Kanäle und genau einmalige Bereitstellung¶
Unter diesem Thema wird erklärt, wie Snowpipe Streaming Daten über Kanäle mit garantierter Reihenfolge aufnimmt und wie Offset-Token eine genau einmalige Bereitstellung ermöglichen.
Grundlagen zur Streaming-Datenaufnahme¶
Snowpipe Streaming basiert auf mehreren zentralen Prinzipien der Streaming-Datenaufnahme:
Kontinuierliche Datenaufnahme: Die Daten fließen in Snowflake ein, während sie erzeugt werden, anstatt in Batches gesammelt und regelmäßig geladen zu werden. Anwendungen übermitteln kontinuierlich Zeilen über dauerhafte Verbindungen, und Snowflake überträgt die Daten automatisch.
Genau einmalige Bereitstellung: Jeder Datensatz wird genau einmal erfasst, auch bei Client-Ausfällen oder Netzwerkunterbrechungen. Snowpipe Streaming erreicht dies durch die Verfolgung von Offset-Token, sodass Clients an der letzten bestätigten Position fortfahren können, ohne Daten zu duplizieren.
Geordnete Datenaufnahme: Zeilen werden in der Reihenfolge übertragen, in der sie innerhalb eines Kanals übermittelt werden. Dadurch wird die Sequenz von Ereignissen aus dem Quellsystem beibehalten, was für Zeitreihendaten, CDC-Pipelines und Prüfpfade entscheidend ist.
Niedrige Latenz: Die Daten stehen bereits 5 Sekunden nach der Erfassung für Abfragen zur Verfügung. Dies ermöglicht Analysen nahezu in Echtzeit ohne die Verzögerungen, die beim herkömmlichen Batch-Ladevorgängen auftreten.
Serverlos: Snowflake verwaltet alle Computeressourcen für die Datenaufnahme. Die Ressourcen skalieren automatisch nach Durchsatz, ohne dass der Client eine Infrastruktur bereitstellen oder verwalten muss.
Datenfluss¶
Eine Clientanwendung verbindet sich über ein Snowpipe Streaming SDK (Java oder Python) oder die REST API mit Snowflake. Der Client öffnet einen oder mehrere Kanäle für eine Pipe und übermittelt dann Zeilen über diese Kanäle. Snowflake puffert die Daten und überträgt sie an die Zieltabelle, sodass sie innerhalb von Sekunden für Abfragen zur Verfügung stehen.
Der durchgängige Datenfluss:
Die Clientanwendung übermittelt Zeilen unter Verwendung des SDK (
appendRows) oder der REST API (Append Rows-Endpunkt).Der Kanal empfängt die Zeilen in einer bestimmten Reihenfolge und verknüpft jeden Batch mit einem Offset-Token zur Fortschrittsverfolgung.
Die Pipe verarbeitet die Daten serverseitig: Sie validiert das Schema, wendet alle konfigurierten Transformationen oder Pre-Clustering an und führt dann ein Commit für die Zieltabelle aus.
Die Zieltabelle empfängt die übertragenen Daten, die sofort abfragbar sind.
