SnowConvert: Transact DMLs¶
Between¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
소스 코드
-- Additional Params: -t JavaScript
CREATE PROCEDURE ProcBetween
AS
BEGIN
declare @aValue int = 1;
IF(@aValue BETWEEN 1 AND 2)
return 1
END;
GO
예상 코드
CREATE OR REPLACE PROCEDURE ProcBetween ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
let AVALUE = 1;
if (SELECT(` ? BETWEEN 1 AND 2`,[AVALUE])) {
return 1;
}
$$;
알려진 문제 ¶
문제가 발견되지 않았습니다.
대량 삽입¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
BULK INSERT 의 직접적인 변환은 Snowflake COPY INTO 문입니다. COPY INTO 는 파일 경로를 직접 사용하여 값을 검색하지 않습니다. 파일은 STAGE 앞에 위치해야 합니다. 또한 BULK INSERT 에서 사용되는 옵션은 STAGE 또는 COPY INTO 에 의해 직접 소비될 Snowflake FILE FORMAT 에 지정되어야 합니다.
STAGE 에 파일을 추가하려면 PUT 명령을 사용해야 합니다. 이 명령은 오직 SnowSQL CLI 에서만 실행될 수 있습니다.. 다음은 COPY INTO 를 실행하기 전에 수행해야 하는 단계의 예입니다.
-- Additional Params: -t JavaScript
CREATE PROCEDURE PROCEDURE_SAMPLE
AS
CREATE TABLE #temptable
([col1] varchar(100),
[col2] int,
[col3] varchar(100))
BULK INSERT #temptable FROM 'C:\test.txt'
WITH
(
FIELDTERMINATOR ='\t',
ROWTERMINATOR ='\n'
);
GO
CREATE OR REPLACE FILE FORMAT FILE_FORMAT_638434968243607970
FIELD_DELIMITER = '\t'
RECORD_DELIMITER = '\n';
CREATE OR REPLACE STAGE STAGE_638434968243607970
FILE_FORMAT = FILE_FORMAT_638434968243607970;
--** SSC-FDM-TS0004 - PUT STATEMENT IS NOT SUPPORTED ON WEB UI. YOU SHOULD EXECUTE THE CODE THROUGH THE SNOWFLAKE CLI **
PUT file://C:\test.txt @STAGE_638434968243607970 AUTO_COMPRESS = FALSE;
CREATE OR REPLACE PROCEDURE PROCEDURE_SAMPLE ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
EXEC(`CREATE OR REPLACE TEMPORARY TABLE T_temptable
(
col1 VARCHAR(100),
col2 INT,
col3 VARCHAR(100))`);
EXEC(`COPY INTO T_temptable FROM @STAGE_638434968243607970/test.txt`);
$$
위의 코드에서 볼 수 있듯이 SnowConvert 는 코드의 모든 BULK INSERTS 를 식별하고 각 인스턴스마다 복사본이 실행되기 전에 STAGE 및 FILE FORMAT 을 새로 생성합니다. 또한 STAGE 를 생성한 후 PUT 명령도 생성되어 스테이지에 파일을 추가할 수 있습니다.
생성된 문의 이름은 사용 간의 충돌을 방지하기 위해 현재 타임스탬프(초)를 사용하여 자동으로 생성됩니다.
마지막으로 대량 삽입에 대한 모든 옵션이 적용되는 경우 파일 형식 옵션에 매핑됩니다. 해당 옵션이 Snowflake에서 지원되지 않는 경우 설명과 함께 경고가 추가됩니다. SSC-FDM-TS0004도 참조하십시오.
지원되는 대량 옵션¶
SQL 서버 |
Snowflake |
|---|---|
FORMAT |
TYPE |
FIELDTERMINATOR |
FIELD_DELIMITER |
FIRSTROW |
SKIP_HEADER |
ROWTERMINATOR |
RECORD_DELIMITER |
FIELDQUOTE |
FIELD_OPTIONALLY_ENCLOSED_BY |
관련 EWIs¶
SSC-FDM-TS0004: PUT STATEMENT IS NOT SUPPORTED ON WEB UI.
공통 테이블 식 (CTE)¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
일반적인 테이블 식은 기본적으로 Snowflake SQL 에서 지원됩니다.
Snowflake SQL 구문¶
하위 쿼리:
[ WITH
<cte_name1> [ ( <cte_column_list> ) ] AS ( SELECT ... )
[ , <cte_name2> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
[ , <cte_nameN> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
]
SELECT ...
재귀 CTE:
[ WITH [ RECURSIVE ]
<cte_name1> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause )
[ , <cte_name2> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause ) ]
[ , <cte_nameN> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause ) ]
]
SELECT ...
여기서
anchorClause ::=
SELECT <anchor_column_list> FROM ...
recursiveClause ::=
SELECT <recursive_column_list> FROM ... [ JOIN ... ]
주목할 만한 세부 정보¶
RECURSIVE 키워드는 T-SQL 에 존재하지 않으며, 변환이 해당 키워드를 결과에 적극적으로 추가하지 않습니다. 이 동작을 설명하기 위해 출력 코드에 경고가 추가됩니다.
SELECT INTO 를 사용한 일반적인 테이블 식¶
WITH 식 뒤에 SELECT INTO 문이 오면 다음과 같이 변환되며, 이는 TEMPORARY TABLE 러 변환됩니다.
SQL 서버:
WITH ctetable(col1, col2) AS
(
SELECT col1, col2 FROM t1 poh WHERE poh.col1 = 16 and poh.col2 = 4
),
employeeCte AS
(
SELECT BUSINESSENTITYID, VACATIONHOURS FROM employee WHERE BUSINESSENTITYID = (SELECT col1 FROM ctetable)
),
finalCte AS
(
SELECT BUSINESSENTITYID, VACATIONHOURS FROM employeeCte
) SELECT * INTO #table2 FROM finalCte;
SELECT * FROM #table2;
Snowflake:
CREATE OR REPLACE TEMPORARY TABLE T_table2 AS
WITH ctetable (
col1,
col2
) AS
(
SELECT
col1,
col2
FROM
t1 poh
WHERE
poh.col1 = 16 and poh.col2 = 4
),
employeeCte AS
(
SELECT
BUSINESSENTITYID,
VACATIONHOURS
FROM
employee
WHERE
BUSINESSENTITYID = (SELECT
col1
FROM
ctetable
)
),
finalCte AS
(
SELECT
BUSINESSENTITYID,
VACATIONHOURS
FROM
employeeCte
)
SELECT
*
FROM
finalCte;
SELECT
*
FROM
T_table2;
다른 식과 공통 테이블 표현식¶
WITH 식 뒤에 INSERT 또는 DELETE 문이 오는 경우 다음과 같은 변환이 발생합니다.
SQL 서버:
WITH CTE AS( SELECT * from table1)
INSERT INTO Table2 (a,b,c,d)
SELECT a,b,c,d
FROM CTE
WHERE e IS NOT NULL;
Snowflake:
INSERT INTO Table2 (a, b, c, d)
WITH CTE AS( SELECT
*
from
table1
)
SELECT
a,
b,
c,
d
FROM
CTE AS CTE
WHERE
e IS NOT NULL;
삭제 위치가 있는 일반적인 테이블 식¶
이 변환의 경우CTE (공통 테이블 식)에 삭제자가 있는 경우에만 적용되지만 일부 세부 사항 CTE 에 대해서만 적용됩니다. 1개의 CTE 만 있어야 하며 ROW_NUMBER 또는 RANK 의 함수 내에 있어야 합니다.
삭제가 포함된 CTE 의 목적은 테이블에서 중복을 제거하는 것이어야 합니다. 삭제가 포함된 CTE 에서 다른 종류의 데이터를 제거하려는 경우에는 이 변환이 적용되지 않습니다.
예를 살펴보겠습니다. 작동하는 예제를 보려면 먼저 일부 데이터가 있는 테이블을 생성해야 합니다.
CREATE TABLE WithQueryTest
(
ID BIGINT,
Value BIGINT,
StringValue NVARCHAR(258)
);
Insert into WithQueryTest values(100, 100, 'First');
Insert into WithQueryTest values(200, 200, 'Second');
Insert into WithQueryTest values(300, 300, 'Third');
Insert into WithQueryTest values(400, 400, 'Fourth');
Insert into WithQueryTest values(100, 100, 'First');
중복된 값이 있다는 점에 유의하십시오. 8라인과 12라인에 동일한 값을 삽입합니다. 이제 테이블에서 중복 행을 제거해 보겠습니다.
