異常検知(SnowflakeML関数)¶
概要¶
異常検出は、データ内の外れ値を識別するプロセスです。異常値検出関数により、時系列データの外れ値を検出するモデルをトレーニングすることができます。外れ値とは、予想される範囲から外れたデータポイントのことで、データから得られる統計やモデルに大きな影響を与える可能性があります。そのため、外れ値を見つけ、取り除くことは、結果の質を高めるのに役立ちます。
注釈
異常検知は、機械学習を利用したSnowflakeのビジネス分析ツールスイートの一部です。
外れ値の検出は、明らかな原因がない場合に、プロセスの問題や逸脱の原因を突き止めるのにも役立ちます。例:
ログパイプラインに問題が発生し始めた時を判断する。
Snowflakeのコンピューティングコストが予想より高い日を識別する。
異常検出は単一系列データでも複数系列データでも機能します。複数系列データは、イベントの複数の独立したスレッドを表します。たとえば、複数の店舗の販売データがある場合は、各店舗の売上を店舗識別子に基づいて1つのモデルで別々にチェックすることができます。
データには次が含まれている必要があります。
タイムスタンプ列。
各タイムスタンプで興味のある数量を表すターゲット値の列。
注釈
理想的には、異常検出モデルのトレーニングデータには、等間隔(たとえば、毎日)の時間ステップが含まれます。ただし、モデルのトレーニングでは、時間ステップが欠落するか、重複する、またはずれている実際のデータを処理できます。詳細については、 時系列予測における現実世界のデータの取り扱い をご参照ください。
時系列データの外れ値を検出するには、Snowflake組み込みクラス ANOMALY_DETECTION (SNOWFLAKE.ML) を使用し、次のステップに従います。
異常検出オブジェクトを作成 し、トレーニングデータへの参照を渡します。
このオブジェクトは、プロバイダーから提供された学習データにモデルを当てはめます。モデルはスキーマレベルのオブジェクトです。
この異常検出モデルオブジェクトを使用して、 <モデル名>!DETECT_ANOMALIES メソッドを呼び出し、分析するデータへの参照を渡して異常を検出します。
このメソッドは、モデルを使用してデータ内の外れ値を識別します。
異常検出は 予測 と密接に関連しています。異常検出モデルは、異常をチェックするデータと同じ期間の予測を作成し、実際のデータと予測を比較して外れ値を特定します。
異常検出のアルゴリズムについて¶
異常検出アルゴリズムは、 勾配ブースティングマシン (GBM)を使用しています。 ARIMA モデルのように、非定常トレンドを持つデータをモデリングするために差分変換を使用し、モデル変数として過去のターゲットデータの自己回帰ラグを使用します。
さらに、このアルゴリズムは、過去のターゲットデータの移動平均を使用してトレンドの予測を支援し、タイムスタンプデータから周期的なカレンダー変数(曜日や週番号など)を自動的に生成します。
過去のターゲット値とタイムスタンプのデータだけでモデルを適合させることも、ターゲット値に影響を与えた可能性のある外生データ(変数)を含めることもできます。外生変数は、数値またはカテゴリ別の値であり、 NULL (外生変数の NULLs を含む行はドロップされません)の場合もあります。
このアルゴリズムは、カテゴリ別変数でトレーニングする際にone-hotエンコーディングに依存しないため、ディメンション数の多い(カーディナリティの高い)カテゴリデータを使用することができます。
モデルに外生変数が組み込まれている場合は、異常を検出する際に将来のタイムスタンプでそれらの変数の値を提供する必要があります。適切な外生変数には、気象情報(気温、降雨量)、企業固有の情報(これまでの、および計画されている企業の休日、広告キャンペーン、イベントスケジュール)、またはターゲット変数の予測に役立つと思われるその他の外部要因などがあります。
オプションで、別個のブール列を使用して、個別の履歴行に異常または異常なしのラベルを付けることができます。
予測区間 とは、データのある割合が該当する可能性のある上限値と下限値内の推定値の範囲を表します。たとえば、0.99という値は、データの99%が区間内に出現する可能性が高いことを意味します。異常検出モデルは、予測区間から外れたデータを異常として識別します。予測間隔を指定するか、デフォルトの0.99を使用します。この値は、1.0、0.9999に非常に近いか、あるいはさらに近い値に設定することをお勧めします。
重要
