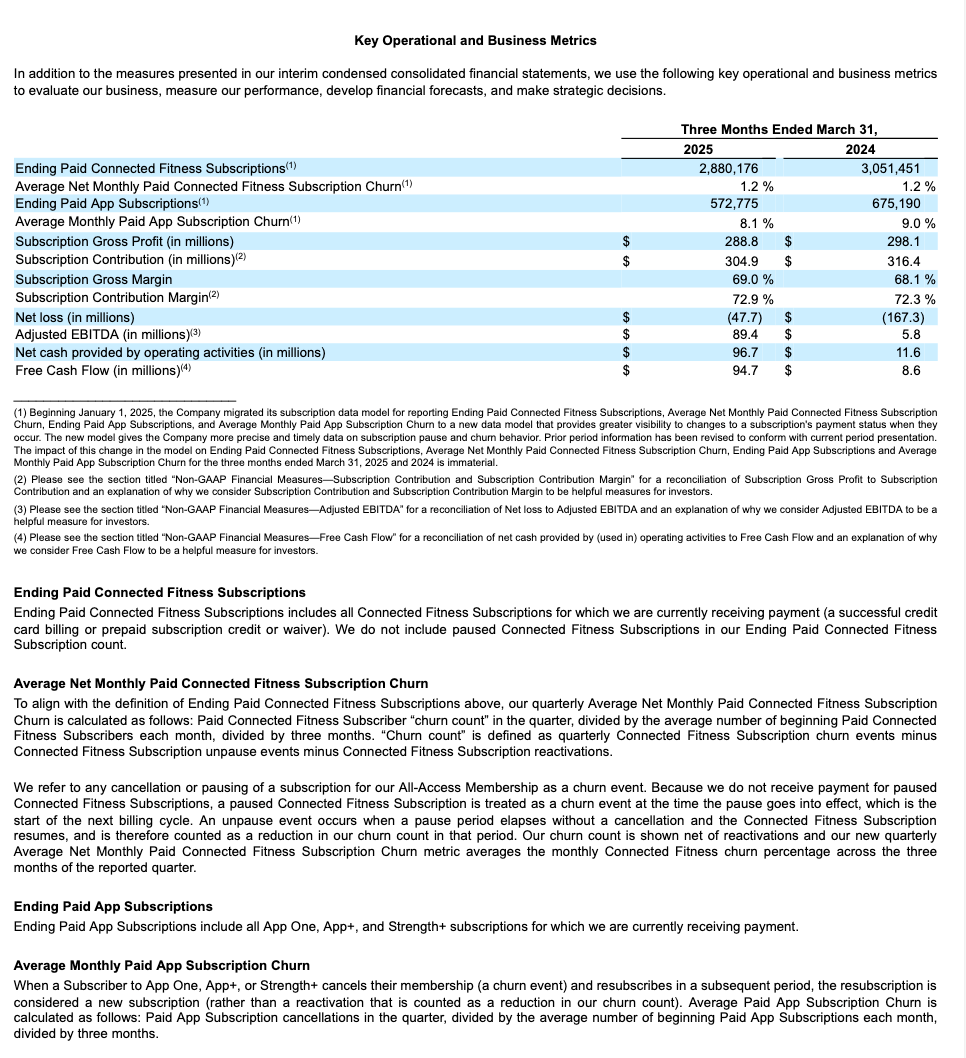
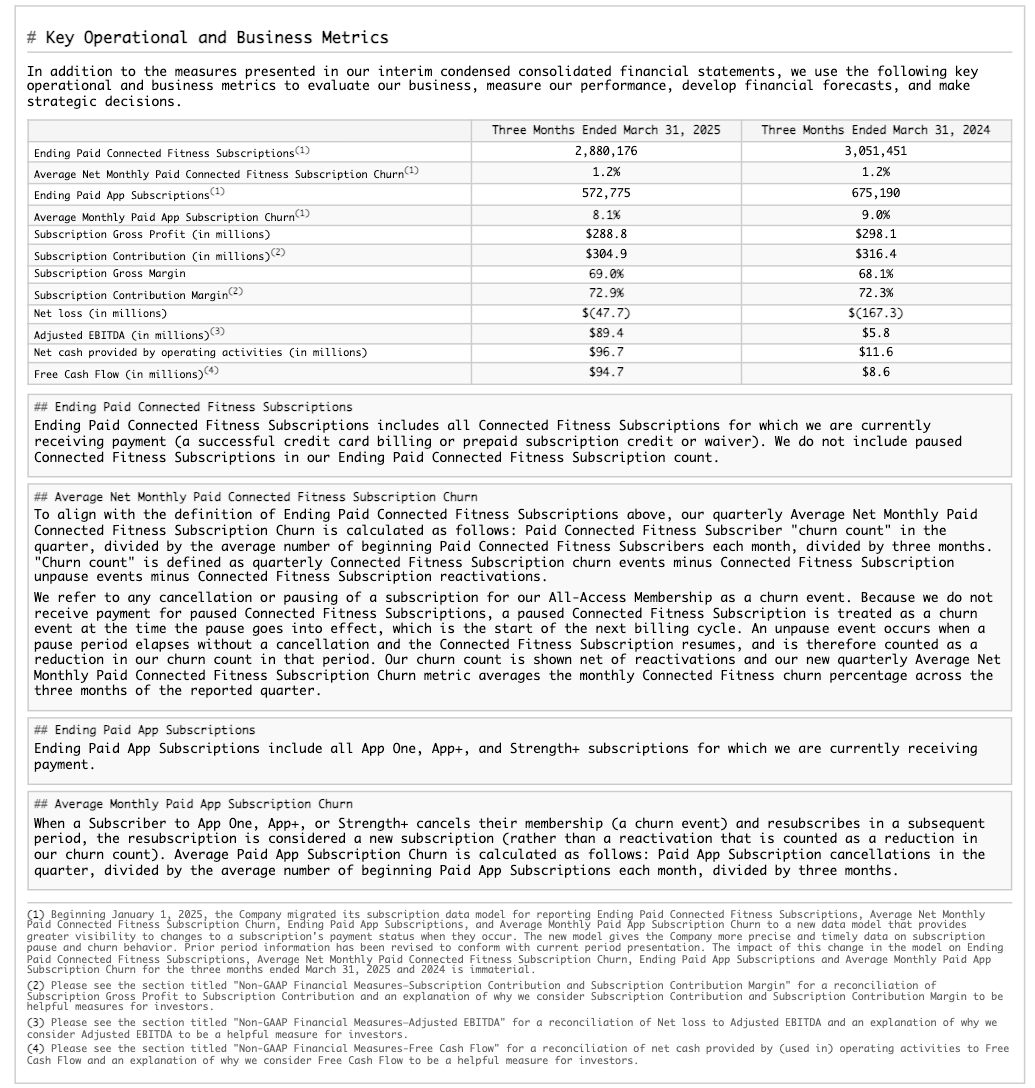
Exemple d’extraction de la structure de table¶
Cet exemple illustre l’extraction de la mise en page structurelle, y compris une table, à partir d’un formulaire 10-K. le schéma suivant montre les résultats rendus pour l’une des pages traitées (index de page 28 dans la sortie JSON).
Page du document d’origine |
Markdown extrait rendu en tant que HTML |
|---|---|
|
|
Astuce
Pour voir l’une de ces images à une taille plus lisible, sélectionnez-la en cliquant dessus ou en la touchant.
Ce qui suit est la commande SQL pour traiter le document original :
La réponse de AI_PARSE_DOCUMENT est un objet JSON contenant des métadonnées et du texte des pages du document, comme les suivants. Les résultats pour toutes les pages, sauf la page précédemment affichée, ont été omis par souci de brièveté.
Exemple de diaporama¶
Cet exemple illustre l’extraction de la mise en page structurelle à partir d’une présentation. ci-dessous, nous montrons les résultats rendus pour l’une des diapositives traitées (index de page 17 dans la sortie JSON).