WITH Duplicated AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY ID ORDER BY ID) AS RN
FROM WithQueryTest
)
DELETE FROM Duplicated
WHERE Duplicated.RN > 1
테이블에서 선택을 실행하면 다음과 같은 결과가 표시됩니다
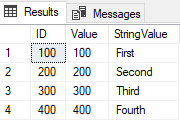
중복된 행이 없다는 점에 유의하십시오. 이러한 CTE 의 기능을 보존하기 위해 Snowflake에서 Delete를 사용하면 다음과 같이 변환됩니다
CREATE OR REPLACE TABLE PUBLIC.WithQueryTest AS SELECT
*
FROM PUBLIC.WithQueryTest
QUALIFY ROW_NUMBER()
OVER (PARTITION BY ID ORDER BY ID) = 1 ;
보시다시피 쿼리는 테이블 생성하기 또는 바꾸기로 변환됩니다.
Snowflake에서 테스트해 보겠습니다. 테스트하려면 테이블도 필요합니다.
CREATE OR REPLACE TABLE PUBLIC.WithQueryTest
(
ID BIGINT,
Value BIGINT,
StringValue VARCHAR(258)
);
Insert into PUBLIC.WithQueryTest values(100, 100, 'First');
Insert into PUBLIC.WithQueryTest values(200, 200, 'Second');
Insert into PUBLIC.WithQueryTest values(300, 300, 'Third');
Insert into PUBLIC.WithQueryTest values(400, 400, 'Fourth');
Insert into PUBLIC.WithQueryTest values(100, 100, 'First');
이제 변환 결과를 실행한 다음 선택을 클릭하여 중복된 행이 삭제되었는지 확인하면 다음과 같은 결과가 표시됩니다.
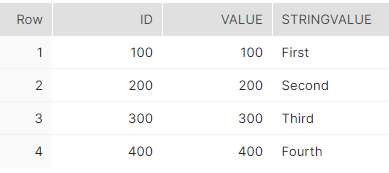
MERGE 문을 사용한 일반적인 테이블 식¶
WITH 식 뒤에 MERGE 문이 오면 다음과 같은 변환이 발생하며, 이는 MERGEINTO 호 해결할 수 있습니다..
SQL 서버:
WITH ctetable(col1, col2) as
(
SELECT col1, col2
FROM t1 poh
where poh.col1 = 16 and poh.col2 = 88
),
finalCte As
(
SELECT col1 FROM ctetable
)
MERGE
table1 AS target
USING finalCte AS source
ON (target.ID = source.COL1)
WHEN MATCHED THEN UPDATE SET target.ID = source.Col1
WHEN NOT MATCHED THEN INSERT (ID, col1) VALUES (source.COL1, source.COL1 );
Snowflake:
MERGE INTO table1 AS target
USING (
--** SSC-PRF-TS0001 - PERFORMANCE WARNING - RECURSION FOR CTE NOT CHECKED. MIGHT REQUIRE RECURSIVE KEYWORD **
WITH ctetable (
col1,
col2
) as
(
SELECT
col1,
col2
FROM
t1 poh
where
poh.col1 = 16 and poh.col2 = 88
),
finalCte As
(
SELECT
col1
FROM
ctetable
)
SELECT
*
FROM
finalCte
) AS source
ON (target.ID = source.COL1)
WHEN MATCHED THEN
UPDATE SET
target.ID = source.Col1
WHEN NOT MATCHED THEN
INSERT (ID, col1) VALUES (source.COL1, source.COL1);
UPDATE 문을 사용한 일반적인 테이블 식¶
WITH 식 뒤에 UPDATE 문이 오는 경우 다음과 같은 변환이 발생하며, 이는 UPDATE 문으로 변환됩니다.
SQL 서버:
WITH ctetable(col1, col2) AS
(
SELECT col1, col2
FROM table2 poh
WHERE poh.col1 = 5 and poh.col2 = 4
)
UPDATE tab1
SET ID = 8, COL1 = 8
FROM table1 tab1
INNER JOIN ctetable CTE ON tab1.ID = CTE.col1;
Snowflake:
UPDATE dbo.table1 tab1
SET
ID = 8,
COL1 = 8
FROM
(
WITH ctetable (
col1,
col2
) AS
(
SELECT
col1,
col2
FROM
table2 poh
WHERE
poh.col1 = 5 and poh.col2 = 4
)
SELECT
*
FROM
ctetable
) AS CTE
WHERE
tab1.ID = CTE.col1;
알려진 문제 ¶
문제가 발견되지 않았습니다.
관련 EWIs¶
SSC-EWI-0108: 다음 하위 쿼리는 유효하지 않은 것으로 간주되는 패턴 중 하나 이상과 일치하며 컴파일 오류가 발생할 수 있습니다.
SSC-PRF-TS0001: 성능 경고 - CTE 에 대한 재귀가 확인되지 않았습니다. 재귀 키워드가 필요할 수 있습니다.
삭제¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
설명¶
SQL 서버의 테이블 또는 뷰에서 1개 이상의 행을 제거합니다. SQL 서버 삭제에 대한 자세한 내용은 여기 를 참조하십시오.
[ WITH <common_table_expression> [ ,...n ] ]
DELETE
[ TOP ( expression ) [ PERCENT ] ]
[ FROM ]
{ { table_alias
| <object>
| rowset_function_limited
[ WITH ( table_hint_limited [ ...n ] ) ] }
| @table_variable
}
[ <OUTPUT Clause> ]
[ FROM table_source [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <Query Hint> [ ,...n ] ) ]
[; ]
<object> ::=
{
[ server_name.database_name.schema_name.
| database_name. [ schema_name ] .
| schema_name.
]
table_or_view_name
}
샘플 소스 패턴 ¶
DELETE 문을 변환하는 방법은 매우 간단하지만 몇 가지 주의 사항이 있습니다. 이러한 주의 사항 중 하나는 FROM 절에서 여러 소스를 지원하는 방식인데, 아래 그림과 같이 Snowflake에도 이에 상응하는 방식이 있습니다.
SQL 서버
DELETE T1 FROM TABLE2 T2, TABLE1 T1 WHERE T1.ID = T2.ID
Snowflake
DELETE FROM
TABLE1 T1
USING TABLE2 T2
WHERE
T1.ID = T2.ID;
참고
원래 DELETE 는 T1 용이므로 FROM 절에 TABLE2 T2 가 있으면 USING 절을 생성해야 합니다.
¶
테이블에서 중복 삭제하기¶
다음 설명서에서는 SQL 서버의 테이블에서 중복된 행을 제거하는 데 사용되는 일반적인 패턴 에 대해 설명합니다. 이 접근법은 ROW_NUMBER 함수를 사용하여 쉼표로 구분된 1개 이상의 열일 수 있는 key_value 를 기준으로 데이터를 파티션합니다. 그런 다음 1보다 큰 행 번호 값을 받은 모든 레코드를 삭제합니다. 이 값은 레코드가 중복되어 있음을 나타냅니다. 참조된 설명서를 읽고 이 메서드의 동작을 이해하고 다시 만들 수 있습니다.
DELETE T
FROM
(
SELECT *
, DupRank = ROW_NUMBER() OVER (
PARTITION BY key_value
ORDER BY ( {expression} )
)
FROM original_table
) AS T
WHERE DupRank > 1
다음 예제에서는 이 접근법을 사용하여 테이블과 이에 해당하는 Snowflake에서 중복을 제거합니다. 변환은 테이블을 잘라내는(모든 데이터를 제거) INSERT OVERWRITE 문을 수행한 다음 중복된 행을 무시하고 동일한 테이블에 다시 행을 삽입하는 것으로 구성됩니다. 출력 코드는 원본 코드에 사용되는 PARTITION BY 및 ORDER BY 절을 동일하게 고려하여 생성됩니다.
