Vektoreinbettungen¶
Eine Einbettung bezieht sich auf die Reduzierung von hochdimensionalen Daten, wie z. B. unstrukturiertem Text, auf eine Darstellung mit weniger Dimensionen, wie z. B. einen Vektor. Moderne Deep-Learning-Techniken können aus unstrukturierten Daten wie Text und Bildern Vektoreinbettungen, d. h. strukturierte numerische Darstellungen, erstellen und dabei semantische Begriffe wie Ähnlichkeit und Unähnlichkeit in der Geometrie der erzeugten Vektoren beibehalten.
Die folgende Abbildung ist ein vereinfachtes Beispiel für die Vektoreinbettung und geometrische Ähnlichkeit von Text in natürlicher Sprache. In der Praxis erzeugen neuronale Netze Einbettungsvektoren mit Hunderten oder sogar Tausenden von Dimensionen, nicht wie hier gezeigt zwei, aber das Konzept ist dasselbe. Semantisch ähnlicher Text ergibt Vektoren, die in dieselbe allgemeine Richtung „weisen“.
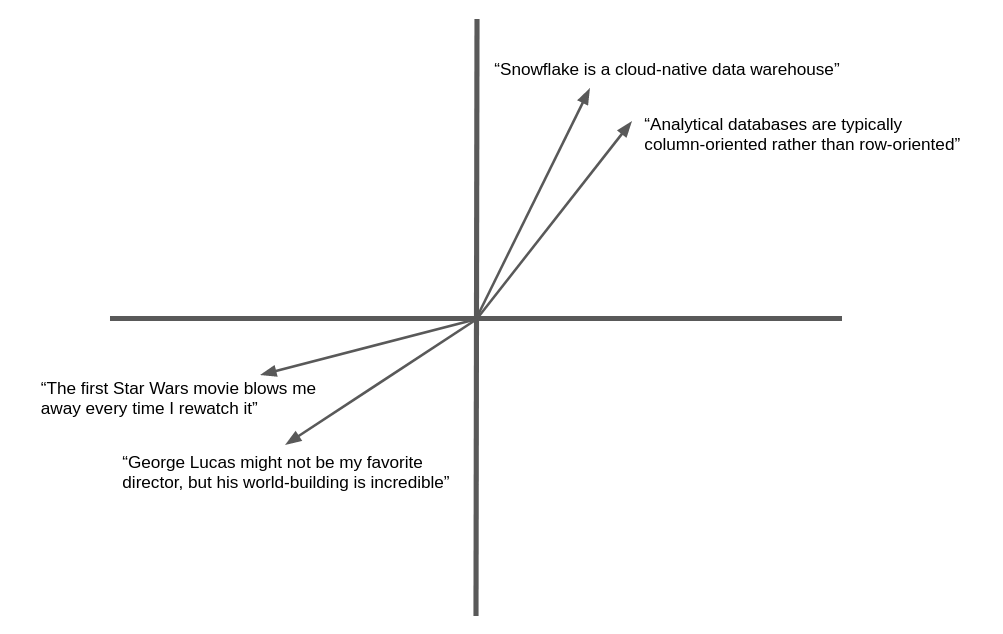
Viele Anwendungen können von der Fähigkeit profitieren, Text oder Bilder zu finden, die einem Ziel ähnlich sind. Wenn beispielsweise ein neuer Support-Fall bei einem Helpdesk angemeldet wird, kann das Support-Team von der Möglichkeit profitieren, ähnliche Fälle zu finden, die bereits gelöst wurden. Der Vorteil der Verwendung von Einbettungsvektoren in dieser Anwendung ist, dass sie über das Abgleichen von Schlüsselwörtern hinausgeht und eine semantische Ähnlichkeit herstellt, sodass verwandte Datensätze auch dann gefunden werden können, wenn sie nicht genau dieselben Wörter enthalten.
Snowflake Cortex bietet die Funktionen EMBED_TEXT_768 und EMBED_TEXT_1024 sowie mehrere Vektorfunktionen zum Vergleich für verschiedene Anwendungen.
Modelle zur Texteinbettung¶
Snowflake bietet die folgenden Modelle zur Texteinbettung. Weitere Details dazu finden Sie unten.
