SnowConvert: Transact DMLs¶
Between¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
ソースコード
-- Additional Params: -t JavaScript
CREATE PROCEDURE ProcBetween
AS
BEGIN
declare @aValue int = 1;
IF(@aValue BETWEEN 1 AND 2)
return 1
END;
GO
期待されるコード
CREATE OR REPLACE PROCEDURE ProcBetween ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
let AVALUE = 1;
if (SELECT(` ? BETWEEN 1 AND 2`,[AVALUE])) {
return 1;
}
$$;
既知の問題¶
問題は見つかりませんでした。
Bulk Insert¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
BULK INSERT の直訳はSnowflake COPY INTO ステートメントです。COPY INTO は、値を取得するためにファイルパスを直接使用しません。ファイルは STAGE 内に事前に存在している必要があります。また、 BULK INSERT で使用されるオプションは、 STAGE で消費される、または直接 COPY INTO で消費されるSnowflake FILE FORMAT で指定する必要があります。
STAGE にファイルを追加するには、 PUT コマンドを使用します。コマンドは SnowSQL CLI からのみ実行できることに注意してください。以下は、 COPY INTO を実行する前に行うべきステップの例です。
-- Additional Params: -t JavaScript
CREATE PROCEDURE PROCEDURE_SAMPLE
AS
CREATE TABLE #temptable
([col1] varchar(100),
[col2] int,
[col3] varchar(100))
BULK INSERT #temptable FROM 'C:\test.txt'
WITH
(
FIELDTERMINATOR ='\t',
ROWTERMINATOR ='\n'
);
GO
CREATE OR REPLACE FILE FORMAT FILE_FORMAT_638434968243607970
FIELD_DELIMITER = '\t'
RECORD_DELIMITER = '\n';
CREATE OR REPLACE STAGE STAGE_638434968243607970
FILE_FORMAT = FILE_FORMAT_638434968243607970;
--** SSC-FDM-TS0004 - PUT STATEMENT IS NOT SUPPORTED ON WEB UI. YOU SHOULD EXECUTE THE CODE THROUGH THE SNOWFLAKE CLI **
PUT file://C:\test.txt @STAGE_638434968243607970 AUTO_COMPRESS = FALSE;
CREATE OR REPLACE PROCEDURE PROCEDURE_SAMPLE ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
EXEC(`CREATE OR REPLACE TEMPORARY TABLE T_temptable
(
col1 VARCHAR(100),
col2 INT,
col3 VARCHAR(100))`);
EXEC(`COPY INTO T_temptable FROM @STAGE_638434968243607970/test.txt`);
$$
上のコードにあるように、 SnowConvert はコード内のすべての BULK INSERTS を識別し、各インスタンスごとに、コピー実行前に新しい STAGE と FILE FORMAT が作成されます。また、 STAGE の作成後、ステージにファイルを追加するため、 PUT コマンドも作成されます。
生成されるステートメントの名前は、使用間の衝突を避けるために、秒単位の現在のタイムスタンプを使用して自動生成されます。
最後に、一括挿入のすべてのオプションは、該当する場合、ファイル形式オプションにマッピングされています。オプションがSnowflakeでサポートされていない場合は、コメントされ、警告が追加されます。SSC-FDM-TS0004も参照してください。
サポートされている一括オプション¶
SQL Server |
Snowflake |
|---|---|
FORMAT |
TYPE |
FIELDTERMINATOR |
FIELD_DELIMITER |
FIRSTROW |
SKIP_HEADER |
ROWTERMINATOR |
RECORD_DELIMITER |
FIELDQUOTE |
FIELD_OPTIONALLY_ENCLOSED_BY |
関連 EWIs¶
SSC-FDM-TS0004: PUT STATEMENT IS NOT SUPPORTED ON WEB UI.
共通テーブル式(CTE)¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
Snowflake SQL では、共通テーブル式がデフォルトでサポートされています。
Snowflake SQL 構文¶
サブクエリ:
[ WITH
<cte_name1> [ ( <cte_column_list> ) ] AS ( SELECT ... )
[ , <cte_name2> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
[ , <cte_nameN> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
]
SELECT ...
再帰的 CTE:
[ WITH [ RECURSIVE ]
<cte_name1> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause )
[ , <cte_name2> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause ) ]
[ , <cte_nameN> ( <cte_column_list> ) AS ( anchorClause UNION ALL recursiveClause ) ]
]
SELECT ...
条件:
anchorClause ::=
SELECT <anchor_column_list> FROM ...
recursiveClause ::=
SELECT <recursive_column_list> FROM ... [ JOIN ... ]
注目すべき詳細¶
RECURSIVE キーワードはT-SQL には存在せず、変換はそのキーワードを結果に積極的に追加しません。この動作を明記するため、出力コードに警告が追加されます。
SELECT INTO を用いた共通テーブル式¶
WITH 式の後に SELECT INTO ステートメントが続くと、次の変換が発生し、 TEMPORARY TABLE に変換されます。
SQL Server:
WITH ctetable(col1, col2) AS
(
SELECT col1, col2 FROM t1 poh WHERE poh.col1 = 16 and poh.col2 = 4
),
employeeCte AS
(
SELECT BUSINESSENTITYID, VACATIONHOURS FROM employee WHERE BUSINESSENTITYID = (SELECT col1 FROM ctetable)
),
finalCte AS
(
SELECT BUSINESSENTITYID, VACATIONHOURS FROM employeeCte
) SELECT * INTO #table2 FROM finalCte;
SELECT * FROM #table2;
Snowflake:
CREATE OR REPLACE TEMPORARY TABLE T_table2 AS
WITH ctetable (
col1,
col2
) AS
(
SELECT
col1,
col2
FROM
t1 poh
WHERE
poh.col1 = 16 and poh.col2 = 4
),
employeeCte AS
(
SELECT
BUSINESSENTITYID,
VACATIONHOURS
FROM
employee
WHERE
BUSINESSENTITYID = (SELECT
col1
FROM
ctetable
)
),
finalCte AS
(
SELECT
BUSINESSENTITYID,
VACATIONHOURS
FROM
employeeCte
)
SELECT
*
FROM
finalCte;
SELECT
*
FROM
T_table2;
他の式との共通テーブル式¶
WITH 式の後に INSERT または DELETE ステートメントが続くと、以下の変換が行われます。
SQL Server:
WITH CTE AS( SELECT * from table1)
INSERT INTO Table2 (a,b,c,d)
SELECT a,b,c,d
FROM CTE
WHERE e IS NOT NULL;
Snowflake:
INSERT INTO Table2 (a, b, c, d)
WITH CTE AS( SELECT
*
from
table1
)
SELECT
a,
b,
c,
d
FROM
CTE AS CTE
WHERE
e IS NOT NULL;
Delete Fromを使用した共通テーブル式¶
この変換では、Delete Fromを持つ CTE (共通テーブル式)に対してのみ適用されますが、一部の仕様 CTE に対してのみ適用されます。CTE を1つだけ持ち、 ROW_NUMBER または RANK の関数を内部に持たなければなりません。
Deleteを使った CTE の目的は、テーブルから重複を削除することでなければなりません。Deleteを使った CTE が別の種類のデータを削除することを意図している場合、この変換は適用されません。
例を見てみましょう。例として、まずデータの入ったテーブルを作成します。
CREATE TABLE WithQueryTest
(
ID BIGINT,
Value BIGINT,
StringValue NVARCHAR(258)
);
Insert into WithQueryTest values(100, 100, 'First');
Insert into WithQueryTest values(200, 200, 'Second');
Insert into WithQueryTest values(300, 300, 'Third');
Insert into WithQueryTest values(400, 400, 'Fourth');
Insert into WithQueryTest values(100, 100, 'First');
値が重複していることに注意してください。8行目と12行目には同じ値が挿入されています。では、テーブルの重複行を削除します。
WITH Duplicated AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY ID ORDER BY ID) AS RN
FROM WithQueryTest
)
DELETE FROM Duplicated
WHERE Duplicated.RN > 1
テーブルからSelectを実行すると、次のような結果が表示されます
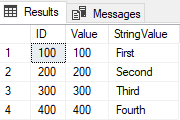
重複行がないことに注意してください。SnowflakeのDeleteでこれらの CTE の機能を保存するために、次のように変換されます
CREATE OR REPLACE TABLE PUBLIC.WithQueryTest AS SELECT
*
FROM PUBLIC.WithQueryTest
QUALIFY ROW_NUMBER()
OVER (PARTITION BY ID ORDER BY ID) = 1 ;
ご覧のように、クエリはCreate Or Replace Tableに変換されます。
Snowflakeで試してみましょう。テストするにはテーブルも必要です。
CREATE OR REPLACE TABLE PUBLIC.WithQueryTest
(