SQL 서버
행이 중복된 테이블 생성하기
create table duplicatedRows(
someID int,
col2 bit,
col3 bit,
col4 bit,
col5 bit
);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(11, 1, 1, 0, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(13, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
14 | true | false | true | false |
중복된 행 제거하기
DELETE f FROM (
select someID, row_number() over (
partition by someID, col2
order by
case when COL3 = 1 then 1 else 0 end
+ case when col4 = 1 then 1 else 0 end
+ case when col5 = 1 then 1 else 0 end
asc
) as rownum
from
duplicatedRows
) f where f.rownum > 1;
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
Snowflake
행이 중복된 테이블 생성하기
create table duplicatedRows(
someID int,
col2 BOOLEAN,
col3 BOOLEAN,
col4 BOOLEAN,
col5 BOOLEAN
);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(11, 1, 1, 0, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(13, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
14 | true | false | true | false |
중복된 행 제거하기
insert overwrite into duplicatedRows
SELECT
*
FROM
duplicatedRows
QUALIFY
ROW_NUMBER()
over
(partition by someID, col2
order by
case when COL3 = 1 then 1 else 0 end
+ case when col4 = 1 then 1 else 0 end
+ case when col5 = 1 then 1 else 0 end
asc) = 1;
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
경고
이 패턴에는 여러 가지 변형이 있을 수 있지만 모두 동일한 원리를 기반으로 하며 동일한 구조를 가지고 있습니다.
Known Issues¶
문제가 발견되지 않았습니다.
관련 EWIs¶
관련 EWIs 없음.
방울¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
DROP TABLE¶
Transact-SQL 의 구문¶
DROP TABLE [ IF EXISTS ] <table_name> [ ,...n ]
[ ; ]
Snowflake의 구문¶
DROP TABLE [ IF EXISTS ] <name> [ CASCADE | RESTRICT ]
변환¶
단일 DROP TABLE 문에 대한 변환은 매우 간단합니다. 문 내에 삭제되는 테이블이 하나만 있는 경우 그대로 유지됩니다.
예:
DROP TABLE IF EXISTS [table_name]
DROP TABLE IF EXISTS table_name;
SQL 서버와 Snowflake의 유일한 주목할 만한 차이점은 입력 문이 둘 이상의 테이블을 삭제할 때 표시됩니다. 이러한 시나리오에서는 삭제되는 각 테이블에 대해 서로 다른 DROP TABLE 문이 생성됩니다.
예:
DROP TABLE IF EXISTS [table_name], [table_name2], [table_name3]
DROP TABLE IF EXISTS table_name;
DROP TABLE IF EXISTS table_name2;
DROP TABLE IF EXISTS table_name3;
알려진 문제 ¶
문제가 발견되지 않았습니다.
관련 EWIs ¶
관련 EWIs 없음.
존재¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
하위 쿼리의 타입¶
하위 쿼리는 상관관계가 있거나 상관관계가 없는 것으로 분류할 수 있습니다.
상관 하위 쿼리는 하위 쿼리 외부에서 1개 이상의 열을 참조합니다. (열은 일반적으로 하위 쿼리의 WHERE 절 내에서 참조됩니다.) 상관 하위 쿼리는 하위 쿼리가 외부 쿼리에 위치한 테이블의 각 행에서 평가된 것처럼 참조하는 테이블의 필터로 생각할 수 있습니다.
비상관 하위 쿼리는 이러한 외부 열 참조가 없습니다. 그리고 독립적인 쿼리로, 쿼리의 결과는 외부 쿼리에 한 번만 반환 및 사용됩니다(행당 아님).
EXISTS 문은 상관 하위 쿼리로 간주됩니다.
소스 코드
-- Additional Params: -t JavaScript
CREATE PROCEDURE ProcExists
AS
BEGIN
IF(EXISTS(Select AValue from ATable))
return 1;
END;
예상 코드
CREATE OR REPLACE PROCEDURE ProcExists ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
if (SELECT(` EXISTS(Select
AValue
from
ATable
)`)) {
return 1;
}
$$;
알려진 문제 ¶
문제가 발견되지 않았습니다.
관련 EWIs ¶
관련 EWIs 없음.
IN¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
IN 연산자는 하위 쿼리에서 반환된 값에 식이 포함되어 있는지 확인합니다.
소스 코드
-- Additional Params: -t JavaScript
CREATE PROCEDURE dbo.SP_IN_EXAMPLE
AS
DECLARE @results as VARCHAR(50);
SELECT @results = COUNT(*) FROM TABLE1
IF @results IN (1,2,3)
SELECT 'is IN';
ELSE
SELECT 'is NOT IN';
return
GO
-- =============================================
-- Example to execute the stored procedure
-- =============================================
EXECUTE dbo.SP_IN_EXAMPLE
GO
예상 코드
CREATE OR REPLACE PROCEDURE dbo.SP_IN_EXAMPLE ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
let RESULTS;
SELECT(` COUNT(*) FROM
TABLE1`,[],(value) => RESULTS = value);
if ([1,2,3].includes(RESULTS)) {
} else {
}
return;
$$;
-- =============================================
-- Example to execute the stored procedure
-- =============================================
CALL dbo.SP_IN_EXAMPLE();
알려진 문제 ¶
문제가 발견되지 않았습니다.
관련 EWIs ¶
관련 EWIs 없음.
삽입¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
설명¶
SQL 서버의 테이블 또는 뷰에 1개 이상의 행을 추가합니다. SQL 서버 삽입에 대한 자세한 내용은 여기 에서 확인할 수 있습니다.
구문 비교¶
기본 삽입 문법은 SQL 언어 모두에서 동일합니다. 그러나 SQL 서버에는 여전히 차이점을 보여주는 몇 가지 다른 구문 요소가 있습니다. 예를 들어, 개발자가 할당 연산자를 사용하여 열에 값을 추가할 수 있는 구문 요소가 있습니다. 언급된 구문도 기본 삽입 구문으로 변환됩니다.
Snowflake
INSERT [ OVERWRITE ] INTO <target_table> [ ( <target_col_name> [ , ... ] ) ]
{
VALUES ( { <value> | DEFAULT | NULL } [ , ... ] ) [ , ( ... ) ] |
<query>
}
SQL 서버
[ WITH <common_table_expression> [ ,...n ] ]
INSERT
{
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ]
{ <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
{
[ ( column_list ) ]
[ <OUTPUT Clause> ]
{ VALUES ( { DEFAULT | NULL | expression } [ ,...n ] ) [ ,...n ]
| derived_table
| execute_statement
| <dml_table_source>
| DEFAULT VALUES
}
}
}
[;]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name
}
<dml_table_source> ::=
SELECT <select_list>
FROM ( <dml_statement_with_output_clause> )
[AS] table_alias [ ( column_alias [ ,...n ] ) ]
[ WHERE <search_condition> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
샘플 소스 패턴 ¶
기본 INSERT¶
SQL 서버¶
INSERT INTO TABLE1 VALUES (1, 2, 123, 'LiteralValue');
Snowflake¶
INSERT INTO TABLE1 VALUES (1, 2, 123, 'LiteralValue');
assing 연산자가 있는 INSERT¶
SQL 서버¶
INSERT INTO aTable (columnA = 'varcharValue', columnB = 1);
Snowflake¶
INSERT INTO aTable (columnA = 'varcharValue', columnB = 1);
INTO 가 없는 INSERT¶
SQL 서버¶
INSERT exampleTable VALUES ('Hello', 23);
Snowflake¶
INSERT INTO exampleTable VALUES ('Hello', 23);
공통 테이블 식이 있는 INSERT¶
SQL 서버¶
WITH ctevalues (textCol, numCol) AS (SELECT 'cte string', 155)
INSERT INTO exampleTable SELECT * FROM ctevalues;
Snowflake¶
INSERT INTO exampleTable
WITH ctevalues (
textCol,
numCol
) AS (SELECT 'cte string', 155)
SELECT
*
FROM
ctevalues AS ctevalues;
MERGE 를 DML 로 사용한 테이블 DML 요소가 있는 INSERT¶
이 경우는 INSERT 문에 SELECT 쿼리가 있고, SELECT 의 FROM 절에 MERGE DML 문이 포함되어 있는 매우 구체적인 경우입니다. Snowflake에서 이에 상응하는 문을 찾으면 다음 문이 생성됩니다. 임시 테이블, the merge 문 converted 및 마지막으로 삽입 문이 생성됩니다.