Snowflakeは、異常検出アルゴリズムを改良することがあります。このような改善は、通常のSnowflakeリリースプロセスを通じて展開されます。以前のバージョンの特徴量に戻すことはできませんが、以前のバージョンで作成したモデルは、引き続きそのバージョンを異常検出に使用します。
制限事項¶
異常検出アルゴリズムを選択または調整することはできません。特に、アルゴリズムはトレンド、季節性、または季節振幅を上書きするパラメーターを提供しません。パラメーターはデータから推測されます。
主な異常検出アルゴリズムの最小行数は、時系列ごとに12です。観測データが2と11の間の時系列では、異常検出はすべての予測値が最後に観測されたターゲット値に等しい「ナイーブ」な結果を生成します。ラベル付き異常検出のケースでは、使用される観測データの数は、ラベル列がfalseである行の数です。
データの最小許容粒度は1秒です。(タイムスタンプの間隔は1秒以内でなければなりません。)
季節要因の最小粒度は1分です。(関数はより小さな時間差で周期的なパターンを検出することはできません。)
自己回帰的な特徴量の「シーズンの長さ」は、入力頻度に関連付けられています(1時間ごとのデータでは24、1日ごとのデータでは7など)。
異常検出モデルは、一度トレーニングすると不変です。新しいデータで既存のモデルを更新することはできず、まったく新しいモデルをトレーニングする必要があります。モデルはバージョニングをサポートしていません。一般的に、モデルが変化する傾向を常に把握できるように、新しいデータを受け取る頻度に応じて、1日に1回、週に1回、月に1回など、定期的にモデルを再トレーニングすることをお勧めします。
この機能はテストデータ内の異常のみを検出します。トレーニングデータ内の異常は検出できません。さらに、テストデータ内のタイムスタンプはすべて、トレーニングデータ内のタイムスタンプよりも大きくする必要があります。学習データが実際の外れ値のない典型的な期間をカバーしていることを確認するか、または既知の外れ値がブール列でラベル付けされていることを確認します。
モデルをクローンしたり、ロールやアカウント間でモデルを共有したりすることはできません。スキーマやデータベースをクローンする場合、モデルオブジェクトはスキップされます。
ANOMALY_DETECTION クラスのインスタンスを 複製 することはできません。
異常検出の準備¶
異常検出を使用する前に、以下が必要です。
モデルをトレーニングし、実行するための 仮想ウェアハウスを選択 します。
異常検出オブジェクトの作成権限を付与 します。
また、 SNOWFLAKE.ML を含めるように 検索パスを変更 する場合もあります。
仮想ウェアハウスの選択¶
Snowflake 仮想ウェアハウス は、この機能のために機械学習モデルをトレーニングして使用するためのコンピュートリソースを提供します。このセクションでは、トレーニングステップ(プロセスの中で最も時間とメモリを消費する部分)に焦点を当て、この目的に最適なウェアハウスのサイズと型を選択するための一般的なガイダンスを提供します。
単一系列データのトレーニング¶
単一系列データで学習したモデルの場合、トレーニングデータのサイズに基づいてウェアハウスタイプを選択する必要があります。標準ウェアハウスは、 Snowparkのメモリ制限 が低く、行数が少ないトレーニングジョブや外生的な特徴に適しています。トレーニングデータに外生的な特徴が含まれていない場合、データセットが500万行以下であれば、標準ウェアハウスでトレーニングできます。トレーニングデータに5個以上の外生的な特徴量を使用している場合、最大行数は少なくなります。それ以外の場合は、大規模なトレーニングジョブに対して Snowparkに最適化されたウェアハウス を使用することをSnowflakeは提案します。
一般的に、単一系列データの場合、ウェアハウスサイズが大きくなっても、トレーニング時間が短縮されたり、メモリ制限が高くなったりすることはありません。大まかな経験則として、トレーニング時間は時系列の行数に比例します。たとえば、 XS 標準ウェアハウスで、評価をオフ(CONFIG_OBJECT => {'evaluate': False})にした場合、100,000行のデータセットの学習には約60秒かかりますが、1,000,000行のデータセットの学習には約125秒かかります。評価をオンにすると、トレーニング時間は使用される分割数に応じてほぼ直線的に増加します。