ID BIGINT,
Value BIGINT,
StringValue VARCHAR(258)
);
Insert into PUBLIC.WithQueryTest values(100, 100, 'First');
Insert into PUBLIC.WithQueryTest values(200, 200, 'Second');
Insert into PUBLIC.WithQueryTest values(300, 300, 'Third');
Insert into PUBLIC.WithQueryTest values(400, 400, 'Fourth');
Insert into PUBLIC.WithQueryTest values(100, 100, 'First');
ここで、変換の結果を実行し、重複行が削除されたかどうかをチェックするためにSelectを実行すると、このようになります。
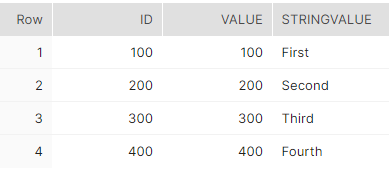
MERGE ステートメントを使用した共通テーブル式¶
WITH 式の後に MERGE ステートメントが続くと、次の変換が発生し、 MERGE INTO に変換されます。
SQL Server:
WITH ctetable(col1, col2) as
(
SELECT col1, col2
FROM t1 poh
where poh.col1 = 16 and poh.col2 = 88
),
finalCte As
(
SELECT col1 FROM ctetable
)
MERGE
table1 AS target
USING finalCte AS source
ON (target.ID = source.COL1)
WHEN MATCHED THEN UPDATE SET target.ID = source.Col1
WHEN NOT MATCHED THEN INSERT (ID, col1) VALUES (source.COL1, source.COL1 );
Snowflake:
MERGE INTO table1 AS target
USING (
--** SSC-PRF-TS0001 - PERFORMANCE WARNING - RECURSION FOR CTE NOT CHECKED. MIGHT REQUIRE RECURSIVE KEYWORD **
WITH ctetable (
col1,
col2
) as
(
SELECT
col1,
col2
FROM
t1 poh
where
poh.col1 = 16 and poh.col2 = 88
),
finalCte As
(
SELECT
col1
FROM
ctetable
)
SELECT
*
FROM
finalCte
) AS source
ON (target.ID = source.COL1)
WHEN MATCHED THEN
UPDATE SET
target.ID = source.Col1
WHEN NOT MATCHED THEN
INSERT (ID, col1) VALUES (source.COL1, source.COL1);
UPDATE ステートメントを使用した共通テーブル式¶
WITH 式の後に UPDATE ステートメントが続くと、次の変換が発生し、 UPDATE ステートメントに変換されます。
SQL Server:
WITH ctetable(col1, col2) AS
(
SELECT col1, col2
FROM table2 poh
WHERE poh.col1 = 5 and poh.col2 = 4
)
UPDATE tab1
SET ID = 8, COL1 = 8
FROM table1 tab1
INNER JOIN ctetable CTE ON tab1.ID = CTE.col1;
Snowflake:
UPDATE dbo.table1 tab1
SET
ID = 8,
COL1 = 8
FROM
(
WITH ctetable (
col1,
col2
) AS
(
SELECT
col1,
col2
FROM
table2 poh
WHERE
poh.col1 = 5 and poh.col2 = 4
)
SELECT
*
FROM
ctetable
) AS CTE
WHERE
tab1.ID = CTE.col1;
既知の問題¶
問題は見つかりませんでした。
関連 EWIs¶
SSC-EWI-0108: 以下のサブクエリは無効なパターンの少なくとも1つにマッチし、コンパイルエラーが発生する可能性があります。
SSC-PRF-TS0001: パフォーマンスの警告 - CTE の再帰がチェックされていません。再帰キーワードが必要になるかもしれません。
削除¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
説明¶
SQL Serverのテーブルまたはビューから1つ以上の行を削除します。SQL Server Deleteに関する詳細情報は、 こちら をご覧ください。
[ WITH <common_table_expression> [ ,...n ] ]
DELETE
[ TOP ( expression ) [ PERCENT ] ]
[ FROM ]
{ { table_alias
| <object>
| rowset_function_limited
[ WITH ( table_hint_limited [ ...n ] ) ] }
| @table_variable
}
[ <OUTPUT Clause> ]
[ FROM table_source [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <Query Hint> [ ,...n ] ) ]
[; ]
<object> ::=
{
[ server_name.database_name.schema_name.
| database_name. [ schema_name ] .
| schema_name.
]
table_or_view_name
}
サンプルソースパターン¶
DELETE ステートメントの変換は、いくつかの注意点を除き、非常に簡単です。これらの注意点の1つは、Snowflakeが FROM 句で複数のソースをサポートする方法ですが、Snowflakeには以下のように同等のものがあります。
SQL Server
DELETE T1 FROM TABLE2 T2, TABLE1 T1 WHERE T1.ID = T2.ID
Snowflake
DELETE FROM
TABLE1 T1
USING TABLE2 T2
WHERE
T1.ID = T2.ID;
注釈
元の DELETE はT1用であったため、 FROM 句に TABLE2 T2が存在する場合は、 USING 句を作成する必要があることに注意してください。
¶
テーブルから重複を削除¶
以下のドキュメントでは、 SQL Serverのテーブルから重複行を削除するために使用される一般的なパターン を説明します。このアプローチでは、 ROW_NUMBER 関数を使用して、 key_value (コンマで区切られた1つまたは複数の列)に基づいてデータを分割します。次に、行番号の値が1より大きい記録をすべて削除します。この値は記録が重複していることを示します。参照されたドキュメントを読んで、このメソッドの動作を理解し、再現することができます。
DELETE T
FROM
(
SELECT *
, DupRank = ROW_NUMBER() OVER (
PARTITION BY key_value
ORDER BY ( {expression} )
)
FROM original_table
) AS T
WHERE DupRank > 1
次の例では、この方法を使用して、Snowflakeのテーブルと同等のものから重複を削除します。変換は、テーブルを切り捨て(すべてのデータを削除)、重複した行を無視して同じテーブルに再度行を挿入する INSERT OVERWRITE ステートメントの実行で構成されます。出力コードは、元のコードで使用されたのと同じ PARTITION BY、 ORDER BY 句を考慮して生成されます。
SQL Server
重複行を含むテーブルの作成
create table duplicatedRows(
someID int,
col2 bit,
col3 bit,
col4 bit,
col5 bit
);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(11, 1, 1, 0, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(13, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
14 | true | false | true | false |
重複行の削除
DELETE f FROM (
select someID, row_number() over (
partition by someID, col2
order by
case when COL3 = 1 then 1 else 0 end
+ case when col4 = 1 then 1 else 0 end
+ case when col5 = 1 then 1 else 0 end
asc
) as rownum
from
duplicatedRows
) f where f.rownum > 1;
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
Snowflake
重複行を含むテーブルの作成
create table duplicatedRows(
someID int,
col2 BOOLEAN,
col3 BOOLEAN,
col4 BOOLEAN,
col5 BOOLEAN
);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(10, 1, 0, 0, 1);
insert into duplicatedRows VALUES(11, 1, 1, 0, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(12, 0, 0, 1, 1);
insert into duplicatedRows VALUES(13, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
insert into duplicatedRows VALUES(14, 1, 0, 1, 0);
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
14 | true | false | true | false |
重複行の削除
insert overwrite into duplicatedRows
SELECT
*
FROM
duplicatedRows
QUALIFY
ROW_NUMBER()
over
(partition by someID, col2
order by
case when COL3 = 1 then 1 else 0 end
+ case when col4 = 1 then 1 else 0 end
+ case when col5 = 1 then 1 else 0 end
asc) = 1;
select * from duplicatedRows;
someID | col2 | col3 | col4 | col5 |
10 | true | false | false | true |
11 | true | true | false | true |
12 | false | false | true | true |
13 | true | false | true | false |
14 | true | false | true | false |
警告
このパターンにはいくつかのバリエーションがあるかもしれませんが、どれも同じ原理に基づいており、同じ構造を持っていると考えてください。
既知の問題¶
問題は見つかりませんでした。
関連 EWIs¶
関連 EWIs はありません。
ドロップ¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
DROP TABLE¶
Transact-SQL の構文¶
DROP TABLE [ IF EXISTS ] <table_name> [ ,...n ]
[ ; ]
Snowflakeの構文¶
DROP TABLE [ IF EXISTS ] <name> [ CASCADE | RESTRICT ]
翻訳¶