SQL 서버¶
INSERT INTO T3
SELECT
col1,
col2
FROM (
MERGE T1 USING T2
ON T1.col1 = T2.col1
WHEN NOT MATCHED THEN
INSERT VALUES ( T2.col1, T2.col2 )
WHEN MATCHED THEN
UPDATE SET T1.col2 = t2.col2
OUTPUT
$action ACTION_OUT,
T2.col1,
T2.col2
) AS MERGE_OUT
WHERE ACTION_OUT='UPDATE';
Snowflake¶
--** SSC-FDM-TS0026 - DELETE CASE IS NOT BEING CONSIDERED, PLEASE CHECK IF THE ORIGINAL MERGE PERFORMS IT **
CREATE OR REPLACE TEMPORARY TABLE MERGE_OUT AS
SELECT
CASE WHEN T1.$1 IS NULL THEN 'INSERT' ELSE 'UPDATE' END ACTION_OUT,
T2.col1,
T2.col2
FROM T2 LEFT JOIN T1 ON T1.col1 = T2.col1;
MERGE INTO T1
USING T2
ON T1.col1 = T2.col1
WHEN NOT MATCHED THEN INSERT VALUES (T2.col1, T2.col2)
WHEN MATCHED THEN UPDATE SET T1.col2 = t2.col2
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT
$action ACTION_OUT,
T2.col1,
T2.col2 ;
INSERT INTO T3
SELECT col1, col2
FROM MERGE_OUT
WHERE ACTION_OUT ='UPDATE';
경고
참고: 패턴의 이름에서 알 수 있듯이 본문에 MERGE 문이 포함된 select…가 삽입된 경우만 해당합니다.
Known Issues¶
1. 특수 매핑이 필요한 구문 요소입니다.
[INTO]: 이 키워드는 Snowflake에서 필수이며 없는 경우 추가해야 합니다.
[DEFAULT VALUES]: 삽입에 지정된 모든 열에 기본값을 삽입합니다. VALUES (DEFAULT, DEFAULT, …)로 변환되어야 하며, 추가된 DEFAULTs 의 양은 삽입이 수정할 열의 수와 같습니다. 현재로서는 경고가 추가되고 있습니다.
SQL 서버
INSERT INTO exampleTable DEFAULT VALUES;
#### Snowflake
!!!RESOLVE EWI!!! /*** SSC-EWI-0073 - PENDING FUNCTIONAL EQUIVALENCE REVIEW FOR 'INSERT WITH DEFAULT VALUES' NODE ***/!!!
INSERT INTO exampleTable DEFAULT VALUES;
2. 지원되지 않거나 관련 없는 구문 요소:
[TOP (expression) [PERCENT]]: 삽입할 행의 양 또는 백분율을 나타냅니다. 지원 안 됨.
[rowset_function_limited]: OPENQUERY() 또는 OPENROWSET()이며, 원격 서버에서 데이터를 읽는 데 사용됩니다. 지원 안 됨.
[WITH table_hint_limited]: 테이블에 대한 읽기/쓰기 잠금을 설정하는 데 사용됩니다. Snowflake와 관련이 없습니다.
[<OUTPUT 절>]: 삽입된 행이 삽입될 테이블 또는 결과 세트를 지정합니다. 지원 안 됨.
[execute_statement]: 데이터를 가져오는 쿼리를 실행하는 데 사용할 수 있습니다. 지원 안 됨.
[dml_table_source]: 다른 DML 문의 OUTPUT 절에 의해 생성된 임시 결과 세트입니다. 지원 안 됨.
3. DELETE 케이스는 고려되지 않고 있습니다.
MERGE 를 DML 로 사용한 테이블 DML 요소가 있는 INSERT 패턴의 경우 솔루션에서 DELETE 케이스는 고려하지 않으므로 소스 코드 병합 문에 DELETE 케이스가 있는 경우 예상대로 작동하지 않을 수 있음을 고려하십시오.
관련 EWIs¶
SSC-EWI-0073: 보류 중 함수 동등성 검토.
SSC-FDM-TS0026: DELETE 케이스는 고려되지 않고 있습니다.
병합¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
구문 비교¶
Snowflake SQL 구문:
MERGE
INTO <target_table>
USING <source>
ON <join_expr>
{ matchedClause | notMatchedClause } [ ... ]
Transact-SQL 구문:
-- SQL Server and Azure SQL Database
[ WITH <common_table_expression> [,...n] ]
MERGE
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ] <target_table> [ WITH ( <merge_hint> ) ] [ [ AS ] table_alias ]
USING <table_source> [ [ AS ] table_alias ]
ON <merge_search_condition>
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ <output_clause> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
;
예¶
다음 소스 코드가 주어집니다.
MERGE
INTO
targetTable WITH(KEEPIDENTITY, KEEPDEFAULTS, HOLDLOCK, IGNORE_CONSTRAINTS, IGNORE_TRIGGERS, NOLOCK, INDEX(value1, value2, value3)) as tableAlias
USING
tableSource AS tableAlias2
ON
mergeSetCondition > mergeSetCondition
WHEN MATCHED BY TARGET AND pi.Quantity - src.OrderQty >= 0
THEN UPDATE SET pi.Quantity = pi.Quantity - src.OrderQty
OUTPUT $action, DELETED.v AS DELETED, INSERTED.v INSERTED INTO @localVar(col, list)
OPTION(RECOMPILE);
다음과 같은 결과를 기대할 수 있습니다.
MERGE INTO targetTable as tableAlias
USING tableSource AS tableAlias2
ON mergeSetCondition > mergeSetCondition
WHEN MATCHED AND pi.Quantity - src.OrderQty >= 0 THEN
UPDATE SET
pi.Quantity = pi.Quantity - src.OrderQty
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT $action, DELETED.v AS DELETED, INSERTED.v INSERTED INTO @localVar(col, list);
관련 EWIs¶
SSC-EWI-0021: Snowflake에서 지원되지 않는 구문입니다.
선택¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
설명¶
SQL 서버에서 1개 이상의 테이블의 행 또는 열을 1개 이상 선택할 수 있습니다.
SQL Server Select에 대한 자세한 내용은 여기 에서 확인할 수 있습니다.
<SELECT statement> ::=
[ WITH { [ XMLNAMESPACES ,] [ <common_table_expression> [,...n] ] } ]
<query_expression>
[ ORDER BY <order_by_expression> ]
[ <FOR Clause>]
[ OPTION ( <query_hint> [ ,...n ] ) ]
<query_expression> ::=
{ <query_specification> | ( <query_expression> ) }
[ { UNION [ ALL ] | EXCEPT | INTERSECT }
<query_specification> | ( <query_expression> ) [...n ] ]
<query_specification> ::=
SELECT [ ALL | DISTINCT ]
[TOP ( expression ) [PERCENT] [ WITH TIES ] ]
< select_list >
[ INTO new_table ]
[ FROM { <table_source> } [ ,...n ] ]
[ WHERE <search_condition> ]
[ <GROUP BY> ]
[ HAVING < search_condition > ]
샘플 소스 패턴 ¶
SELECT WITH COLUMN ALIASES¶
다음 예제는 Snowflake에서 열 별칭을 사용하는 방법을 보여줍니다. SQL 서버 코드의 처음 두 열은 AS 키워드를 사용하여 할당 양식에서 정규화된 양식으로 변환될 것으로 예상됩니다. 세 번째 및 네 번째 열은 유효한 Snowflake 형식을 사용하고 있습니다.
SQL 서버
SELECT
MyCol1Alias = COL1,
MyCol2Alias = COL2,
COL3 AS MyCol3Alias,
COL4 MyCol4Alias
FROM TABLE1;
Snowflake
SELECT
COL1 AS MyCol1Alias,
COL2 AS MyCol2Alias,
COL3 AS MyCol3Alias,
COL4 MyCol4Alias
FROM
TABLE1;
SELECT TOP¶
SQL Server Select Top의 기본 케이스는 Snowflake에서 지원됩니다. 그러나 지원되지 않는 경우가 세 가지 더 있으며, 알려진 문제 섹션에서 확인할 수 있습니다.