最高のパフォーマンスを得るために、モデルのトレーニングには他のワークロードが同時に発生しない専用ウェアハウスを使用することをSnowflakeは推奨します。
複数系列データのトレーニング¶
単一系列のデータと同様に、最大の時系列の行数に基づいてウェアハウスタイプを選択します。最大の時系列が500万行を超える場合、トレーニングジョブは標準ウェアハウスのメモリ制限を超える可能性があります。
単一系列のデータとは異なり、複数系列のデータは、ウェアハウスサイズが大きくなるとかなり高速にトレーニングされます。選択する際は、以下のデータポイントを手引きとしてください。繰り返しますが、これらの時間はすべて評価をオフにした状態で行っています。
ウェアハウスのタイプとサイズ |
時系列の数 |
時系列ごとの行数 |
トレーニング時間(秒) |
|---|---|---|---|
標準 XS |
1 |
100,000 |
60秒 |
標準 XS |
10 |
100,000 |
204秒 |
標準 XS |
100 |
100,000 |
720秒 |
標準 XL |
10 |
100,000 |
104秒 |
標準 XL |
100 |
100,000 |
211秒 |
標準 XL |
1000 |
100,000 |
840秒 |
Snowpark用に最適化された XL |
10 |
100,000 |
65秒 |
Snowpark用に最適化された XL |
100 |
100,000 |
293秒 |
Snowpark用に最適化された XL |
1000 |
100,000 |
831秒 |
異常の検出¶
推論ステップでは、ウェアハウスのサイズに関係なく、入力データセットの100行の処理に約1秒かかります。
異常検出オブジェクトの作成権限の付与¶
異常検出モデルをトレーニングすると、スキーマレベルのオブジェクトが生成されます。したがって、モデルの作成に使用するロールには、モデルが作成されるスキーマ上で CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 権限があり、そこにモデルを格納できるようにする必要があります。この権限は CREATE TABLE や CREATE VIEW のような他のスキーマ権限と類似しています。
Snowflakeは、 analyst という名前のロールを作成し、異常検出を実行する必要のある人が使用できるようにすることをお勧めします。
以下の例では、 admin ロールがスキーマ admin_db.admin_schema の所有者です。 analyst ロールにより、このスキーマでモデルを作成する必要があります。
このスキーマを使用するには、ユーザーは analyst ロールを引き受けます。
analyst ロールがデータベース analyst_db の CREATE SCHEMA 権限を持っている場合、そのロールは新しいスキーマ analyst_db.analyst_schema を作成し、そのスキーマに異常検出モデルを作成することができます。
スキーマに対するロールのモデル作成権限を取り消すには、 REVOKE <権限> ... FROM ROLE を使用します。
例に対するデータの設定¶
次のセクションの例では、異なる店舗にある商品の日次売上と、毎日の天候データ(湿度と気温)を含むサンプルデータセットを使用します。データセットには、その日が休日かどうかを示す列も含まれています。
以下のステートメントを実行して、モデルの学習データを格納する
historical_sales_dataという名前のテーブルを作成します。
以下のステートメントを実行して、分析するデータを含む
new_sales_dataという名前のテーブルを作成します。
モデルのトレーニング、使用、表示、削除、更新¶
CREATE SNOWFLAKE.ML.ANOMALY_DETECTION を使用してモデルを作成し、トレーニングします。モデルは提供されたデータセットでトレーニングされます。
SNOWFLAKE.ML.ANOMALY_DETECTION コンストラクターの包括的な詳細については、 ANOMALY_DETECTION (SNOWFLAKE.ML) をご参照ください。モデルの作成例については、 異常の検出 をご参照ください。
注釈
SNOWFLAKE.ML.ANOMALY_DETECTION は制限された権限で実行されるため、デフォルトではご使用のデータにアクセスできません。そのため、テーブルとビューを 参照 として渡す必要があります。参照は、呼び出し元の権限も一緒に渡します。テーブルやビューへの参照ではなく、 クエリ参照 を提供することもできます。
