チャネルと1回限りの配信¶
このトピックでは、Snowpipe Streamingが順序保証付きのチャネルでデータを取り込む方法と、オフセットトークンを使用して1回限りの配信を有効にする方法について説明します。
ストリーミング取り込みの基礎¶
Snowpipe Streamingは、いくつかの主要なストリーミング取り込みの原則に基づいて構築されています。
継続的な取り込み :データは、バッチに収集され定期的にロードされるのではなく、生成されるとSnowflakeに流れます。アプリケーションは、長期間の接続を通じて継続的に行を送信し、Snowflakeはデータを自動的にコミットします。
1回限りの配信 :クライアントの障害やネットワークの中断が発生した場合でも、各記録は正確に1回取り込まれます。Snowpipe Streamingは、オフセットトークンの追跡によってこれを実現します。これにより、クライアントはデータを重複することなく、最後にコミットされた位置から再開することができます。
順序付き取り込み :行は、チャネル内で送信された順にコミットされます。これは、時系列データ、 CDC パイプライン、および監査トレースにとって重要なソースシステムからのイベントのシーケンスを保持します。
低レイテンシ :データは取り込み後最短5秒でクエリに利用できるようになります。これにより、従来のバッチロードの遅延がない、ほぼリアルタイムの分析が可能になります。
サーバーレス :Snowflakeは、取り込みのためにすべてのコンピューティングリソースを管理します。リソースはスループットに基づいて自動的にスケーリングされ、クライアントがプロビジョニングまたは管理するインフラストラクチャは不要です。
データの流れ¶
クライアントアプリケーションは、Snowpipe Streaming SDK (JavaまたはPython)または REST API を使用してSnowflakeに接続します。クライアントは、パイプに対して1つ以上のチャネルを開き、それらのチャネルを介して行を送信します。Snowflakeは、データをターゲットテーブルにバッファーしてコミットし、数秒以内にクエリで使用できるようにします。
エンドツーエンドフロー:
クライアントアプリケーション は、 SDK (
appendRows)または REST API (Append Rowsエンドポイント)を使用して行を送信します。チャネル は、行を順番に受け取り、各バッチを進捗追跡のためにオフセットトークンに関連付けます。
パイプ は、データのサーバー側を処理します。スキーマを検証し、構成された変換または事前クラスタリングを適用してから、ターゲットテーブルにコミットします。
ターゲットテーブル はコミットされたデータを受け取り、そのデータはすぐにクエリ可能になります。
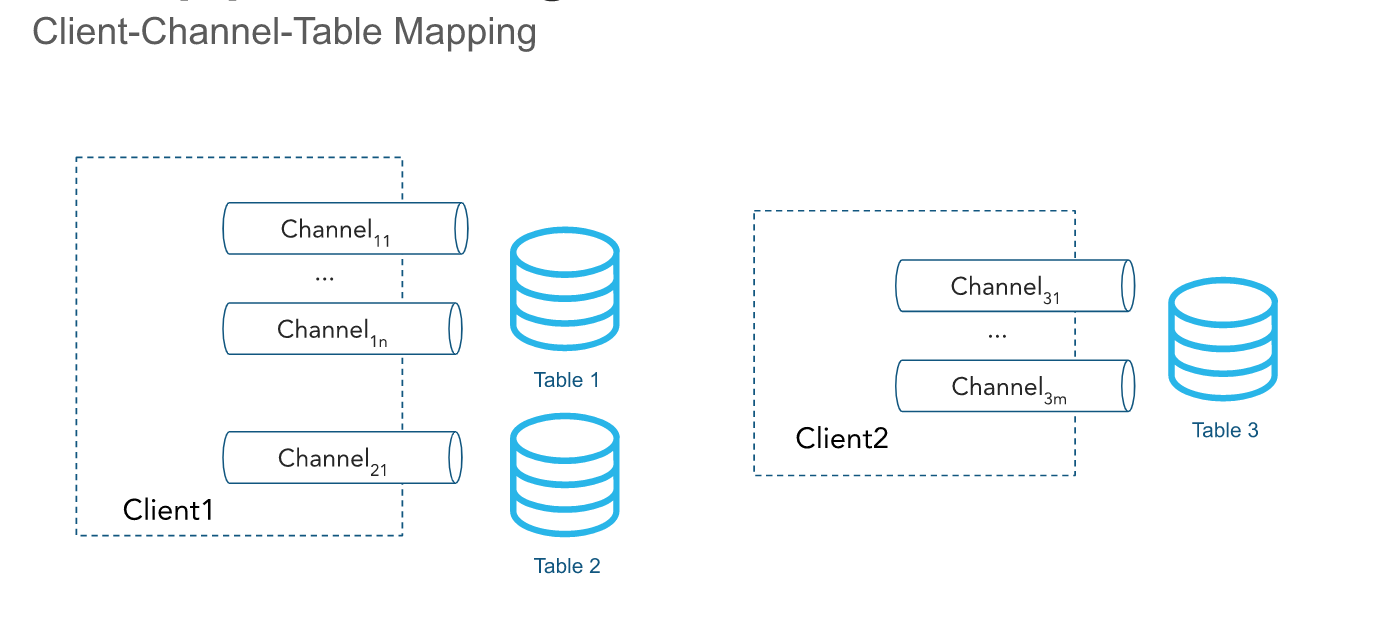
チャネル¶
チャネルは、データをテーブルにロードするためのSnowflakeへの論理的な名前付きストリーミング接続です。チャネルは2つの保証を提供します。
順序付き取り込み :行の順序とそれに対応するオフセットトークンはチャネル内に保持されます。
1回限りの配信 :オフセットトークンを使用すると、クライアントはコミットされた進捗状況を追跡し、復旧時に最後にコミットされた位置からリプレイすることができます。
順序はチャネル内で保持されますが、同じテーブルをポイントするチャネル間では保持されません。
チャネルはパイプに対して開かれます。クライアント SDK は複数のチャネルを複数のパイプに開くことができますが、 SDK はアカウント間でチャネルを開くことはできません。チャネルは、クライアントが活発にデータを挿入していると長い間維持され、オフセットトークンの情報が保持されるため、クライアントプロセスの再起動後も再利用されるべきです。