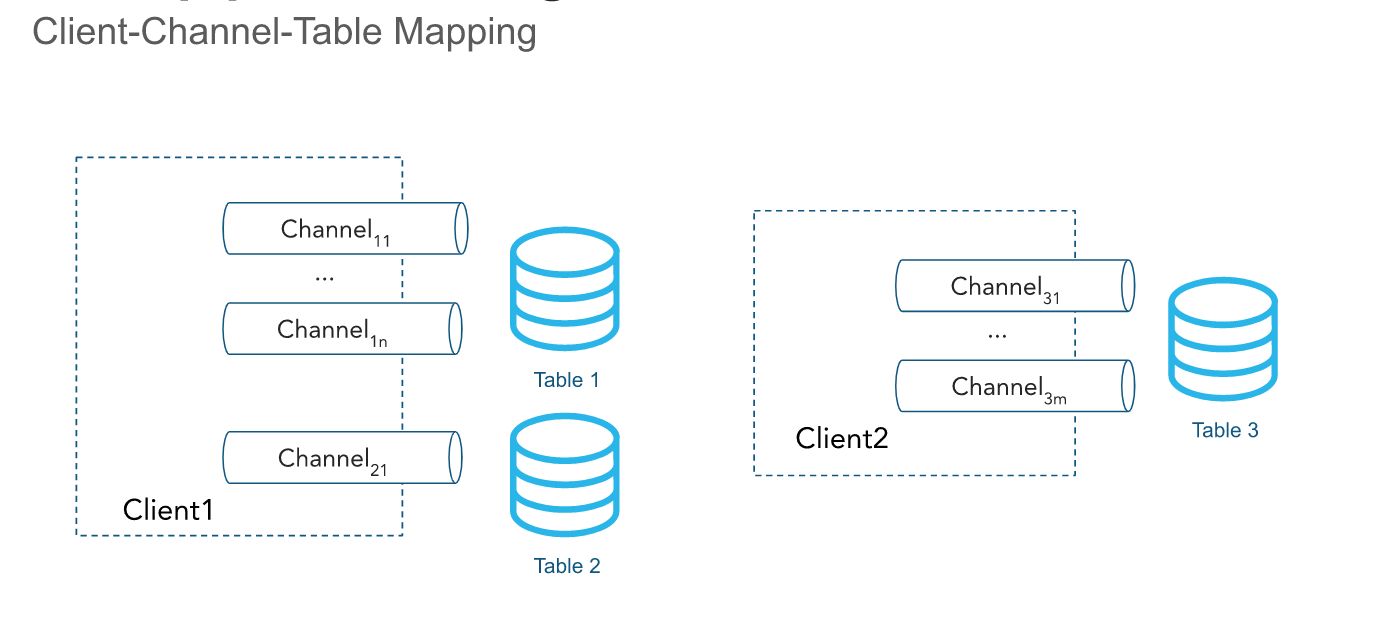
Kanäle¶
Ein Kanal ist eine benannte logische Streaming-Verbindung zu Snowflake, über die Daten in eine Tabelle geladen werden. Kanäle bieten zwei Garantien:
Geordnete Datenaufnahme: Die Reihenfolge der Zeilen und der entsprechenden Offset-Token wird innerhalb eines Kanals beibehalten.
Genau einmalige Bereitstellung: Offset-Tokens ermöglichen es Clients, den bestätigten Fortschritt zu verfolgen und im Wiederherstellungsfall ab der letzten bestätigten Position den Vorgang zu wiederholen.
Die Reihenfolge wird innerhalb eines Kanals beibehalten, aber nicht zwischen Kanälen, die auf dieselbe Tabelle verweisen.
Kanäle werden für eine Pipe geöffnet. Das Client-SDK kann mehrere Kanäle zu mehreren Pipes öffnen, aber das SDK kann keine kontenübergreifenden Kanäle öffnen. Kanäle sind für eine lange Verwendungsdauer gedacht, wenn ein Client aktiv Daten einfügt, und sollten bei Neustarts des Clientprozesses wiederverwendet werden, da die Informationen zu Offset-Token erhalten bleiben.
Wenn der Kanal und die zugehörigen Offset-Metadaten nicht mehr benötigt werden, können Sie Kanäle mithilfe der DropChannelRequest API dauerhaft löschen. Sie können einen Kanal auf zwei Arten löschen:
Löschen eines Kanals beim Schließen Die Daten im Kanal werden automatisch gelöscht, bevor der Kanal gelöscht wird.
Blindes Löschen eines Kanals Wir empfehlen diesen Ansatz nicht, da dabei alle ausstehenden Daten verworfen werden.
Sie können den Befehl SHOW CHANNELS ausführen, um die Kanäle aufzulisten, für die Sie Zugriffsrechte haben. Weitere Informationen dazu finden Sie unter SHOW CHANNELS.