この参照を作成するには、 TABLE キーワード をテーブル名、ビュー名、クエリと共に使用するか、 SYSTEM$REFERENCE または SYSTEM$QUERY_REFERENCE 関数を呼び出します。
異常を検出するには、モデルの <モデル名>!DETECT_ANOMALIES メソッドを呼び出します。
メソッドの表形式出力から列を選択するには、 FROM句 でメソッドを呼び出します。
モデルのリストを表示するには、 SHOW SNOWFLAKE.ML.ANOMALY_DETECTION コマンドを使用します。
モデルを削除するには、 DROP SNOWFLAKE.ML.ANOMALY_DETECTION コマンドを使用します。
モデルを更新するには、モデルを削除して新しいモデルをトレーニングします。モデルは不変であり、導入状態で更新することはできません。
異常の検出¶
次のセクションでは、異常検出を使用して外れ値を検出する方法を示します。これらのセクションでは、単一時系列、複数時系列、外生変数の有無、ユーザー定義の予測区間、および教師あり(ラベル付き)アプローチによる異常の検出例を示します。
単一時系列の異常検出(教師なし)¶
データの異常を検出するには、
過去のデータを使用して異常検出モデルをトレーニングします。
トレーニング済みの異常検出モデルを使用して、過去のデータまたは予測データの異常を検出します。テストデータのタイムスタンプは、トレーニングデータのタイムスタンプに時系列で追随している必要があります。モデルをトレーニングするには少なくとも2個のデータポイントが必要で、非ネイティブな結果には少なくとも12個のデータポイント、非線形結果を得るには少なくとも60個のデータポイントが必要です。
モデルの作成時および使用時に使用するパラメーターについては、 ANOMALY_DETECTION (SNOWFLAKE.ML) をご参照ください。
異常検出モデルのトレーニング¶
異常検知モデルオブジェクトを作成するには、 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION コマンドを実行します。
たとえば、 store_id が1の店舗でジャケットの売上を分析するとします。
異常検出モデルをトレーニングするためのデータを返すビューを作成するか、クエリを設計します。
この例では、 CREATE VIEW コマンドを実行して、日付と売上情報を含む
view_with_training_dataという名前のビューを作成します。異常検出オブジェクトを作成し、そのモデルをそのビュー内のデータでトレーニングします。
この例では、 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION コマンドを実行して、
basic_modelという名前の異常検出オブジェクトを作成します。以下の引数を渡します。この例では、INPUT_DATA引数としてビューへの参照を渡しています。例 では、 TABLEキーワードを使用して、参照 を作成しています。別の方法として、 SYSTEM$REFERENCE を呼び出して参照を作成することもできます。
ラベル列の目的は、どの行が既知の異常であるかをモデルに伝えることです。この例では教師なしのトレーニングを使用しているため、ラベル列を使用する必要はありません。ラベル列の名前として空の文字列を渡します。
Tip
INPUT_DATA 引数に対するビューを作成しない場合、インラインビューとして機能する SELECT ステートメントを使用する クエリへの参照 で渡すことができます。
このクエリ参照を作成するには、TABLEキーワードを使用します。例:
一重引用符やその他の特殊文字はバックスラッシュでエスケープします。
TABLE キーワードを使用する代わりに、 SYSTEM$QUERY_REFERENCE を呼び出してクエリ参照を作成できます。
コマンドの実行に成功すると、異常検出インスタンスが正常に作成されたことを示すメッセージが表示されます。
異常を検出するための異常検出モデルの使用¶
異常検知オブジェクトを作成すると、モデルがトレーニングされ、スキーマに格納されます。異常検出オブジェクトを使用して異常を検知するには、オブジェクトの <モデル名>!DETECT_ANOMALIES メソッドを呼び出します。例:
分析用のデータを返すビューを作成するか、クエリを設計します。
この例では、 CREATE VIEW コマンドを実行して、日付と売上情報を含む
