pandas on Snowflake¶
pandas on Snowflakeを使用すると、Snowflakeのデータ上で直接pandasコードを実行できます。importステートメントと数行のコードを変更するだけで、堅牢なパイプラインを開発するための使い慣れたpandasのエクスペリエンスを得ることができ、パイプラインのスケールに応じたSnowflakeのパフォーマンスとスケーラビリティの恩恵をシームレスに受けることができます。
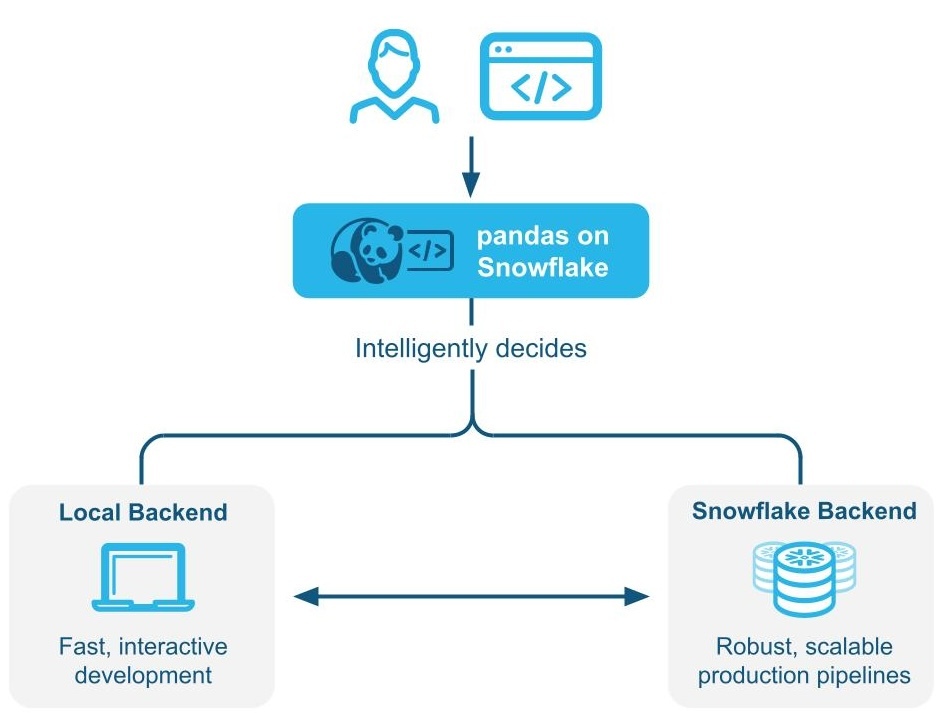
pandas on Snowflakeは、pandasコードをローカルで実行するか、Snowflakeエンジンを使用して ハイブリッド実行 によってスケーリングしパフォーマンスを向上させるかをインテリジェントに判断します。Snowflakeのワークロードをネイティブに実行し、 SQLにトランスパイルすることで、並列化、データガバナンス、セキュリティといったSnowflakeの利点を活用することができます。
pandas on Snowflakeは、 Snowpark Pythonライブラリ の一部としてSnowpark pandas APIを通じて提供され、Snowflakeプラットフォーム内でPythonコードのスケーラブルなデータ処理を可能にします。
pandas on Snowflakeを使うメリット¶
Python開発者の必要に合致: pandas on Snowflakeは、Snowflakeでネイティブに動作するpandas互換のレイヤーにより、Python開発者に親しみやすいインターフェースを提供します。
スケーラブルな分散pandas pandas on Snowflakeは、Snowflakeの既存のクエリ最適化技術を活用することで、pandasの利便性とSnowflakeのスケーラビリティを橋渡しします。コードの書き換えは最小限に抑えられ、移行作業が簡素化されるため、プロトタイプから本番稼動までシームレスに移行できます。
管理とチューニングに追加のコンピューティングインフラストラクチャは不要: pandas on SnowflakeはSnowflakeのパワフルなコンピューティングエンジンを活用するため、追加のコンピューティングインフラストラクチャを設定したり管理したりする必要はありません。
pandas on Snowflake入門¶
pandas on Snowflakeをインストールするには、condaまたはpipを使用してパッケージをインストールします。詳細な手順については、 Installation をご参照ください。
pandas on Snowflakeがインストールされたら、pandasを import pandas as pd としてインポートする代わりに、以下の2行を使用します。
ここでは、pandas on Snowpark Pythonライブラリを通じて、pandas on Snowflakeを使用する方法の一例を紹介します。
read_snowflake は、Snowflakeビュー、動的テーブル、Icebergテーブルなどからの読み取りをサポートしています。また、 SQLクエリを直接渡すと、pandas on Snowflake DataFrame が返ってくるので、 SQLとpandas on Snowflakeをシームレスに行き来することが簡単にできます。
ハイブリッド実行の仕組み¶
注釈
Snowpark Pythonバージョン1.40.0から、Snowflakeでpandasを使用する場合、デフォルトでハイブリッド実行が有効になりました。
pandas on Snowflakeは、pandasのコードをローカルで実行するか、Snowflakeエンジンを使用してスケーリングとパフォーマンス向上を行うかを決定するために、ハイブリッド実行を使用します。これにより、パイプラインのスケールに合わせてSnowflakeのパフォーマンスとスケーラビリティの恩恵をシームレスに受けながら、コードを実行する最適で効率的な方法を考えることなく、堅牢なパイプラインを開発するために使い慣れたpandasコードを書き続けることができます。
例1:11行の小さな DataFrameインラインを作成します。ハイブリッド実行では、Snowflakeはローカルのインメモリpandasバックエンドを選択して処理を実行します。
**例2**テーブルに1,000万行のトランザクションをシードします
これはSnowflakeに存在する大きなテーブルなので、テーブルがバックエンドとしてSnowflakeを活用していることがわかります。
例3 :データにフィルターをかけ、 groupby 集計を行い、7行のデータを得ます。
データがフィルタリングされると、出力が7行のデータのみであるため、Snowflakeは、バックエンドの選択としてのSnowflakeからpandasへのエンジンの変更を暗黙的に認識します。
リスクと制限¶