単一の DROP TABLE ステートメントの翻訳は非常に簡単です。ステートメント内でドロップされるテーブルが1つだけである限り、そのままにしておきます。
例:
DROP TABLE IF EXISTS [table_name]
DROP TABLE IF EXISTS table_name;
SQL ServerとSnowflakeで注目すべき唯一の違いは、入力ステートメントが複数のテーブルをドロップする場合に現れます。これらのシナリオでは、ドロップされるテーブルごとに異なる DROP TABLE ステートメントが作成されます。
例:
DROP TABLE IF EXISTS [table_name], [table_name2], [table_name3]
DROP TABLE IF EXISTS table_name;
DROP TABLE IF EXISTS table_name2;
DROP TABLE IF EXISTS table_name3;
既知の問題¶
問題は見つかりませんでした。
関連 EWIs ¶
関連 EWIs はありません。
存在する¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
サブクエリのタイプ¶
サブクエリは、相関するものと相関しないものに分類できます。
相関サブクエリは、サブクエリの外部からの1つ以上の列を参照します。(通常、列はサブクエリの WHERE 句内で参照されます。)相関サブクエリは、外部クエリ内のテーブルの各行でサブクエリが評価されたかのように、それが参照するテーブルのフィルターと考えることができます。
非相関サブクエリには、そのような外部列参照はありません。これは独立したクエリであり、その結果は(行ごとではなく)外部のクエリに一度返されて使用されます。
EXISTS ステートメントは相関サブクエリとみなされます。
ソースコード
-- Additional Params: -t JavaScript
CREATE PROCEDURE ProcExists
AS
BEGIN
IF(EXISTS(Select AValue from ATable))
return 1;
END;
期待されるコード
CREATE OR REPLACE PROCEDURE ProcExists ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
if (SELECT(` EXISTS(Select
AValue
from
ATable
)`)) {
return 1;
}
$$;
既知の問題¶
問題は見つかりませんでした。
関連 EWIs ¶
関連 EWIs はありません。
IN¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
IN 演算子は、ある式がサブクエリの返す値に含まれるかどうかを調べます。
ソースコード
-- Additional Params: -t JavaScript
CREATE PROCEDURE dbo.SP_IN_EXAMPLE
AS
DECLARE @results as VARCHAR(50);
SELECT @results = COUNT(*) FROM TABLE1
IF @results IN (1,2,3)
SELECT 'is IN';
ELSE
SELECT 'is NOT IN';
return
GO
-- =============================================
-- Example to execute the stored procedure
-- =============================================
EXECUTE dbo.SP_IN_EXAMPLE
GO
期待されるコード
CREATE OR REPLACE PROCEDURE dbo.SP_IN_EXAMPLE ()
RETURNS STRING
LANGUAGE JAVASCRIPT
COMMENT = '{"origin":"sf_sc","name":"snowconvert","version":{"major":1, "minor":0},"attributes":{"component":"transact"}}'
EXECUTE AS CALLER
AS
$$
// SnowConvert Helpers Code section is omitted.
let RESULTS;
SELECT(` COUNT(*) FROM
TABLE1`,[],(value) => RESULTS = value);
if ([1,2,3].includes(RESULTS)) {
} else {
}
return;
$$;
-- =============================================
-- Example to execute the stored procedure
-- =============================================
CALL dbo.SP_IN_EXAMPLE();
既知の問題¶
問題は見つかりませんでした。
関連 EWIs ¶
関連 EWIs はありません。
挿入¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
説明¶
SQL Serverのテーブルまたはビューに1つ以上の行を追加します。SQL Server Insertに関する詳細情報は、 こちら をご覧ください。
構文比較¶
基本的な挿入文法は、 SQL 両言語間で同等です。ただし、 SQL Serverには違いを示す他の構文要素がまだいくつかあります。たとえば、開発者が割り当て演算子を使用して列に値を追加できる構文要素があります。この構文も基本的な挿入構文に変換されます。
Snowflake
INSERT [ OVERWRITE ] INTO <target_table> [ ( <target_col_name> [ , ... ] ) ]
{
VALUES ( { <value> | DEFAULT | NULL } [ , ... ] ) [ , ( ... ) ] |
<query>
}
SQL Server
[ WITH <common_table_expression> [ ,...n ] ]
INSERT
{
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ]
{ <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
{
[ ( column_list ) ]
[ <OUTPUT Clause> ]
{ VALUES ( { DEFAULT | NULL | expression } [ ,...n ] ) [ ,...n ]
| derived_table
| execute_statement
| <dml_table_source>
| DEFAULT VALUES
}
}
}
[;]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name
}
<dml_table_source> ::=
SELECT <select_list>
FROM ( <dml_statement_with_output_clause> )
[AS] table_alias [ ( column_alias [ ,...n ] ) ]
[ WHERE <search_condition> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
サンプルソースパターン¶
基本的な INSERT¶
SQL Server¶
INSERT INTO TABLE1 VALUES (1, 2, 123, 'LiteralValue');
Snowflake¶
INSERT INTO TABLE1 VALUES (1, 2, 123, 'LiteralValue');
割り当て演算子を含む INSERT¶
SQL Server¶
INSERT INTO aTable (columnA = 'varcharValue', columnB = 1);
Snowflake¶
INSERT INTO aTable (columnA = 'varcharValue', columnB = 1);
INTO を含まない INSERT¶
SQL Server¶
INSERT exampleTable VALUES ('Hello', 23);
Snowflake¶
INSERT INTO exampleTable VALUES ('Hello', 23);
共通テーブル式を含む INSERT¶
SQL Server¶
WITH ctevalues (textCol, numCol) AS (SELECT 'cte string', 155)
INSERT INTO exampleTable SELECT * FROM ctevalues;
Snowflake¶
INSERT INTO exampleTable
WITH ctevalues (
textCol,
numCol
) AS (SELECT 'cte string', 155)
SELECT
*
FROM
ctevalues AS ctevalues;
MERGE を DML としてテーブル DML 要因を含む INSERT¶
このケースは非常に特殊で、 INSERT ステートメントに SELECT クエリがあり、言及された SELECT の FROM 句に MERGE DML ステートメントが含まれています。Snowflakeで同等のステートメントを探すと、次のステートメントが作成されます: 仮テーブル、 変換されたmergeステートメント、最後に挿入ステートメント。
SQL Server¶
INSERT INTO T3
SELECT
col1,
col2
FROM (
MERGE T1 USING T2
ON T1.col1 = T2.col1
WHEN NOT MATCHED THEN
INSERT VALUES ( T2.col1, T2.col2 )
WHEN MATCHED THEN
UPDATE SET T1.col2 = t2.col2
OUTPUT
$action ACTION_OUT,
T2.col1,
T2.col2
) AS MERGE_OUT
WHERE ACTION_OUT='UPDATE';
Snowflake¶
--** SSC-FDM-TS0026 - DELETE CASE IS NOT BEING CONSIDERED, PLEASE CHECK IF THE ORIGINAL MERGE PERFORMS IT **
CREATE OR REPLACE TEMPORARY TABLE MERGE_OUT AS
SELECT
CASE WHEN T1.$1 IS NULL THEN 'INSERT' ELSE 'UPDATE' END ACTION_OUT,
T2.col1,
T2.col2
FROM T2 LEFT JOIN T1 ON T1.col1 = T2.col1;
MERGE INTO T1
USING T2
ON T1.col1 = T2.col1
WHEN NOT MATCHED THEN INSERT VALUES (T2.col1, T2.col2)
WHEN MATCHED THEN UPDATE SET T1.col2 = t2.col2
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT
$action ACTION_OUT,
T2.col1,
T2.col2 ;
INSERT INTO T3
SELECT col1, col2
FROM MERGE_OUT
WHERE ACTION_OUT ='UPDATE';
警告
NOTE: パターンの名前が示すように、挿入にselect...fromが付属し、その本体に MERGE ステートメントが含まれている場合 ONLY です。
既知の問題¶
1.特別なマッピングを必要とする構文要素:
[INTO]: このキーワードはSnowflakeでは必須なので、存在しない場合は追加してください。
[DEFAULT VALUES]: 挿入で指定されたすべての列にデフォルト値を挿入します。VALUES (DEFAULT、 DEFAULT、...)に変換する必要があります。 DEFAULTs の追加量は、挿入によって変更される列の数に等しくなります。今のところ、警告が追加されています。
SQL Server
INSERT INTO exampleTable DEFAULT VALUES;
#### Snowflake
!!!RESOLVE EWI!!! /*** SSC-EWI-0073 - PENDING FUNCTIONAL EQUIVALENCE REVIEW FOR 'INSERT WITH DEFAULT VALUES' NODE ***/!!!