view_with_data_to_analyzeという名前のビューを作成します。異常検出モデルのオブジェクト(この例では、 先に作成した
basic_model)を使用して、 <モデル名>!DETECT_ANOMALIES メソッドを呼び出します。このメソッドは、現在ビュー
view_with_data_to_analyzeにあるデータの行を含むテーブルを検出器の予測値と合わせて返します。このテーブルの列の説明については、 戻り値 をご参照ください。
出力
結果は読みやすくするために丸めてあります。
結果を直接テーブルに保存するには、 CREATE TABLE ... AS SELECT ... を使用して、 FROM 句で DETECT_ANOMALIES メソッドを呼び出します。
上述の例のように、メソッドを呼び出すときは CALL コマンドを省略します。代わりに、 TABLE キーワードを前に付けて、呼び出しを括弧で囲みます。
ラベル付きデータによる異常検出モデルのトレーニング¶
先ほどの例では、モデルの結果が不正確に見えます。それは次の理由によると考えられます。
異常検出モデルは、わずかな入力データでトレーニングされた。
2020年1月3日に、多数のジャケット(30着)が販売された。このため予測値が上方に歪み、予測区間が拡大しました。
異常検出モデルの精度を向上させるには、より多くのトレーニングデータを含めるか、トレーニングデータにラベルを付ける(教師ありトレーニング)ことができます。ラベル付きトレーニングデータには、各行に既知の異常があるかどうかを示すブール列が追加されています。ラベル付けは、異常検出モデルがトレーニングデータ内の既知の異常に過剰適合することを回避するのに役立ちます。
ラベル付きデータをトレーニングデータに含めるには、 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION コマンドの LABEL_COLNAME コンストラクター引数にラベルを含む列を指定します。例:
ラベルとトレーニングデータを返すビューを作成するか、クエリを設計します。
この例では、 CREATE VIEW コマンドを実行して、
labelという名前の列にあるラベルを含むview_with_labeled_dataという名前のビューを作成します。異常検出モデル用のオブジェクトを作成し、そのビューのデータでモデルをトレーニングします。
この例では、 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION コマンドを実行して、
model_trained_with_labeled_dataという名前の異常検出オブジェクトを作成します。次のステートメントは、異常検出オブジェクトを作成します。この新しい異常検出モデルを使用し、 単一時系列の異常検出(教師なし) で使用したのと同じ引数を渡して、 <モデル名>!DETECT_ANOMALIES メソッドを呼び出します。
このメソッドは、現在ビュー
view_with_data_to_analyzeにあるデータの行を含むテーブルを検出器の予測値と合わせて返します。このテーブルの列の説明については、 戻り値 をご参照ください。
出力
結果は読みやすくするために丸めてあります。
異常検出向け予測間隔の指定¶
さまざまな感度で異常を検出できます。異常として分類するオブザベーションの割合を指定するには、 <モデル名>!DETECT_ANOMALIES の構成設定を含む OBJECT を作成し、 prediction_interval キーに、異常としてマークするオブザベーションの割合を設定します。
このオブジェクトを構築するには、 オブジェクト定数 または OBJECT_CONSTRUCT 関数を使用します。
そして、 <モデル名>!DETECT_ANOMALIES メソッドを呼び出す際に、 CONFIG_OBJECT 引数としてこのオブジェクトを渡します。
デフォルトでは、prediction_intervalキーに関連する値は0.99に設定されており、これはデータのおよそ1%が異常としてマークされることを意味します。0~1の間で指定できます。
より少ないオブザベーションを異常としてマークするには、
prediction_intervalに高い値を指定します。より多くのオブザベーションを異常としてマークするには、
prediction_intervalの値を小さくします。