DataFrame型は、バックエンドが変更されても常に
modin.pandas.DataFrame/Series/etcであり、下流のコードとの相互運用性/互換性を保証します。使用するバックエンドを決定するために、Snowflakeは各ステップで DataFrameの正確な長さを計算する代わりに、行サイズの推定値を使用することがあります。つまり、データセットが大きくなったり小さくなったりした場合(フィルターや集約など)、Snowflakeが操作直後に最適なバックエンドに切り替わるとは限りません。
異なるバックエンドにまたがる2つ以上の DataFramesを組み合わせた操作がある場合、Snowflakeは最も低いデータ転送コストに基づいてデータの移動先を決定します。
Snowflakeはフィルタリングされたデータのサイズを推定できない場合があるため、フィルタリング操作によってデータが移動しない場合があります。
インメモリPythonデータで構成されるすべての DataFramesは、以下のようなpandasバックエンドが使用されます。
DataFramesは、限定された操作で自動的にSnowflakeエンジンからpandasエンジンに移行します。これらの操作には、
df.apply、df.plot、df.iterrows、df.itertuples、series.items、そしてデータのサイズがより小さくなることが保証されている縮小操作が含まれます。すべての操作が、データ移行が可能なポイントに対応しているわけではありません。ハイブリッド実行は、
pd.concatのような操作が複数の DataFramesに対して作用する場合を除き、 DataFrameをpandasエンジンからSnowflakeに自動的に戻すことはありません。Snowflakeは、
pd.concatのような操作が複数の DataFramesに作用しない限り、 DataFrameをpandasエンジンからSnowflakeに自動的に戻すことはありません。
pandas on Snowflakeを使うべき時¶
以下のいずれかに当てはまる場合は、pandas on Snowflakeを使用する必要があります。
あなたはpandas API と、より広い PyData エコシステムに精通しています。
pandasに精通し、同じコードベースで共同作業をしたい人とチームで仕事をします。
pandasで書かれた既存のコードがあります
AI ベースのCopilotツールによる、より正確なコード補完を好みます。
詳細については、 Snowpark DataFrames vs Snowpark pandas DataFrame: どちらを選ぶべきでしょうか? をご参照ください
Snowparkで pandas on Snowflakeを使う DataFrames¶
pandas on Snowflakeと DataFrame API は相互運用性が高いので、 APIs の両方を活用したパイプラインを構築することができます。詳細については、 Snowpark DataFrames vs Snowpark pandas DataFrame: どちらを選ぶべきでしょうか? をご参照ください
Snowpark DataFrames とSnowpark pandas DataFrames 間の変換を行うには、以下の操作を使用できます。
操作 |
入力 |
出力 |
|---|---|---|
Snowpark DataFrame |
Snowpark pandas DataFrame |
|
Snowpark pandas DataFrame またはSnowpark pandas Series |
Snowpark DataFrame |
pandas on Snowflakeがネイティブpandasを比較する方法¶
pandas on Snowflakeとネイティブpandasは、一致した DataFrameシグネチャと類似したセマンティクスを持つ類似した APIsを持っています。pandas on Snowflakeは、ネイティブpandasと同じ APIシグネチャを提供し、Snowflakeによるスケーラブルな計算を提供します。pandas on Snowflakeは、ネイティブpandasのドキュメントに記述されているセマンティクスを可能な限り尊重しますが、Snowflakeの計算と型システムを使用します。しかし、ネイティブpandasがクライアントマシン上で実行される場合は、Pythonの計算と型システムを使用します。pandas on SnowflakeとSnowflake間の型マッピングについては、 Data types をご参照ください。
Snowpark Python 1.40.0から、pandas on Snowflakeは、すでにSnowflakeにあるデータで使用するのが最適です。ネイティブpandasとpandas on Snowflake型を変換するには、以下の操作を使用します。