SQL 서버
SELECT TOP 1 * from ATable;
Snowflake
SELECT TOP 1
*
from
ATable;
SELECT INTO¶
다음 예제에서는 SELECT INTO 가 CREATE TABLE AS 로 변환된 것을 볼 수 있는데, 이는 Snowflake에서 SELECT INTO 에 해당하는 것이 없고 쿼리를 기반으로 테이블을 생성하려면 CREATE TABLE AS 를 사용해야 하기 때문입니다.
SQL 서버
SELECT * INTO NEWTABLE FROM TABLE1;
Snowflake
CREATE OR REPLACE TABLE NEWTABLE AS
SELECT
*
FROM
TABLE1;
또 다른 경우는 EXCEPT 및 INTERSECT 과 같은 세트 연산자를 포함하는 경우입니다. 변환은 기본적으로 이전 변환과 동일합니다.
SQL 서버
SELECT * INTO NEWTABLE FROM TABLE1
EXCEPT
SELECT * FROM TABLE2
INTERSECT
SELECT * FROM TABLE3;
Snowflake
CREATE OR REPLACE TABLE NEWTABLE AS
SELECT
*
FROM
TABLE1
EXCEPT
SELECT
*
FROM
TABLE2
INTERSECT
SELECT
*
FROM
TABLE3;
Known Issues¶
SELECT TOP 추가 인자¶
PERCENT 및 WITH TIES 키워드는 결과에 영향을 미치며, Snowflake에서 지원하지 않으므로 오류로 설명되어 추가됩니다.
SQL 서버
SELECT TOP 1 PERCENT * from ATable;
SELECT TOP 1 WITH TIES * from ATable;
SELECT TOP 1 PERCENT WITH TIES * from ATable;
Snowflake
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT FOR¶
FOR 절은 Snowflake에서 지원되지 않으므로 변환 중에 오류로 설명되어 추가됩니다.
SQL 서버
SELECT column1, column2 FROM my_table FOR XML PATH('');
Snowflake
SELECT
--** SSC-FDM-TS0016 - XML COLUMNS IN SNOWFLAKE MIGHT HAVE A DIFFERENT FORMAT **
FOR_XML_UDF(OBJECT_CONSTRUCT('column1', column1, 'column2', column2), '')
FROM
my_table;
SELECT OPTION¶
OPTION 절은 Snowflake에서 지원되지 않습니다. 변환하는 동안 설명이 추가되고 경고로 추가됩니다.
경고
OPTION 문은 관련성이 없거나 필요하지 않으므로 변환에서 제거되었음을 참고하십시오.
SQL 서버
SELECT column1, column2 FROM my_table OPTION (HASH GROUP, FAST 10);
Snowflake
SELECT
column1,
column2
FROM
my_table;
SELECT WITH¶
WITH 절은 Snowflake에서 지원되지 않습니다. 변환하는 동안 설명이 추가되고 경고로 추가됩니다.
경고
WITH(NOLOCK, NOWAIT) 문은 관련성이 없거나 필요하지 않으므로 변환에서 제거되었습니다.
SQL 서버
SELECT AValue from ATable WITH(NOLOCK, NOWAIT);
Snowflake
SELECT
AValue
from
ATable;
관련 EWIs¶
SSC-EWI-0040: 문은 지원되지 않습니다.
SSC-FDM-TS0016: XML 열의 형식은 다를 수 있습니다
세트 연산자¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
TSQL 과 Snowflake의 설정 연산자는 TSQL 에서 지원되지 않는 MINUS 를 제외하고 동일한 구문과 지원 시나리오(EXCEPT, INTERSECT, UNION, UNION ALL)를 제공하므로 변환 시 동일한 코드가 생성됩니다.
SELECT LastName, FirstName FROM employees
UNION ALL
SELECT FirstName, LastName FROM contractors;
SELECT ...
INTERSECT
SELECT ...
SELECT ...
EXCEPT
SELECT ...
잘라내기¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
소스 코드
TRUNCATE TABLE TABLE1;
변환된 코드
TRUNCATE TABLE TABLE1;
관련 EWIs¶
관련 EWIs 없음.
업데이트¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
참고
출력 코드의 일부 부분은 명확성을 위해 생략되었습니다.
설명¶
SQL 서버에서 테이블 또는 뷰의 기존 데이터를 변경합니다. SQL 서버 업데이트에 대한 자세한 내용은 여기 를 참조하십시오.
[ WITH <common_table_expression> [...n] ]
UPDATE
[ TOP ( expression ) [ PERCENT ] ]
{ { table_alias | <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
| @table_variable
}
SET
{ column_name = { expression | DEFAULT | NULL }
| { udt_column_name.{ { property_name = expression
| field_name = expression }
| method_name ( argument [ ,...n ] )
}
}
| column_name { .WRITE ( expression , @Offset , @Length ) }
| @variable = expression
| @variable = column = expression
| column_name { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable = column { += | -= | *= | /= | %= | &= | ^= | |= } expression
} [ ,...n ]
[ <OUTPUT Clause> ]
[ FROM{ <table_source> } [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <query_hint> [ ,...n ] ) ]
[ ; ]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name}
샘플 소스 패턴 ¶
기본 UPDATE¶
일반 UPDATE 문으로 변환하는 방법은 매우 간단합니다. 기본 UPDATE 구조는 Snowflake에서 기본적으로 지원되므로 이상값은 약간의 차이가 있는 부분으로, 알려진 문제 섹션에서 확인하십시오.
SQL 서버¶
Update UpdateTest1
Set Col1 = 5;
Snowflake
Update UpdateTest1
Set
Col1 = 5;
데카르트 곱¶
SQL 서버는 업데이트 문의 대상 테이블과 FROM 절 사이에 순환 참조를 추가할 수 있습니. 실행 시 데이터베이스 최적화 도구는 생성된 데카르트 곱을 제거합니다. 그렇지 않으면, Snowflake는 현재 이 시나리오를 최적화하지 않고 실행 계획에서 확인할 수 있는 데카르트 곱을 생성합니다.\
이를 해결하기 위해 테이블 중 하나가 업데이트 대상과 동일한 JOIN 이 있는 경우 이 참조를 제거하고 WHERE 절에 추가하여 데이터를 필터링하고 세트 작업을 하지 않는 데 사용합니다.
SQL 서버¶
UPDATE [HumanResources].[EMPLOYEEDEPARTMENTHISTORY_COPY]
SET
BusinessEntityID = b.BusinessEntityID ,
DepartmentID = b.DepartmentID,
ShiftID = b.ShiftID,
StartDate = b.StartDate,
EndDate = b.EndDate,
ModifiedDate = b.ModifiedDate
FROM [HumanResources].[EMPLOYEEDEPARTMENTHISTORY_COPY] AS a
RIGHT OUTER JOIN [HumanResources].[EmployeeDepartmentHistory] AS b
ON a.BusinessEntityID = b.BusinessEntityID and a.ShiftID = b.ShiftID;
Snowflake
UPDATE HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY a
SET
BusinessEntityID = b.BusinessEntityID,
DepartmentID = b.DepartmentID,
ShiftID = b.ShiftID,
StartDate = b.StartDate,
EndDate = b.EndDate,
ModifiedDate = b.ModifiedDate
FROM
HumanResources.EmployeeDepartmentHistory AS b
WHERE
HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY.BusinessEntityID = b.BusinessEntityID(+)
AND HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY.ShiftID = b.ShiftID(+);
Known Issues¶
OUTPUT 절¶
OUTPUT 절은 Snowflake에서 지원되지 않습니다.
SQL 서버¶
Update UpdateTest2
Set Col1 = 5
OUTPUT
deleted.Col1,
inserted.Col1
into ValuesTest;
Snowflake
Update UpdateTest2
Set
Col1 = 5
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT
deleted.Col1,
inserted.Col1
into ValuesTest;
CTE¶
WITH CTE 절을 업데이트 문의 내부 쿼리로 이동하여 Snowflake에서 지원하도록 합니다.
SQL 서버¶
With ut as (select * from UpdateTest3)
Update x
Set Col1 = 5
from ut as x;
Snowflake
UPDATE UpdateTest3
Set
Col1 = 5
FROM
(
WITH ut as (select
*
from
UpdateTest3
)
SELECT
*
FROM
ut
) AS x;
TOP 절¶
TOP 절은 Snowflake에서 지원되지 않습니다.