Diapositive dans le document original |
Markdown extrait rendu en tant que HTML |
|---|---|

|

|
Astuce
Pour voir l’une de ces images à une taille plus lisible, sélectionnez-la en cliquant dessus ou en la touchant.
Ce qui suit est la commande SQL pour traiter le document original :
La réponse de AI_PARSE_DOCUMENT est un objet JSON contenant des métadonnées et le texte des diapositives de la présentation, comme les suivantes. Les résultats de certaines diapositives ont été omis par souci de brièveté.
Exemple de document multilingue¶
cet exemple présente les capacités multilingues de AI_PARSE_DOCUMENT en extrayant la mise en page structurelle d’un article en allemand. AI_PARSE_DOCUMENT préserve l’ordre de lecture du texte principal même lorsque des images et des guillemets extraits sont présents.
Page du document d’origine |
Markdown extrait rendu en tant que HTML |
|---|---|

|

|
Astuce
Pour voir l’une de ces images à une taille plus lisible, sélectionnez-la en cliquant dessus ou en la touchant.
Ce qui suit est la commande SQL pour traiter le document original. Comme le document comporte une seule page, vous n’avez pas besoin du fractionnement de page pour cet exemple.
La réponse de AI_PARSE_DOCUMENT est un objet JSON contenant des métadonnées et le texte du document, comme les suivants.
snowflake cortex peut produire une traduction dans n’importe quelle langue prise en charge (anglais, code de langue 'en', dans ce cas) comme suit :
La traduction est la suivante :
Utilisation du mode OCR¶
le mode OCR extrait du texte de documents numérisés, tels que des captures d’écran ou des PDFs contenant des images de texte. Il ne préserve pas la mise en page.
Sortie :
Traiter uniquement certaines pages d’un document¶
This example demonstrates using the page_filter option to extract specific pages from a document, specifically
the first page of a 55-page research paper. Keep in mind that page indexes starts at 0 and ranges are inclusive of
the start value but exclusive of the end value. For example, start: 0, end: 1 returns only the first page (index 0).
Résultat :
Catégoriser plusieurs documents¶
Pour catégoriser plusieurs documents, commencez par créer une table de fichiers en récupérant les emplacements des documents à partir d’un répertoire, en convertissant ces emplacements en objets FILE.
Appliquez ensuite AI_PARSE_DOCUMENT à chaque document de la table et traitez les résultats, par exemple en les transmettant à AI_CLASSIFY pour classer les documents par type. Il s’agit d’une approche efficace pour l’analyse de documents par lots dans un ensemble de documents.
La requête renvoie les libellés de classification pour chaque document.
Exigences en matière d’entrées¶
AI_PARSE_DOCUMENT est optimisé pour les documents numériques et numérisés. La table suivante répertorie les limitations et les exigences relatives aux documents d’entrée :
Taille maximale du fichier |
100 MB |
|---|---|
Nombre maximal de pages par document |
500 |
Résolution maximale de la page |
|
Types de fichiers pris en charge |
PDF, PPTX, DOCX, JPEG, JPG, PNG, TIFF, TIF, HTML, TXT |
Chiffrement de la zone de préparation |
Chiffrement côté serveur |
Taille de la police |
8 points ou plus pour les meilleurs résultats |
Fonctionnalités et limitations relatives aux documents pris en charge¶
Orientation de la page |
AI_PARSE_DOCUMENT détecte automatiquement l’orientation de la page. |
|---|---|
Fractionnement des pages |
AI_PARSE_DOCUMENT peut diviser des documents de plusieurs pages en pages distinctes et analyser chacune d’entre elles séparément. Cela est utile pour le traitement de documents volumineux qui dépassent la taille maximale. |
Filtrage des pages |
AI_PARSE_DOCUMENT peut traiter certaines pages d’un document, au lieu de toutes, grâce à la spécification de plages de pages. Cela est utile lorsque vous savez sur quelles pages se trouvent les informations que vous recherchez. |