INSERT INTO exampleTable DEFAULT VALUES;
2.構文要素がサポートされていないか、無関係です。
[TOP (expression) [PERCENT]]: 挿入される行の量またはパーセントを示します。サポート対象外です。
[rowset_function_limited]: OPENQUERY()または OPENROWSET()で、リモートサーバーからデータを読み込むために使用されます。サポート対象外です。
[WITH table_hint_limited]:テーブルの読み書きロックを取得するために使用されます。Snowflakeでは関係ありません。
[<OUTPUT Clause>]: 挿入された行も挿入されるテーブルまたは結果セットを指定します。サポート対象外です。
[execute_statement]: データを取得するクエリの実行に使用できます。サポート対象外です。
[dml_table_source]: 別の DML ステートメントの OUTPUT 句によって生成された仮結果セット。サポート対象外です。
3.DELETE ケースは考慮されていません。
MERGE を DML としてテーブル DML 要因を含む INSERT パターンの場合、ソリューションでは DELETE ケースが考慮されていないため、ソースコードのmergeステートメントに DELETE ケースがある場合は、期待どおりに動作しない可能性があることを考慮してください。
関連 EWIs¶
SSC-EWI-0073: 機能同等性レビュー保留中。
SSC-FDM-TS0026: DELETE ケースは考慮されていません。
マージ¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
構文比較¶
Snowflake SQL 構文:
MERGE
INTO <target_table>
USING <source>
ON <join_expr>
{ matchedClause | notMatchedClause } [ ... ]
Transact-SQL 構文:
-- SQL Server and Azure SQL Database
[ WITH <common_table_expression> [,...n] ]
MERGE
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ] <target_table> [ WITH ( <merge_hint> ) ] [ [ AS ] table_alias ]
USING <table_source> [ [ AS ] table_alias ]
ON <merge_search_condition>
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ <output_clause> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
;
例¶
次のようなソースコードがあるとします。
MERGE
INTO
targetTable WITH(KEEPIDENTITY, KEEPDEFAULTS, HOLDLOCK, IGNORE_CONSTRAINTS, IGNORE_TRIGGERS, NOLOCK, INDEX(value1, value2, value3)) as tableAlias
USING
tableSource AS tableAlias2
ON
mergeSetCondition > mergeSetCondition
WHEN MATCHED BY TARGET AND pi.Quantity - src.OrderQty >= 0
THEN UPDATE SET pi.Quantity = pi.Quantity - src.OrderQty
OUTPUT $action, DELETED.v AS DELETED, INSERTED.v INSERTED INTO @localVar(col, list)
OPTION(RECOMPILE);
次のような結果が得られると予想されます。
MERGE INTO targetTable as tableAlias
USING tableSource AS tableAlias2
ON mergeSetCondition > mergeSetCondition
WHEN MATCHED AND pi.Quantity - src.OrderQty >= 0 THEN
UPDATE SET
pi.Quantity = pi.Quantity - src.OrderQty
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT $action, DELETED.v AS DELETED, INSERTED.v INSERTED INTO @localVar(col, list);
関連 EWIs¶
SSC-EWI-0021: 構文がSnowflakeでサポートされていません。
選択¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
説明¶
SQL Serverの1つまたは複数のテーブルの1つまたは複数の行または列を選択できるようにします。
SQL Server Selectに関する詳細情報は、 こちら をご覧ください。
<SELECT statement> ::=
[ WITH { [ XMLNAMESPACES ,] [ <common_table_expression> [,...n] ] } ]
<query_expression>
[ ORDER BY <order_by_expression> ]
[ <FOR Clause>]
[ OPTION ( <query_hint> [ ,...n ] ) ]
<query_expression> ::=
{ <query_specification> | ( <query_expression> ) }
[ { UNION [ ALL ] | EXCEPT | INTERSECT }
<query_specification> | ( <query_expression> ) [...n ] ]
<query_specification> ::=
SELECT [ ALL | DISTINCT ]
[TOP ( expression ) [PERCENT] [ WITH TIES ] ]
< select_list >
[ INTO new_table ]
[ FROM { <table_source> } [ ,...n ] ]
[ WHERE <search_condition> ]
[ <GROUP BY> ]
[ HAVING < search_condition > ]
サンプルソースパターン¶
SELECT WITH COLUMN ALIASES¶
次の例は、Snowflakeで列エイリアスを使用する方法を示しています。最初の2列は、 SQL Serverコードから、 AS キーワードを使用して、割り当て形式から正規化形式に変換されることが期待されます。3列目と4列目は有効なSnowflake形式を使用しています。
SQL Server
SELECT
MyCol1Alias = COL1,
MyCol2Alias = COL2,
COL3 AS MyCol3Alias,
COL4 MyCol4Alias
FROM TABLE1;
Snowflake
SELECT
COL1 AS MyCol1Alias,
COL2 AS MyCol2Alias,
COL3 AS MyCol3Alias,
COL4 MyCol4Alias
FROM
TABLE1;
SELECT TOP¶
SQL Server Select Topの基本的なケースはSnowflakeでサポートされています。ただし、サポートされていないケースがさらに3つ存在しますので、既知の問題セクションで確認してください。
SQL Server
SELECT TOP 1 * from ATable;
Snowflake
SELECT TOP 1
*
from
ATable;
SELECT INTO¶
次の例では、 SELECT INTO が CREATE TABLE AS に変換されています。これは、Snowflakeには SELECT INTO に相当するものがなく、クエリに基づいてテーブルを作成するには CREATE TABLE AS を使用する必要があるためです。
SQL Server
SELECT * INTO NEWTABLE FROM TABLE1;
Snowflake
CREATE OR REPLACE TABLE NEWTABLE AS
SELECT
*
FROM
TABLE1;
もう一つのケースは、 EXCEPT や INTERSECT のようなセット演算子を含む場合です。変換は基本的に前回と同じです。
SQL Server
SELECT * INTO NEWTABLE FROM TABLE1
EXCEPT
SELECT * FROM TABLE2
INTERSECT
SELECT * FROM TABLE3;
Snowflake
CREATE OR REPLACE TABLE NEWTABLE AS
SELECT
*
FROM
TABLE1
EXCEPT
SELECT
*
FROM
TABLE2
INTERSECT
SELECT
*
FROM
TABLE3;
既知の問題¶
SELECT TOP 追加引数¶
PERCENT および WITH TIES キーワードは結果に影響し、Snowflakeではサポートされていないため、コメントアウトされ、エラーとして追加されます。
SQL Server
SELECT TOP 1 PERCENT * from ATable;
SELECT TOP 1 WITH TIES * from ATable;
SELECT TOP 1 PERCENT WITH TIES * from ATable;
Snowflake
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT
TOP 1 !!!RESOLVE EWI!!! /*** SSC-EWI-0040 - THE STATEMENT IS NOT SUPPORTED IN SNOWFLAKE ***/!!!