Modellbezeichnung |
Abmessungen der Ausgabe |
Kontextfenster |
Unterstützung von Sprachen |
|---|---|---|---|
snowflake-arctic-embed-m-v1.5 |
768 |
512 |
Nur auf Englisch |
snowflake-arctic-embed-m |
768 |
512 |
Nur auf Englisch |
e5-base-v2 |
768 |
512 |
Nur auf Englisch |
snowflake-arctic-embed-l-v2.0 |
1024 |
512 |
Mehrsprachig |
voyage-multilingual-2 |
1024 |
32000 |
Mehrsprachig (unterstützte Sprachen) |
nv-embed-qa-4 |
1024 |
512 |
Nur auf Englisch |
Unterstützte Modelle können unterschiedliche Kosten haben.
Allgemeine Informationen zu Vektorähnlichkeitsfunktionen¶
Die Messung der Ähnlichkeit zwischen Vektoren ist eine grundlegende Operation beim semantischen Vergleich. Snowflake Cortex bietet vier Vektorähnlichkeitsfunktionen: VECTOR_INNER_PRODUCT, VECTOR_L1_distance, VECTOR_L2_DISTANCE und VECTOR_COSINE_SIMILARITY. Weitere Informationen zu diesen Funktionen finden Sie unter Vektorfunktionen.
Einzelheiten zur Syntax und Verwendung finden Sie auf der Referenzseite zu jeder Funktion:
Beispiele¶
Die folgenden Beispiele verwenden die Vektorähnlichkeitsfunktionen.
Das folgende SQL-Beispiel verwendet die Funktion VECTOR_INNER_PRODUCT, um zu ermitteln, welche Vektoren in der Tabelle zwischen den Spalten a und b am nächsten beieinander liegen:
Das folgende SQL-Beispiel ruft die Funktion VECTOR_COSINE_SIMILARITY auf, um den Vektor zu finden, der [1,2,3] am nächsten kommt:
Snowflake Connector für Python¶
Die folgenden Beispiele zeigen, wie Sie den Datentyp VECTOR und die Vektorähnlichkeitsfunktionen mit dem Python-Konnektor verwenden können.
Bemerkung
Die Unterstützung für den Typ VECTOR wurde in Version 3.6 des Snowflake Connectors für Python eingeführt.
Snowpark Python¶
Die folgenden Beispiele zeigen, wie Sie den Datentyp VECTOR und die Vektorähnlichkeitsfunktionen mit der Snowpark Python Library verwenden können.
Bemerkung
Die Unterstützung für den Typ VECTOR wurde in Version 1.11 von Snowpark Python eingeführt.
Die Snowpark Python-Bibliothek unterstützt die Funktion VECTOR_COSINE_SIMILARITY nicht.
Vektoreinbettungen aus Text erstellen¶
Um eine Vektoreinbettung aus einem Textstück zu erstellen, können Sie die Funktionen EMBED_TEXT_768 (SNOWFLAKE.CORTEX) oder EMBED_TEXT_1024 (SNOWFLAKE.CORTEX) verwenden, je nach den Ausgabedimensionen des Modells. Diese Funktionen geben die Vektoreinbettung für einen gegebenen englischsprachigen Text zurück. Dieser Vektor kann mit den Vektorvergleichsfunktionen verwendet werden, um die semantische Ähnlichkeit zweier Dokumente zu ermitteln.
Tipp
Sie können andere Einbettungsmodelle über Snowpark Container Services verwenden. Weitere Informationen dazu finden Sie unter Embed Text Container Service.
Wichtig
EMBED_TEXT_768 und EMBED_TEXT_1024 sind Cortex LLM-Funktionen, daher unterliegt ihre Verwendung derselben Zugriffssteuerung wie die anderen Cortex LLM-Funktionen. Eine Anleitung zum Zugriff auf diese Funktionen finden Sie unter Erforderliche Berechtigungen für Cortex LLM-Funktionen.