チャンネルと関連するオフセットメタデータが不要に なった場合、 DropChannelRequest API を使用して、 チャンネルを永久的に削除することができます。2つの方法でチャネルをドロップできます。
クロージングでチャネルを削除する。チャネル内のデータは、チャネルが削除される前に自動的にフラッシュされます。
やみくもにチャネルを削除する。保留中のデータはすべて破棄されるため、このアプローチは推奨されません。
SHOW CHANNELS コマンドを実行すると、アクセス権限のあるチャンネルをリストできます。詳細については、 SHOW CHANNELS をご参照ください。
注釈
非アクティブなチャネルとそのオフセットトークンは、30日を過ぎると自動的に削除されます。
オフセットトークンと1回限りの配信¶
Tip
Snowpipe Streamingにおける「1回限り」の仕組み :アプリケーションは、オフセットトークン(例:Kafkaパーティションオフセット)を使用して行を送信します。Snowflakeは、データがコミットされたときにトークンを永続化します。復旧時に、アプリケーションは getLatestCommittedOffsetToken を呼び出し、中断した位置を見つけて、その位置からリプレイします。重複データは取り込みされず、データは失われません。
オフセットトークン は、チャネルごとに取り込みの進行状況を追跡するために、クライアントが行送信リクエストに含める文字列です。使用される具体的なメソッドは、 SDK に対しては appendRow または appendRows 、および REST API に対しては Append Rows エンドポイントです。
トークンはチャネルの作成時に NULL に初期化され、提供されたオフセットトークンを持つ行がSnowflakeにコミットされるときに更新されます。クライアントは定期的に getLatestCommittedOffsetToken を呼び出して、チャネルに対してコミットされた最新のオフセットトークンを取得し、それを使用して取り込みの進行状況を判断できます。
クライアントがチャネルを再度開くと、最新の永続化されたオフセットトークンが返されます。クライアントは、トークンを使用してデータソース内の位置をリセットし、同じデータを2回送信することを回避できます。チャネルの再開イベントが発生すると、Snowflakeにバッファーされたコミットされていないデータは、コミットを回避するために破棄されます。
最新のコミットされたオフセットトークンを使用して、次を実行できます。
取り込みの進行状況を追跡する
特定のオフセットがコミットされているかどうかを、最後にコミットされたオフセットトークンと比較することによって確認する
ソースオフセットを提出し、すでにコミットされたデータをパージする
重複排除を有効にし、データを1回限り配信するようにする
例:Kafkaコネクタのクラッシュ復旧
Kafkaコネクタは、 <partition>:<offset> などのトピックからオフセットトークンを読み取ります。または、パーティションがチャネル名にエンコードされている場合は、単に を読み取ることができます。次のシナリオを検討してください。
Kafkaコネクタがオンラインになり、Kafkaトピック
TのPartition 1に対応するチャネルがT:P1というチャネル名で開きます。コネクタは、Kafkaパーティションからの記録の読み取りを開始します。
コネクタは API を呼び出し、記録に関連付けられたオフセットをオフセットトークンとして使用して
appendRowsメソッドリクエストを作成します。たとえば、オフセットトークンは
10で、Kafkaパーティションの10番目の記録を参照します。コネクタは定期的に
getLatestCommittedOffsetTokenメソッドリクエストを実行し、インジェストの進行状況を判断します。
Kafkaコネクタがクラッシュした場合は、次のプロシージャが正しいオフセットからの記録の読み取りを再開します。