操作 |
入力 |
出力 |
|---|---|---|
Snowpark pandas DataFrame |
Native pandas DataFrame:すべてのデータをローカル環境に具現化します。データセットが大きい場合は、メモリ不足エラーになることがあります。 |
|
ネイティブpandas DataFrame、生データ、Snowpark pandasオブジェクト |
Snowpark pandas DataFrame |
実行環境¶
pandas:単一のマシンで動作し、メモリ内データを処理します。pandas on Snowflake:Snowflakeと統合することで、大規模なデータセットの場合はマシンのクラスタ全体で分散コンピューティングを行い、小規模なデータセットの処理にはインメモリpandasを活用することができます。この統合により、1台のマシンのメモリ容量を超えるような非常に大きなデータセットを扱うことができます。Snowpark pandas APIを使用するには、Snowflakeへの接続が必要であることに注意してください。
遅延評価と先行評価¶
pandas:即座に操作を実行し、操作後ごとに結果をメモリ内で完全に具現化します。このような操作の先行評価は、データをマシン内で広範囲に移動させる必要があるため、メモリ負荷の増加につながる可能性があります。pandas on Snowflake: pandasと同じ API エクスペリエンスを提供します。pandasの先行評価モデルを模倣していますが、内部的には遅延評価されたクエリグラフを構築し、処理全体の最適化を実現しています。クエリグラフを通じて操作を融合およびトランスパイルすることで、基になる分散Snowflakeコンピューティングエンジンにさらなる最適化の機会がもたらされ、Snowflake内で直接pandasを実行する場合と比較して、コストとエンドツーエンドのパイプライン実行時間の両方が削減されます。
注釈
I/O関連 APIs と、戻り値がSnowpark pandasオブジェクトではない APIs(つまり
DataFrameまたはSeries)のIndexは、常に先行評価されます。例:read_snowflaketo_snowflaketo_pandasto_dictto_list__repr__ダンダーメソッド、
__array__は、scikit-learnのようなサードパーティライブラリによって自動的に呼び出されます。このメソッドを呼び出すと、ローカルマシンに結果が具現化されます。
データソースおよびストレージ¶
pandas: IO ツール(text、 CSV、 HDF5 など) のpandasドキュメントにリストされている様々なリーダーとライターをサポートします。pandas on Snowflake:Snowflakeテーブルからの読み取りと書き込み、ローカルまたはステージングされた CSV、 JSON、parquetファイルの読み込みが可能です。詳細については IO (読み取りおよび書き込み) をご参照ください。
データ型¶
pandas: 整数型、浮動小数点数型、文字列型、datetime型、カテゴリ型など、豊富なデータ型を備えています。また、ユーザー定義のデータ型もサポートしています。pandasのデータ型は通常、基になるデータから派生し、厳格に適用されます。pandas on Snowflake:Snowflakeでpandasデータ型を SQL 型に変換してpandasオブジェクトを SQL にマッピングする、Snowflake型システムにより制約されます。pandas型の大部分は、Snowflakeで自然に等価なものを持っていますが、マッピングは必ずしも1対1であるとは限りません。場合によっては、複数のpandas型が同じ SQL 型にマッピングされます。
次のテーブルは、pandasとSnowflake SQL 間の型マッピングのリストです。
pandas型 |
Snowflake型 |
|---|---|
pandasの拡張整数型を含む、すべての符号付き/符号なし整数型 |
NUMBER(38, 0) |
pandasの拡張浮動小数点数データ型を含む、すべての浮動小数点数型 |
FLOAT |
|
BOOLEAN |
|
STRING |
|
TIME |
|
DATE |
タイムゾーンなしの全 |
TIMESTAMP_NTZ |
すべてのタイムゾーン対応 |
TIMESTAMP_TZ |
|
ARRAY |
|
MAP |
データ型が混在するオブジェクト列 |
VARIANT |
Timedelta64[ns] |
NUMBER(38, 0) |
注釈
カテゴリ型、周期型、区間型、スパース型、およびユーザー定義データ型はサポートされていません。Timedeltaは現在、Snowparkクライアントでのみサポートされています。TimedeltaをSnowflakeに書き戻す場合、Number型として保存されます。