SQL 서버¶
Update TOP(10) UpdateTest4
Set Col1 = 5;
Snowflake
Update
-- !!!RESOLVE EWI!!! /*** SSC-EWI-0021 - TOP CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
-- TOP(10)
UpdateTest4
Set
Col1 = 5;
WITH TABLE HINT LIMITED¶
업데이트 WITH 절은 Snowflake에서 지원되지 않습니다.
SQL 서버¶
Update UpdateTest5 WITH(TABLOCK)
Set Col1 = 5;
Snowflake
Update UpdateTest5
Set
Col1 = 5;
관련 EWIs¶
SSC-EWI-0021: Snowflake에서 지원되지 않는 구문입니다.
JOIN 이 있는 UPDATE 의 대안¶
이 내용은 진행 중이며 향후 변경될 수 있습니다.
Description
UPDATE FROM 패턴은 다른 테이블의 데이터를 기반으로 데이터를 업데이트하는 데 사용됩니다. 이 SQLServer 설명서 는 간단한 샘플을 제공합니다.
설명서 에서 다음 SQL 서버 구문을 검토하십시오.
SQL 서버 구문
UPDATE [table_name]
SET column_name = expression [, ...]
[FROM <table_source> [, ...]]
[WHERE <search_condition>]
[OPTION (query_hint)]
table_name: 업데이트하려는 테이블 또는 뷰입니다.SET: 열과 새 값을 지정합니다.SET절은 1개 이상의 열에 새 값(또는 식)을 할당합니다.FROM: 1개 이상의 소스 테이블을 지정하는 데 사용됩니다(예: join). 업데이트를 수행하기 위한 데이터의 출처를 정의하는 데 도움이 됩니다.WHERE: 조건에 따라 업데이트할 행을 지정합니다. 이 절이 없으면 테이블의 모든 행이 업데이트됩니다.OPTION (query_hint): 쿼리 최적화를 위한 힌트를 지정합니다.
Snowflake 구문
Snowflake 구문은 Snowflake 설명서 에서도 확인할 수 있습니다.
참고
Snowflake는 UPDATE 절의 JOINs 을 지원하지 않습니다.
UPDATE <target_table>
SET <col_name> = <value> [ , <col_name> = <value> , ... ]
[ FROM <additional_tables> ]
[ WHERE <condition> ]
필수 매개 변수
_
target_table:업데이트할 테이블을 지정합니다._
col_name:_target_table_. 에서 열의 이름을 지정합니다. 테이블 이름을 포함하지 마십시오. 예:UPDATE t1 SET t1.col = 1은 유효하지 않습니다._
value:_ _col_name_ 에 설정할 새 값을 지정합니다.
선택적 매개 변수
FROM``_additional_tables:_ 업데이트할 행을 선택하거나 새 값을 설정하는 데 사용할 1개 이상의 테이블을 지정합니다. 대상 테이블을 반복하면 셀프 조인이 발생한다는 점에 유의하십시오.WHERE``_condition:_: 업데이트할 대상 테이블의 행을 지정하는 식입니다. 기본값: 값 없음(대상 테이블의 모든 행이 업데이트됨)
변환 요약¶
| SQL Server JOIN type | Snowflake Best Alternative |
|---|---|
Single INNER JOIN | Use the target table in the FROM clause to emulate an INNER JOIN. |
Multiple INNER JOIN | Use the target table in the FROM clause to emulate an INNER JOIN. |
Multiple INNER JOIN + Agregate condition | Use subquery + IN Operation |
Single LEFT JOIN | Use subquery + IN Operation |
Multiple LEFT JOIN | Use Snowflake
|
Multiple RIGHT JOIN | Use Snowflake
|
| Single RIGHT JOIN | Use the table in the FROM clause and add filters in the WHERE clause as needed. |
참고-1: 간단한 JOIN 은 FROM 절의 테이블을 사용하고 필요에 따라 WHERE 절에 필터를 추가할 수 있습니다
참고-2: 다른 접근법은 JOINs_을 정의하기 위해 (+) 피연산자를 포함할 수 있습니다
샘플 소스 패턴 ¶
설정 데이터¶
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
Quantity INT,
OrderDate DATE
);
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
);
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100),
Price DECIMAL(10, 2)
);
CREATE OR REPLACE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
Quantity INT,
OrderDate DATE
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100),
Price DECIMAL(10, 2)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
Data Insertion for samples
-- Insert Customer Data
INSERT INTO Customers (CustomerID, CustomerName) VALUES (1, 'John Doe');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (2, 'Jane Smith');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (3, 'Alice Johnson');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (4, 'Bob Lee');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (5, 'Charlie Brown');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (6, 'David White');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (7, 'Eve Black');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (8, 'Grace Green');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (9, 'Hank Blue');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (10, 'Ivy Red');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (11, 'Jack Grey');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (12, 'Kim Yellow');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (13, 'Leo Purple');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (14, 'Mona Pink');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (15, 'Nathan Orange');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (16, 'Olivia Cyan');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (17, 'Paul Violet');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (18, 'Quincy Brown');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (19, 'Rita Silver');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (20, 'Sam Green');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (21, 'Tina Blue');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (22, 'Ursula Red');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (23, 'Vince Yellow');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (24, 'Wendy Black');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (25, 'Xander White');
-- Insert Product Data
INSERT INTO Products (ProductID, ProductName, Price) VALUES (1, 'Laptop', 999.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (2, 'Smartphone', 499.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (3, 'Tablet', 299.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (4, 'Headphones', 149.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (5, 'Monitor', 199.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (6, 'Keyboard', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (7, 'Mouse', 29.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (8, 'Camera', 599.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (9, 'Printer', 99.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (10, 'Speaker', 129.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (11, 'Charger', 29.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (12, 'TV', 699.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (13, 'Smartwatch', 199.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (14, 'Projector', 499.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (15, 'Game Console', 399.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (16, 'Speaker System', 299.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (17, 'Earphones', 89.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (18, 'USB Drive', 15.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (19, 'External Hard Drive', 79.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (20, 'Router', 89.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (21, 'Printer Ink', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (22, 'Flash Drive', 9.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (23, 'Gamepad', 34.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (24, 'Webcam', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (25, 'Docking Station', 129.99);
-- Insert Orders Data
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (1, 1, 1, 2, '2024-11-01');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (2, 2, 2, 1, '2024-11-02');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (3, 3, 3, 5, '2024-11-03');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (4, 4, 4, 3, '2024-11-04');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (5, NULL, 5, 7, '2024-11-05'); -- NULL Customer
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (6, 6, 6, 2, '2024-11-06');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (7, 7, NULL, 4, '2024-11-07'); -- NULL Product
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (8, 8, 8, 1, '2024-11-08');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (9, 9, 9, 3, '2024-11-09');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (10, 10, 10, 2, '2024-11-10');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (11, 11, 11, 5, '2024-11-11');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (12, 12, 12, 2, '2024-11-12');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (13, NULL, 13, 8, '2024-11-13'); -- NULL Customer
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (14, 14, NULL, 4, '2024-11-14'); -- NULL Product
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (15, 15, 15, 3, '2024-11-15');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (16, 16, 16, 2, '2024-11-16');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (17, 17, 17, 1, '2024-11-17');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (18, 18, 18, 4, '2024-11-18');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (19, 19, 19, 3, '2024-11-19');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (20, 20, 20, 6, '2024-11-20');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (21, 21, 21, 3, '2024-11-21');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (22, 22, 22, 5, '2024-11-22');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (23, 23, 23, 2, '2024-11-23');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (24, 24, 24, 4, '2024-11-24');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (25, 25, 25, 3, '2024-11-25');
케이스 1: 단일 INNER JOIN 업데이트¶
INNER JOIN 의 경우 테이블이 FROM 문 내에 사용되면 자동으로 INNER JOIN 으로 바뀝니다. UPDATE 문에서 JOINs 을 지원하는 방법에는 여러 가지가 있습니다. 이는 가독성을 보장하는 가장 간단한 패턴 중 하나입니다.