*
from
ATable;
SELECT FOR¶
Snowflakeでは FOR 句はサポートされていないため、コメントアウトされ、変換時にエラーとして追加されます。
SQL Server
SELECT column1, column2 FROM my_table FOR XML PATH('');
Snowflake
SELECT
--** SSC-FDM-TS0016 - XML COLUMNS IN SNOWFLAKE MIGHT HAVE A DIFFERENT FORMAT **
FOR_XML_UDF(OBJECT_CONSTRUCT('column1', column1, 'column2', column2), '')
FROM
my_table;
SELECT OPTION¶
OPTION 句はSnowflakeではサポートされていません。これはコメントアウトされ、変換時に警告として追加されます。
警告
OPTION ステートメントは、Snowflakeでは関連性がない、または必要ないため、変換から削除されていることに注意してください。
SQL Server
SELECT column1, column2 FROM my_table OPTION (HASH GROUP, FAST 10);
Snowflake
SELECT
column1,
column2
FROM
my_table;
SELECT WITH¶
WITH 句はSnowflakeではサポートされていません。これはコメントアウトされ、変換時に警告として追加されます。
警告
WITH(NOLOCK, NOWAIT) ステートメントは、Snowflakeでは関連性がない、または必要ないため、変換から削除されていることに注意してください。
SQL Server
SELECT AValue from ATable WITH(NOLOCK, NOWAIT);
Snowflake
SELECT
AValue
from
ATable;
関連 EWIs¶
SSC-EWI-0040: ステートメントがサポートされていません。
SSC-FDM-TS0016: Snowflakeの XML 列は形式が異なるかもしれません
集合演算子¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
TSQL とSnowflakeのセット演算子は、 TSQL でサポートされていない MINUS を除き、同じ構文とサポートされているシナリオ(EXCEPT、 INTERSECT、 UNION、 UNION ALL)を示します。その結果、変換時に同じコードが発生します。
SELECT LastName, FirstName FROM employees
UNION ALL
SELECT FirstName, LastName FROM contractors;
SELECT ...
INTERSECT
SELECT ...
SELECT ...
EXCEPT
SELECT ...
切り捨て¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
ソースコード
TRUNCATE TABLE TABLE1;
翻訳済みコード
TRUNCATE TABLE TABLE1;
関連 EWIs¶
関連 EWIs はありません。
更新¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
注釈
わかりやすくするため、出力コードの一部を省略しています。
説明¶
SQL Serverのテーブルまたはビュー内の既存のデータを変更します。SQL Server Updateに関する詳細情報は、 こちら をご覧ください。
[ WITH <common_table_expression> [...n] ]
UPDATE
[ TOP ( expression ) [ PERCENT ] ]
{ { table_alias | <object> | rowset_function_limited
[ WITH ( <Table_Hint_Limited> [ ...n ] ) ]
}
| @table_variable
}
SET
{ column_name = { expression | DEFAULT | NULL }
| { udt_column_name.{ { property_name = expression
| field_name = expression }
| method_name ( argument [ ,...n ] )
}
}
| column_name { .WRITE ( expression , @Offset , @Length ) }
| @variable = expression
| @variable = column = expression
| column_name { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable { += | -= | *= | /= | %= | &= | ^= | |= } expression
| @variable = column { += | -= | *= | /= | %= | &= | ^= | |= } expression
} [ ,...n ]
[ <OUTPUT Clause> ]
[ FROM{ <table_source> } [ ,...n ] ]
[ WHERE { <search_condition>
| { [ CURRENT OF
{ { [ GLOBAL ] cursor_name }
| cursor_variable_name
}
]
}
}
]
[ OPTION ( <query_hint> [ ,...n ] ) ]
[ ; ]
<object> ::=
{
[ server_name . database_name . schema_name .
| database_name .[ schema_name ] .
| schema_name .
]
table_or_view_name}
サンプルソースパターン¶
基本的な UPDATE¶
通常の UPDATE ステートメントへの変換は非常に簡単です。基本的な UPDATE 構造はSnowflakeでデフォルトでサポートされているため、外れ値は違いが見られる部分であり、既知の問題のセクションで確認してください。
SQL Server¶
Update UpdateTest1
Set Col1 = 5;
Snowflake
Update UpdateTest1
Set
Col1 = 5;
デカルト積¶
SQL Serverは、Updateステートメントのターゲットテーブルと FROM 句の間の循環参照の追加を許可します。実行時に、データベースオプティマイザーは、生成されたデカルト積を削除します。そうでなければ、Snowflakeは現在このシナリオを最適化せず、実行計画でチェックできるデカルト積を生成します。\
これを解決するには、テーブルの1つが更新ターゲットと同じである JOIN がある場合、この参照が削除されて WHERE 句に追加され、データのフィルター処理のみが行われ、セット操作が行われないようにするために使用されます。
SQL Server¶
UPDATE [HumanResources].[EMPLOYEEDEPARTMENTHISTORY_COPY]
SET
BusinessEntityID = b.BusinessEntityID ,
DepartmentID = b.DepartmentID,
ShiftID = b.ShiftID,
StartDate = b.StartDate,
EndDate = b.EndDate,
ModifiedDate = b.ModifiedDate
FROM [HumanResources].[EMPLOYEEDEPARTMENTHISTORY_COPY] AS a
RIGHT OUTER JOIN [HumanResources].[EmployeeDepartmentHistory] AS b
ON a.BusinessEntityID = b.BusinessEntityID and a.ShiftID = b.ShiftID;
Snowflake
UPDATE HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY a
SET
BusinessEntityID = b.BusinessEntityID,
DepartmentID = b.DepartmentID,
ShiftID = b.ShiftID,
StartDate = b.StartDate,
EndDate = b.EndDate,
ModifiedDate = b.ModifiedDate
FROM
HumanResources.EmployeeDepartmentHistory AS b
WHERE
HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY.BusinessEntityID = b.BusinessEntityID(+)
AND HumanResources.EMPLOYEEDEPARTMENTHISTORY_COPY.ShiftID = b.ShiftID(+);
既知の問題¶
OUTPUT 句¶
OUTPUT 句はSnowflakeではサポートされていません。
SQL Server¶
Update UpdateTest2
Set Col1 = 5
OUTPUT
deleted.Col1,
inserted.Col1
into ValuesTest;
Snowflake
Update UpdateTest2
Set
Col1 = 5
!!!RESOLVE EWI!!! /*** SSC-EWI-0021 - OUTPUT CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
OUTPUT
deleted.Col1,
inserted.Col1
into ValuesTest;
CTE¶
WITH CTE 句は、Snowflakeでサポートされるようにupdateステートメントの内部クエリに移動されます。
SQL Server¶
With ut as (select * from UpdateTest3)
Update x
Set Col1 = 5
from ut as x;
Snowflake
UPDATE UpdateTest3
Set
Col1 = 5
FROM
(
WITH ut as (select
*
from
UpdateTest3
)
SELECT
*
FROM
ut
) AS x;
TOP 句¶
TOP 句はSnowflakeではサポートされていません。
SQL Server¶
Update TOP(10) UpdateTest4
Set Col1 = 5;
Snowflake
Update
-- !!!RESOLVE EWI!!! /*** SSC-EWI-0021 - TOP CLAUSE NOT SUPPORTED IN SNOWFLAKE ***/!!!
-- TOP(10)
UpdateTest4
Set
Col1 = 5;
WITH TABLE HINT LIMITED¶
Update WITH 句はSnowflakeではサポートされていません。
SQL Server¶
Update UpdateTest5 WITH(TABLOCK)
Set Col1 = 5;
Snowflake
Update UpdateTest5
Set
Col1 = 5;
関連 EWIs¶
SSC-EWI-0021: 構文がSnowflakeでサポートされていません。
JOIN を含む UPDATE の代替案¶
これは進行中の作業であり、将来変更される可能性があります。
Description
パターン UPDATE FROM は、他のテーブルのデータに基づいてデータを更新するために使用されます。この SQLServer ドキュメント では、単純なサンプルを提供しています。
ドキュメント にある以下の SQL Server構文を確認してください。
SQL Server構文
UPDATE [table_name]
SET column_name = expression [, ...]
[FROM <table_source> [, ...]]