次のテーブルでは、 df.dtypes を使用した、Snowflake SQL 型からpandas on Snowflake型へのマッピングを提供します。
Snowflake型 |
pandas on Snowflake型( |
|---|---|
NUMBER ( |
|
NUMBER ( |
|
BOOLEAN |
|
STRING, TEXT |
|
VARIANT, BINARY, GEOMETRY, GEOGRAPHY |
|
ARRAY |
|
OBJECT |
|
TIME |
|
TIMESTAMP, TIMESTAMP_NTZ, TIMESTAMP_LTZ, TIMESTAMP_TZ |
|
DATE |
|
to_pandas() を使用してSnowpark pandas DataFrame からネイティブpandas DataFrame に変換する場合、ネイティブpandas DataFrame はpandas on Snowflakeに比べて洗練されたデータ型になりますが、関数やプロシージャについては SQL-Pythonデータ型マッピング と互換性があります。
キャストおよび型推論¶
NULL値の取り扱い¶
pandas: pandasバージョン1.xでは、 欠損データの処理 が柔軟であったため、PythonNone、np.nan、pd.NaN、pd.NA、pd.NaTのすべてを欠損値として扱っていました。それ以降のpandasバージョン(2.2.x)では、これらの値は異なる値として扱われます。pandas on Snowflake: 以前のpandasバージョンと同様のアプローチを採用し、前述の先行値をすべて欠損値として扱います。Snowparkは、pandasからのNaN、NA、NaTを再利用します。しかし、これらの欠損値はすべてが同じように扱われ、Snowflakeテーブル内で SQL NULL として格納されます。
オフセット/頻度エイリアス¶
pandas: pandasの日付オフセットがバージョン2.2.1で変更されました。単一文字のエイリアス'M'、'Q'、'Y'などは、2文字のオフセットに取って代わられました。pandas on Snowflake: pandas時系列ドキュメント で説明されている新しいオフセットを排他的に使用します。
pandas on Snowflakeライブラリをインストールする¶
前提条件
以下のパッケージのバージョンが必要です。
Python 3.9(非推奨)、3.10、3.11、3.12、または3.13
modinバージョン0.32.0
pandasバージョン2.2.*
Tip
Snowflake Notebooks で pandas on Snowflakeを使用するには、 ノートブックのpandas on Snowflake のセットアップ手順をご参照ください。
開発環境のpandas on Snowflakeをインストールするには、以下の手順に従ってください。
プロジェクトディレクトリに移動し、Python仮想環境を有効にします。
注釈
API は現在開発中のため、システム全体ではなくPythonの仮想環境にインストールすることをお勧めします。この方法によって、作成するプロジェクトごとに特定のバージョンを使用することができ、将来のバージョンの変更から隔離することができます。
Anaconda、 Miniconda、 virtualenv などのツールを使用して、特定のPythonバージョン用のPython仮想環境を作成できます。
たとえば、condaを使用してPython 3.12の仮想環境を作成するには、これらのコマンドを使用します。
注釈
以前にPython 3.9とpandas 1.5.3を使用して古いバージョンのpandas on Snowflakeをインストールした場合は、上記のようにPythonとpandasのバージョンをアップグレードする必要があります。Python 3.10から3.13で新しい環境を作成する手順に従います。
ModinでSnowpark Pythonライブラリをインストールします。
or
注釈
snowflake-snowpark-pythonバージョン1.17.0以降がインストールされていることを確認します。
Snowflakeに対する認証¶
pandas on Snowflakeを使用する前に、Snowflakeデータベースとのセッションを確立する必要があります。構成ファイルを使用してセッションの接続パラメーターを選択することも、コード内でパラメーターを列挙することもできます。詳細については、 Snowpark Pythonのセッションの作成 をご参照ください。アクティブなSnowpark Pythonセッションが存在する場合、pandas on Snowflake は自動的にそれを使用します。例:
