Snowpark Migration Accelerator: 도구 실행하기¶
이제 Snowpark Migration Accelerator(SMA)를 설치하고 코드베이스를 준비했으므로 실행 프로세스를 시작할 수 있습니다. 애플리케이션이 아직 열려 있으면 SMA 애플리케이션으로 돌아가거나, 닫은 경우에는 실행합니다.
프로젝트 설정¶
When you first open the SMA, the project page is shown.

메뉴에서 ‘새 프로젝트’를 선택하여 시작합니다. 이 연습을 위해 이미 프로젝트를 생성한 경우에는 대신’프로젝트 열기’를 선택하여 액세스할 수 있습니다.
The “Project Creation” page allows you to create a new project file, which is essential for both assessment and code conversion tasks in SMA. The project file (with a .snowct extension) is stored in your selected output directory and keeps track of all your SMA executions. If you want to link multiple executions together, you can reopen an existing project file. All project information is saved both on your local machine and in the shared database. For more details about projects, see the “project” file.
All fields shown are required for configuring the assessment tool and managing the project after running the analysis.

Project name: This is the name for your project file. Multiple executions can be connected to a single project as well as any settings you save. You can learn more about the project file below.
Email address: This email address identifies the user of the tool. This should be the user of the tool, not the owner of the codebase being scanned.
Company name: This is to help you specify the organization’s code you are working with. If you are running your own code, then put your own organization here. If you are working with another organization, then put that organization name here.
Input folder: Specify the directory where your source codebase is located.
Output folder: The directory where the output files (logs, reports, code) will be placed.
For this walkthrough, we will use the “Spark Data Engineering Examples” codebase. You can find it in the sample codebases section. Follow these steps:
코드베이스 다운로드 및 압축 해제
모든 파일이 들어있는 루트 디렉터리를 찾습니다. 이 디렉터리가 입력 디렉터리가 됩니다
원하는 프로젝트 이름을 선택합니다.
출력 디렉터리를 선택합니다(도구에서 기본 위치를 제안하지만 필요에 따라 변경할 수 있습니다)
Before starting the assessment, make sure your input directory contains the correct source code files with the proper file extensions, as explained in the code preparation section.
When you are ready to begin, click Save to save your project.
After you save, the SMA takes you to the project home page. Select the Code Process tile to start the guided assessment or conversion workflow:
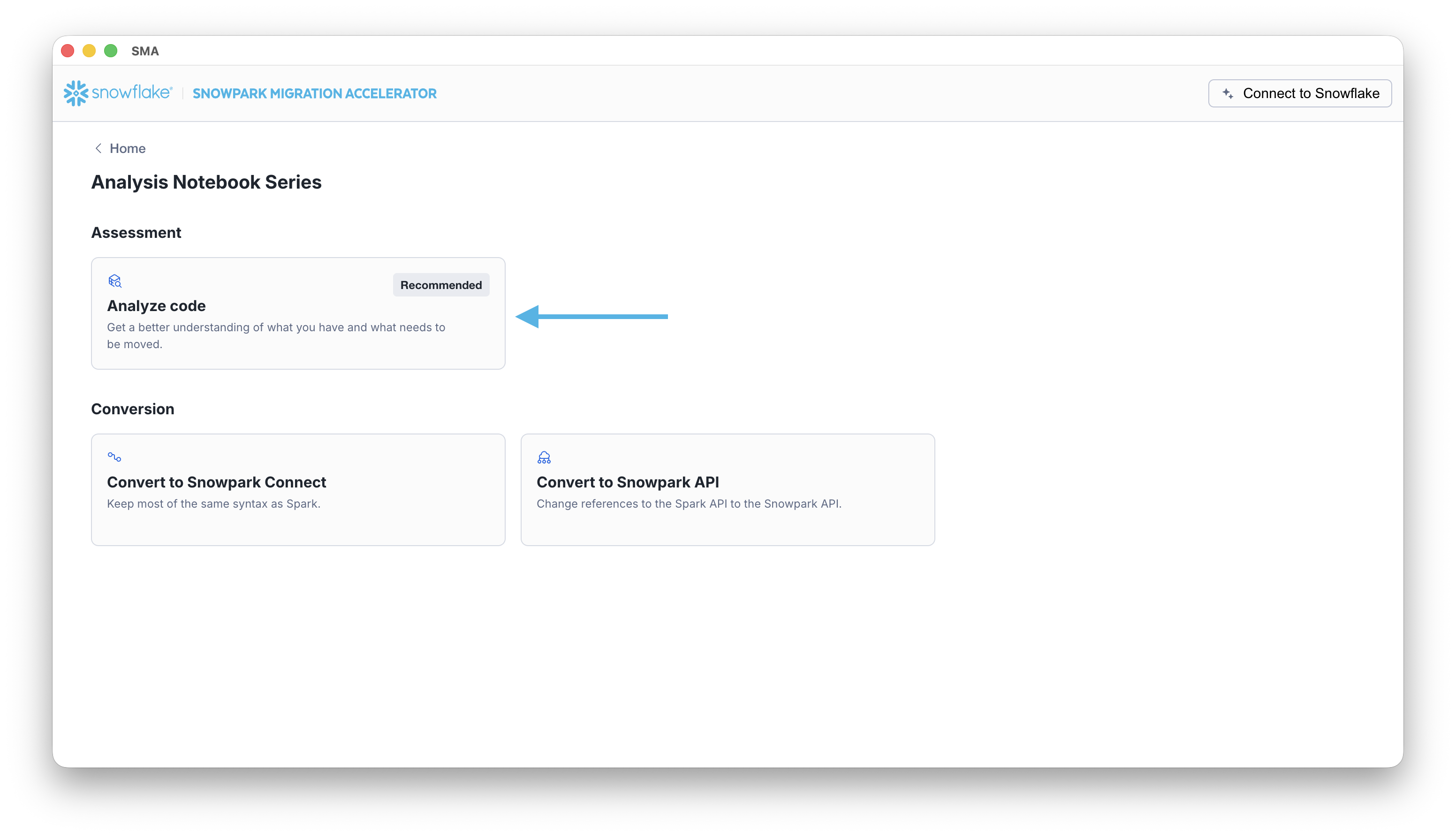
실행 및 평가 출력¶
평가 프로세스를 시작하면 SMA 가 3단계로 소스 코드를 분석합니다.
먼저 기본 스캔을 수행하여 코드베이스에 있는 모든 파일과 키워드의 인벤토리를 생성합니다.
그런 다음 소스 언어에 따라 코드를 구문 분석하고 코드의 기능을 나타내는 의미 체계 모델을 생성합니다.
Finally, it uses this model to generate detailed information, including the Spark Reference Inventory and Import Library Analysis. It also produces the converted code.
이 과정에서 화면에 3가지 진행률 표시기가 표시됩니다.
소스 코드 로딩
소스 코드 분석
결과 작성
각 단계가 완료되면 이 표시등에 불이 들어옵니다.

After the analysis is complete, the SMA automatically shows the Assessment Results page where you can see the analysis output.