Bemerkung
Inaktive Kanäle werden zusammen mit ihren Offset-Token automatisch nach 30 Tagen Inaktivität gelöscht.
Offset-Token und genau einmalige Bereitstellung¶
Tipp
So funktioniert die genau einmalige Bereitstellung in Snowpipe Streaming: Ihre Anwendung übermittelt Zeilen mit einem Offset-Token (z. B. ein Kafka-Partitions-Offset). Snowflake behält das Token bei, wenn die Daten übertragen werden. Bei der Wiederherstellung ruft Ihre Anwendung getLatestCommittedOffsetToken auf, um die letzte Position zu ermitteln, und setzt dann die Verarbeitung ab dieser Position fort. Es werden keine doppelten Daten aufgenommen und es gehen keine Daten verloren.
Ein Offset-Token ist eine Zeichenfolge, die ein Client in Zeilenübermittlungsanforderungen einfügt, um den Erfassungsfortschritt pro Kanal zu verfolgen. Die verwendeten Methoden sind:code:appendRow oder:code:appendRows für das SDK und der Append Rows-Endpunkt für die REST API.
Das Token wird bei der Erstellung des Kanals mit NULL initialisiert, und es wird aktualisiert, wenn die Zeilen mit einem bereitgestellten Offset-Token an Snowflake übergeben werden. Clients können in regelmäßigen Abständen getLatestCommittedOffsetToken aufrufen, um das letzte bestätigte Offset-Token für einen Kanal abzurufen und daraus Rückschlüsse auf den Erfassungsfortschritt zu ziehen.
Wenn ein Client einen Kanal wieder öffnet, wird das letzte gespeicherte Offset-Token zurückgegeben. Der Client kann seine Position in der Datenquelle mithilfe des Tokens zurücksetzen, um zu vermeiden, dass dieselben Daten zweimal gesendet werden. Bei einem Wiederöffnungsereignis eines Kanals werden alle in Snowflake gepufferten, unbestätigten Daten verworfen, damit sie nicht übertragen werden.
Sie können das letzte bestätigte Offset-Token verwenden, um Folgendes durchzuführen:
Verfolgen des Erfassungsfortschritts
Überprüfen, ob ein bestimmter Offset übertragen wurde, indem dieser mit dem letzten übertragenen Offset-Token verglichen wird
Aktualisieren des Quellen-Offsets und Bereinigen der bereits bestätigten Daten
Aktivieren der Deduplizierung und Sicherstellen der genau einmaligen Bereitstellung von Daten
Beispiel: Wiederherstellung nach Absturz des Kafka-Konnektors
Der Kafka-Konnektor liest ein Offset-Token aus einem Topic wie <partition>:<offset>. Betrachten Sie das folgende Szenario:
Der Kafka-Konnektor geht online und öffnet einen Kanal, der
Partition 1im Kafka-TopicTmit dem KanalnamenT:P1entspricht.Der Konnektor beginnt mit dem Lesen von Datensätzen aus der Kafka-Partition.
Der Konnektor ruft die API auf und führt eine
appendRows-Methodenanforderung mit dem Offset aus, der dem Datensatz als Offset-Token zugeordnet ist.Das Offset-Token könnte zum Beispiel
10lauten und damit auf den zehnten Datensatz in der Kafka-Partition verweisen.Der Konnektor führt in regelmäßigen Abständen
getLatestCommittedOffsetToken-Methodenanforderungen aus, um den Erfassungsfortschritt zu ermitteln.
Wenn der Kafka-Konnektor abstürzt, wird das Lesen der Datensätze aus dem korrekten Offset wie folgt fortgesetzt:
Der Kafka-Konnektor ist wieder online und öffnet den Kanal erneut unter demselben Namen wie zuvor.