[WHERE <search_condition>]
[OPTION (query_hint)]
table_name: 更新するテーブルまたはビュー。SET: 列とその新しい値を指定します。SET句は、1つ以上の列に新しい値(または式)を割り当てます。FROM: 1つ以上のソーステーブルを指定するために使用されます(_ join のように)_。これは、更新を実行するためのデータの出所を定義するのに役立ちます。WHERE: 条件に基づいて更新する行を指定します。この句がなければ、テーブルのすべての行が更新されます。OPTION (query_hint): クエリ最適化のためのヒントを指定します。
Snowflake構文
Snowflakeの構文は Snowflakeドキュメント でも確認できます。
注釈
Snowflakeは UPDATE 句の JOINs をサポートしていません。
UPDATE <target_table>
SET <col_name> = <value> [ , <col_name> = <value> , ... ]
[ FROM <additional_tables> ]
[ WHERE <condition> ]
必須パラメーター
_
target_table:_ 更新するテーブルを指定します。_
col_name:_ _target_table_ 内の列の名前を指定します。テーブル名は含めないでください。例えば、UPDATE t1 SET t1.col = 1は無効です。_
value:_ _col_name_ に設定する新しい値を指定します。
オプションのパラメーター
FROM``_additional_tables:_ 更新する行の選択や新しい値のセットに使用する1つ以上のテーブルを指定します。 ターゲットテーブルを繰り返すと自己結合になることに注意してください。WHERE``_条件:_ 更新するターゲットテーブルの行を指定する式。デフォルト:値なし(ターゲットテーブルのすべての行が更新されます)
翻訳概要¶
| SQL Server JOIN type | Snowflake Best Alternative |
|---|---|
Single INNER JOIN | Use the target table in the FROM clause to emulate an INNER JOIN. |
Multiple INNER JOIN | Use the target table in the FROM clause to emulate an INNER JOIN. |
Multiple INNER JOIN + Agregate condition | Use subquery + IN Operation |
Single LEFT JOIN | Use subquery + IN Operation |
Multiple LEFT JOIN | Use Snowflake
|
Multiple RIGHT JOIN | Use Snowflake
|
| Single RIGHT JOIN | Use the table in the FROM clause and add filters in the WHERE clause as needed. |
注-1: 単純な JOIN は、 FROM 句でテーブルを使用し、必要に応じて WHERE 句でフィルターを追加することができます。
注-2: 他のアプローチには、 JOINs を定義するための(+)オペランドが含まれる場合があります。
サンプルソースパターン¶
セットアップデータ¶
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
Quantity INT,
OrderDate DATE
);
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
);
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100),
Price DECIMAL(10, 2)
);
CREATE OR REPLACE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
Quantity INT,
OrderDate DATE
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100),
Price DECIMAL(10, 2)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "11/12/2024", "domain": "test" }}'
;
Data Insertion for samples
-- Insert Customer Data
INSERT INTO Customers (CustomerID, CustomerName) VALUES (1, 'John Doe');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (2, 'Jane Smith');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (3, 'Alice Johnson');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (4, 'Bob Lee');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (5, 'Charlie Brown');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (6, 'David White');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (7, 'Eve Black');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (8, 'Grace Green');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (9, 'Hank Blue');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (10, 'Ivy Red');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (11, 'Jack Grey');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (12, 'Kim Yellow');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (13, 'Leo Purple');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (14, 'Mona Pink');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (15, 'Nathan Orange');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (16, 'Olivia Cyan');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (17, 'Paul Violet');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (18, 'Quincy Brown');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (19, 'Rita Silver');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (20, 'Sam Green');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (21, 'Tina Blue');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (22, 'Ursula Red');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (23, 'Vince Yellow');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (24, 'Wendy Black');
INSERT INTO Customers (CustomerID, CustomerName) VALUES (25, 'Xander White');
-- Insert Product Data
INSERT INTO Products (ProductID, ProductName, Price) VALUES (1, 'Laptop', 999.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (2, 'Smartphone', 499.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (3, 'Tablet', 299.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (4, 'Headphones', 149.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (5, 'Monitor', 199.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (6, 'Keyboard', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (7, 'Mouse', 29.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (8, 'Camera', 599.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (9, 'Printer', 99.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (10, 'Speaker', 129.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (11, 'Charger', 29.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (12, 'TV', 699.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (13, 'Smartwatch', 199.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (14, 'Projector', 499.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (15, 'Game Console', 399.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (16, 'Speaker System', 299.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (17, 'Earphones', 89.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (18, 'USB Drive', 15.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (19, 'External Hard Drive', 79.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (20, 'Router', 89.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (21, 'Printer Ink', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (22, 'Flash Drive', 9.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (23, 'Gamepad', 34.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (24, 'Webcam', 49.99);
INSERT INTO Products (ProductID, ProductName, Price) VALUES (25, 'Docking Station', 129.99);
-- Insert Orders Data
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (1, 1, 1, 2, '2024-11-01');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (2, 2, 2, 1, '2024-11-02');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (3, 3, 3, 5, '2024-11-03');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (4, 4, 4, 3, '2024-11-04');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (5, NULL, 5, 7, '2024-11-05'); -- NULL Customer
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (6, 6, 6, 2, '2024-11-06');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (7, 7, NULL, 4, '2024-11-07'); -- NULL Product
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (8, 8, 8, 1, '2024-11-08');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (9, 9, 9, 3, '2024-11-09');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (10, 10, 10, 2, '2024-11-10');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (11, 11, 11, 5, '2024-11-11');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (12, 12, 12, 2, '2024-11-12');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (13, NULL, 13, 8, '2024-11-13'); -- NULL Customer
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (14, 14, NULL, 4, '2024-11-14'); -- NULL Product
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (15, 15, 15, 3, '2024-11-15');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (16, 16, 16, 2, '2024-11-16');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (17, 17, 17, 1, '2024-11-17');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (18, 18, 18, 4, '2024-11-18');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (19, 19, 19, 3, '2024-11-19');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (20, 20, 20, 6, '2024-11-20');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (21, 21, 21, 3, '2024-11-21');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (22, 22, 22, 5, '2024-11-22');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (23, 23, 23, 2, '2024-11-23');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (24, 24, 24, 4, '2024-11-24');