pd.session はSnowparkセッションであるため、他のSnowparkセッションと同じように操作できます。たとえば、これを使用して任意の SQL クエリを実行し、 セッションAPI にしたがってSnowpark DataFrame を生成できますが、結果はSnowpark pandas DataFrame ではなくSnowpark DataFrame になることに注意してください。
または、 構成ファイル でSnowpark接続パラメーターを設定することもできます。これにより、コード内で接続パラメーターを列挙する必要がなくなり、pandas on Snowflakeコードを通常のpandasコードとほぼ同じように記述することができるようになります。
~/.snowflake/connections.tomlに次のような構成ファイルを作成します。これらの認証情報を使用してセッションを作成するには、
snowflake.snowpark.Session.builder.create()を使用します。
また、複数の Snowpark セッションを作成し、そのうちの1つをpandas on Snowflakeに割り当てることもできます。pandas on Snowflakeは1つのセッションしか使用しないため、 pd.session = pandas_session で明示的にセッションの1つをpandas on Snowflakeに割り当てる必要があります。
次の例では、アクティブなSnowparkセッションがないときにpandas on Snowflakeを使用しようとすると、「pandas on Snowflake requires an active snowpark session, but there is none.」のようなエラーで SnowparkSessionException が発生します。セッションを作成すると、pandas on Snowflakeを使用できるようになります。例:
次の例では、複数のアクティブなSnowparkセッションがあるときにpandas on Snowflakeを使用しようとすると、「There are multiple active snowpark sessions, but you need to choose one for pandas on Snowflake.」のようなメッセージで SnowparkSessionException が発生します。
注釈
Snowflake DataFrameまたはSeriesで新しいpandasに使用するセッションは、 modin.pandas.session を介して設定する必要があります。ただし、異なるセッションで作成された DataFrames を結合またはマージすることはサポートされていないため、繰り返し異なるセッションを設定したり、ワークフローで異なるセッションを使用したりして DataFrames を作成することは避けてください。
API リファレンス¶
現在実装されている APIs と利用可能なメソッドの全リストは the pandas on Snowflake API 参照 をご参照ください。
サポートされている操作の完全なリストについては、pandas on Snowflakeリファレンスの以下のテーブルをご参照ください。
APIsおよびハイブリッド実行の設定パラメーター¶
ハイブリッド実行は、データセットの推定サイズと、 DataFrameに適用される操作の組み合わせを使用して、バックエンドの選択を決定します。一般的に、100k行未満のデータセットではローカルのpandasを使用する傾向があり、100k行を超えるデータセットでは、ローカルファイルから読み込まれない限り、Snowflakeを使用する傾向があります。
転送コストの構成¶
デフォルトの切り替えしきい値を別の行数制限値に変更するには、 DataFrameを初期化する前に環境変数を変更します。
この値を設定すると、Snowflakeから行を転送する際にペナルティが課されます。
ローカル実行制限の構成¶
DataFrameをマージのためにSnowflakeに戻す必要がない限り、通常はローカルに留まりますが、ローカルで処理できるデータの最大サイズに関する上限が考慮されます。現在、この境界は10M行です。
バックエンドのチェックと設定¶
現在選択されているバックエンドを確認するには、 df.getbackend() を使用できます。このコマンドは、ローカル実行の場合は Pandas 、プッシュダウン実行の場合は Snowflake を返します。
現在のバックエンドを設定するには、 set_backend またはそのエイリアス move_to のどちらかを選択します。
バックエンドを設定することもできます。
データが移動された 理由 に関する情報を検査し、表示するには、以下を行います。
バックエンドをピン留めすることで、バックエンドの選択を手動で上書きします。¶
デフォルトでは、Snowflakeは自動的に所与の DataFrameと操作に最適なバックエンドを選択します。エンジンの自動選択をオーバーライドしたい場合は、 pin_backend() メソッドを使用して、オブジェクトとそれによって生成されるすべての結果データの自動切り替えを無効にすることができます。