次の例では、 prediction_interval を0.995に設定することで、異常検出をより厳密に設定します。この例では、ラベル付きデータ(ラベル付きデータによる異常検出モデルのトレーニング で設定)でトレーニングしたモデルを、分析対象のデータ(単一時系列の異常検出(教師なし) で設定)を含むビューで使用しています。
このステートメントは、現在ビュー view_with_data_to_analyze にあるデータの行を含むテーブルを生成します。各行には、検出器の予測値を示す列があります。このモデルの結果は、ラベルのない例よりも正確であることがわかります。
出力
結果は読みやすくするために丸めてあります。
分析向け追加列の含め¶
これらの列が真の異常の識別を向上させるのに役立つ場合は、トレーニングおよび分析用のデータに追加の列(例: temperature、 weather、 is_black_friday)を含めることができます。
分析に新しい列を含めるには、
トレーニングデータに対して、新しい列を含むビューまたはクエリを作成し、そのビューまたはクエリへの参照を渡して新しい異常検出オブジェクトを作成します。
分析するデータについては、新しい列を含むビューを作成するかクエリを作成し、そのビューまたはクエリへの参照を <モデル名>!DETECT_ANOMALIES メソッドに渡します。
異常検出モデルは、追加列を自動的に検出して使用します。
注釈
CREATE SNOWFLAKE.ML.ANOMALY_DETECTION コマンドを実行するときと、 <モデル名>!DETECT_ANOMALIES メソッドを呼び出すときに、同じ追加列のセットをビューまたはクエリに提供する必要があります。コマンドに渡されたトレーニングデータの列と、関数に渡された分析用データの列が不一致の場合は、エラーが発生します。
たとえば、 temperature、 humidity、 holiday の列を追加するとします。
これらの列を追加したトレーニングデータを返すビューを作成するかクエリを設計します。
この例では、 CREATE VIEW コマンドを実行して、
view_with_training_data_extra_columnsという名前のビューを作成します。異常検出モデル用のオブジェクトを作成し、そのビューのデータでモデルをトレーニングします。
この例では、 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION コマンドを実行して、
model_with_additional_columnsという名前の異常検出オブジェクトを作成し、新しいビューへの参照を渡します。これらの追加列を使用して分析するデータを返すビューを作成するかクエリを設計します。
この例では、 CREATE VIEW コマンドを実行して、
view_with_data_for_analysis_extra_columnsという名前のビューを作成します。この新しい異常検出オブジェクトを使用して、 <モデル名>!DETECT_ANOMALIES メソッドを呼び出し、新しいビューを渡します。
このステートメントは、現在ビュー
view_with_data_for_analysis_extra_columnsにあるデータの行を含むテーブルを検出器の予測値と合わせて作成します。出力の形式は、先に実行したコマンドで表示された出力の形式と同じです。
出力
結果は読みやすくするために丸めてあります。
複数系列における異常の検出¶
前のセクションでは、単一系列の異常を検出する例を提供しました。これらの例では、1つの店舗(店舗 ID 1)で1つの種類のアイテム(ジャケット)の販売が異常であるとしてフラグが立てられました。同時に複数系列(例: 複数の商品と店舗の組み合わせ)の異常を検出するには、
トレーニングデータについて、系列を識別する列を含むビューを作成するかクエリを設計し、新しい異常検出オブジェクトを作成して、そのビューまたはクエリへの参照を渡して、 SERIES_COLNAME 引数のために系列の列名を指定します。
分析するデータのために、系列を識別する列を含むビューを作成するかクエリを設計します。 <モデル名>!DETECT_ANOMALIES メソッドを呼び出し、そのビューまたはクエリへの参照を渡して、 SERIES_COLNAME 引数のために系列の列名を指定します。
たとえば、 store_id と item の列の組み合わせを使用して系列を識別するとします。
系列のために列のあるトレーニングデータを返すビューを作成するかクエリを設計します。
この例では、 CREATE VIEW コマンドを実行して、