INSERT INTO Orders (OrderID, CustomerID, ProductID, Quantity, OrderDate) VALUES (25, 25, 25, 3, '2024-11-25');
ケース1: 単一の INNER JOIN 更新¶
INNER JOIN の場合、 FROM ステートメント内でテーブルを使用すると、自動的に INNER JOIN になります。Snowflakeの UPDATE ステートメントで JOINs をサポートするには、いくつかのアプローチがあることに注意してください。これは、可読性を確保するための最も単純なパターンのひとつです。
SQL Server¶
UPDATE Orders
SET Quantity = 10
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerName = 'John Doe';
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'John Doe';
CustomerID |
数量 |
CustomerName |
|---|---|---|
1 |
10 |
ジョン・ドウ |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 10
FROM
Customers C
WHERE
C.CustomerName = 'John Doe'
AND O.CustomerID = C.CustomerID;
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'John Doe';
CustomerID |
数量 |
CustomerName |
|---|---|---|
1 |
10 |
ジョン・ドウ |
その他のアプローチ:
MERGE INTO
MERGE INTO Orders O
USING Customers C
ON O.CustomerID = C.CustomerID
WHEN MATCHED AND C.CustomerName = 'John Doe' THEN
UPDATE SET O.Quantity = 10;
IN Operation
UPDATE Orders O
SET O.Quantity = 10
WHERE O.CustomerID IN
(SELECT CustomerID FROM Customers WHERE CustomerName = 'John Doe');
ケース2: 複数の INNER JOIN 更新¶
SQL Server¶
UPDATE Orders
SET Quantity = 5
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerName = 'Alice Johnson' AND P.ProductName = 'Tablet';
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'Alice Johnson';
CustomerID |
数量 |
CustomerName |
|---|---|---|
3 |
5 |
アリス・ジョンソン |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 5
FROM Customers C, Products P
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet'
AND O.ProductID = P.ProductID;
-- Select the changes
SELECT Orders.CustomerID, Orders.Quantity, Customers.CustomerName FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID
AND Customers.CustomerName = 'Alice Johnson';
CustomerID |
数量 |
CustomerName |
|---|---|---|
3 |
5 |
アリス・ジョンソン |
ケース3: 集計条件による複数の INNER JOIN 更新¶
SQL Server¶
UPDATE Orders
SET Quantity = 6
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
SELECT C.CustomerID, C.CustomerName, O.Quantity, P.Price FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
CustomerID |
CustomerName |
数量 |
価格 |
|---|---|---|---|
11 |
ジャック・グレイ |
6 |
29.99 |
18 |
クインシー・ブラウン |
6 |
15.99 |
20 |
サム・グリーン |
6 |
89.99 |
22 |
ウルスラ・レッド |
6 |
9.99 |
24 |
ウェンディ・ブラック |
6 |
49.99 |
Snowflake¶
UPDATE Orders O
SET Quantity = 6
WHERE O.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND O.ProductID IN (SELECT ProductID FROM Products WHERE Price < 200);
-- Select changes
SELECT C.CustomerID, C.CustomerName, O.Quantity, P.Price FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID
INNER JOIN Products P ON O.ProductID = P.ProductID
WHERE C.CustomerID IN (SELECT CustomerID FROM Orders WHERE Quantity > 3)
AND P.Price < 200;
CustomerID |
CustomerName |
数量 |
価格 |
|---|---|---|---|
11 |
ジャック・グレイ |
6 |
29.99 |
18 |
クインシー・ブラウン |
6 |
15.99 |
20 |
サム・グリーン |
6 |
89.99 |
22 |
ウルスラ・レッド |
6 |
9.99 |
24 |
ウェンディ・ブラック |
6 |
49.99 |
ケース4: 単一の LEFT JOIN 更新¶
SQL Server¶
UPDATE Orders
SET Quantity = 13
FROM Orders O
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND O.ProductID = 13;
-- Select the changes
SELECT * FROM orders
WHERE CustomerID IS NULL;
OrderID |
CustomerID |
ProductID |
数量 |
OrderDate |
|---|---|---|---|---|
5 |
null |
5 |
7 |
2024-11-05 |
13 |
null |
13 |
13 |
2024-11-13 |
Snowflake¶
UPDATE Orders
SET Quantity = 13
WHERE OrderID IN (
SELECT O.OrderID
FROM Orders O
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND O.ProductID = 13
);
-- Select the changes
SELECT * FROM orders
WHERE CustomerID IS NULL;
OrderID |
CustomerID |
ProductID |
数量 |
OrderDate |
|---|---|---|---|---|
5 |
null |
5 |
7 |
2024-11-05 |
13 |
null |
13 |
13 |
2024-11-13 |
注釈
Snowflakeのこのアプローチでは、必要な行が更新されないため、機能しません。
UPDATE Orders O SET O.Quantity = 13 FROM Customers C WHERE O.CustomerID = C.CustomerID AND C.CustomerID IS NULL AND O.ProductID = 13;
ケース5: 複数の LEFT JOIN と RIGHT JOIN 更新¶
これはもっと複雑なパターンです。複数の LEFT JOINs を翻訳するには、以下のパターンを確認してください。
注釈
LEFT JOIN と RIGHT JOIN は、 FROM 句の順番に依存します。
UPDATE [target_table_name]
SET [all_set_statements]
FROM [all_left_join_tables_separated_by_comma]
WHERE [all_clauses_into_the_ON_part]
SQL Server¶
UPDATE Orders
SET
Quantity = C.CustomerID
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
SELECT O.OrderID, O.CustomerID, O.ProductID, O.Quantity, O.OrderDate
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
OrderID |
CustomerID |
ProductID |
数量 |
OrderDate |
|---|---|---|---|---|
3 |
3 |
3 |
3 |
2024-11-12 |
Snowflake¶
UPDATE Orders O
SET O.Quantity = C.CustomerID
FROM Customers C, Products P
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet'
AND O.ProductID = P.ProductID;
SELECT O.OrderID, O.CustomerID, O.ProductID, O.Quantity, O.OrderDate
FROM Orders O
LEFT JOIN Customers C ON C.CustomerID = O.CustomerID
LEFT JOIN Products P ON P.ProductID = O.ProductID
WHERE C.CustomerName = 'Alice Johnson'
AND P.ProductName = 'Tablet';
OrderID |
CustomerID |
ProductID |
数量 |
OrderDate |
|---|---|---|---|---|
3 |
3 |
3 |
3 |
2024-11-12 |
ケース6: 混在する INNER JOIN と LEFT JOIN 更新¶
SQL Server¶
UPDATE Orders
SET Quantity = 4
FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
-- Select changes
SELECT O.CustomerID, C.CustomerName, O.Quantity FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
CustomerID |
CustomerName |
数量 |
|---|---|---|
null |
null |
4 |
Snowflake¶
UPDATE Orders O
SET Quantity = 4
WHERE O.ProductID IN (SELECT ProductID FROM Products WHERE ProductName = 'Monitor')
AND O.CustomerID IS NULL;
-- Select changes
SELECT O.CustomerID, C.CustomerName, O.Quantity FROM Orders O
INNER JOIN Products P ON O.ProductID = P.ProductID
LEFT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerID IS NULL AND P.ProductName = 'Monitor';
CustomerID |
CustomerName |
数量 |
|---|---|---|
null |
null |
4 |
ケース7: 単一の RIGHT JOIN 更新¶
SQL Server¶
UPDATE O
SET O.Quantity = 1000
FROM Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE C.CustomerName = 'Alice Johnson';
-- Select changes
SELECT
O.OrderID,
O.CustomerID,
O.ProductID,
O.Quantity,
O.OrderDate,
C.CustomerName
FROM
Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE
C.CustomerName = 'Alice Johnson';
| OrderID | CustomerID | ProductID | Quantity | CustomerName |
|---|---|---|---|---|
| 3 | 3 | 3 | 1000 | Alice Johnson |
Snowflake¶
UPDATE Orders O
SET O.Quantity = 1000
FROM Customers C
WHERE O.CustomerID = C.CustomerID
AND C.CustomerName = 'Alice Johnson';
-- Select changes
SELECT
O.OrderID,
O.CustomerID,
O.ProductID,
O.Quantity,
O.OrderDate,
C.CustomerName
FROM
Orders O
RIGHT JOIN Customers C ON O.CustomerID = C.CustomerID
WHERE
C.CustomerName = 'Alice Johnson';
| OrderID | CustomerID | ProductID | Quantity | CustomerName |
|---|---|---|---|---|
| 3 | 3 | 3 | 1000 | Alice Johnson |
既知の問題¶
Snowflakeの
UPDATEではJOINsを直接使用することができないため、説明したパターンに合致しないケースが存在する可能性があります。
LEFT と RIGHT JOIN を含む UPDATE¶
Applies to
[x] SQL Server
[x] Azure Synapse Analytics
警告
Snowflakeで部分的にサポートされています
説明¶
パターン UPDATE FROM は、他のテーブルのデータに基づいてデータを更新するために使用されます。この SQLServer ドキュメント では、単純なサンプルを提供しています。
ドキュメント にある以下の SQL Server構文を確認してください。
SQL Server構文¶
UPDATE [table_name]
SET column_name = expression [, ...]
[FROM <table_source> [, ...]]