バックエンドの自動切り替えを再び有効にするには、 unpin_backend() を呼び出します。
SnowflakeノートブックでのSnowpark pandasの使用¶
Snowflakeノートブックで pandas on Snowflakeを使用するには、 notebooksの pandas on Snowflake をご参照ください。
PythonワークシートでのSnowpark pandasの使用¶
Snowpark pandasを使用するには、Pythonワークシート環境の Packages から modin を選択してModinをインストールする必要があります。
Python 関数のリターンタイプは Settings > Return type の下で選択できます。デフォルトではSnowparkテーブルとしてセットされています。結果として Snowpark pandas DataFrame を表示するには、 to_snowpark() を呼び出して、Snowpark pandas DataFrame を SnowparkDataFrame に変換します。この変換にI/Oコストは発生しません。
PythonワークシートでSnowpark pandasを使用する例です。
ストアドプロシージャでpandas on Snowflakeを使用する¶
pandas on Snowflakeを ストアドプロシージャ で使用してデータパイプラインを構築し、 タスク でストアドプロシージャの実行をスケジュールすることができます。
ここでは、 SQL を使用してストアドプロシージャを作成する方法を説明します。
ここでは、 Snowflake Python API を使用してストアドプロシージャを作成する方法を示します。
ストアドプロシージャを呼び出すには、Python で dt_pipeline_sproc() を実行するか、 SQL で CALL run_data_transformation_pipeline_sp() を実行します。
サードパーティライブラリでpandas on Snowflakeを使用する¶
pandasは可視化や機械学習アプリケーションのためにサードパーティライブラリ APIs でよく使用されます。pandas on Snowflakeはこれらのライブラリのほとんどと相互運用可能であるため、明示的にpandas DataFrames に変換することなく使用することができます。しかし、分散実行は、限られたユースケースを除いて、ほとんどのサードパーティライブラリではサポートされていないことが多いことに注意してください。そのため、大容量データセットのパフォーマンスが低下する可能性があります。
対応サードパーティライブラリ¶
以下にリストされているライブラリはpandas on Snowflake DataFrames を入力として受け付けますが、すべてのメソッドがテストされているわけではありません。API レベルでの詳細な相互運用性のステータスについては、 サードパーティライブラリとの相互運用性 をご覧ください。
Plotly
Altair
Seaborn
Matplotlib
Numpy
Scikit-learn
XGBoost
NLTK
Streamlit
pandas on Snowflakeは、現在のところ、一部の NumPy および Matplotlib APIs、 np.where 用の分散実装 と df.plot との相互運用性については限定された互換性を持ちます。これらのサードパーティライブラリで作業する場合、Snowpark pandas DataFrames を to_pandas() 経由で変換することで、複数の I/O 呼び出しを避けることができます。
以下は、視覚化用に Altair を、機械学習用に scikit-learn を使用した例です。
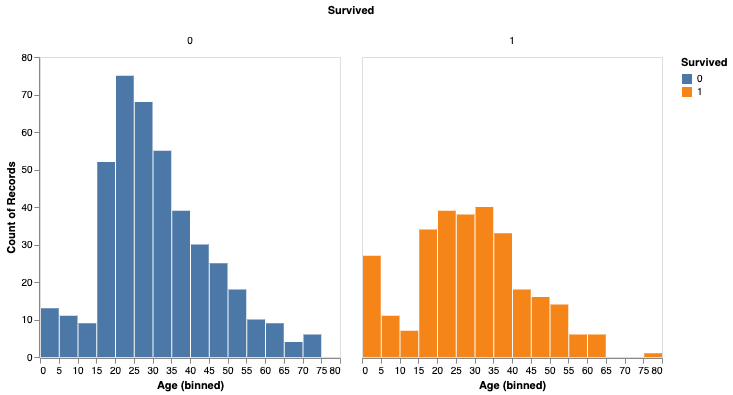
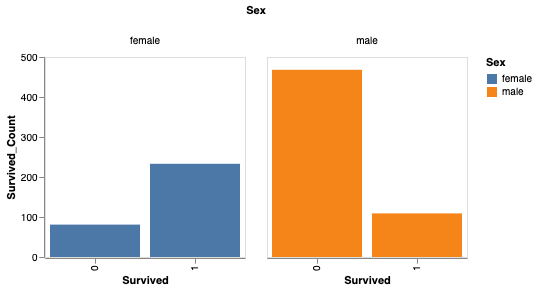
また、性別によって生存率を分析することもできます。
これでscikit-learnを使って簡単なモデルを学習できます。
注釈
パフォーマンスを向上させるために、特にscikit-learnのような機械学習ライブラリを使用する場合は、 to_pandas() によってpandas DataFrames に変換することをお勧めします。しかし、 to_pandas() 関数はすべての行を収集するので、最初に sample(frac=0.1) または head(10) を使用してデータフレームのサイズを縮小したほうがよい場合があります。
サポートされていないライブラリ¶