view_with_training_data_multiple_seriesという名前のビューを作成します。このビューには、store_itemという名前の列があり、この列は、 ID と商品の組み合わせとして系列を識別します。異常検出用のオブジェクトを作成し、そのビューのデータでモデルをトレーニングします。
この例では、 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION コマンドを実行して、
model_for_multiple_seriesという名前の異常検出オブジェクトを作成し、新しいビューへの参照を渡して、store_item引数の SERIES_COLNAME を指定します。系列の列で分析するデータを返すビューを作成するかクエリを設計します。
この例では、 CREATE VIEW コマンドを実行して、系列の
store_itemという名前の列を含むview_with_data_for_analysis_multiple_seriesという名前のビューを作成します。この新しい異常検出オブジェクトを使用して、 <モデル名>!DETECT_ANOMALIES メソッドを呼び出し、新しいビューを渡して、 SERIES_COLNAME 引数に
store_itemを指定します。このステートメントは、現在ビュー
view_with_data_for_analysis_multiple_seriesにあるデータの行を含むテーブルを検出器の予測値と合わせて作成します。出力には系列を識別する列が含まれます。
出力
結果は読みやすくするために丸めてあります。
異常の視覚化と結果の解釈¶
Snowsight を使用して、異常検出の結果を確認し、視覚化します。 Snowsight では、 <モデル名>!DETECT_ANOMALIES メソッドを呼び出すと、結果がワークシートの下のテーブルに表示されます。

結果を視覚化するには、 Snowsight のチャート機能を使用することができます。
<モデル名>!DETECT_ANOMALIES メソッドを呼び出した後、クエリの結果テーブルで Charts を選択します。
チャート右側の Data で、
Y 列を選択し、 Aggregation で None を選択します。
TS 列を選択し、 Bucketing で None を選択します。
LOWER_BOUND と UPPER_BOUND 列を追加し、 Aggregation で None を選択します。
初期の視覚化を表示するには、 Chart を選択します。

ページの右側で Add Column を選択し、視覚化する列を選択します。
LOWER_BOUND
UPPER_BOUND
IS_ANOMALY
結果:
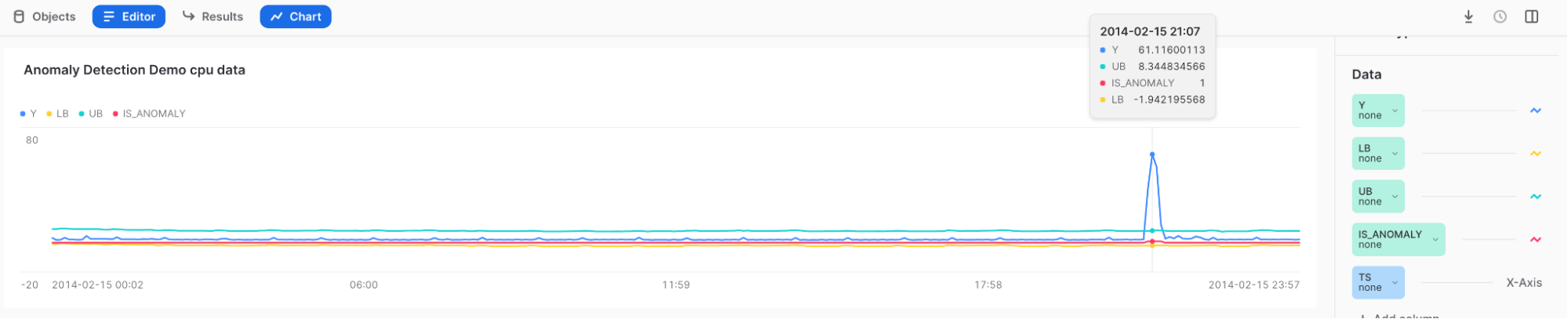
高いスパイクにカーソルを合わせると、Yが上限の外側にあり、 IS_ANOMALY のフィールドに1がタグ付けされていることがわかります。
Tip
結果をよりよく理解するには、 Top Insights をお試しください。
Snowflakeタスクおよびアラートによる異常検出の自動化¶
モデルの再トレーニングとデータ異常のモニタリング両方のために、Snowflakeタスクまたはアラート内で異常検出関数を使用して、自動化された異常検出パイプラインを作成できます。
Snowflakeタスクを使用した反復トレーニング¶
Snowflakeタスク を使用して、最新のデータを反映するようにモデルを更新できます。
異常検出オブジェクトを1時間ごとにリフレッシュするタスクを作成するには、 your_warehouse_name をウェアハウス名に置き換えて、以下のステートメントを実行します。
デフォルトでは、新しく作成されたタスクは中断されます。
タスクを再開するには、 ALTER TASK ... RESUME コマンドを実行します。
タスクを一時停止するには、 ALTER TASK ... SUSPEND コマンドを実行します。
Snowflakeタスクを使用したモニタリング¶
Snowflakeタスクを使用して、指定された頻度でデータをモニターすることもできます。
まず、異常検出の結果を保持するテーブルを作成します。
定期的な異常検出操作の結果をテーブルに格納するタスクを作成します。この例では WAREHOUSE パラメーターを snowhouse に設定しています。それを自分のウェアハウスに置き換えることができます。
タスクを再開するには、 ALTER TASK ... RESUME コマンドを実行します。