Der Konnektor ruft
getLatestCommittedOffsetTokenauf, um den letzten bestätigten Offset für die Partition zu erhalten.Angenommen, das letzte persistent gespeicherte Offset-Token ist
20.Der Konnektor verwendet die Kafka-Lese-APIs, um einen Cursor zurückzusetzen, der dem Offset plus 1 zugeordnet ist (in diesem Beispiel
21).Der Konnektor setzt das Lesen der Datensätze fort. Nachdem der Lesecursor erfolgreich neu positioniert wurde, werden keine doppelten Daten abgerufen.
Beispiel: Datenaufnahme von Protokolldateien mit Wiederherstellung nach Absturz
Eine Anwendung liest Protokolle aus einem Verzeichnis und verwendet das Snowpipe Streaming SDK, um diese Protokolle nach Snowflake zu exportieren. Die Anwendung macht Folgendes:
Listet Dateien im Protokollverzeichnis auf.
Angenommen, das Protokollierungs-Framework generiert Protokolldateien, die lexikografisch sortiert werden können, wobei neue Protokolldateien an das Ende dieser Sortierung positioniert werden.
Liest eine Protokolldatei zeilenweise und ruft die API auf, die
appendRows-Methodenanforderungen mit einem Offset-Token ausführt, das dem Namen der Protokolldatei und der Zeilenzahl oder Byteposition entspricht.Ein Offset-Token könnte zum Beispiel
messages_1.log:20sein, wobeimessages_1.logder Name der Protokolldatei und20die Zeilennummer ist.
Wenn die Anwendung abstürzt oder neu gestartet werden muss, ruft sie getLatestCommittedOffsetToken auf, um das Offset-Token abzurufen, das der letzten exportierten Protokolldatei und -zeile entspricht. Im Beispiel wäre dies messages_1.log:20. Die Anwendung öffnet dann messages_1.log und sucht nach Zeile 21, um zu verhindern, dass dieselbe Protokollzeile zweimal erfasst wird.
Bemerkung
Die Informationen zum Offset-Token können verloren gehen. Das Offset-Token ist mit einem Kanalobjekt verknüpft, und ein Kanal wird automatisch gelöscht, wenn für einen Zeitraum von 30 Tagen keine neue Erfassung unter Verwendung des Kanals ausgeführt wird. Um den Verlust des Offset-Tokens zu verhindern, sollten Sie einen separaten Offset pflegen und das Offset-Token des Kanals bei Bedarf zurückzusetzen.
Rollen von offsetToken und continuationToken¶
offsetToken und continuationToken werden beide verwendet, um eine genau einmalige Datenbereitstellung sicherzustellen, aber sie dienen unterschiedlichen Zwecken und werden von unterschiedlichen Untersystemen verwaltet. Der primäre Unterschied besteht darin, wer den Wert des Tokens und den Umfang seiner Verwendung kontrolliert.
continuationToken(nur von direkten REST API-Benutzenden verwendet):Dieses Token wird von Snowflake verwaltet und ist unerlässlich, um den Status einer einzelnen, kontinuierlichen Streaming-Sitzung aufrecht zu erhalten. Wenn ein Client Daten über die
Append RowsAPI sendet, gibt Snowflake eincontinuationTokenzurück. Der Client muss dieses Token in seiner nächsten AppendRows-Anforderung zurücksenden, um sicherzustellen, dass die Daten in der richtigen Reihenfolge und ohne Lücken empfangen werden. Snowflake verwendet das Token, um doppelte oder fehlende Daten im Falle eines erneuten SDK-Versuchs zu erkennen und zu verhindern.offsetToken:Dieses Token ist ein benutzerdefinierter Bezeichner, der die genau einmalige Bereitstellung von einer externen Quelle ermöglicht. Snowflake speichert diesen Wert, verwendet ihn aber nicht für seine eigenen internen Operationen oder um eine erneute Erfassung zu verhindern. Es liegt in der Verantwortung des externen Systems (wie eines Kafka-Konnektors), das offsetToken von Snowflake zu lesen und es zu verwenden, um den eigenen Aufnahmefortschritt zu verfolgen und das Senden doppelter Daten zu vermeiden, wenn der externe Stream wiederholt werden muss.