サポートされていないサードパーティライブラリをpandas on Snowflake DataFrame で使用する場合は、サードパーティライブラリのメソッドに DataFrame を渡す前に to_pandas() を呼び出してpandas on Snowflake DataFrame をpandas DataFrame に変換することをお勧めします。
注釈
to_pandas() を呼び出すと、データがSnowflakeからメモリに取り出されるため、大容量のデータセットや機密性の高いユースケースの場合はその点を考慮してください。
Snowflake Cortex LLM 関数をSnowpark pandasで使用する¶
Snowflake Cortex LLM 関数 を、 Snowpark pandas apply関数 を介して使用できます。
特殊なキーワード引数で関数を適用します。現在、以下のCortex関数がサポートされています。
以下の例では、Snowpark pandas DataFrame の複数の記録にわたって TRANSLATE 関数を使用しています。
出力:
次の例では、 reviews という名前のSnowflakeテーブルで SENTIMENT (SNOWFLAKE.CORTEX) 関数を使用します。
次の例では、 EXTRACT_ANSWER (SNOWFLAKE.CORTEX) を使って質問に答えています。
出力:
注釈
Cortex LLM 関数を使用するには、 snowflake-ml-python パッケージをインストールする必要があります。
制限事項¶
pandas on Snowflakeには以下の制限があります。
pandas on Snowflakeは、 OSS サードパーティライブラリとの互換性を保証するものではありません。しかし、バージョン1.14.0a1以降、Snowpark pandasは NumPy の互換性、特に
np.whereの使用を限定的に導入しています。詳細については、 NumPy の相互運用性 をご参照ください。Snowpark pandas DataFrame を使用してサードパーティライブラリ APIs を呼び出す場合、Snowflakeでは DataFrame をサードパーティライブラリ呼び出しに渡す前に
to_pandas()を呼び出して、Snowpark pandas DataFrame をpandas DataFrame に変換することをお勧めします。詳細については、 サードパーティライブラリでpandas on Snowflakeを使用する をご参照ください。pandas on Snowflakeは Snowpark ML と統合されていません。Snowpark ML を使用する場合は、Snowpark ML を呼び出す前に to_snowpark() を使用して、Snowpark pandas DataFrame をSnowpark DataFrame に変換することをお勧めします。
遅延
MultiIndexオブジェクトはサポートされていません。MultiIndexが使用されると、ネイティブpandasMultiIndexオブジェクトが返され、すべてのデータをクライアント側にプルする必要があります。すべてのpandas APIs がpandas on Snowflakeで分散実装されているわけではありませんが、いくつかは追加されています。サポートされていない APIs の場合は、
NotImplementedErrorがスローされます。サポートされる APIs については、 API のリファレンスドキュメントをご参照ください。pandas on Snowflakeはpandas 2.2のどのパッチバージョンとも互換性があります。
Snowpark pandasの
apply関数内でSnowpark pandasを参照することはできません。apply内では、ネイティブpandasしか使用できません。以下はその例です:
トラブルシューティング¶
このセクションでは、pandas on Snowflakeを使用する際のトラブルシューティングのヒントについて説明します。
トラブルシューティングの場合には、ネイティブpandas DataFrame(またはサンプル)で同じ操作を実行してみて、pandasで同じエラーが続くかどうかを確認してください。この方法により、クエリを修正するヒントが得られる場合があります。例:
長時間実行のノートブックを開いている場合、デフォルトでは、セッションが240分(4時間)アイドル状態になると、Snowflakeセッションがタイムアウトすることに注意してください。セッションの有効期限が切れると、pandas on Snowflakeのクエリを追加で実行した場合に以下のエラーが発生します。「Authentication token has expired.The user must authenticate again.」この時点で、Snowflakeへの接続を再確立する必要があります。これにより、未接続のセッション変数が失われる可能性があります。セッションアイドルタイムアウトパラメーターの構成方法の詳細については、 セッションポリシー をご参照ください。