anomaly_res_table には各タスクの実行結果がすべて含まれます。
タスクを一時停止するには、 ALTER TASK ... SUSPEND コマンドを実行します。
Snowflakeアラートを使用したモニタリング¶
Snowflakeアラート を使用して、指定された頻度でデータをモニターし、検出された異常をメールで送信することもできます。次のステートメントは、1分ごとに異常を検出するアラートを作成します。まず、 ストアドプロシージャ を定義して異常を検出し、次にそのストアドプロシージャを使用するアラートを作成します。
注釈
ストアドプロシージャからメールを送信するには、メール統合を設定する必要があります。 Snowflakeでの通知 をご参照ください。
アラートを開始または再開するには、 ALTER ALERT ... RESUME コマンドを実行します。
アラートを一時停止するには、 ALTER ALERT ... SUSPEND コマンドを実行します。
特徴量の重要性について¶
異常検出モデルは、選択した外生変数や自動生成時間特徴量(曜日や週番号など)、ターゲット変数の変換(移動平均や自己回帰ラグなど)など、モデルで使用されるすべての特徴量の相対的な重要性を説明することができます。この情報は、データに実際に影響を与えている要因を理解するのに役立ちます。
<モデル名>!EXPLAIN_FEATURE_IMPORTANCE メソッドは、モデルのツリーが各特徴量を使用して決定した回数をカウントします。それから、これらの特徴量の重要度スコアは、合計が1になるように0から1の間の値に正規化されます。結果として得られるスコアは、トレーニング済みモデルの特徴量の近似ランキングを表します。
スコアが近い特徴量は同じような重要性を持ちます。極端に単純な系列(たとえば、対象列の値が一定の場合)では、すべての特徴量の重要度スコアが0になる可能性があります。
互いによく似た複数の特徴量を使用すると、それらの特徴量の重要度スコアが低下する可能性があります。たとえば、ある特徴量が 販売個数 であり、別の特徴量が 在庫個数 である場合、その値は相関している可能性があります。なぜなら、在庫個数よりも多く販売することはできず、在庫個数は販売個数よりも多くならないように在庫を管理しようとするからです。2つの特徴量が同じである場合、モデルは決定を下す際にそれらを交換可能なものとして扱い、その結果、同じ特徴量のうちの1つだけが含まれていた場合には、特徴量の重要度スコアは本来のスコアの半分になる可能性があります。
特徴量の重要度は、 ラグ特徴量 も報告します。トレーニング中、モデルはトレーニングデータの頻度(毎時、毎日、毎週)を推測します。特徴量 lagx (例: lag24)は、ターゲット変数 x 単位時間前の値です。たとえば、データが1時間ごとと推測される場合、 lag24 は24時間前のターゲット変数を表します。
ターゲット変数の他のすべての変換(移動平均など)は、結果テーブルの aggregated_endogenous_features として要約されます。
制限事項¶
特徴量の重要度を計算する手法は選択できません。
特徴量の重要度スコアは、どの特徴量がモデルの精度にとって重要かを直感的に理解するのに役立ちますが、実際の値は推測として考慮される必要があります。
例¶
モデルに対する特徴量の相対的な重要性を理解するには、モデルをトレーニングしてから、 <モデル名>!EXPLAIN_FEATURE_IMPORTANCE を呼び出します。この例では、まず2つの外生変数を持つランダムデータを作成します。1つはランダムであるためモデルにとって重要性が低くなると考えられ、もう1つはターゲットのコピーであるためモデルにとって重要性が高くなると考えられます。
以下のステートメントを実行すると、データが生成され、モデルがトレーニングされ、特徴量の重要度が取得されます。
出力
この例ではランダムなデータを使用しているため、出力がこれと正確に一致するとは限りません。
トレーニングログの検査¶
複数の系列を CONFIG_OBJECT => 'ON_ERROR': 'SKIP' でトレーニングする場合、トレーニングプロセス全体が失敗しなくても、個々の時系列モデルがトレーニングに失敗することがあります。どの時系列がなぜ失敗したかを把握するには、 <model_instance>!SHOW_TRAINING_LOGS を呼び出します。
例¶
出力
コストの考慮事項¶
ML 関数の使用コストの詳細については、 ML 関数の概要の コストの考慮事項 を参照してください。