SQL 서버¶
UPDATE Orders
SET Quantity = 10
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerName = 'John Doe';
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'John Doe';
CustomerID |
수량 |
CustomerName |
|---|---|---|
1 |
10 |
John Doe |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 10
FROM
Customers C
WHERE
C.CustomerName = 'John Doe'
AND O.CustomerID = C.CustomerID;
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'John Doe';
CustomerID |
수량 |
CustomerName |
|---|---|---|
1 |
10 |
John Doe |
다른 접근법:
MERGE INTO
MERGE INTO Orders O
USING Customers C
ON O.CustomerID = C.CustomerID
WHEN MATCHED AND C.CustomerName = 'John Doe' THEN
UPDATE SET O.Quantity = 10;
IN Operation
UPDATE Orders O
SET O.Quantity = 10
WHERE O.CustomerID IN
(SELECT CustomerID FROM Customers WHERE CustomerName = 'John Doe');
케이스 2: 다중 INNER JOIN 업데이트¶
SQL 서버¶
UPDATE Orders
SET Quantity = 5
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerName = 'Alice Johnson' AND P.ProductName = 'Tablet';
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'Alice Johnson';
CustomerID |
수량 |
CustomerName |
|---|---|---|
3 |
5 |
Alice Johnson |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 5
FROM Customers C, Products P
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet'
AND O.ProductID = P.ProductID;
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'Alice Johnson';
CustomerID |
수량 |
CustomerName |
|---|---|---|
3 |
5 |
Alice Johnson |
케이스 3: 집계 조건이 있는 여러 INNER JOIN 업데이트¶
SQL 서버¶
UPDATE Orders
SET Quantity = 6
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
SELECT C.CustomerID, C.CustomerName, O.Quantity, P.Price FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
CustomerID |
CustomerName |
수량 |
Price |
|---|---|---|---|
11 |
Jack Grey |
6 |
29.99 |
18 |
Quincy Brown |
6 |
15.99 |
20 |
Sam Green |
6 |
89.99 |
22 |
Ursula Red |
6 |
9.99 |
24 |
Wendy Black |
6 |
49.99 |
Snowflake¶
UPDATE Orders O
SET Quantity = 6
WHERE O.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND O.ProductID IN (SELECT ProductID FROM Products WHERE Price < 200);
-- Select changes
SELECT C.CustomerID, C.CustomerName, O.Quantity, P.Price FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
CustomerID |
CustomerName |
수량 |
Price |
|---|---|---|---|
11 |
Jack Grey |
6 |
29.99 |
18 |
Quincy Brown |
6 |
15.99 |
20 |
Sam Green |
6 |
89.99 |
22 |
Ursula Red |
6 |
9.99 |
24 |
Wendy Black |
6 |
49.99 |
케이스 4: 단일 LEFT JOIN 업데이트¶
SQL 서버¶
UPDATE Orders
SET Quantity = 13
FROM Orders O
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND O.ProductID = 13;
-- Select the changes
SELECT * FROM orders
WHERE CustomerID IS NULL;
OrderID |
CustomerID |
ProductID |
수량 |
OrderDate |
|---|---|---|---|---|
5 |
Null |
5 |
7 |
2024-11-05 |
13 |
Null |
13 |
13 |
2024-11-13 |
Snowflake¶
UPDATE Orders
SET Quantity = 13
WHERE OrderID IN (
SELECT O.OrderID
FROM Orders O
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND O.ProductID = 13
);
-- Select the changes
SELECT * FROM orders
WHERE CustomerID IS NULL;
OrderID |
CustomerID |
ProductID |
수량 |
OrderDate |
|---|---|---|---|---|
5 |
Null |
5 |
7 |
2024-11-05 |
13 |
Null |
13 |
13 |
2024-11-13 |
참고
Snowflake의 이 접근법은 필요한 행을 업데이트하지 않으므로 작동하지 않습니다.
UPDATE Orders O SET O.Quantity = 13 FROM Customers C WHERE O.CustomerID = C.CustomerID AND C.CustomerID IS NULL AND O.ProductID = 13;
케이스 5: 여러 LEFT JOIN 및 RIGHT JOIN 업데이트¶
이는 더 복잡한 패턴입니다. 여러 LEFT JOINs 을 변환하려면 다음 패턴을 검토하십시오.
참고
LEFT JOIN 및 RIGHT JOIN 은 FROM 절의 순서에 따라 종속성을 갖습니다.
UPDATE [target_table_name]
SET [all_set_statements]
FROM [all_left_join_tables_separated_by_comma]
WHERE [all_clauses_into_the_ON_part]
SQL 서버¶
UPDATE Orders
SET
Quantity = C.CustomerID
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
SELECT O.OrderID, O.CustomerID, O.ProductID, O.Quantity, O.OrderDate
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
OrderID |
CustomerID |
ProductID |
수량 |
OrderDate |
|---|---|---|---|---|
3 |
3 |
3 |
3 |
2024-11-12 |
Snowflake¶
UPDATE Orders O
SET O.Quantity = C.CustomerID
FROM Customers C, Products P
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet'
AND O.ProductID = P.ProductID;
SELECT O.OrderID, O.CustomerID, O.ProductID, O.Quantity, O.OrderDate
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
OrderID |
CustomerID |
ProductID |
수량 |
OrderDate |
|---|---|---|---|---|
3 |
3 |
3 |
3 |
2024-11-12 |
케이스 6: INNER JOIN 및 LEFT JOIN 업데이트 혼합¶
SQL 서버¶
UPDATE Orders
SET Quantity = 4
FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
-- Select changes
SELECT O.CustomerID, C.CustomerName, O.Quantity FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
CustomerID |
CustomerName |
수량 |
|---|---|---|
Null |
Null |
4 |
Snowflake¶
UPDATE Orders O
SET Quantity = 4
WHERE O.ProductID IN (SELECT ProductID FROM Products WHERE ProductName = 'Monitor')
AND O.CustomerID IS NULL;
-- Select changes
SELECT O.CustomerID, C.CustomerName, O.Quantity FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
CustomerID |
CustomerName |
수량 |
|---|---|---|
Null |
Null |
4 |
케이스 7: 단일 RIGHT JOIN 업데이트¶
SQL 서버¶
UPDATE O
SET O.Quantity = 1000
FROM Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerName = 'Alice Johnson';
-- Select changes
SELECT
O.OrderID,
O.CustomerID,
O.ProductID,
O.Quantity,
O.OrderDate,
C.CustomerName
FROM
Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE
C.CustomerName = 'Alice Johnson';
| OrderID | CustomerID | ProductID | Quantity | CustomerName |
|---|---|---|---|---|
| 3 | 3 | 3 | 1000 | Alice Johnson |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 1000
FROM Customers C
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson';
-- Select changes
SELECT
O.OrderID,
O.CustomerID,
O.ProductID,
O.Quantity,
O.OrderDate,
C.CustomerName
FROM
Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE
C.CustomerName = 'Alice Johnson';
| OrderID | CustomerID | ProductID | Quantity | CustomerName |
|---|---|---|---|---|
| 3 | 3 | 3 | 1000 | Alice Johnson |
문제 파악¶
UPDATE에서JOINs을 직접 사용할 수 없으므로 설명된 패턴과 일치하지 않는 경우가 있을 수 있습니다.
UPDATELEFT 및 RIGHTJOIN¶
Applies to
[x] SQL 서버
[x] Azure 시냅스 분석
경고
Snowflake에서 부분적으로 지원됨
설명 ¶
UPDATE FROM 패턴은 다른 테이블의 데이터를 기반으로 데이터를 업데이트하는 데 사용됩니다. 이 SQLServer 설명서 는 간단한 샘플을 제공합니다.
설명서 에서 다음 SQL 서버 구문을 검토하십시오.
SQL 서버 구문¶
UPDATE [table_name]
SET column_name = expression [, ...]
[FROM <table_source> [, ...]]
[WHERE <search_condition>]
[OPTION (query_hint)]
table_name: 업데이트하려는 테이블 또는 뷰입니다.SET: 열과 새 값을 지정합니다.SET절은 1개 이상의 열에 새 값(또는 식)을 할당합니다.FROM: 1개 이상의 소스 테이블을 지정하는 데 사용됩니다(예: join). 업데이트를 수행하기 위한 데이터의 출처를 정의하는 데 도움이 됩니다.WHERE: 조건에 따라 업데이트할 행을 지정합니다. 이 절이 없으면 테이블의 모든 행이 업데이트됩니다.OPTION (query_hint): 쿼리 최적화를 위한 힌트를 지정합니다.