Kafkaコネクタがオンラインに戻り、以前と同じ名前を使用してチャネルを再度開きます。
コネクタは
getLatestCommittedOffsetTokenを呼び出し、パーティションの最新のコミット済みオフセットを取得します。たとえば、最新の永続オフセットトークンが
20であるとします。コネクタは、Kafka読み取り APIs を使用して、オフセット+1 (この例では
21)に対応するカーソルをリセットします。コネクタは記録の読み取りを再開します。読み取りカーソルが正常に再配置されると、重複するデータは取得されません。
例:クラッシュ復旧を使用したログファイルの取り込み
アプリケーションはディレクトリからログを読み込み、Snowpipe Streaming SDK を使用してこれらのログをSnowflakeにエクスポートします。アプリケーションは以下を実行します。
ログディレクトリ内のファイルをリストする。
ログフレームワークが生成するログファイルは辞書順に並べることができ、新しいログファイルはこの順序の最後に配置されるとします。
ログファイルを1行ずつ読み取り、 API を呼び出して、ログファイル名と行数またはバイト位置に対応するオフセットトークンを使用して
appendRowsメソッドリクエストを作成する。たとえば、オフセットトークンは
messages_1.log:20のようになります。ここで、messages_1.logはログファイルの名前で、20は行番号です。
アプリケーションがクラッシュしたり、再起動が必要になったりすると、 getLatestCommittedOffsetToken が呼び出され、最後にエクスポートされたログファイルと行に対応するオフセットトークンが取得されます。例を続けると、これは messages_1.log:20 になります。その後、アプリケーションは messages_1.log を開き、行 21 を検索して、同じログ行が2回取り込まれないようにします。
注釈
オフセットトークンの情報が失われる可能性があります。オフセットトークンはチャネルオブジェクトにリンクされており、チャネルを使用して新しいインジェスチョンが30日間実行されない場合、チャネルは自動的にクリアされます。オフセットトークンの損失を防ぐために、別のオフセットを維持し、必要に応じてチャネルのオフセットトークンをリセットすることを検討してください。
offsetToken および continuationToken のロール¶
offsetToken および continuationToken の両方とも1回だけのデータ配信を保証するために使用されますが、これらは異なる目的を果たし、異なるサブシステムによって管理されます。主な違いは、誰がトークンの値とその使用範囲を管理するかです。
continuationToken( REST API を直接利用するユーザーのみが使用):このトークンはSnowflakeによって管理され、単一の継続的なストリーミングセッションの状態を維持するために不可欠です。クライアントが
Append RowsAPI を使用してデータを送信する場合、SnowflakeはcontinuationTokenを返します。クライアントは次の AppendRows リクエストでこのトークンを渡し、データが正しい順序でギャップなくSnowflakeに受信されるようにする必要があります。Snowflakeはトークンを使用して、SDK 再試行が発生した場合に重複データまたは不足データを検出し、防ぎます。offsetToken:このトークンは、外部ソースからの1回限りの配信を可能にするユーザー定義の識別子です。Snowflakeはこの値を保存しますが、独自の内部操作や再取り込みの防止には使用しません。SnowflakeからoffsetTokenを読み取り、それを使用して自身の取り込みの進捗を追跡し、外部ストリームのリプレイが必要な場合に重複データの送信を回避するのは、外部システム(Kafkaコネクタなど)の責任です。