ベストプラクティス¶
このセクションでは、pandas on Snowflakeを使用する際のベストプラクティスについて説明します。
forループ、iterrows、iteritemsなどの反復コードパターンの使用は避けてください。反復コードパターンにより、生成されるクエリの複雑さが急速に増大します。pandas on Snowflakeに、クライアントコードではなくデータ分散と計算の並列化を実行させます。反復コードパターンに関しては、 DataFrame 全体に対して実行できる操作を探し、それに対応する操作を代わりに使用するようにします。
apply、applymap、transformの呼び出しは避けます。これらは最終的に UDFs や UDTFs で実装されますが、通常の SQL クエリほどパフォーマンスが高くない可能性があります。適用された関数に同等の DataFrame または系列操作がある場合は、代わりにその操作を使用します。たとえば、df.groupby('col1').apply('sum')の代わりに、df.groupby('col1').sum()を直接呼び出します。サードパーティライブラリの呼び出しに DataFrame または series を渡す前に、
to_pandas()を呼び出します。pandas on Snowflake は、サードパーティライブラリとの互換性を保証していません。余計なI/Oオーバーヘッドを避けるために、具現化された通常のSnowflakeテーブルを使用します。pandas on Snowflakeは、通常のテーブルに対してのみ機能するデータスナップショットの上で動作します。外部テーブル、ビュー、 Apache Iceberg™ テーブルを含む他の型では、スナップショットを取得する前に仮テーブルが作成されます。そのため、追加の具現化オーバーヘッドが必要になります。
pandas on Snowflakeは、Snowflakeテーブルから DataFrames を使って
read_snowflakeを作成する際に、高速なゼロコピークローン機能を提供します。他の操作に進む前に結果の型を再度確認し、必要に応じて
astypeで明示的に型をキャストします。型推論機能が限られているため、型ヒントが与えられていない場合、
df.applyは、結果すべてに整数値が含まれていても、オブジェクト(バリアント)型の結果を返します。他の操作でdtypeをintにする必要がある場合は、astypeメソッドを呼び出して明示的に型をキャストし、列の型を修正してから処理を続行します。評価や具現化が必要でない場合は、 APIs の呼び出しを避けます。
SeriesやDataframeを返さない APIs には、正しい型で結果を得るために評価と具現化を実行する必要がありますプロットの方法も同じです。不要な評価や具現化を最小限に抑えるために、これらの APIs への呼び出しを減らします。大規模データセットでは、
np.where(<cond>, <scalar>, n)の呼び出しを避けます。<scalar>は、時間がかかる可能性のある<cond>のサイズの DataFrame にブロードキャストされます。反復的に構築されるクエリを扱う場合、
df.cache_resultは、中間結果を具現化することで、繰り返される評価を減らし、クエリ全体の待ち時間を改善し、複雑さを軽減することができます。例:上記の例では、
df2を生成するクエリは計算コストが高く、df3とdf4の両方の生成に再利用されます。df2を仮テーブルに具現化する(df2を含む後続操作をピボットではなくテーブルスキャンにする)と、コードブロック全体の遅延時間を短縮できます。
例¶
以下はpandas操作を使ったコード例です。まず、 pandas_test という名前のSnowpark pandas DataFrame から始めます。これには、 COL_STR、 COL_FLOAT、 そして COL_INT の3つの列があります。これらの例に関連するノートブックを表示するには、 Snowflake-Labsリポジトリ内の pandas on Snowflakeの例 をご参照ください。
例を通して使用する DataFrame を pandas_test という名前のSnowflakeテーブルとして保存します。
次に、Snowflakeテーブルから DataFrame を作成します。列 COL_INT をドロップし、結果を列名 row_position でSnowflakeに保存します。
その結果、 pandas_test2 という新しいテーブルができ、次のようになります。
IO (読み取りおよび書き込み)¶
詳細については、 入出力 をご参照ください。
インデックス作成¶
欠損値¶
型変換¶
2項演算¶
集計¶
マージ¶
グループ別¶
詳細については、 GroupBy をご参照ください。