Snowpark Migration Accelerator: ツールの実行¶
Snowpark Migration Accelerator(SMA)をインストールし、コードベースを準備すると、実行プロセスを開始できます。SMA アプリケーションが開いている場合は戻り、閉じている場合は起動します。
プロジェクト設定¶
When you first open the SMA, the project page is shown.

メニューから「新規プロジェクト」を選択して開始します。このチュートリアルのためにすでにプロジェクトを作成している場合は、代わりに「プロジェクトを開く」を選択することでアクセスできます。
The "Project Creation" page allows you to create a new project file, which is essential for both assessment and code conversion tasks in SMA. The project file (with a .snowct extension) is stored in your selected output directory and keeps track of all your SMA executions. If you want to link multiple executions together, you can reopen an existing project file. All project information is saved both on your local machine and in the shared database. For more details about projects, see the "project" file.
All fields shown are required for configuring the assessment tool and managing the project after running the analysis.

Project name: This is the name for your project file. Multiple executions can be connected to a single project as well as any settings you save. You can learn more about the project file below.
Email address: This email address identifies the user of the tool. This should be the user of the tool, not the owner of the codebase being scanned.
Company name: This is to help you specify the organization's code you are working with. If you are running your own code, then put your own organization here. If you are working with another organization, then put that organization name here.
Input folder: Specify the directory where your source codebase is located.
Output folder: The directory where the output files (logs, reports, code) will be placed.
For this walkthrough, we will use the "Spark Data Engineering Examples" codebase. You can find it in the sample codebases section. Follow these steps:
コードベースをダウンロードして解凍します。
すべてのファイルが格納されているルートディレクトリを探します。これが、入力ディレクトリになります。
ご希望のプロジェクト名を選択します。
出力ディレクトリを選択します(ツールはデフォルトの場所を提案しますが、必要に応じて変更できます)。
Before starting the assessment, make sure your input directory contains the correct source code files with the proper file extensions, as explained in the code preparation section.
When you are ready to begin, click Save to save your project.
After you save, the SMA takes you to the project home page. Select the Code Process tile to start the guided assessment or conversion workflow:
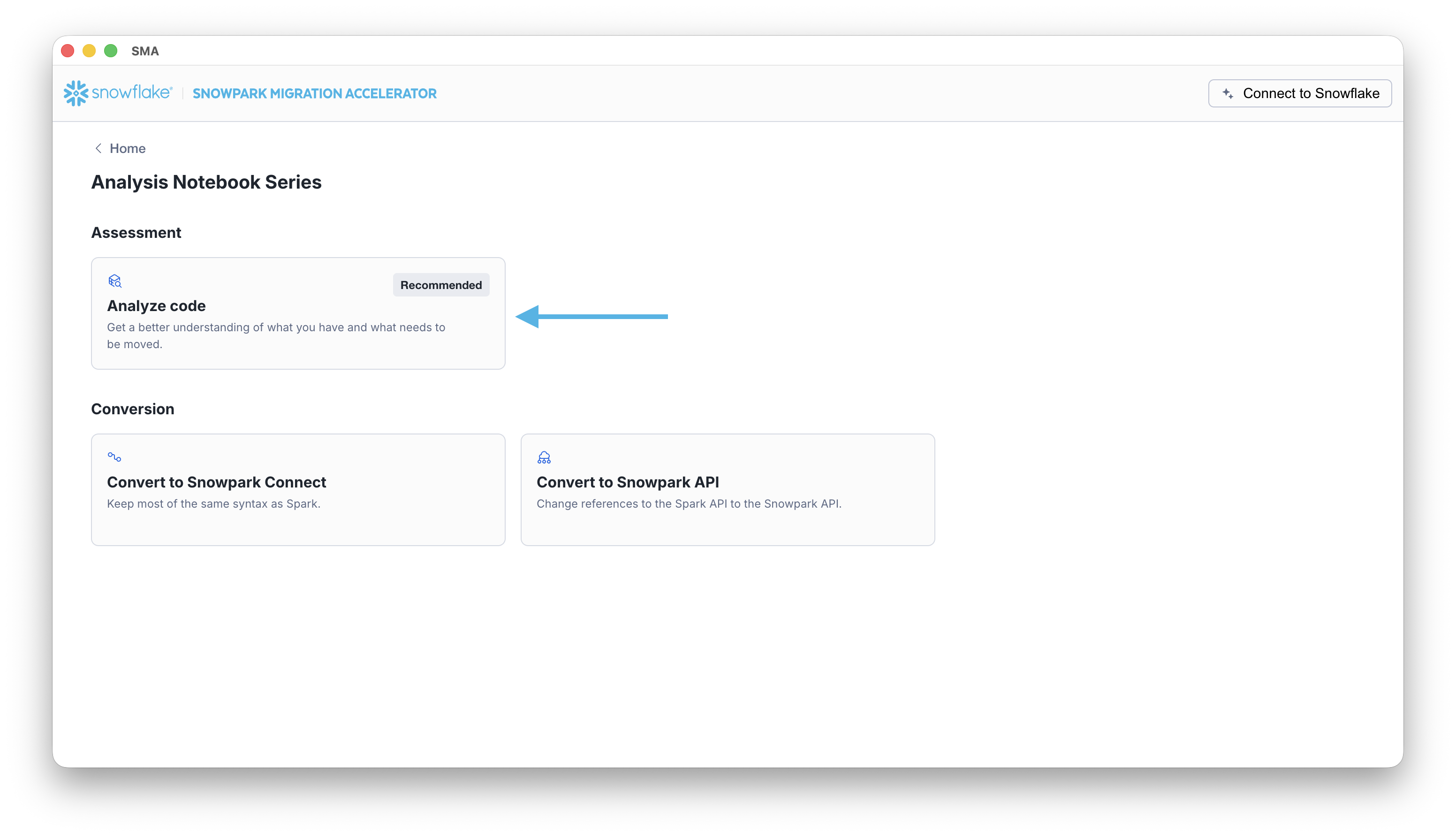
実行と評価の出力¶
評価プロセスを開始すると、 SMA は、3つのステップでソースコードを分析します。
まず、基本的なスキャンを実行し、コードベース内のすべてのファイルとキーワードのインベントリを作成します。
そして、ソース言語に従ってコードを解析し、コードの関数を表すセマンティックモデルを作成します。
Finally, it uses this model to generate detailed information, including the Spark Reference Inventory and Import Library Analysis. It also produces the converted code.
このプロセス中、画面には3つの進行状況インジケーターが表示されます。
ソースコードの読み込み
ソースコードの分析
結果の書き込み
各ステップが完了すると、これらのインジケーターが点灯します。

After the analysis is complete, the SMA automatically shows the Assessment Results page where you can see the analysis output.