Caractères |
AI_PARSE_DOCUMENT détecte les caractères suivants :
|
Images |
AI_PARSE_DOCUMENT génère du balisage pour les images du document, mais n’extrait pas actuellement les images réelles. |
Éléments structurés |
AI_PARSE_DOCUMENT détecte et extrait automatiquement les tables et les formulaires. |
Polices |
AI_PARSE_DOCUMENT reconnaît le texte dans la plupart des polices à empattement et sans empattement, mais peut avoir des difficultés avec les polices décoratives ou de script. La fonction ne reconnaît pas l’écriture manuelle. |
Langues acceptées¶
AI_PARSE_DOCUMENT est entraîné pour les langues suivantes :
Mode OCR |
Mode LAYOUT |
|---|---|
|
|
Disponibilité régionale¶
La prise en charge de AI_PARSE_DOCUMENT est disponible pour les comptes dans les régions Snowflake suivantes :
AWS |
Azure |
Google Cloud Platform |
|---|---|---|
US Ouest 2 (Oregon) |
Est US 2 (Virginie) |
US Central 1 (Iowa) |
US East (Ohio) |
Ouest US 2 (Washington) |
|
US East 1 (N. du Nord) |
Europe (Pays-Bas) |
|
Europe (Irlande) |
||
Europe Central 1 (Francfort) |
||
Europe West 2 (London) |
||
Asie-Pacifique (Sydney) |
||
Asie-Pacifique (Tokyo) |
AI_PARSE_DOCUMENT dispose d’une prise en charge interrégionale dans les autres régions Snowflake. Pour plus d’informations sur l’activation de la prise en charge interrégionale de Cortex AI, voir Inférence interrégionale.
Exigences en matière de contrôle d’accès¶
Pour utiliser la fonction AI_PARSE_DOCUMENT, un utilisateur ayant un rôle ACCOUNTADMIN doit accorder le rôle de base de données SNOWFLAKE.CORTEX_USER à l’utilisateur qui appellera la fonction. Consultez la rubrique Privilèges LLM Cortex pour plus de détails.
Considérations relatives aux clients¶
La fonction Cortex AI_PARSE_DOCUMENT engendre des coûts de calcul basés sur le nombre de pages par document traité. Ce qui suit décrit comment les pages sont comptées pour différents formats de fichiers :
Pour les formats de fichiers paginés (PDF, DOCX), chaque page du document est facturée comme une page.
Pour les formats d’images (JPEG, JPG, TIF, TIFF, PNG), chaque fichier d’image est facturé comme une page.
Pour les fichiers HTML et TXT, chaque morceau de 3 000 caractères est facturé comme une page, y compris le dernier morceau, qui peut être inférieur à 3 000 caractères.
Snowflake recommande d’exécuter les requêtes qui font appel à la fonction Cortex AI_PARSE_DOCUMENT dans un entrepôt plus petit (pas plus grand que MEDIUM). Des entrepôts plus grands n’augmentent pas les performances.
Conditions d’erreur¶
Snowflake Cortex AI_PARSE_DOCUMENT peut produire les messages d’erreur suivants.
Message |
Explication |
|---|---|
|
Le document d’entrée contient une langue non prise en charge. |
|
Le document présente un format non pris en charge. |
|
Le format de fichier n’est pas pris en charge et n’est pas compris comme un fichier binaire. |
|
Le document dépasse la limite de 500 pages. |
|
L’image saisie ou la page du document converti dépasse les dimensions prises en charge. |
|
La page dépasse les dimensions prises en charge. |
|
Le document dépasse 100 MB. |
|
Le fichier n’existe pas. |
|
Impossible d’accéder au fichier en raison de privilèges insuffisants. |
|
Un délai d’expiration s’est produit. |
|
Une erreur système s’est produite. Attendez et réessayez. |
Avis juridiques¶
La classification des données d’entrées et de sorties est présentée dans la table suivante.
Classification des données d’entrée |
Classification des données de sortie |
Désignation |
|---|---|---|
Usage Data |
Customer Data |
Les fonctions généralement disponibles sont des fonctions AI couvertes. Les fonctions d’aperçu sont les fonctions AI d’aperçu. [1] |
Pour plus d’informations, reportez-vous à Snowflake AI et ML.