Beispielhafte Anwendungsfälle¶
Dieser Abschnitt zeigt, wie Sie Einbettungen, die Vektorähnlichkeitsfunktionen und den Datentyp VECTOR verwenden, um beliebte Anwendungsfälle wie Vektorähnlichkeitssuche und Retrieval-Augmented Generation (RAG) zu implementieren.
Vektorähnlichkeitssuche¶
Um eine Suche nach semantisch ähnlichen Dokumenten zu implementieren, speichern Sie zunächst die Einbettungen für die zu durchsuchenden Dokumente. Halten Sie die Einbettungen auf dem neuesten Stand, wenn Dokumente hinzugefügt oder bearbeitet werden.
In diesem Beispiel handelt es sich bei den Dokumenten um Call-Center-Probleme, die von Support-Mitarbeitern protokolliert wurden. Die Ausgabe wird in einer Spalte namens issue_text der Tabelle issues gespeichert. Der folgende SQL-Code erstellt eine neue Vektorspalte, die die Einbettungen der Probleme enthält.
Um eine Suche durchzuführen, erstellen Sie eine Einbettung des Suchbegriffs oder des Zieldokuments und verwenden dann eine Vektorähnlichkeitsfunktion, um Dokumente mit ähnlichen Einbettungen zu finden. Verwenden Sie die Klauseln ORDER BY und LIMIT, um die k besten übereinstimmenden Dokumente auszuwählen, und verwenden Sie optional eine WHERE-Bedingung, um eine Mindestähnlichkeit anzugeben.
Im Allgemeinen sollte der Aufruf der Vektorähnlichkeitsfunktion in der SELECT-Klausel erfolgen, nicht in der WHERE-Klausel. Auf diese Weise wird die Funktion nur für die Zeilen aufgerufen, die in der WHERE-Klausel angegeben sind, die die Abfrage auf der Grundlage anderer Kriterien einschränken kann, anstatt über alle Zeilen der Tabelle zu operieren. Um einen Ähnlichkeitswert in der WHERE-Klausel zu testen, definieren Sie einen Spaltenalias für den VECTOR_COSINE_SIMILARITY-Aufruf in der SELECT-Klausel und verwenden diesen Alias in einer Bedingung in der WHERE-Klausel.
Dieses Beispiel findet bis zu fünf Ausgaben aus den letzten 90 Tagen, die dem Suchbegriff entsprechen, vorausgesetzt, die Cosinus-Ähnlichkeit mit dem Suchbegriff beträgt mindestens 0,7.
Retrieval-Augmented Generation (RAG)¶
Bei der Retrieval-Augmented Generation (RAG) wird die Abfrage eines Benutzers verwendet, um mithilfe der Vektorähnlichkeit ähnliche Dokumente zu finden. Das oberste/beste Dokument wird dann zusammen mit der Abfrage des Benutzers an ein großes Sprachmodell (LLM) weitergeleitet, das den Kontext für die generative Antwort (Completion) liefert. Dies kann die Brauchbarkeit der Antwort erheblich verbessern.
Im folgenden Beispiel ist wiki eine Tabelle mit einer Textspalte content und query ist eine einzeilige Tabelle mit einer Textspalte text.
Hinweise zu Kosten¶
Snowflake Cortex-LLM-Funktionen, einschließlich EMBED_TEXT_768 und EMBED_TEXT_1024, verursachen Computekosten, die sich nach der Anzahl der verarbeiteten Token richten.
Bemerkung
Ein Token ist die kleinste Texteinheit, die von den Snowflake Cortex-LLM-Funktionen verarbeitet wird, und entspricht etwa vier Textzeichen. Das Verhältnis des ein-/ausgegebene Rohtextes zur Tokenanzahl kann je nach Modell variieren.
Bei den Funktionen EMBED_TEXT_768 und EMBED_TEXT_1024 werden nur die eingegebenen Token auf die abrechenbare Summe angerechnet.
Vektorähnlichkeitsfunktionen verursachen keine tokenbasierten Kosten.
Weitere Informationen zur Abrechnung von Cortex LLM-Funktionen finden Sie unter Kostenbetrachtungen für Cortex LLM-Funktionen. Allgemeine Informationen über Rechenkosten finden Sie unter Erläuterungen zu den Computekosten.