[WHERE <search_condition>]
[OPTION (query_hint)]
table_name: 更新するテーブルまたはビュー。SET: 列とその新しい値を指定します。SET句は、1つ以上の列に新しい値(または式)を割り当てます。FROM: 1つ以上のソーステーブルを指定するために使用されます(_ join のように)_。これは、更新を実行するためのデータの出所を定義するのに役立ちます。WHERE: 条件に基づいて更新する行を指定します。この句がなければ、テーブルのすべての行が更新されます。OPTION (query_hint): クエリ最適化のためのヒントを指定します。
Snowflake構文¶
Snowflakeの構文は Snowflakeドキュメント でも確認できます。
注釈
Snowflakeは UPDATE 句の JOINs をサポートしていません。
UPDATE <target_table>
SET <col_name> = <value> [ , <col_name> = <value> , ... ]
[ FROM <additional_tables> ]
必須パラメーター
_
target_table:_ 更新するテーブルを指定します。_
col_name:_ _target_table_ 内の列の名前を指定します。テーブル名は含めないでください。例えば、UPDATE t1 SET t1.col = 1は無効です。_
value:_ _col_name_ に設定する新しい値を指定します。
オプションのパラメーター
FROM``_additional_tables:_ 更新する行の選択や新しい値のセットに使用する1つ以上のテーブルを指定します。 ターゲットテーブルを繰り返すと自己結合になることに注意してください。WHERE``_条件:_ 更新するターゲットテーブルの行を指定する式。デフォルト:値なし(ターゲットテーブルのすべての行が更新されます)
翻訳概要¶
文法の説明で説明されているように、 UPDATE 句内の JOINs については、直接等価な解決策はありません。このため、このステートメントを変換するアプローチは、論理的に必要なデータをテーブルに追加する列に演算子(+)を追加することです。この演算子(+)は、 LEFT/RIGHT JOIN セクションでテーブルが参照されるケースに追加されます。
この演算子(+)を使用する言語は他にもあり、演算子の位置によって結合のタイプが決まる場合があることに注意してください。Snowflakeのこの特定のケースでは、位置が結合タイプを決定するのではなく、論理的に必要なテーブルと列との関連付けが決定します。
MERGE c;auseや CTE;の使用として他の選択肢がある場合でも、これらの選択肢は、複雑なクエリがある場合、読みにくくなり、大規模になる傾向があります。
サンプルソースパターン¶
セットアップデータ¶
CREATE TABLE GenericTable1 (
Col1 INT,
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10),
Col6 VARCHAR(100)
);
CREATE TABLE GenericTable2 (
Col1 VARCHAR(10),
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10)
);
CREATE TABLE GenericTable3 (
Col1 VARCHAR(10),
Col2 VARCHAR(100),
Col3 CHAR(1)
);
INSERT INTO GenericTable1 (Col1, Col2, Col3, Col4, Col5, Col6)
VALUES
(1, 'A1', 'B1', 'C1', NULL, NULL),
(2, 'A2', 'B2', 'C2', NULL, NULL),
(3, 'A3', 'B3', 'C3', NULL, NULL);
INSERT INTO GenericTable2 (Col1, Col2, Col3, Col4, Col5)
VALUES
('1', 'A1', 'B1', 'C1', 'X1'),
('2', 'A2', 'B2', 'C2', 'X2'),
('3', 'A3', 'B3', 'C3', 'X3');
INSERT INTO GenericTable3 (Col1, Col2, Col3)
VALUES
('X1', 'Description1', 'A'),
('X2', 'Description2', 'A'),
('X3', 'Description3', 'A');
CREATE OR REPLACE TABLE GenericTable1 (
Col1 INT,
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10),
Col6 VARCHAR(100)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE GenericTable2 (
Col1 VARCHAR(10),
Col2 VARCHAR(10),
Col3 VARCHAR(10),
Col4 VARCHAR(10),
Col5 VARCHAR(10)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
CREATE OR REPLACE TABLE GenericTable3 (
Col1 VARCHAR(10),
Col2 VARCHAR(100),
Col3 CHAR(1)
)
COMMENT = '{ "origin": "sf_sc", "name": "snowconvert", "version": { "major": 0, "minor": 0, "patch": "0" }, "attributes": { "component": "transact", "convertedOn": "12/18/2024", "domain": "test" }}'
;
INSERT INTO GenericTable1 (Col1, Col2, Col3, Col4, Col5, Col6)
VALUES
(1, 'A1', 'B1', 'C1', NULL, NULL),
(2, 'A2', 'B2', 'C2', NULL, NULL),
(3, 'A3', 'B3', 'C3', NULL, NULL);
INSERT INTO GenericTable2 (Col1, Col2, Col3, Col4, Col5)
VALUES
('1', 'A1', 'B1', 'C1', 'X1'),
('2', 'A2', 'B2', 'C2', 'X2'),
('3', 'A3', 'B3', 'C3', 'X3');
INSERT INTO GenericTable3 (Col1, Col2, Col3)
VALUES
('X1', 'Description1', 'A'),
('X2', 'Description2', 'A'),
('X3', 'Description3', 'A');
LEFT JOIN¶
SQL Server
UPDATE T1
SET
T1.Col5 = T2.Col5,
T1.Col6 = T3.Col2
FROM GenericTable1 T1
LEFT JOIN GenericTable2 T2 ON
T2.Col1 COLLATE SQL_Latin1_General_CP1_CI_AS = T1.Col1
AND T2.Col2 = T1.Col2
AND T2.Col3 = T1.Col3
AND T2.Col4 = T1.Col4
LEFT JOIN GenericTable3 T3 ON
T3.Col1 = T2.Col5 AND T3.Col3 = 'A';
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
| Col1 | Col2 | Col3 | Col4 | Col5 | Col6 |
|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | X1 | Description1 |
| 2 | A2 | B2 | C2 | X2 | Description2 |
| 3 | A3 | B3 | C3 | X3 | Description3 |
Snowflake
UPDATE dbo.GenericTable1 T1
SET
T1.Col5 = T2.Col5,
T1.Col6 = T3.Col2
FROM
GenericTable2 T2,
GenericTable3 T3
WHERE
T2.Col1(+) COLLATE 'EN-CI-AS' /*** SSC-FDM-TS0002 - COLLATION FOR VALUE CP1 NOT SUPPORTED ***/ = T1.Col1
AND T2.Col2(+) = T1.Col2
AND T2.Col3(+) = T1.Col3
AND T2.Col4(+) = T1.Col4
AND T3.Col1(+) = T2.Col5
AND T3.Col3 = 'A';
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
| Col1 | Col2 | Col3 | Col4 | Col5 | Col6 |
|---|---|---|---|---|---|
| 1 | A1 | B1 | C1 | X1 | Description1 |
| 2 | A2 | B2 | C2 | X2 | Description2 |
| 3 | A3 | B3 | C3 | X3 | Description3 |
RIGHT JOIN¶
SQL Server
UPDATE T1
SET
T1.Col5 = T2.Col5
FROM GenericTable2 T2
RIGHT JOIN GenericTable1 T1 ON
T2.Col1 COLLATE SQL_Latin1_General_CP1_CI_AS = T1.Col1
AND T2.Col2 = T1.Col2
AND T2.Col3 = T1.Col3
AND T2.Col4 = T1.Col4;
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
X1 |
null |
2 |
A2 |
B2 |
C2 |
X2 |
null |
3 |
A3 |
B3 |
C3 |
X3 |
null |
Snowflake
UPDATE dbo.GenericTable1 T1
SET
T1.Col5 = T2.Col5
FROM
GenericTable2 T2,
GenericTable1 T1
WHERE
T2.Col1 COLLATE 'EN-CI-AS' /*** SSC-FDM-TS0002 - COLLATION FOR VALUE CP1 NOT SUPPORTED ***/ = T1.Col1
AND T2.Col2 = T1.Col2(+)
AND T2.Col3 = T1.Col3(+)
AND T2.Col4 = T1.Col4(+);
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
null |
null |
2 |
A2 |
B2 |
C2 |
null |
null |
3 |
A3 |
B3 |
C3 |
null |
null |
Col1 |
Col2 |
Col3 |
Col4 |
Col5 |
Col6 |
|---|---|---|---|---|---|
1 |
A1 |
B1 |
C1 |
X1 |
null |
2 |
A2 |
B2 |
C2 |
X2 |
null |
3 |
A3 |
B3 |
C3 |
X3 |
null |
既知の問題¶
ロジックの違いから翻訳できないパターンもあるかもしれません。
クエリパターンが当てはまる場合は、非決定行を見直してください。「FROM 句で、テーブル間に JOIN が含まれている場合(例:
t1とt2)、t1のターゲット行は、テーブルt2の複数の行を結合(つまり一致)する場合があります。これが発生すると、ターゲット行は 複数結合行 と呼ばれます。複数結合行を更新する場合、 ERROR_ON_NONDETERMINISTIC_UPDATE セッションパラメーターが更新の結果を制御します」 (Snowflakeドキュメント)。