Snowflake 구문¶
Snowflake 구문은 Snowflake 설명서 에서도 확인할 수 있습니다.
참고
Snowflake는 UPDATE 절의 JOINs 을 지원하지 않습니다.
UPDATE <target_table>
SET <col_name> = <value> [ , <col_name> = <value> , ... ]
[ FROM <additional_tables> ]
필수 매개 변수
_
target_table:업데이트할 테이블을 지정합니다._
col_name:_target_table_. 에서 열의 이름을 지정합니다. 테이블 이름을 포함하지 마십시오. 예:UPDATE t1 SET t1.col = 1은 유효하지 않습니다._
value:_ _col_name_ 에 설정할 새 값을 지정합니다.
선택적 매개 변수
FROM``_additional_tables:_ 업데이트할 행을 선택하거나 새 값을 설정하는 데 사용할 1개 이상의 테이블을 지정합니다. 대상 테이블을 반복하면 셀프 조인이 발생한다는 점에 유의하십시오.WHERE``_condition:_: 업데이트할 대상 테이블의 행을 지정하는 식입니다. 기본값: 값 없음(대상 테이블의 모든 행이 업데이트됨)
변환 요약¶
문법 설명에 설명되어 있듯이 UPDATE 클래스 내에 JOINs 에 대한 직접적인 동등한 솔루션은 없습니다. 따라서 이 문을 변환하는 방법은 필수 권한을 테이블에 논리적으로 추가하는 열에 연산자(+)를 추가하는 것입니다. 이 연산자(+)는 LEFT/RIGHT JOIN 섹션에서 테이블이 참조되는 케이스에 추가됩니다.
이 연산자 (+)를 사용하는 다른 언어가 있으며 연산자의 위치에 따라 조인 유형이 결정될 수 있다는 점에 유의하십시오. 이 특정 경우 Snowflake에서는 위치가 조인 유형을 결정하는 것이 아니라 논리적으로 필요한 테이블 및 열과의 연결에 따라 결정됩니다.
MERGE 케이스 또는 CTE 의 사용법과 같은 다른 대안이 있더라도 쿼리가 복잡하고 방대해지면 이러한 대안은 읽기 어려워지는 경향이 있습니다.
샘플 소스 패턴 ¶
설정 데이터¶
CREATE TABLE GenericTable1 (
Col1 INT,
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10),
Col6 VARCHAR(100)
);
CREATE TABLE GenericTable2 (
Col1 VARCHAR(10),
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10)
);
CREATE TABLE GenericTable3 (
Col1 VARCHAR(10),
Col2 VARCHAR(100),
Col3 CHAR(1)
);
INSERT INTO GenericTable1 (Col1, Col2, Col3, Col4, Col5, Col6)
VALUES
(1, 'A1', 'B1', 'C1', NULL, NULL),
(2, 'A2', 'B2', 'C2', NULL, NULL),
(3, 'A3', 'B3', 'C3', NULL, NULL);
INSERT INTO GenericTable2 (Col1, Col2, Col3, Col4, Col5)
VALUES
('1', 'A1', 'B1', 'C1', 'X1'),
('2', 'A2', 'B2', 'C2', 'X2'),
('3', 'A3', 'B3', 'C3', 'X3');
INSERT INTO GenericTable3 (Col1, Col2, Col3)
VALUES
('X1', 'Description1', 'A'),
('X2', 'Description2', 'A'),
('X3', 'Description3', 'A');
CREATE OR REPLACE TABLE GenericTable1 (
Col1 INT,
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10),
Col6 VARCHAR(100)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE GenericTable2 (
Col1 VARCHAR(10),
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE GenericTable3 (
Col1 VARCHAR(10),
Col2 VARCHAR(100),
Col3 CHAR(1)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
INSERT INTO GenericTable1 (Col1, Col2, Col3, Col4, Col5, Col6)
VALUES
(1, 'A1', 'B1', 'C1', NULL, NULL),
(2, 'A2', 'B2', 'C2', NULL, NULL),
(3, 'A3', 'B3', 'C3', NULL, NULL);
INSERT INTO GenericTable2 (Col1, Col2, Col3, Col4, Col5)
VALUES
('1', 'A1', 'B1', 'C1', 'X1'),
('2', 'A2', 'B2', 'C2', 'X2'),
('3', 'A3', 'B3', 'C3', 'X3');
INSERT INTO GenericTable3 (Col1, Col2, Col3)
VALUES
('X1', 'Description1', 'A'),
('X2', 'Description2', 'A'),
('X3', 'Description3', 'A');
LEFT JOIN¶
SQL 서버
UPDATE T1
SET
T1.Col5 = T2.Col5,
T1.Col6 = T3.Col2
FROM GenericTable1 T1
LEFT JOIN GenericTable2 T2 ON
T2.Col1 COLLATE SQL_Latin1_General_CP1_CI_AS = T1.Col1
AND T2.Col2 = T1.Col2
AND T2.Col3 = T1.Col3
AND T2.Col4 = T1.Col4
LEFT JOIN GenericTable3 T3 ON
T3.Col1 = T2.Col5 AND T3.Col3 = 'A';
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
| Col1 | Col2 | Col3 | Col4 | Col5 | Col6 |
|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | X1 | Description1 |
| 2 | A2 | B2 | C2 | X2 | Description2 |
| 3 | A3 | B3 | C3 | X3 | Description3 |
Snowflake
UPDATE dbo.GenericTable1 T1
SET
T1.Col5 = T2.Col5,
T1.Col6 = T3.Col2
FROM
GenericTable2 T2,
GenericTable3 T3
WHERE
T2.Col1(+) COLLATE 'EN-CI-AS' /*** SSC-FDM-TS0002 - COLLATION FOR VALUE CP1 NOT SUPPORTED ***/ = T1.Col1
AND T2.Col2(+) = T1.Col2
AND T2.Col3(+) = T1.Col3
AND T2.Col4(+) = T1.Col4
AND T3.Col1(+) = T2.Col5
AND T3.Col3 = 'A';
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
| Col1 | Col2 | Col3 | Col4 | Col5 | Col6 |
|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | X1 | Description1 |
| 2 | A2 | B2 | C2 | X2 | Description2 |
| 3 | A3 | B3 | C3 | X3 | Description3 |
RIGHT JOIN¶
SQL 서버
UPDATE T1
SET
T1.Col5 = T2.Col5
FROM GenericTable2 T2
RIGHT JOIN GenericTable1 T1 ON
T2.Col1 COLLATE SQL_Latin1_General_CP1_CI_AS = T1.Col1
AND T2.Col2 = T1.Col2
AND T2.Col3 = T1.Col3
AND T2.Col4 = T1.Col4;
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
X1 |
null |
2 |
A2 |
B2 |
C2 |
X2 |
null |
3 |
A3 |
B3 |
C3 |
X3 |
null |
Snowflake
UPDATE dbo.GenericTable1 T1
SET
T1.Col5 = T2.Col5
FROM
GenericTable2 T2,
GenericTable1 T1
WHERE
T2.Col1 COLLATE 'EN-CI-AS' /*** SSC-FDM-TS0002 - COLLATION FOR VALUE CP1 NOT SUPPORTED ***/ = T1.Col1
AND T2.Col2 = T1.Col2(+)
AND T2.Col3 = T1.Col3(+)
AND T2.Col4 = T1.Col4(+);
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
X1 |
null |
2 |
A2 |
B2 |
C2 |
X2 |
null |
3 |
A3 |
B3 |
C3 |
X3 |
null |
Known Issues¶
논리의 차이로 인해 변환할 수 없는 패턴이 있을 수 있습니다.
쿼리 패턴이 적용되는 경우 비결정적 행을 검토하십시오. “FROM 절에 테이블 사이(예:
t1및t2)에 JOIN 이 포함된 경우,t1의 대상 행은 테이블t2의 하나 이상의 행에 조인(즉, 일치)될 수 있습니다. 이 경우 대상 행을 _다중 조인 행_이라고 합니다. 다중 조인 행을 업데이트할 때 ERROR_ON_NONDETERMINISTIC_UPDATE 세션 매개 변수는 업데이트 결과를 제어합니다” (Snowflake 설명서).